Note:
We continuously update the benchmark results for MyScale and other vector database products in our open-source project, vector-db-benchmark (opens new window).
It is widely assumed that relational databases cannot compete with the performance of specialized vector databases. For example, PostgreSQL with vector extensions has a significant performance disadvantage when compared to specialized vector databases like Pinecone. This is why there are so many specialized vector databases available today. People prefer relational databases for a variety of reasons, including production readiness, a robust feature set, support and community, integration, security, and of course, SQL, the familiar and powerful language for communicating with data. In specialized vector databases, all these features are somewhat compromised.
What if we had a relational database that could compete with, or even outperforms specialized vector databases?
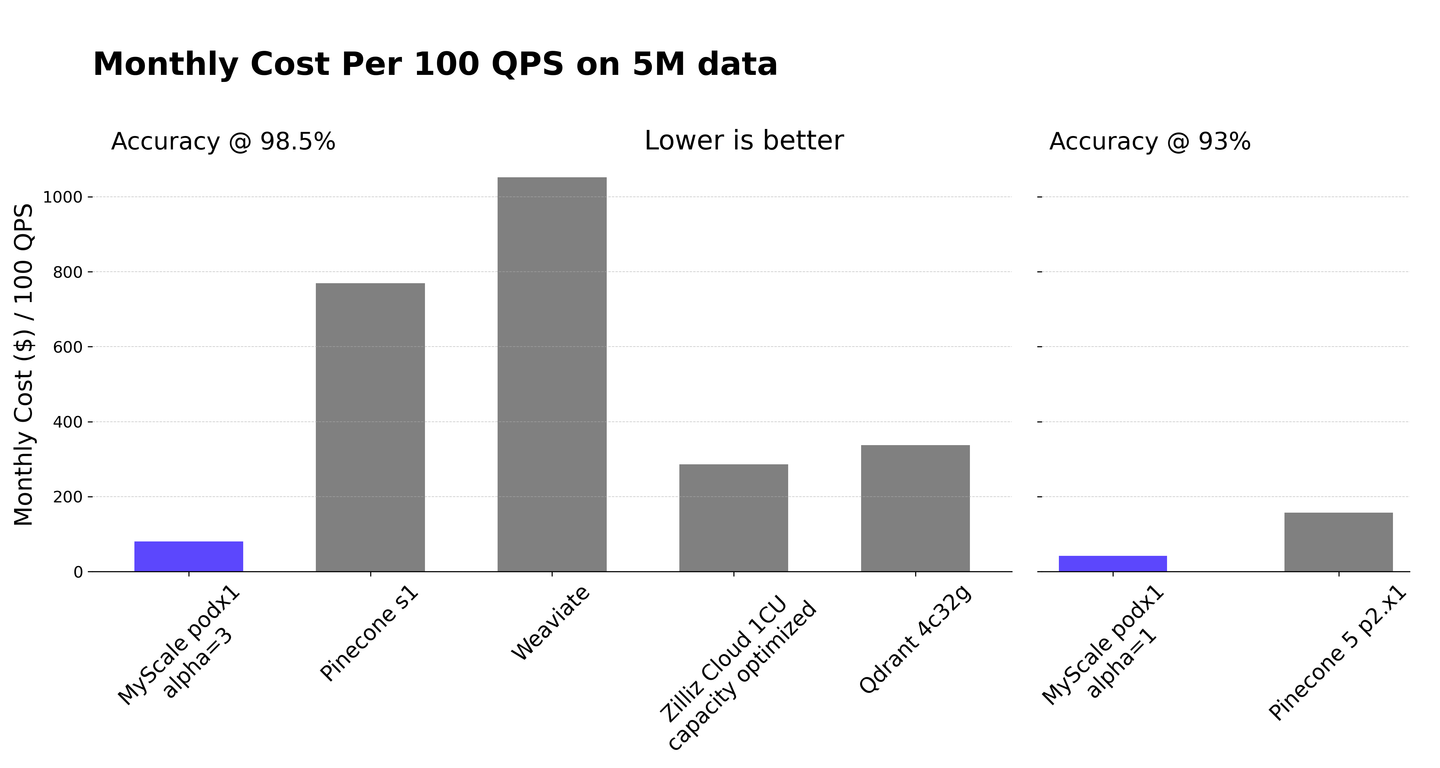
We are thrilled to announce a significant upgrade to MyScale accomplishes exactly this. For the first time, a relational database can outperform the most advanced specialized vector databases in terms of vector performance, while retaining all of the relational database and SQL benefits. In a direct comparison with Pinecone, a leading specialized vector database, MyScale outperforms it by 10x against Pinecone's s1 pod in query speed, and by 5x against its p2 pod in data density. When cost-effectiveness is considered, MyScale is 3.6x more cost-effective than other top-performing specialized vector databases at various levels of accuracy. This is illustrated in the figure below. While Pinecone is a leading database, the cost-effectiveness comparison in this context is with a range of the best performing specialized vector databases, not just Pinecone.
This is accomplished by integrating structured data and vectors seamlessly with a series of innovations involving both algorithmic and system engineering:
- Algorithm innovations. At the core of vector databases are nearest neighbor search algorithms. Unlike most vector databases, which rely on the same set of algorithms, such as IVF and HNSW or their variants, and thus have similar performance limits. MyScale implements a proprietary algorithm called MSTG (Multi-Scale Tree Graph) that outperforms IVF and HNSW, sometimes by 10x or more.
- System engineering. MyScale is built on top of ClickHouse. We love ClickHouse for its high performance and extensive feature set. However, it comes with some well-known issues and system overheads. We made numerous system improvements and bug fixes to make vectors work with ClickHouse (some are contributed back to the ClickHouse community, such as light-weight deletes).
The performance upgrades, which are now available through MyScale, allow users to create even more powerful AI applications. MyScale includes the following key features:
- High data capacity and performance: In MyScale, a single standard pod supports 5 million 768-dimensional data points with high accuracy, achieving over 150 queries per second (QPS).
- Rapid data ingestion: Ingest 5 million data points in under 30 minutes, minimizing wait time and allowing you to serve your vector data faster.
- Support for multiple indexes: You can create multiple tables with unique vector indexes in each MyScale pod (see Vector Reference (opens new window)). By leveraging this feature with high data capacity, you can efficiently manage heterogeneous vector data in one MyScale cluster, further reducing system complexity and cost.
- Simple data import and backup: With support for standard formats such as Parquet or compressed tar files, you can easily import/export data from/to S3 (opens new window) or other compatible object storage systems using a single SQL command.
MyScale is currently in beta, with a free developer tier and a commercial plan on the way. To the best of our knowledge, MyScale offers the first free plan that supports 5 million 768-dimensional vector data points with high performance search.
# Benchmarking MyScale Against Leading Vector Database Services
In this article, we conduct a thorough benchmarking comparison of MyScale with other widely used vector database services. The benchmarking code and results are publicly available here (opens new window), and we will be updating them on a regular basis. This post contains a concise summary of the key findings.
The services chosen for this benchmarking exercise include industry leaders such as Pinecone, Qdrant, Weaviate, and Zilliz Cloud. We evaluated these services on three key parameters: data ingestion time, search QPS (Queries Per Second), and average latency. The dataset used for testing consists of 5 million 768-dimensional vectors, generated from the LAION 2B images (opens new window). This dataset is also publicly accessible (opens new window).
Our primary focus during this benchmarking exercise was on services with high capacity. Thus, when a service provided multiple pod configurations, we chose for the one with the greatest data density. Examples include Pinecone's s1 pod and Zilliz Cloud's capacity-optimized 1CU, which provide 5-million-vector data capacity. Additionally, services like MyScale, Weaviate, and Zilliz Cloud offer various tuning options for balancing search speed and accuracy. In the case of MyScale, we selected a configuration with alpha=3 that provided a top-10 recall of 98.5%, and compared it to other services with similar levels of accuracy. All tests were conducted using four parallel client connections.
# Cost-performance ratio
An essential component of this benchmarking study is the evaluation of the cost-performance ratio, which measures the ratio of the monthly cost to the QPS (Queries Per Second) of the service per one hundred units. It quantifies the monthly cost required to achieve 100 QPS on 5 million vector data points. Our analysis highlights the superior cost-performance ratio of MyScale, which is over 3.6 times cheaper than other vector databases. Despite its high data density, Pinecone's s1 is hampered by its lower QPS, resulting in a less favorable cost-performance ratio. Weaviate’s cost-effectiveness is constrained by its pricing structure, which scales the number of queries. Even at a minimum query rate of one per month, the base cost remains at $192/month, and with an average QPS of 5, the cost rises to $690/month, which was used in the previous figure to calculate cost efficiency. Despite its substantial data storage capacity, Zilliz Cloud has a lower QPS, negatively impacting its cost-to-performance ratio. Qdrant cloud requires 32GB memory to manage 5 million data points efficiently, resulting in increased costs. Despite investigating numerous HNSW tuning parameters and settling on m=32 ef_c=256 for optimal performance, the query per second (QPS) rate is insufficient for a satisfactory cost-performance ratio.
To conduct a thorough comparison, we also examined the Pinecone p2 pod. Each p2 pod supports 1M 768D data, and we selected the 5 p2.x1 scaling out configuration to accommodate the data while minimizing costs. Pinecone's p2 has a top-10 recall rate of approximately 93%, which is lower than the performance of other vector database services but comparable to the performance of MyScale's alpha=1 setting. Thus, we included a separate comparison for Pinecone p2 on the right graph. In this case, MyScale proves to be 3.7x more cost effective than 5 p2.x1. The rest of the article primarily emphasizes on the high accuracy setting, consistent with the prevalent standard among vector database services.
Here's a summary of the services tested in this article, see previous figure for the cost-performance ratio of each service.
| Accuracy | Service | QPS | Monthly Cost ($) | Comment |
|---|---|---|---|---|
| 98.5% | MyScale's standard pod (alpha=3) | 150 | 120 | Beta with free trial, standard tier coming soon |
| Pinecone s1 | 9 | 69 | GCP Base Price | |
| Weaviate | 66 | 690 | Total monthly queries calculated as 5 * 3600 * 24 * 30 | |
| Zilliz Cloud 1CU Capacity Optimized | 63 | 186 | - | |
| Qdrant 4c32g | 81 | 273 | HNSW m=32 ef_c=256 | |
| 93% | MyScale's standard pod (alpha=1) | 288 | 120 | - |
| Pinecone 5 p2.x1 | 331 | 518 | Horizontal scaling of 5 p2 pods |
Let's examine some more specific performance metrics, such as QPS, average query latency, and data ingestion time.
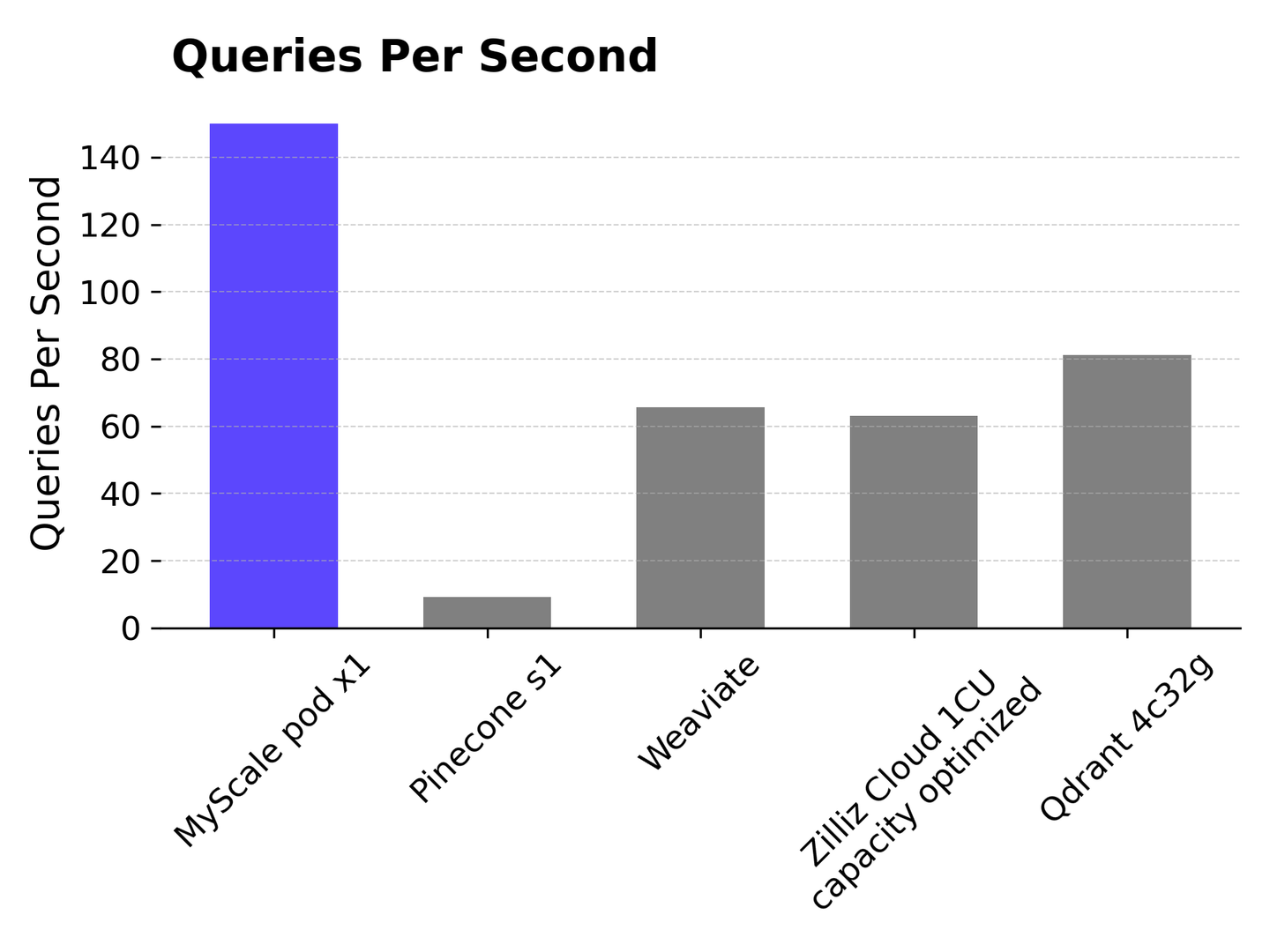
# Queries Per Second (QPS)
MyScale outperforms other vector databases in terms of QPS on the LAION 5M dataset with a 98.5% recall rate, achieving over 150 QPS. In comparison, Pinecone s1 has a QPS of approximately 10, which is significantly lower than MyScale. Weaviate and Zilliz Cloud both achieve around 65 QPS, while Qdrant achieves 81 QPS.
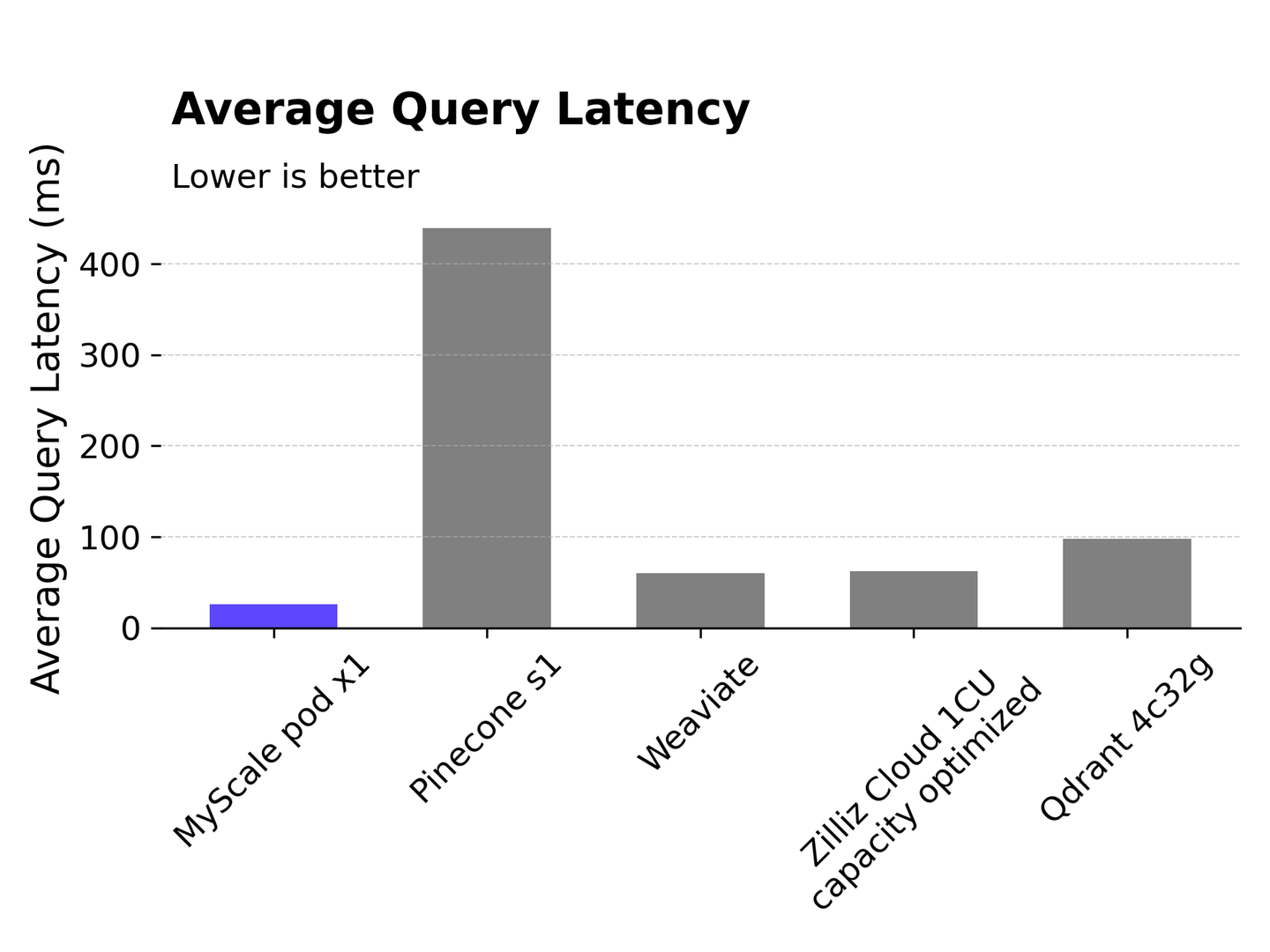
# Average Query Latency
Query latency is an important performance metric that is measured from the time the client sends the request until it receives the response. MyScale achieves 150 QPS while maintaining an average latency as low as 25.8 ms. Pinecone s1 has a relatively high latency of over 400 ms. Weaviate and Zilliz Cloud both have latencies of around 60 ms, while Qdrant has a slightly higher latency of around 100 ms.
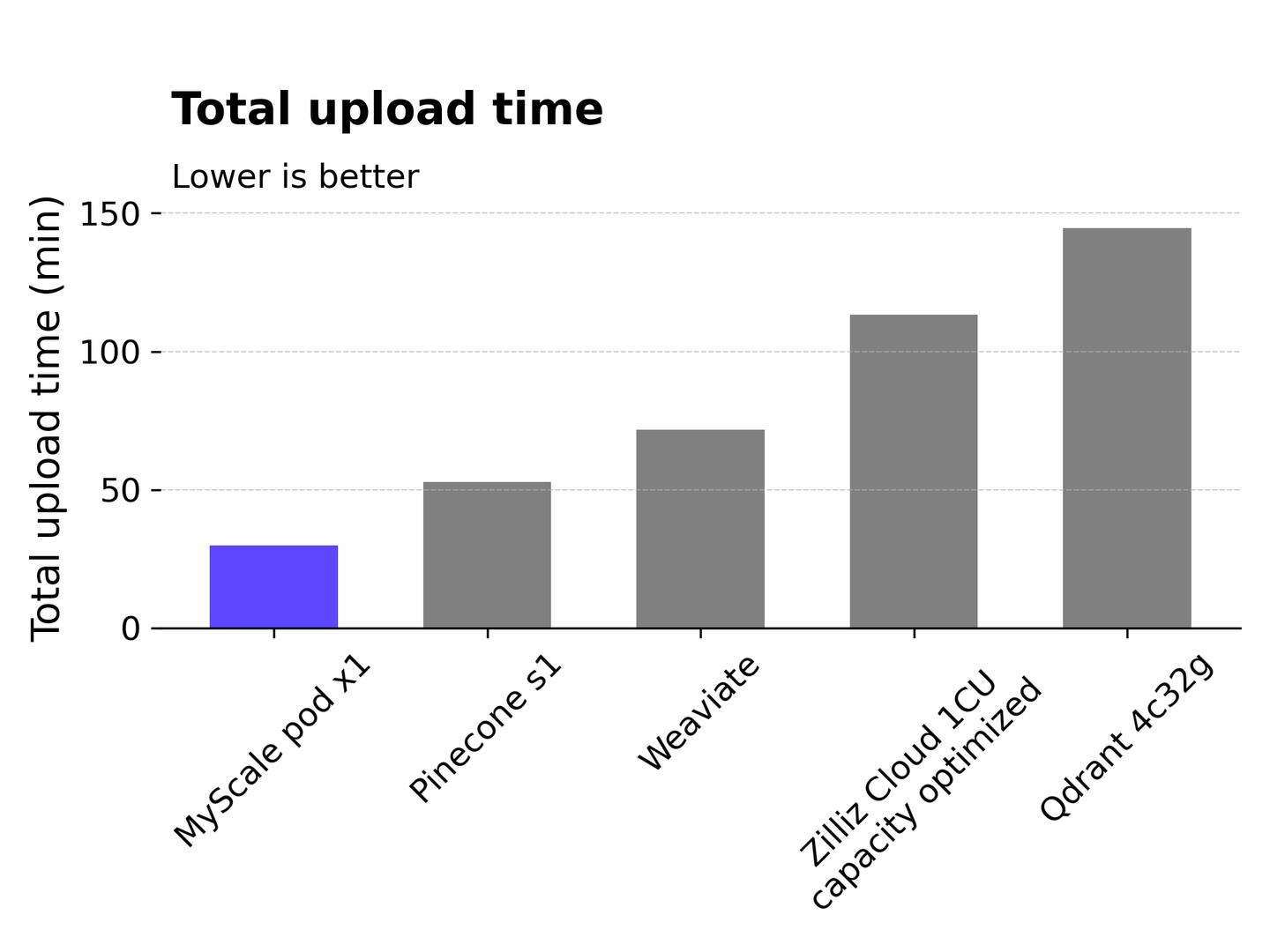
# Data Ingestion Time
The time it takes from data upload to the vector index being built and ready to serve is referred to as data ingestion time. Index creation can take a long time, especially for graph-based algorithms such as HNSW. Among all the services tested, MyScale had the fastest ingestion time for 5 million data points, completing the task in about 30 minutes. Pinecone s1 takes approximately 53 minutes, while Weaviate takes 72 minutes. Zilliz Cloud requires a longer duration of approximately 113 minutes, while Qdrant has the longest ingestion time, taking 145 minutes to process 5 million data points.

# Conclusion
In conclusion, MyScale, which is based on ClickHouse, demonstrates that it is possible to outperform specialized vector databases by achieving 3.6x higher cost-efficiency while retaining all the benefits of relational databases and SQL. And this is just the beginning.
MyScale has now officially launched with a free developer tier. The commercial plan offers additional features, including increased data capacity, as well as multi-replication and multi-zone availability. For more information, please contact us at contact@myscale.com or join our Discord (opens new window).