
Retrieval augmented generation (RAG) (opens new window) war ein großer Fortschritt in der KI, der die Art und Weise veränderte, wie Chatbots (opens new window) mit Benutzern interagieren. Durch die Kombination von abrufbasierten Methoden mit generativer KI ermöglichte RAG Chatbots, Echtzeitdaten aus großen externen Quellen abzurufen und genaue und relevante Antworten zu generieren. Diese Innovation vereinfachte die Entwicklung von Chatbots und machte sie effizienter, während sie sicherstellte, dass sie sich an sich ändernde Daten anpassen können, was in Bereichen wie dem Kundensupport (opens new window) entscheidend ist, wo zeitnahe und präzise Informationen wichtig sind.
Traditionelle RAG-Systeme hatten jedoch Schwierigkeiten, in schnelllebigen Szenarien wie der Terminvereinbarung oder der Bearbeitung von Echtzeitanfragen schnelle Entscheidungen zu treffen. Hier kommt das agentic RAG ins Spiel, das diese Herausforderung durch Hinzufügen von intelligenten Agenten (opens new window) angeht, die Daten eigenständig abrufen, überprüfen und darauf reagieren können. Im Gegensatz zum herkömmlichen RAG, das hauptsächlich Daten abruft und Antworten generiert, ermöglicht das agentic RAG KI-Systemen, proaktiv Entscheidungen in Echtzeit zu treffen. Dies macht es ideal für komplexe Situationen wie medizinische Diagnosen oder Kundenservice, wo schnelle und genaue Entscheidungsfindung unerlässlich ist.
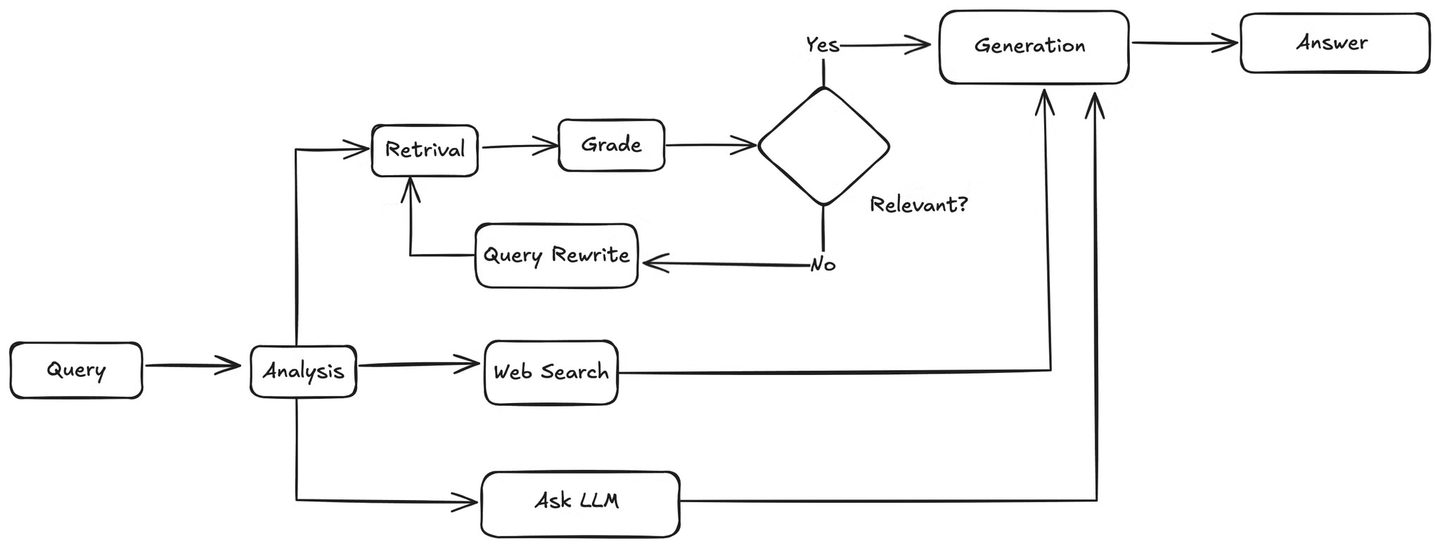
Genau das werden wir in diesem Tutorial umsetzen: ein intelligentes, agentic Frage-Antwort-System (Q&A), das dynamisch entscheidet, ob es eine Wissensdatenbank (opens new window) verwendet oder eine Internetsuche basierend auf der Benutzeranfrage durchführt. Dazu müssen wir mehrere Tools integrieren:
- LangChain (opens new window): Dieses Tool verwaltet die Interaktion des Systems mit dem Sprachmodell und den anderen Tools. Basierend auf der Anfrage hilft es dem System dabei, zu entscheiden, ob die Wissensdatenbank oder das Internet durchsucht werden soll.
- MyScaleDB (opens new window): MyScaleDB dient als unsere Vektordatenbank, in der Embeddings (opens new window) gespeichert werden, die die Wissensdatenbank repräsentieren. Es wird verwendet, um effizient nach gespeicherten Daten zu suchen, wenn die Anfrage mit der Wissensdatenbank zusammenhängt.
- VoyageAI (opens new window): Es stellt verschiedene Embedding-Modelle bereit, um Embeddings aus Text zu generieren, die zur Codierung von Wissen für eine bessere Suche und Übereinstimmung verwendet werden.
- Tavily (opens new window): Dieses Tool ruft Echtzeitinformationen aus dem Internet ab, wenn die Frage des Benutzers aktuelle oder externe Daten erfordert, um sicherzustellen, dass das System immer genaue Antworten liefert.
# Einrichten der Umgebung
Zunächst müssen Sie die erforderlichen Bibliotheken installieren und die Pakete herunterladen, die wir für die Entwicklung dieser KI-Anwendung benötigen, indem Sie den folgenden Befehl ausführen:
pip install -U langchain-google-genai langchain-voyageai langchain-core langchain-community
Der nächste Schritt besteht darin, die für die Verwendung von Gemini (opens new window) (Google Generative AI) und Tavily Search (opens new window) erforderlichen API-Schlüssel einzurichten. Für MyScale können Sie diese Schnellstartanleitung (opens new window) befolgen.
import os
# MyScale API-Zugangsdaten
os.environ["MYSCALE_HOST"] = "msc-24862074.us-east-1.aws.myscale.com"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "Ihr_MyScale_Benutzername"
os.environ["MYSCALE_PASSWORD"] = "Ihr_MyScale_Passwort"
# Tavily API-Schlüssel
os.environ["TAVILY_API_KEY"] = "Ihr_Tavily_API-Schlüssel"
# Google API-Schlüssel für Gemini
os.environ["GOOGLE_API_KEY"] = "Ihr_Google_API-Schlüssel"
Ersetzen Sie die Platzhalter im obigen Code durch Ihre tatsächlichen API-Schlüssel.
Hinweis: Alle diese Tools bieten kostenlose Versionen zum Testen der Funktionalitäten an. Erstellen Sie also gerne ein Konto auf den entsprechenden Plattformen und erhalten Sie den API-Schlüssel.
# Lesen und Aufteilen des Textes
Der nächste Schritt besteht darin, die Daten für die Wissensdatenbank vorzubereiten. Für dieses Tutorial verwenden wir einen Datensatz, der grundlegende Informationen über MyScaleDB enthält. Die Daten werden in handhabbare Abschnitte aufgeteilt, um sie für das System einfacher zu verarbeiten und relevante Informationen effizient abzurufen.
from langchain_text_splitters import CharacterTextSplitter
with open("myscaledb_summary.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator="\\n\\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
Der CharacterTextSplitter teilt den Text basierend auf der Zeichenanzahl in kleinere, handhabbare Abschnitte auf.
Hinweis: Für diesen Blog wird eine txt-Datei über MyScale verwendet. Sie können beliebige Daten verwenden.
# Hinzufügen von Daten zur Wissensdatenbank
Nachdem die Daten aufgeteilt wurden, generieren wir die Embeddings für die Textabschnitte und speichern sie in der Wissensdatenbank. Dazu verwenden wir VoyageAIEmbeddings, um Embeddings für die Textabschnitte zu generieren, und speichern sie in MyScaleDB.
from langchain_voyageai import VoyageAIEmbeddings
from langchain_community.vectorstores import MyScale
embeddings = VoyageAIEmbeddings(
voyage_api_key="Ihr_VoyageAI_API-Schlüssel",
model="voyage-law-2"
)
vectorstore = MyScale.from_documents(
texts,
embeddings,
)
retriever = vectorstore.as_retriever()
Die Methode .from_documents (opens new window) nimmt normalerweise eine Liste von Dokumenten und ein Modell entgegen, um diese Dokumente in Vektor-Embeddings zu transformieren. Diese Methode speichert automatisch die Embeddings in der Wissensdatenbank.
# Erstellen von Tools für das Modell
In LangChain sind Tools (opens new window) Funktionalitäten, die der Agent nutzen kann, um spezifische Aufgaben jenseits der Textgenerierung durchzuführen. Durch Ausstattung des Modells mit Tools kann es mit externen Datenquellen interagieren, Echtzeitinformationen abrufen und genauere und relevantere Antworten auf Benutzeranfragen liefern.
In dieser Anwendung entwickeln wir zwei verschiedene Tools für den Agenten, um zu entscheiden, welches Tool basierend auf der Benutzeranfrage verwendet werden soll:
- Wenn die Anfrage mit MyScaleDB oder MyScale zusammenhängt, verwendet der Agent das Retriever-Tool, um Informationen aus unserer benutzerdefinierten Wissensdatenbank abzurufen.
- Für andere Anfragen, die aktuelle Informationen erfordern, verwendet der Agent das Tavily-Suchtool, um Live-Internetsuchen durchzuführen.
# Retriever-Tool für MyScale-Inhalte
Verwenden wir den oben erstellten MyScaleDB-Retriever und die Methode create_retriever_tool, um diesen Retriever in ein Tool umzuwandeln.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_myscale_content",
"Wird verwendet, um Informationen über MyScaleDB zurückzugeben.",
)
# Tavily-Suchtool für Live-Internetdaten
LangChain bietet eine integrierte Unterstützung zur Verwendung des Tavily-Suchtools (opens new window) über das Community-Paket.
from langchain_community.tools import TavilySearchResults
tool = TavilySearchResults(
max_results=5,
search_depth="advanced",
include_answer=True,
name="live_search",
description="Wird verwendet, um die neuesten Nachrichten aus dem Internet zu suchen.",
)
tools = [retriever_tool, tool]
Das TavilySearchResults-Tool ist so konfiguriert, dass es die neuesten Nachrichten mit maximal 5 Ergebnissen und erweiterter Suche durchsucht, einschließlich direkter Antworten. Am Ende werden beide Tools einer Liste hinzugefügt.
Hinweis: Die Beschreibungen jedes Tools sind sehr wichtig, da sie dem Agenten dabei helfen, zu entscheiden, welches Tool verwendet werden soll und zu welchem Zweck.
# Workflow der Anwendung definieren
Jetzt, da die erforderlichen Tools definiert wurden, ist der nächste Schritt, den vollständigen Workflow der agentic RAG-Anwendung festzulegen, einschließlich der Schritte und Überprüfungen, die durchgeführt werden.
Zuerst analysiert der Agent die Benutzeranfrage, um die Absicht und den Kontext zu verstehen. Anschließend entscheidet er, ob die Wissensdatenbank oder eine Websuche verwendet werden soll. Wenn eine Websuche erforderlich ist, verwendet er das Websuchtool, um Ergebnisse zu sammeln, und gibt diese Ergebnisse an das LLM weiter, das basierend auf den abgerufenen Informationen eine Antwort auf die Benutzeranfrage generiert.
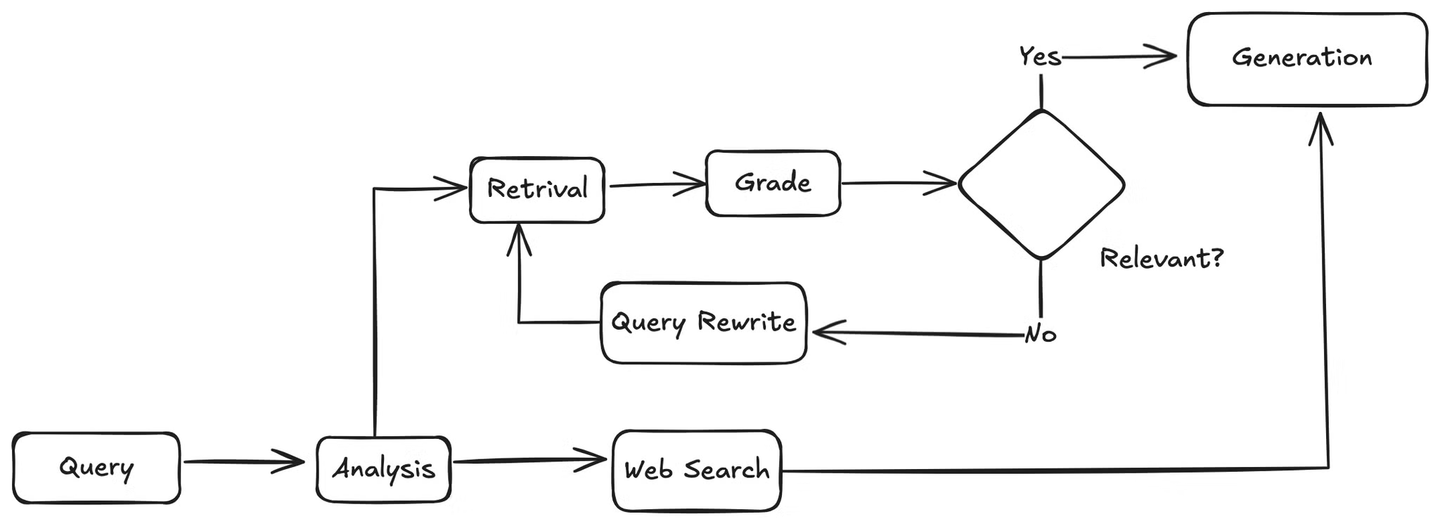
Wenn die Anfrage mit der Wissensdatenbank zusammenhängt, ruft der Agent relevante Abschnitte aus der Wissensdatenbank ab und übergibt sie an eine Funktion, die diese Dokumente mit der Benutzeranfrage abgleicht, um deren Relevanz zu überprüfen. Wenn die Dokumente relevant sind, sendet der Agent sie an das LLM zur Generierung der Antwort. Wenn sie nicht relevant sind, ruft er eine Methode auf, um die Benutzeranfrage neu zu formulieren. Die neu formulierte Anfrage wird dann an den Retriever zurückgesendet, und der Vorgang wird wiederholt, bis relevante Informationen gefunden werden.
# Agent und Zustand definieren
Der erste Schritt besteht darin, eine Klasse AgentState zu definieren, die verwendet wird, um den Zustand der Antwort während des gesamten Prozesses zu verfolgen.
# Imports aus der Standardbibliothek
from typing import Literal, Annotated, Sequence, TypedDict
# Langchain Core Imports
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Langchain und externe Tools
from langchain import hub
from langchain_google_genai import ChatGoogleGenerativeAI
# LangGraph Imports
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
Nun definieren wir den Agenten, der die Benutzeranfrage analysiert und entscheidet, ob die Wissensdatenbank oder eine Websuche verwendet werden soll. Das Gemini-Modell wird verwendet, um das richtige Tool auszuwählen und basierend auf der Anfrage eine Antwort zu generieren.
def agent(state):
messages = state["messages"]
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}
# Bewertung der abgerufenen Dokumente
Der Agent stellt sicher, dass die abgerufenen Dokumente relevant zur Benutzeranfrage sind. Die Funktion grade_documents analysiert die abgerufenen Dokumente, um deren Relevanz zu überprüfen. Wenn die abgerufenen Dokumente relevant sind, entscheidet der Agent, eine Antwort zu generieren. Andernfalls formuliert er die Benutzeranfrage neu.
def grade_documents(state) -> Literal["generate", "rewrite"]:
# Datenmodell für die Bewertung
class Grade(BaseModel):
"""Binäre Bewertung zur Überprüfung der Relevanz."""
binary_score: str = Field(description="Relevanzbewertung 'ja' oder 'nein'")
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
llm_with_tool = model.with_structured_output(Grade)
# Prompt
prompt = PromptTemplate(
template="""Sie sind ein Bewerter, der die Relevanz eines abgerufenen Dokuments für eine Benutzerfrage bewertet.
Hier ist das abgerufene Dokument:
{context}
Hier ist die Benutzerfrage: {question}
Wenn das Dokument Schlüsselwörter oder eine semantische Bedeutung enthält, die mit der Benutzerfrage zusammenhängen, bewerten Sie es als relevant.
Geben Sie eine binäre Bewertung 'ja' oder 'nein' ab, um anzuzeigen, ob das Dokument relevant zur Frage ist.""",
input_variables=["context", "question"],
)
# Kette
chain = prompt | llm_with_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "ja":
return "generate"
else:
return "rewrite"
# Benutzeranfragen neu formulieren
Wenn die abgerufenen Dokumente nicht relevant sind, formuliert der Agent die Benutzeranfrage neu, um die abgerufenen Ergebnisse aus der Wissensdatenbank zu verbessern.
def rewrite(state):
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f"""
Betrachten Sie die Eingabe und versuchen Sie, die zugrunde liegende semantische Absicht / Bedeutung zu erkennen.
Hier ist die ursprüngliche Frage:
-------
{question}
-------
Formulieren Sie eine verbesserte Frage:""",
)
]
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
response = model.invoke(msg)
return {"messages": [response]}
# Generieren der endgültigen Antwort
Sobald bestätigt wurde, dass die abgerufenen Dokumente relevant sind, sendet der Agent die abgerufenen Dokumente zur Generierung der endgültigen Antwort.
def generate(state):
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
# Kette
rag_chain = prompt | llm | StrOutputParser()
# Ausführen
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
# Alles in den LangGraph einfügen
Wir verwenden LangGraph (opens new window), um den Workflow der Anwendung zu optimieren. Es hilft dabei, die verschiedenen Schritte, die der Agent unternehmen wird, wie die Entscheidung, ob die Wissensdatenbank oder eine Websuche verwendet werden soll, das Abrufen relevanter Informationen und das Generieren von Antworten, zu verwalten. Indem wir diese Aufgaben in Knoten organisieren und klare Verbindungen zwischen ihnen definieren, stellt LangGraph sicher, dass alles reibungslos und effizient abläuft. Es vereinfacht die Handhabung komplexer Entscheidungen und hält die Anwendung strukturiert und leicht zu warten.
Um einen Graphen zu erstellen, definieren wir die Knoten (Aktionen) und wie sie verbunden sind.
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
# Definieren Sie einen neuen Graphen
workflow = StateGraph(AgentState)
# Definieren Sie die Knoten, zwischen denen wir zyklisch wechseln werden
workflow.add_node("agent", agent) # Agent-Knoten
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # Abrufknoten
search = ToolNode([tool])
workflow.add_node("search", search) # Suchknoten
workflow.add_node("rewrite", rewrite) # Neuschreibknoten
workflow.add_node("generate", generate) # Generierungsknoten
Die add_node-Funktion fügt dem Graphen Knoten hinzu. Das erste Argument ist der Name des Knotens, das zweite ist die Funktion, die er repräsentiert.
# Kanten definieren
Kanten definieren die Übergänge zwischen den Knoten basierend auf bestimmten Bedingungen. Kanten steuern den vollständigen Ablauf der Anwendung.
# Bedingte Kante für Tools definieren
Definieren Sie zunächst eine Bedingung, die basierend auf der Benutzeranfrage bestimmt, ob der Retriever oder das Suchtool verwendet werden soll. Wenn die Anfrage "myscaledb" oder "myscale" erwähnt, verwendet der Agent den Retriever. Andernfalls verwendet er das Suchtool.
def tools_condition(state) -> Literal["retrieve", "search"]:
messages = state["messages"]
question = messages[0].content.lower()
if "myscaledb" in question or "myscale" in question:
return "retrieve"
else:
return "search"
# Kanten hinzufügen
Fügen Sie nun die Kanten zum Workflow-Graphen hinzu.
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
tools_condition,
{
"search": "search",
"retrieve": "retrieve",
},
)
workflow.add_conditional_edges(
"retrieve",
grade_documents,
)
workflow.add_edge("retrieve", "generate")
workflow.add_edge("search", "generate")
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# Kompilieren Sie den Graphen
graph = workflow.compile()
Die add_edge-Funktion definiert einen direkten Übergang von einem Knoten zu einem anderen. Die add_conditional_edges-Funktion ermöglicht es uns, Übergänge basierend auf Bedingungen festzulegen. Das erste Argument ist der Ausgangsknoten, das zweite ist die Bedingungsfunktion und das dritte ist ein Wörterbuch, das mögliche Bedingungsergebnisse auf Zielknoten abbildet.
# Visualisierung des endgültigen Graphen
Lassen Sie uns den endgültigen Graphen visualisieren, um zu sehen, wie die Knoten und Kanten verbunden sind.
from IPython.display import Image, display
try:
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# Dies erfordert einige zusätzliche Abhängigkeiten und ist optional
pass
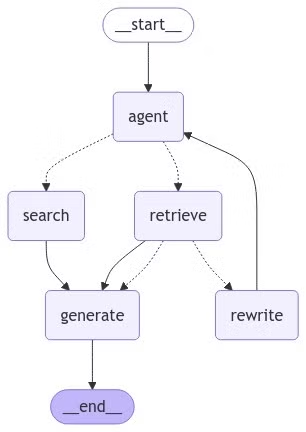
# Ausführen des Graphen
Führen Sie schließlich den Graphen aus, um unser Q&A-System in Aktion zu sehen.
inputs = {
"messages": [
("user", "Welches Modell hat OpenAI kürzlich veröffentlicht?"),
]
}
for output in graph.stream(inputs):
for value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
Es wird eine Ausgabe wie diese generiert:
OpenAI hat kürzlich ein neues generatives KI-Modell namens OpenAI o1 veröffentlicht.
Dieses Modell zeichnet sich durch seine "Reasoning"-Fähigkeiten aus, die es ihm ermöglichen,
sich selbst zu überprüfen und komplexe Probleme wie Codierung und Mathematik zu bewältigen.
Es wurde am 12. September 2024 veröffentlicht und steht ChatGPT Plus- und Team-Benutzern zur Verfügung.
Wenn die Anfrage zu MyScaleDB wie folgt gestellt wird:
inputs = {
"messages": [
("user", "Was ist MyScaleDB?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
Die Ausgabe wäre ungefähr so:
"MyScaleDB ist eine leistungsstarke, cloudbasierte Datenbank, die auf dem Open-Source-ClickHouse aufbaut
und speziell für KI- und Machine-Learning-Anwendungen entwickelt wurde. Sie unterstützt strukturierte und
unstrukturierte Daten und eignet sich daher ideal für die Verwaltung großer Datenmengen und komplexe
Analyseaufgaben."

# Fazit
Durch die Durchführung dieses Tutorials haben Sie erfolgreich ein dynamisches Q&A-System erstellt, das intelligent zwischen der Verwendung einer Wissensdatenbank und einer Live-Internetsuche basierend auf Benutzeranfragen wählt. Durch die Integration von Tools wie LangChain, MyScaleDB, VoyageAI und Tavily haben Sie einen anpassungsfähigen KI-Agenten entwickelt, der komplexe Fragen effizient bearbeiten kann. Erkunden Sie diese Tools weiter, um Ihre KI-Anwendungen weiter zu verbessern!



