
Große Sprachmodelle (LLMs) haben die Art und Weise revolutioniert, wie wir auf Informationen zugreifen und sie verstehen. Diese fortschrittlichen KI-Systeme werden mit riesigen Datenmengen trainiert, was es ihnen ermöglicht, Muster und Bedeutungen in der Sprache zu erkennen. Durch das Verständnis von Wörtern im Kontext erleichtern sie das Erkunden von Ideen, das Lernen neuer Dinge und das schnelle und effiziente Finden von Antworten. LLMs gestalten eine neue Ära in der Art und Weise, wie wir mit Informationen im Alltag interagieren und sie nutzen.
Frühere traditionelle LLMs basierten ausschließlich auf dem bereitgestellten Wissen aus ihren statischen Trainingsdaten. Diese Einschränkung führte oft zu Halluzinationen, bei denen das Modell falsche oder erfundene Informationen generierte, aufgrund veralteter oder unvollständiger Daten. Um diese Probleme zu erkennen, wurde das Konzept der Retrieval-Augmented Generation (RAG) eingeführt.
# Retrieval-Augmented Generation (RAG)
Die Idee hinter Retrieval-Augmented Generation (RAG) (opens new window) war es, LLMs eine zuverlässige Datenbank zur Verfügung zu stellen, um die Qualität ihrer Antworten zu verbessern. Anstatt sich ausschließlich auf die Informationen zu verlassen, die sie während des Trainings gelernt haben, ermöglicht RAG LLMs den Zugriff auf Echtzeitdaten, indem sie eine Vektordatenbank (opens new window) wie MyScale (opens new window) als Wissensbasis verwenden.
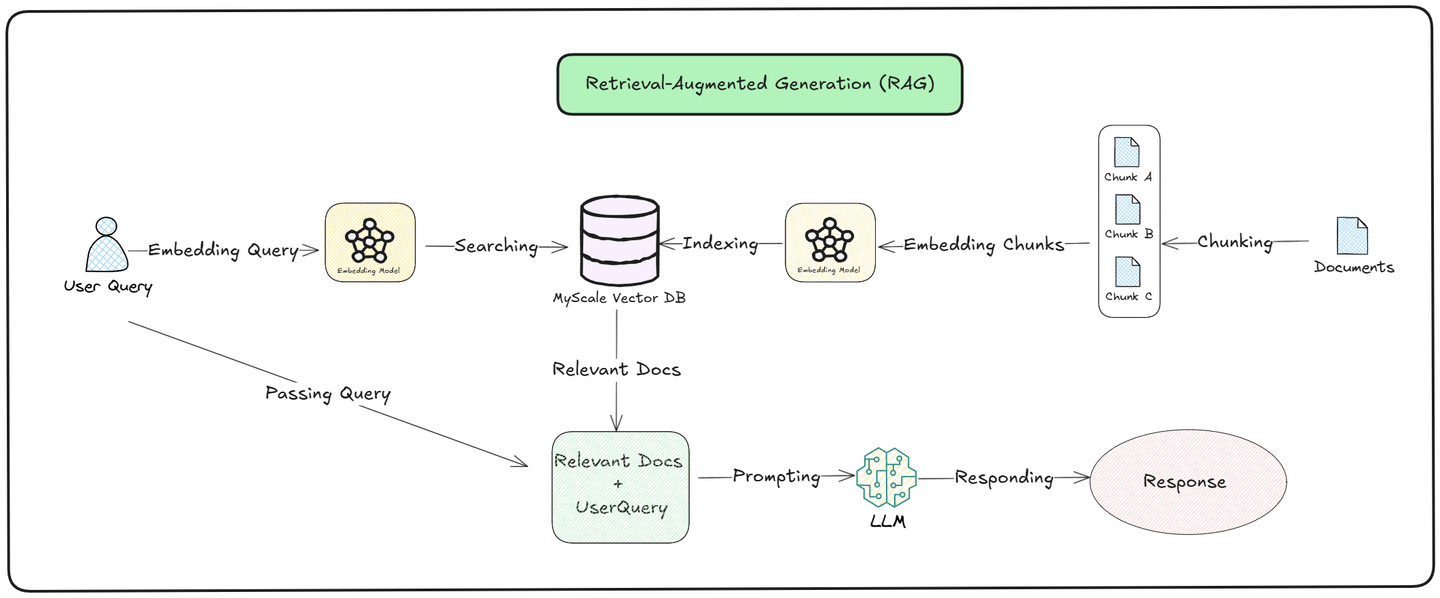
Wie in der obigen Abbildung zu sehen ist, wird der Abfrageprozess in zwei Teile unterteilt: Abruf (opens new window) und Generierung: (opens new window)
Abruf: Das Modell durchsucht eine externe Wissensdatenbank nach relevanten Dokumenten. Es wandelt die Anfrage des Benutzers in einen Vektor um und vergleicht ihn mit den gespeicherten Daten. Die ähnlichsten Dokumente werden abgerufen und basierend auf ihrer Relevanz zur Anfrage eingestuft, um sicherzustellen, dass das Modell genaue und aktuelle Informationen zieht.
Generierung: Nachdem die relevanten Dokumente abgerufen wurden, verwendet das Modell sowohl die abgerufenen Informationen als auch sein vortrainiertes Wissen, um eine Antwort zu erstellen. Es kombiniert die neu gefundenen Daten mit dem, was es bereits weiß, um eine Antwort zu generieren, die kontextuell genau und relevant für die Frage des Benutzers ist.
Zweifellos verbessert RAG die Genauigkeit und Qualität der Antworten. Allerdings funktioniert seine Pipeline statisch. Jedes Mal, wenn ein Benutzer eine Anfrage stellt, wird derselbe Prozess befolgt: Relevante Informationen werden aus der Vektordatenbank abgerufen und dem LLM zur Generierung einer Antwort übergeben. Diese Konsistenz gewährleistet Zuverlässigkeit, schränkt jedoch die Fähigkeit des Systems ein, sich dynamisch an spezifische Kontexte oder Szenarien anzupassen.
Um die Grenzen der statischen Pipeline von RAG zu überwinden, wurden neue Methoden wie ReACT (Reasoning and Acting) (opens new window) und Agenten (opens new window) eingeführt. Diese Werkzeuge helfen Systemen, besser auf Benutzeranfragen zu reagieren, indem sie:
- Logisches Denken
- Entscheidungsfindung
- Aufgabenausführung
hinzufügen.
Sie sind die Bausteine für fortschrittliche Systeme wie Agentic RAG, die logisches Denken mit einfachen Aktionen kombinieren, um die Genauigkeit und Flexibilität zu erhöhen.
# Was ist ReACT
ReACT, was "Reasoning and Acting" bedeutet, ist ein Durchbruch in der Funktionsweise von LLMs. Im Gegensatz zu traditionellen Modellen, die schnelle Antworten geben, hilft ReACT der KI, Probleme Schritt für Schritt zu durchdenken. Dieser Ansatz, der als Chain-of-Thought (CoT) bezeichnet wird, ermöglicht es Modellen, komplexe Aufgaben effektiver zu lösen.
In einem Forschungsbericht von 2022 zeigten Yao und sein Team, wie die Kombination von logischem Denken mit Handlungen die KI intelligenter machen kann. Traditionelle Modelle haben oft Schwierigkeiten mit komplizierten Problemen, aber ReACT ändert das. Es hilft der KI, innezuhalten, kritisch zu denken und bessere Lösungen zu entwickeln.
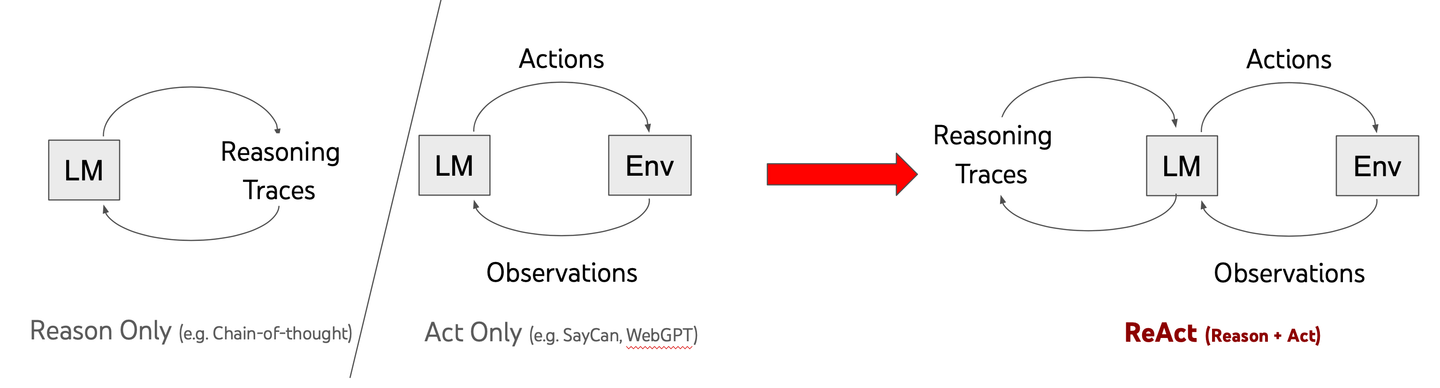
Der entscheidende Unterschied liegt im Ansatz zur Problemlösung. Anstatt hastig zu einer Antwort zu kommen, zerlegen ReACT-gestützte Modelle Herausforderungen methodisch. Dies macht sie anpassungsfähiger und zuverlässiger, wenn es darum geht, reale Probleme zu bewältigen.
Indem es der KI beigebracht wird, vor dem Handeln zu denken, erweitert ReACT die Grenzen dessen, was künstliche Intelligenz leisten kann. Es geht nicht nur darum, Informationen zu haben – es geht darum, diese Informationen intelligent zu nutzen.
# Wie ReACT funktioniert
ReACT verbessert die Fähigkeiten von LLMs, indem es einen systematischen Denkprozess mit umsetzbaren Schritten integriert. Der Rahmen funktioniert in den folgenden Phasen:

Abfrageanalyse: Das Modell beginnt damit, die Anfrage des Benutzers in handhabbare Komponenten zu zerlegen.
Chain of Thought Reasoning: Das LLM denkt Schritt für Schritt nach, analysiert jede Komponente und bestimmt die erforderlichen Aktionen. Beispielsweise kann es Informationen abrufen, Daten überprüfen oder mehrere Quellen logisch kombinieren.
Aufgabenausführung: Basierend auf seinem Denken führt das Modell Aktionen aus, wie z.B. die Interaktion mit externen Werkzeugen, das Abrufen spezifischer Daten oder die Neubewertung der Anfrage, wenn neue Informationen verfügbar werden.
Iterative Verbesserung: ReACT kann sein Denken verfeinern, während es die Schritte durchläuft, und sich dynamisch basierend auf Zwischenresultaten anpassen.
Dieses schrittweise Denken ähnelt der Art und Weise, wie Menschen komplexe Probleme lösen, und stellt sicher, dass die endgültige Antwort gut durchdacht und kontextuell relevant ist. Wenn beispielsweise eine Anfrage lautet: "Was sind die Hauptunterschiede zwischen ReACT und Agenten?", identifiziert das Modell zunächst die Komponenten (z.B. Definition von ReACT, Definition von Agenten) und denkt dann sequenziell darüber nach, bevor es eine vollständige Antwort synthetisiert.
# Einführung von Agenten
Während ReACT sich auf das Denken innerhalb des LLM konzentriert, übernehmen Agenten die Rolle der Ausführung spezifischer Aufgaben außerhalb des Modells. Agenten sind autonome Einheiten, die auf Anweisungen des LLM reagieren und es dem System ermöglichen, mit externen Werkzeugen, APIs, Datenbanken oder sogar komplexen mehrstufigen Arbeitsabläufen zu interagieren.
# Wie Agenten funktionieren
- Aufgabenidentifikation: Das LLM, oft geleitet durch das ReACT-Denken, bestimmt, welcher Agent für eine gegebene Aufgabe benötigt wird. Beispielsweise könnte eine Anfrage zu aktuellen Wetterbedingungen einen Datenabrufagenten aktivieren, um Echtzeit-Wetterupdates abzurufen.
- Ausführung: Der ausgewählte Agent führt die Aufgabe aus. Dies könnte das Abfragen einer Datenbank, das Scrapen von Webinhalten, das Aufrufen einer API oder das Durchführen von Berechnungen umfassen.
- Feedback-Schleife: Sobald die Aufgabe abgeschlossen ist, gibt der Agent das Ergebnis an das LLM zurück, um weiteres Denken oder die Generierung einer Antwort zu ermöglichen.
- Verkettung mehrerer Agenten: In komplexeren Szenarien können mehrere Agenten in einer Sequenz orchestriert werden. Beispielsweise könnte ein Agent Rohdaten abrufen, ein anderer Agent diese verarbeiten und ein dritter Agent das endgültige Ergebnis visualisieren oder formatieren.
# Agenten und Modularität
Agenten sind modular gestaltet, was bedeutet, dass sie für verschiedene Anwendungen angepasst werden können. Beispiele sind:
- Abrufagenten: Abrufen von Daten aus Vektordatenbanken oder Wissensgraphen.
- Zusammenfassungsagenten: Verdichten abgerufener Informationen in Schlüsselpunkte.
- Berechnungsagenten: Bearbeiten von Aufgaben, die Berechnungen oder Datenumwandlungen erfordern.
- API-Interaktionsagenten: Integration mit externen Diensten, um Echtzeit-Updates abzurufen.
Dieser modulare Ansatz ermöglicht Flexibilität und Skalierbarkeit, da neue Agenten hinzugefügt werden können, um spezifische Anforderungen zu erfüllen.
# Was ist Agentic RAG
Agentic RAG kombiniert die Denkfähigkeiten von ReACT mit der Ausführungskraft von Agenten und schafft ein dynamisches und anpassungsfähiges System. Im Gegensatz zu traditionellem RAG, das einer festen Pipeline folgt, führt Agentic RAG Flexibilität ein, indem es ReACT verwendet, um Agenten dynamisch basierend auf dem Kontext der Benutzeranfrage zu orchestrieren. Dies ermöglicht es dem System, nicht nur Informationen abzurufen und zu generieren, sondern auch informierte Aktionen basierend auf dem Kontext, sich entwickelnden Zielen und den Daten, mit denen es interagiert, zu ergreifen.
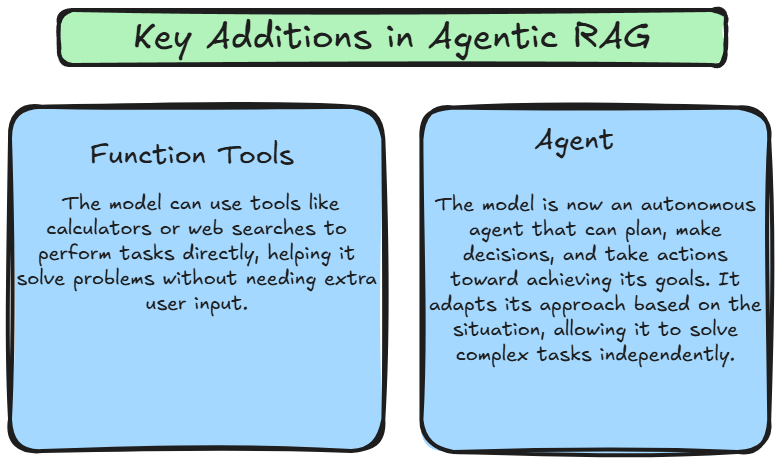
Diese Fortschritte machen Agentic RAG zu einem weitaus leistungsfähigeren und flexibleren Rahmen. Das Modell ist nicht mehr darauf beschränkt, passiv auf Benutzeranfragen zu reagieren; stattdessen kann es aktiv planen, ausführen und seinen Ansatz anpassen, um Probleme unabhängig zu lösen. Dies ermöglicht es dem System, komplexere Aufgaben zu bewältigen, sich dynamisch an neue Herausforderungen anzupassen und kontextuell genauere Antworten zu liefern.
# Wie Agentic RAG funktioniert
Die Schlüsselinnovation in Agentic RAG liegt in seiner Fähigkeit, autonom Werkzeuge zu nutzen, Entscheidungen zu treffen und seine nächsten Schritte zu planen. Die Pipeline folgt diesen Kernphasen:
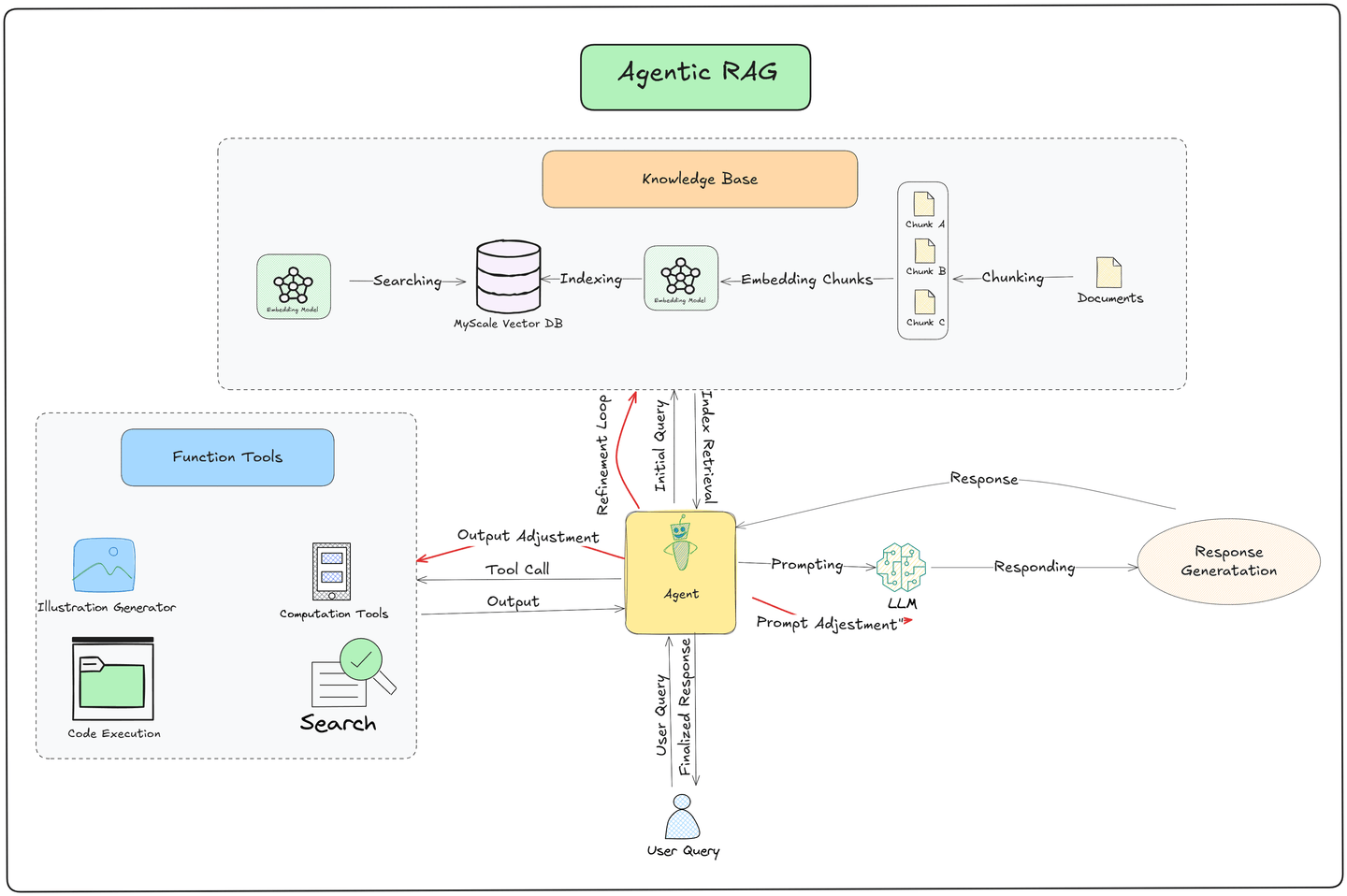
- Einreichung der Benutzeranfrage:
- Der Prozess beginnt mit der Einreichung einer Anfrage durch den Benutzer an das System. Diese Anfrage fungiert als Auslöser für die Pipeline.
- Datenabruf aus einer Vektordatenbank:
- Ein Agent durchsucht eine Vektordatenbank, in der Dokumente als Einbettungen gespeichert sind, um einen effizienten und schnellen Abruf relevanter Informationen zu gewährleisten.
- Wenn die abgerufenen Daten unzureichend sind, verfeinert der Agent die Anfrage und führt zusätzliche Abrufversuche durch, um bessere Ergebnisse zu erzielen.
- Externe Datenbeschaffung mit Funktionstools:
- Wenn die Vektordatenbank nicht über die erforderlichen Informationen verfügt, verwendet der Agent Funktionstools, um Echtzeitdaten aus externen Quellen wie APIs, Websuchmaschinen oder proprietären Datenströmen zu sammeln. Dies stellt sicher, dass das System aktuelle und kontextuell relevante Informationen bereitstellt.
- Generierung der Antwort durch das große Sprachmodell (LLM):
- Die abgerufenen Daten werden an das LLM übergeben, das sie synthetisiert, um eine detaillierte, kontextbewusste Antwort zu generieren, die auf die Anfrage zugeschnitten ist.
- Agentengetriebene Verfeinerung:
- Nachdem das LLM eine Antwort produziert hat, verfeinert der Agent sie weiter auf Genauigkeit, Relevanz und Kohärenz, bevor sie dem Benutzer übergeben wird.
# Vergleich: Agentic RAG vs RAG
Hier ist die Vergleichstabelle.
| Merkmal | RAG (Retrieval-Augmented Generation) | Agentic RAG |
|---|---|---|
| Aufgabenbearbeitung | Ruft relevante Informationen aus externen Quellen (z.B. Datenbanken, Dokumente) ab, bevor Antworten generiert werden. | Erweitert RAG durch Hinzufügen von Denken und Handlungsfähigkeiten, die eine aktive Interaktion mit der Umgebung und ein Feedback-Lernen ermöglichen. |
| Umgebungsinteraktion | Ruft Daten aus externen Quellen ab. | Interagiert aktiv mit externen Umgebungen (APIs, Datenquellen) und passt sich basierend auf Feedback an. |
| Denken | Kein explizites Denken; verlässt sich auf den Abruf, um Kontext bereitzustellen. | Explizite Denkprozesse leiten die Entscheidungsfindung und Aufgabenerfüllung. |
| Feedback-Schleife | Enthält keine Feedback-Schleifen zum Lernen. | Integriert Feedback aus der Umgebung, um Denken und Handlungen zu verfeinern. |
| Autonomie | Passiv; das System reagiert nur nach dem Abruf von Daten. | Aktive Autonomie im Denken und Handeln, trifft Entscheidungen und lernt dynamisch. |
| Anwendungsfall | Ideal für Aufgaben, die kontextuelle Abrufe erfordern (z.B. Fragen beantworten). | Geeignet für Aufgaben, die sowohl Denken als auch Interaktion mit externen Systemen erfordern (z.B. Entscheidungsfindung, Planung). |
# Fazit
Zusammenfassend lässt sich sagen, dass Agentic RAG einen bedeutenden Fortschritt im Bereich der KI darstellt. Durch die Kombination der Leistungsfähigkeit großer Sprachmodelle mit der Fähigkeit, autonom zu denken und Informationen abzurufen, bieten Agentic RAGs ein neues Maß an Intelligenz und Anpassungsfähigkeit. Während sich die KI weiterentwickelt, werden Agentic RAGs eine zunehmend wichtige Rolle in verschiedenen Branchen spielen und die Art und Weise, wie wir arbeiten und mit Technologie interagieren, transformieren.
Um das Potenzial von Agentic AI vollständig auszuschöpfen, ist eine robuste und effiziente Vektordatenbank unerlässlich, wie die MyScale Vektordatenbank (opens new window), die hauptsächlich entwickelt wurde, um den anspruchsvollen Anforderungen großangelegter KI-Anwendungen gerecht zu werden. Mit ihren fortschrittlichen Indizierungstechniken und optimierten Abfrageverarbeitungsfähigkeiten ermöglicht MyScale Agentic RAG-Systemen, relevante Informationen abzurufen und qualitativ hochwertige Antworten schnell zu generieren. Die Nutzung der Leistungsfähigkeit von MyScale kann das volle Potenzial von Agentic AI freisetzen und Innovationen vorantreiben.