
Die Retrieval Augmented Generation (RAG) verbessert die Leistung von LLMs, indem sie sie mit externen Wissensdatenbanken verbindet. Sie hat viele Vorteile, darunter geringere Kosten/Ressourcen, Optimierung von LLMs für bestimmtes Domänenwissen und Datensicherheit usw. RAG ist im Kontext des Deep Learning relativ neu [1], wird jedoch immer häufiger eingesetzt.
Da die Nutzung von RAG zunimmt, wird sie auch kontinuierlich verbessert. Da in den RAG-Systemen Einschränkungen entdeckt werden, identifizieren Forscher Möglichkeiten zur Verbesserung ihrer Leistung. Heute werden wir über die Verbesserung von Abfragen sprechen.
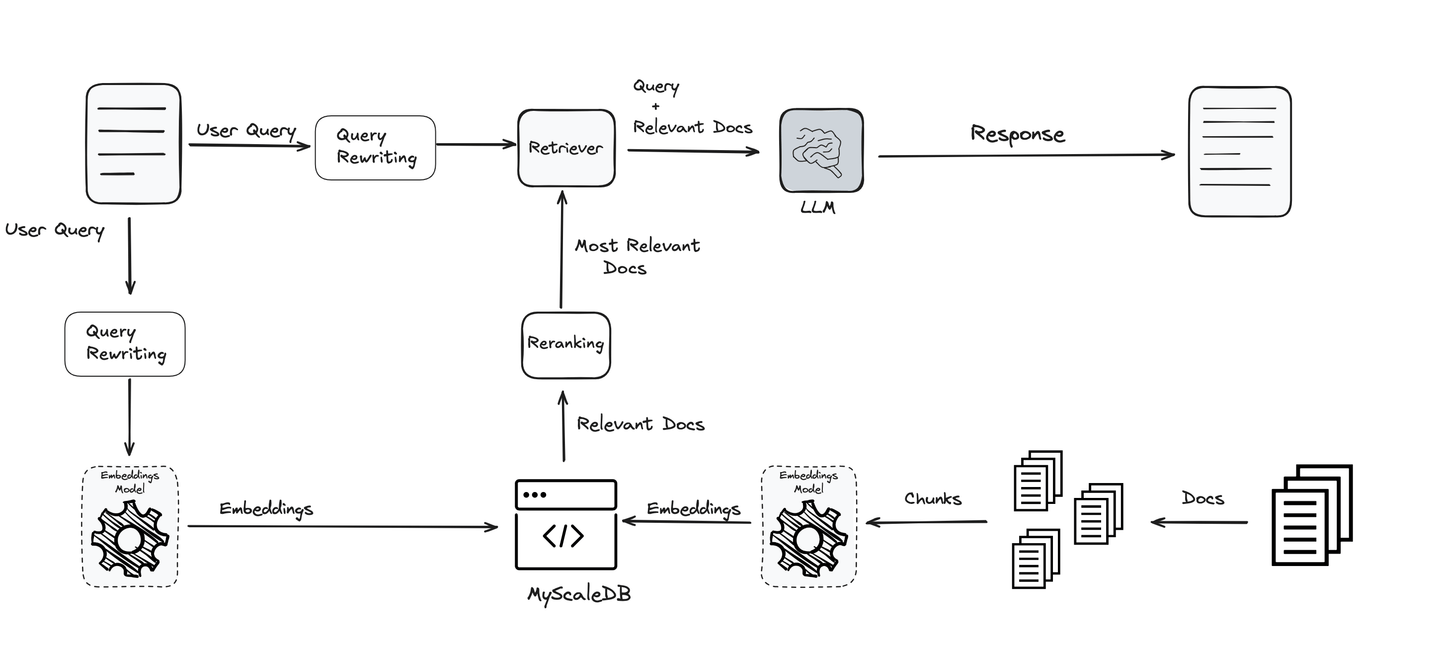
Fügen Sie einen Schritt zur Abfrageumformulierung hinzu
Die Abfrage ist einer der wichtigsten Teile der gesamten RAG-Pipeline. Was auch immer Sie fragen, bestimmt die Richtung, und das LLM sowie alle anderen Werkzeuge arbeiten daran, Ihnen Informationen basierend darauf zu liefern. Wenn die Abfrage nicht klar oder gut optimiert ist, können selbst die besten Systeme versagen. Daher ist die Verbesserung und Verfeinerung von Abfragen entscheidend, um genaue und aussagekräftige Ergebnisse zu erhalten.
Unter Berücksichtigung dieser Bedeutung werden verschiedene Techniken verwendet, um Abfragen zu optimieren und zu klären, um sicherzustellen, dass der Endbenutzer die besten und relevantesten Ergebnisse erhält. Diese Techniken machen das System effektiver und zuverlässiger und unterstützen jeden Schritt der RAG-Pipeline.
# Umformulierung von Abfragen
Eine von einem (meist naiven) Benutzer geschriebene Abfrage kann aus Sicht eines LLMs kaum beurteilt werden, und wie die Erfahrung gezeigt hat, haben diese Abfragen viel Raum für Verbesserungen. LLMs oder andere Abrufsysteme können auch empfindlich auf bestimmte Wörter reagieren, daher können die Umformulierung der Abfragen die Abfragen für ein besseres Verständnis optimieren.
Beispiel:
Um dies weiter zu veranschaulichen, zitieren wir ein Beispiel aus [2]. Die ursprüngliche von ihnen bereitgestellte Abfrage lautete:
Eine Autofabrik erwägt einen neuen Standort für ihr nächstes Werk. Mit welchem der folgenden Punkte würden sich Gemeindeplaner am meisten befassen, bevor sie den Bau des Werks zulassen?
Diese Abfrage war zu komplex, um vom LLM präzise verstanden zu werden, und er konnte sie nicht beantworten. Nach Anwendung des Umformulierers lautet die umformulierte Abfrage:
Mit welchem Punkt würden sich Gemeindeplaner am meisten befassen, bevor sie den Bau einer Autofabrik zulassen?
Sie funktioniert einwandfrei und liefert auch die richtige Antwort.
Es gibt eine Reihe von Techniken zur Umformulierung einer Abfrage. Einige ersetzen sie durch Synonyme, einige hängen Metadaten an (opens new window), einige konzentrieren sich auf die Verbesserung der Grammatik, und einige erweitern die Abfrage in eine sinnvollere Form (sogar einige Methoden generieren Permutationen der ursprünglichen Abfrage (opens new window)), usw. Interessanterweise beinhalten einige dieser Methoden auch LLMs (opens new window) selbst. Es handelt sich also um eine Art rekursiven Einsatz von LLMs, bei dem wir sie verwenden, um die Eingabe für ein anderes (oder dasselbe) LLM zu verbessern.
# Abfrage-Normalisierung
Die Abfrage-Normalisierung bezieht sich auf einfache Methoden zur Behebung von Grammatik- und Rechtschreibfehlern in der ursprünglichen Abfrage usw. Ähnlich können für die Abfrage-Normalisierung auch Vorverarbeitungsschritte wie Umwandlung in Kleinbuchstaben oder Entfernen von Stoppwörtern verwendet werden.
Zum Beispiel ist es viel einfacher zu verstehen, "Wer war der Autor von Die Brüder Karamasow?" als "wer schrieb broter karamov", da Sie die Rechtschreibfehler in der letzteren Abfrage bemerken.
Hierbei ist zu beachten, dass LLMs leistungsstarke Transformer-Modelle sind, die normalerweise in der Lage sind, Sätze ohne zu viel Normalisierung zu verstehen. Daher muss ein Gleichgewicht zwischen der Normalisierung von Eingaben und deren Übertreibung gefunden werden.
# Abfrageerweiterung
Da wir in den meisten Fällen nicht sicher sind, ob eine Abfrage gut funktioniert oder nicht, ist eine häufige Methode, mehrere Permutationen einer Abfrage zu erstellen und Ergebnisse für alle von ihnen zurückzugeben. Während wir auch eine Reihe von klassischen Umschreibemethoden haben, sind LLMs selbst darin sehr gut, wie Sie zuvor bemerkt haben.
Hier ist ein Beispiel (ursprünglich von LangChain (opens new window) übernommen) unter Verwendung von LangChain und OpenAI's GPT-4-Modell.
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""Sie haben die Abfrageerweiterung durchgeführt, um eine Umschreibung einer Frage zu generieren."""
paraphrased_query: str = Field(
...,
description="Eine eindeutige Umschreibung der ursprünglichen Frage.",
)
system = """Sie sind ein Experte darin, Benutzerfragen in Datenbankabfragen umzuwandeln. \
Sie haben Zugriff auf eine Datenbank mit Tutorial-Videos über eine Softwarebibliothek zum Erstellen von LLM-gesteuerten Anwendungen. \
Führen Sie eine Abfrageerweiterung durch. Wenn es mehrere gängige Möglichkeiten gibt, eine Benutzerfrage zu formulieren, \
oder gängige Synonyme für Schlüsselwörter in der Frage, stellen Sie sicher, dass mehrere Versionen der Abfrage mit den verschiedenen Formulierungen zurückgegeben werden.
Wenn es Akronyme oder Wörter gibt, mit denen Sie nicht vertraut sind, versuchen Sie nicht, sie umzuformulieren.
Geben Sie mindestens 3 Versionen der Frage zurück."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
Nachdem der Abfrage Expander erstellt wurde, können wir ihn jetzt verwenden. Zum Beispiel:

Ergebnisse der Abfrageerweiterung
Wie Sie sehen können, liefert er schöne Permutationen (wir können die Anzahl der Permutationen weiter erhöhen, wenn wir möchten), die beim Füttern des LLM hilfreich sein können.
# Kontextuelle Anpassung
Der Prozess der kontextuellen Anpassung besteht darin, eine Abfrage an den spezifischen Kontext anzupassen, in dem sie gestellt wird. Dies wird oft durch die Nutzung von Verstärkendem Lernen (RL) erreicht, das die Formulierung der Abfrage basierend auf kontextuellen Informationen optimiert. Eine Methode verwendet ein kleines Sprachmodell (LM) als Abfrage-Umformulierer und nutzt externe Quellen wie Internetdaten, um den Kontext der Abfrage zu bereichern. Die RL-Komponente feinabstimmt dann diese Anpassung, indem sie aus dem Feedback darüber lernt, wie gut die umformulierte Abfrage im gegebenen Kontext funktioniert. Diese Methode wurde in verschiedenen Forschungsstudien untersucht, wie in [2] und [3] referenziert, und hat sich als wirksam bei der Verbesserung der Relevanz und Leistung von Abfragen erwiesen.
# Abfragezerlegung
Abfragen enthalten oft zwei (oder mehr) verschiedene Abfragen, was es den LLMs erschwert, sie zu verstehen. Außerdem sind LLMs ziemlich anfällig für irrelevante Kontexte [4]. Zum Beispiel wird in dem klassischen Beispiel für das Alter von Jessica die Einführung einer nicht zusammenhängenden Aussage (einer in Rot) das LLM wahrscheinlich verwirren.

Ein Beispiel für eine ineffiziente Abfrageverständnis (übernommen von [4]) führt zur Notwendigkeit der Abfragezerlegung. Die unterstrichene Aussage in Rot kompliziert die Abfrage unnötig und erschwert es dem LLM, sie zu verstehen.
Eine bessere Lösung hier wäre, die Abfrage in etwas wie folgt zu zerlegen:
"Jessica ist sechs Jahre älter als Claire. In zwei Jahren wird Claire 20 Jahre alt sein." "Vor zwanzig Jahren war das Alter von Claires Vater das Dreifache des Alters von Jessica." "Wie alt ist Jessica jetzt?"
Und wahrscheinlich können wir sogar die zweite Aussage weglassen.
# Herausforderungen bei der Abfragezerlegung
Die Abfragezerlegung hat einige Vorteile wie bessere Klarheit und Unterstützung des LLMs bei der schrittweisen Argumentation. Es gibt jedoch auch einige Herausforderungen im Zusammenhang mit der Abfragezerlegung, wie z.B.:
- Übermäßige Zerlegung: Eine zu starke Zerlegung der Abfragen kann den Kontext verwässern und zu weniger relevanten Ergebnissen führen.
- Kombinieren von Ergebnissen: Das Zusammenführen von Ergebnissen aus Teiabfragen kann herausfordernd sein, insbesondere wenn sie widersprüchlich oder unvollständig sind.
- Abhängigkeit von Abfragen: Einige Abfragen hängen von Ergebnissen aus früheren Schritten ab und erfordern iterative Prozesse.
- Kosten und Latenz: Das Aufteilen von Abfragen in mehrere Teile erhöht die Anzahl der Abruf- und Berechnungsschritte, was rechnerisch teuer sein kann.
Obwohl die Abfragezerlegung vielversprechend ist, wie wir an den Herausforderungen gesehen haben, hat sie noch viel Raum für Verbesserungen. Wenn Sie Zweifel haben, ob Sie sie verwenden sollen oder nicht, ist es ratsam, auf der sichereren Seite zu bleiben, insbesondere um Kosten zu sparen.
# Optimierung von Einbettungen
Einbettungen werden in der Regel mit gängigen NLP-Modellen wie BERT (opens new window) oder Titan (opens new window) generiert. Diese Einbettungen sind für viele Anwendungen recht gut geeignet, müssen jedoch oft für ein besseres Verständnis optimiert werden. Aus diesem Grund wurden auch Benchmarks wie der Massive Text Embedding Benchmark, MTEB [5], vorgeschlagen, um zu überprüfen, wie gut Einbettungen in 8 verschiedene Aufgaben wie Klassifizierung, Clustering und Zusammenfassung funktionieren.
"Wir stellen fest, dass es keine einzelne beste Lösung gibt, da verschiedene Modelle bei verschiedenen Aufgaben dominieren." - MTEB-Papier
Wie MTEB ebenfalls richtig erkennt, gibt es keine einzelne beste Lösung für alle Aufgaben: Einige Modelle eignen sich gut für Zusammenfassungen, andere für Klassifizierung usw. Und es ist auch nicht universell für alle Datensätze, da Modelle bei einigen Datensätzen für dieselbe Aufgabe besser abschneiden, während sie bei anderen Ergebnissen unterdurchschnittlich sind.
# Hypothetische Dokumenteinbettung (HyDE)
Im Jahr 2022 wurde eine neuartige Zero-Shot-Methode von Forschern vorgeschlagen. [6] Diese einzigartige Methode basiert auf dem Konzept, ein gefälschtes Dokument zu erstellen und dann seine Einbettungen zu verwenden, um ähnliche (echte) Dokumente im Einbettungsraum zu finden. HyDE gewinnt als Werkzeug zur Abfrageoptimierung in RAG an Beliebtheit. Die Methodik von HyDE kann wie folgt zusammengefasst werden:
- Generieren eines hypothetischen Dokuments
- Berechnung seiner Einbettung
- Verwendung der Einbettung zur Abfrage der Vektordatenbank
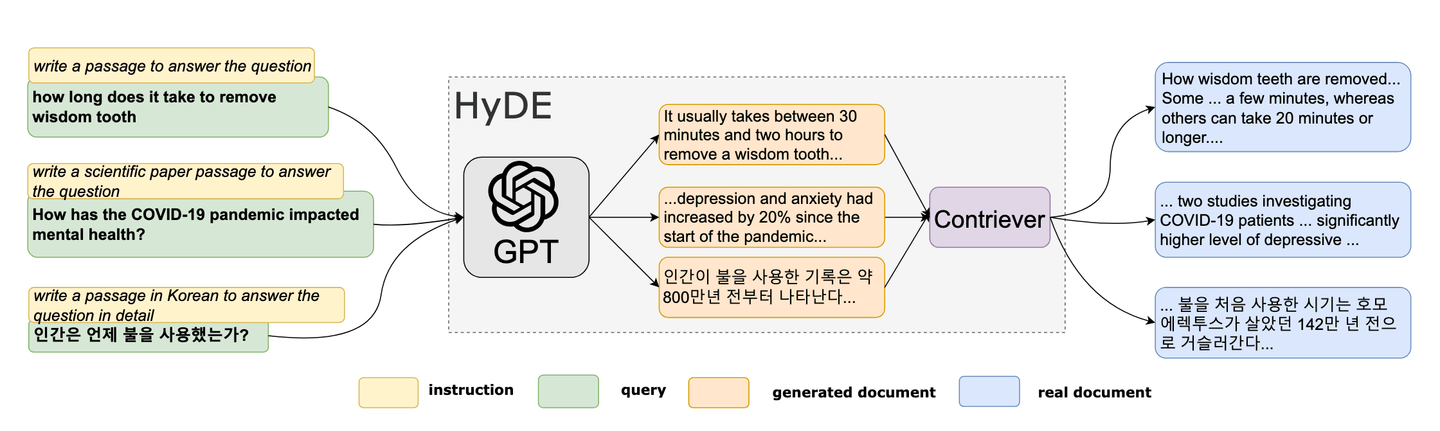
Referenz: HyDE-Papier [6]
# Erstellung hypothetischer Dokumente
Als erster Schritt nehmen wir eine Abfrage und verwenden sie, um ein hypothetisches Dokument zu generieren. Es könnte so einfach generiert werden, indem man das LLM auffordert, "Ein Dokument zu erstellen, das diese Frage beantwortet", wie wir gleich im Beispiel sehen werden.
# Berechnung der Einbettung
Wir können jedes Modell oder jeden Dienst verwenden - MyScale bietet auch seine eigene EmbedText()-Methode an -, um diese Einbettungen zu berechnen. Sobald diese (hypothetische Abfrage-)Einbettungen verfügbar sind, können wir sie verwenden, um die Vektordatenbank abzufragen.
Sobald wir den ähnlichsten Text zur hypothetischen Abfrage erhalten haben, geben wir ihn zusammen mit der (ursprünglichen) Abfrage an das LLM zur Generierung der Antwort weiter.
# Beispiel für HyDE
Beispielsweise werden einige Einbettungen in der Tabelle DocEmbeddings in MyScale gespeichert. Wir können sie - sagen wir mit der Kosinusähnlichkeit - für die 10 ähnlichsten Dokumente abfragen, wie folgt:
Schritt 1: Generierung hypothetischer Dokumente
Als erster Schritt nehmen wir die Abfrage und verwenden sie, um das hypothetische Dokument mit Hilfe des GPT-4 (mini)-Modells von OpenAI zu generieren (für die meisten Aufgaben ist GPT4-mini gut genug und spart Geld).
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Erstellen Sie ein Dokument, das die Frage beantwortet:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
Jetzt haben wir diese Funktion, sodass wir sie verwenden können, um hypothetische Dokumente basierend auf unseren Abfragen zu generieren.
Schritt 2: Berechnung der Einbettungen
Um die Einbettungen zu berechnen, verwenden wir die integrierte EmbedText() von MyScale, um die Einbettungen direkt zu berechnen.
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("Was war die von Levin vorgeschlagene Lösung für das Problem der Bauern?")
parameters = {'sampleString': hypoDoc, 'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
Schritt 3: Verwendung der Einbettung zur Abfrage der Vektordatenbank
Jetzt haben wir die Einbettung in der input_embedding, wir können sie mit den bereits in einer Tabelle (DocEmbeddings in diesem Fall) gespeicherten Vektoren mithilfe der einfachen SQL-Abfrage vergleichen.
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
Wir können es in Python ausführen und als DataFrame anzeigen.
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
Und es gibt die relevantesten Dokumente zurück:

HyDE-Ergebnisse

# Fazit
RAG ist ein leistungsstarkes und kostengünstiges Werkzeug, das die Fähigkeiten von LLMs verbessert, hat jedoch auch seine Grenzen. In diesem Blog-Beitrag haben wir uns auf die Verbesserung von Abfragen als Teil des RAG-Prozesses konzentriert. Wir haben verschiedene Techniken wie Umformulierung (oft unter Verwendung von LLMs), Abfragezerlegung, Optimierung der Qualität von Einbettungen und HyDE untersucht. Obwohl diese Methoden wertvoll sind, stellen sie nur einen Aspekt der RAG-Pipeline dar. Es gibt weitere Möglichkeiten, den gesamten RAG-Generierungsprozess zu verbessern. Im nächsten Beitrag werden wir uns mit Chunking-Strategien befassen und besprechen, wie Daten je nach Anwendungsfall in verschiedene Typen aufgeteilt werden können.
# Referenzen
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP. https://arxiv.org/abs/2305.14283
- Anand, A., V, V., Setty, V., & Anand, A. (2023). Context Aware Query Rewriting for Text Rankers using LLM. ArXiv. https://arxiv.org/abs/2308.16753
- Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. ICML, 2023.
- Muennighoff, N., Tazi, N., Magne, L., & Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. https://arxiv.org/abs/2210.07316
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. ArXiv. https://arxiv.org/abs/2212.10496



