
Vektordatenbanken sind explizit für die Speicherung und Verwaltung von Vektordaten konzipiert und spielen eine entscheidende Rolle in vielen KI-Anwendungen wie semantischer Textsuche und Bildsuche. Während traditionelle Termübereinstimmungs- und BM25-Algorithmen nach wie vor eine Bedeutung bei der Textsuche haben, haben kürzlich auch das weit verbreitete Elasticsearch-System Vektorsuchfähigkeiten hinzugefügt. Insbesondere hat MyScaleDB, eine Open-Source-Hochleistungs-SQL-Vektordatenbank, kürzlich auch die Volltextsuche (opens new window) eingeführt. In diesem Artikel zeigen wir, dass MyScaleDB in Bezug auf die Volltextsuchleistung mit Elasticsearch konkurriert, dabei jedoch eine geringere Latenz aufweist und 40% weniger Speicherplatz benötigt. Darüber hinaus erreicht MyScale mit der Integration der Vektorsuche eine bis zu 10-fach höhere Leistung bei nur 12% der Kosten. Mit seiner hohen Leistung, niedrigen Kosten und einer umfangreichen SQL-Umgebung auf Basis von ClickHouse erweist sich MyScaleDB als effizientes und leistungsstarkes Upgrade und als Alternative zu Elasticsearch.
# Was ist Elasticsearch
Elasticsearch ist eine verteilte, RESTful-Such- und Analyse-Engine, die auf Apache Lucene aufbaut. Es kann große Datenmengen schnell speichern, durchsuchen und analysieren und wird in Bereichen wie Log-Analysen, Anwendungssuchen, Sicherheitsanalysen und Geschäftsanalysen weit verbreitet eingesetzt.
Elasticsearch bietet folgende Vorteile:
- Leistungsstarke Suchfunktionen: Elasticsearch bietet leistungsstarke Volltextsuchfunktionen, einschließlich exakter Werte, Volltext- und Vektorsuchen sowie komplexe Abfrage-, Filter- und Aggregationsoperationen, mit denen Benutzer die gewünschten Informationen schnell und genau abrufen können.
- Umfangreiche Funktionen: Elasticsearch bietet umfangreiche Funktionen und flexible Konfigurationsoptionen wie Textanalyse, Aggregationsanalyse und geografische Suche, um eine Vielzahl von Such- und Analyseanforderungen zu erfüllen.
- Umfangreiches Ökosystem: Das Elasticsearch-Ökosystem ist umfangreich. Es umfasst verschiedene Plugins, Tools und Integrationen von Drittanbietern, die seine Funktionalität und Anwendungsszenarien erweitern und den Benutzern mehr Auswahlmöglichkeiten und Flexibilität bieten.
- Verteilte Architektur: Als verteiltes System kann Elasticsearch problemlos auf viele Knoten skaliert werden und bietet hohe Verfügbarkeit und horizontale Skalierbarkeit, was es für die Verarbeitung und Analyse großer Datenmengen geeignet macht.
- Echtzeit-Datenverarbeitung: Elasticsearch unterstützt die Indizierung und Suche von Echtzeitdaten, sodass es große Mengen von Echtzeitdaten schnell verarbeiten und sofortige Abfrageergebnisse liefern kann.
Allerdings hat Elasticsearch auch einige Nachteile, darunter:
- Steile Lernkurve: Elasticsearch hat eine relativ steile Lernkurve, insbesondere für Anfänger, die Zeit benötigen, um seine komplexen Konzepte und Verwendungsmethoden zu erfassen.
- Begrenzte Vektorabrufalgorithmen: Bis zur Version 8.13 unterstützt Elasticsearch nur begrenzt Vektorabrufalgorithmen wie Brute-Force-kNN und Approximate kNN basierend auf HNSW. Dies begrenzt seine Anwendung in komplexen Vektorabruf-Szenarien.
- Hoher Ressourcenverbrauch: Aufgrund seiner leistungsstarken Funktionen und verteilten Architektur benötigt Elasticsearch während der Laufzeit relativ hohe Ressourcen, einschließlich Speicher, CPU und Speicherplatz.
Zusammenfassend lässt sich sagen, dass Elasticsearch ein leistungsstarkes Werkzeug im Bereich der Textsuche ist. Es hat jedoch einige Nachteile in Bezug auf Benutzerfreundlichkeit, Vektorabruf und Ressourcennutzung, die seine Anwendung in komplexen KI-Such- und Analyzeszenarien einschränken.
# Bevorzugte Elasticsearch-Alternative: MyScaleDB
MyScaleDB basiert auf der Open-Source-SQL-Columnar-Storage-Datenbank ClickHouse. Es verfügt über einen selbst entwickelten Hochleistungs- und hochdatendichten Vektorindexierungsalgorithmus. Wir haben umfangreiche Forschung und Optimierung in Bezug auf seine Abruffähigkeiten und Speicher-Engines für SQL- und Vektorverbundabfragen durchgeführt, wodurch MyScaleDB das weltweit erste SQL-Vektordatenbankprodukt ist, das dedizierte Vektordatenbanken in Bezug auf umfassende Leistung und Wirtschaftlichkeit deutlich übertrifft.
# Native Kompatibilität mit SQL und Vektor
Benutzer interagieren mit MyScaleDB über SQL, was die Einstiegshürden senkt und die Lernkurve verringert, sodass sie schnell starten und sich leicht steigern können. MyScaleDB bietet ein flexibles Datenmodell und eine Abfragesprache, die Benutzer bei der Anpassung von Datenverarbeitungs- und Analysestrategien an ihre spezifischen Anforderungen unterstützt und die Anwendungsflexibilität und Ausführungseffizienz verbessert. Die Kombination von SQL und Vektoren in komplexen KI-Anwendungsszenarien bietet Entwicklern eine intuitivere und effizientere Entwicklungsmethode, was die Effizienz der Entwickler erheblich steigert.
Im Gegensatz zur domänenspezifischen Sprache (DSL) von Elasticsearch, die auf JSON-Abfragen basiert, müssen Benutzer lediglich die Vektorabruffunktion distance() beherrschen, um MyScaleDB zu verwenden. Mit diesen Informationen und ihrem vorhandenen SQL-Wissen können sie komplexe Vektorabrufabfragen entwickeln. Darüber hinaus können sie auch komplexe Analysen und Datenverarbeitungen auf Datenbankebene durchführen, um die Gesamtverarbeitungseffizienz des Anwendungssystems zu beschleunigen.
Beispiel:
-- Führen Sie eine Vektorsuche durch und geben Sie die 10 besten Ergebnisse zurück
SELECT
id, title, text
distance(vector, query_vector) as dist
FROM doc_table
ORDER BY
dist ASC
LIMIT 10;
# Ersetzen von Elasticsearch durch Volltextsuchfunktionen
In der neuesten Version hat MyScaleDB leistungsstarke Funktionen wie Volltext- und hybride Suche eingeführt, die praktische Lösungen für komplexe KI-Anforderungen und Datenherausforderungen bieten - jetzt und in Zukunft. Es enthält die Tantivy-Volltextsuchmaschinenbibliothek, die schnellen Indexaufbau, effiziente Suche und Multithreading-Unterstützung bietet. Darüber hinaus ist es sehr einfach zu bedienen, äußerst flexibel und für die schnelle Suche nach großen Textdaten sehr gut geeignet. Dies ermöglicht es Benutzern, Textdaten, die in der Datenbank gespeichert sind, schnell zu durchsuchen und den Ergebnissatz zurückzugeben, der der bestmöglichen Übereinstimmung entspricht - basierend auf den BM25-Werten.
Beispielsweise enthält die folgende Tabelle die Ergebnisse eines Tests zur Textsuchfunktion, den wir auf demselben Datensatz "wiki" (560 Millionen Datensätze) durchgeführt haben. Die P95-Abfrage-Latenz von MyScaleDB wurde signifikant reduziert, und es gibt auch eine spürbare Verringerung des Speicherbedarfs. Somit kann MyScaleDB im Kontext der Volltextsuche und in Bezug auf die Funktionalität effektiv Elasticsearch ersetzen.
| Engine | Funktion | QPS | p95 Latenz | Spitzenarbeitsspeicher |
|---|---|---|---|---|
| MyScaleDB | TextSearch | 4099.16 | 4.563ms | 2.35GB |
| ElasticSearch | match | 3907 | 8.863ms | 3.7GB |
| ElasticSearch | wildcard | 4679.16 | 5.583ms | 3.7GB |
# Übertreffen von Elasticsearch mit Vektorsuchfunktionen
MyScaleDB verwendet Vektorabruftechnologie und unterstützt verschiedene Vektorindexierungsalgorithmen, darunter MTSG, SCANN, FLAT sowie die HNSW- und IVF-Familien. Dies erfüllt die Abrufanforderungen verschiedener KI-Szenarien besser und hat einen absoluten Vorteil bei der Verarbeitung von großen hochdimensionalen Datenmengen.
Unter Verwendung eines Datensatzes im großen Maßstab (LAION 5M Vektoren, 768 Dimensionen) wurden die Leistung von MyScaleDB und Elasticsearch bei der Vektorsuche unter verschiedenen gleichzeitigen Abfrage-Threads getestet. Die Ergebnisse der Genauigkeits- und Durchsatztests sind in der folgenden Abbildung dargestellt.
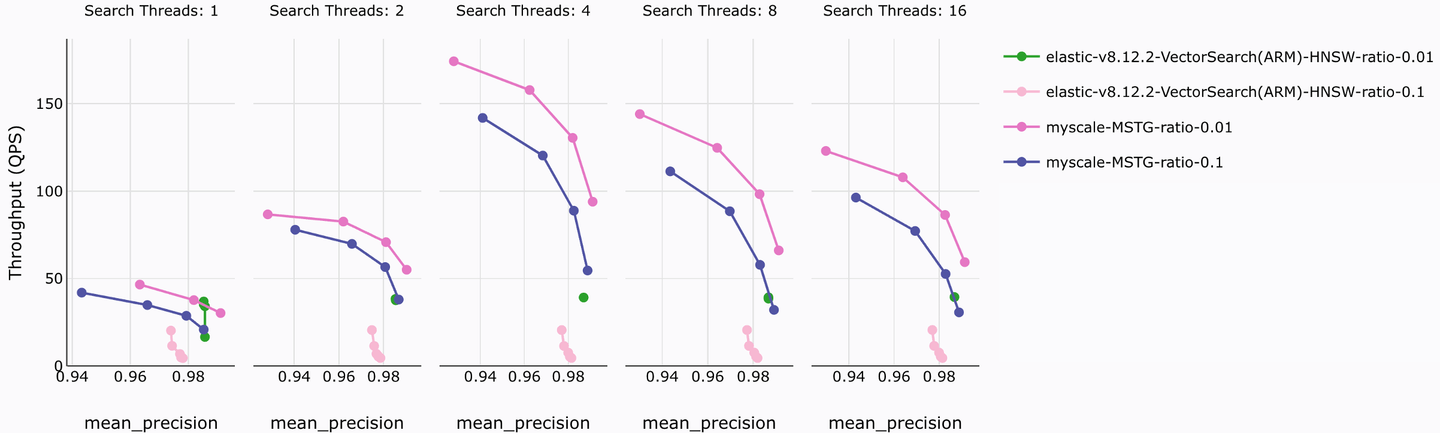
Bei diesem Test wurden zwei gängige Filterverhältnisse, 0,1 und 0,01, getestet. Eine Analyse der Ergebnisse zeigt, dass der MSTG-Index von MyScaleDB bei ähnlicher Genauigkeit eine bis zu 10-fache Verbesserung der QPS-Leistung aufweist. MyScaleDB hat ähnliche Vorteile in Bezug auf den Ressourcenverbrauch des Index, die Erstellungszeit, die Abfrage-Latenz und die Abfragekosten.
Besonders bemerkenswert ist, dass MyScaleDB SaaS nur 120 US-Dollar pro Monat kostet, um 5 Millionen Vektoren zu bedienen, während ElasticCloud mit 982 US-Dollar mehr als achtmal so teuer ist. Darüber hinaus unterstützt MyScaleDB mehrere Arten von Vektorindizes und ist in Kombination mit seiner leistungsstarken Abrufleistung und den kostengünstigen Nutzungskosten besser für Vektorabruf- und Analyseabfrage-Szenarien geeignet als Elasticsearch.
Weitere Leistungstestergebnisse finden Sie in der MyScaleDB Vector Database Benchmark (opens new window).
# Kostenoptimierte Ressourcennutzung
Wie oben beschrieben, basiert MyScaleDB auf der leistungsstarken Columnar-Datenbank ClickHouse, derzeit die schnellste und ressourceneffizienteste Open-Source-Datenbank für Echtzeitanwendungen und -analysen. Einige der fortschrittlichen Funktionen von ClickHouse haben es zu einer guten Wahl gemacht, darunter der effiziente Indexierungsmechanismus, die Datenkompressionstechnologie, die columnar Storage-Struktur, die vektorisierte Abfrageausführung und die verteilte Verarbeitungsfähigkeit.
Darüber hinaus ist die Abfrage-Engine von MyScaleDB für moderne CPUs und Speicher optimiert. Sie verwendet vektorisierte Abfrageverarbeitung und datenparallele Verarbeitungstechniken, um die Leistung von Mehrkernprozessoren voll auszuschöpfen und Datenberechnungen zu beschleunigen. Mit dem ClickHouse-Columnar-Speichermodell erreicht MyScaleDB eine effiziente Datenkompression und schnelle spaltenbasierte Operationen. Es kann nur die in der Abfrage angegebenen Spalten lesen, wodurch der Datenleseumfang reduziert, die Datenkompressionsraten verbessert und die Speicherkosten reduziert werden. Dadurch eignet es sich besonders gut für die Analyse und Verarbeitung großer Datenmengen.
Zusammenfassend lässt sich sagen, dass MyScaleDB durch die Kombination von Vektorabruftechnologie, der Volltextsuchmaschine Tantivy, den leistungsstarken Funktionen von ClickHouse, der verteilten Architektur und der optimierten Abfrage-Engine eine effiziente Verarbeitung und Analyse großer Datensätze erreicht. Es ist besonders für komplexe Datenanalysen, hybride Suche, Volltextsuche und Vektorabruf-Szenarien geeignet.
# Wie man Elasticsearch durch MyScaleDB ersetzt
Dieser Prozess umfasst Aufgaben wie Datenmodellierung, Datenmigration und Umwandlung der Abfragelogik. Weitere Informationen zum schnellen Starten eines MyScaleDB-Clusters, zum Importieren von Daten und zum Ausführen von SQL-Abfragen finden Sie im Schnellstart (opens new window) Handbuch.
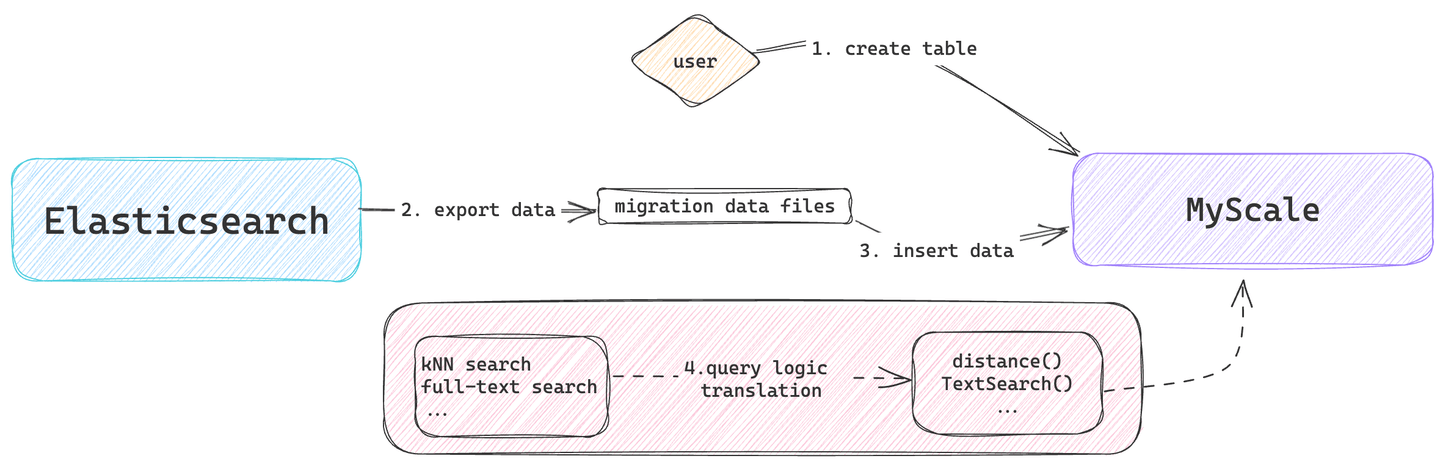
# Datenmodellierung
Die Phase der Datenmodellierung umfasst die Bestimmung der Zuordnung des Dokumentenmodells in Elasticsearch zur Tabellenstruktur in MyScaleDB. Dabei werden hauptsächlich die Spalten, Datentypen und Indextypen für die zu migrierenden Datentabellen in MyScaleDB definiert.
# Konvertierung der Datentypen
MyScaleDB ist mit allen Datentypen von ClickHouse kompatibel. Daher haben alle Feld-Datentypen in Elasticsearch entsprechende Datentypen in MyScaleDB.
Hinweis:
Der für die Vektorsuche in Elasticsearch verwendete dense_vector-Typ sollte in MyScaleDB je nach element_type auf Array(Float32) oder FixedString abgebildet werden. Darüber hinaus sollte die entsprechende Längenbeschränkung zur Spalte hinzugefügt werden.
# Definition des Vektorindex
MyScaleDB unterstützt verschiedene Arten von Vektorindizes. Wir empfehlen jedoch dringend die Verwendung von MSTG-Indizes für optimale Leistung.
Weitere Informationen zur Erstellung und Verwendung von Vektorindizes für beschleunigte Vektorsuche finden Sie im Vektorabfrage-Tutorial (opens new window).
Hier ist ein Beispiel, das den Bildindex in Elasticsearch in die Tabelle es_data_migration in MyScaleDB konvertiert:
{
"image-index": {
"mappings": {
"properties": {
"file-type": {
"type": "keyword"
},
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
}
}
}
}
}
CREATE TABLE default.es_data_migration
(
`id` UInt32,
`file_type` String,
`image_vector` Array(Float32),
`title` String,
`title_vector` Array(Float32),
VECTOR INDEX vec_ind_image image_vector TYPE MSTG('metric_type=L2'),
VECTOR INDEX vec_ind_title title_vector TYPE MSTG('metric_type=L2'),
CONSTRAINT check_length_image CHECK length(image_vector) = 3,
CONSTRAINT check_length_title CHECK length(title_vector) = 5
)
ENGINE = MergeTree
PRIMARY KEY id;
# Datenmigration
Diese Phase umfasst hauptsächlich das Exportieren von Daten aus Elasticsearch und deren anschließenden Import in MyScaleDB.
- Daten aus Elasticsearch exportieren: Benutzer können Daten in gängigen Formaten (wie JSON oder CSV) mithilfe verschiedener Methoden exportieren, z. B. über die Elasticsearch-API, Logstash, die CSV-Berichtsfunktion von Kibana und das Python-Tool es2csv.
- Daten in MyScaleDB importieren: MyScaleDB unterstützt verschiedene Methoden zum Importieren von Daten, einschließlich Python-Client (opens new window), HTTPS-Schnittstelle (opens new window) usw.
Hier ist ein Beispiel für die Verwendung des Python-Clients zum Migrieren von aus Elasticsearch exportierten Daten in MyScaleDB:
import clickhouse_connect
import pandas as pd
# Client initialisieren
# Für SaaS-Benutzer: Gehen Sie zur Seite MyScaleDB-Cluster, klicken Sie auf den Dropdown-Link Aktion und wählen Sie Verbindungsdetails.
client = clickhouse_connect.get_client(
host='127.0.0.1',
port=8123,
username='default',
password=''
)
def convert_vector(vector_str):
return list(map(float, vector_str.split(', ')))
# Migrierungsdatendatei lesen
data = pd.read_csv('test.csv', usecols=['_id', 'image-vector', 'title', 'title-vector'], converters={'image-vector': convert_vector, 'title-vector': convert_vector})
# Daten in die Migrations-Tabelle einfügen
client.insert('default.es_data_migration', data.values.tolist(), ['id', 'image_vector', 'title', 'title_vector'])
# Übersetzung der Abfragesyntax
Die ursprüngliche Abfrage-Abfragelogik der Anwendung, die ursprünglich von Elasticsearch behandelt wurde, wurde in eine MyScaleDB-Suche geändert, und die entsprechende Datenverarbeitungslogik wurde entsprechend aktualisiert.
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}
SELECT
id,
title,
file_type,
distance(image_vector, [-5.0, 9.0, -12.0]) AS l2_dist
FROM default.es_data_migration
ORDER BY l2_dist ASC
LIMIT 10

# Fazit
Durch einen Vergleich der Funktionalität und Leistung zwischen MyScaleDB und Elasticsearch lässt sich feststellen, dass MyScaleDB nicht nur eine effiziente Alternative zu Elasticsearch ist, sondern auch eine fortschrittliche Datenlösung darstellt, die sich an zukünftige Datenanforderungen und Technologietrends anpassen kann. Es hat erhebliche Vorteile, insbesondere bei der Vektorsuche und den Ressourcenkosten.
Darüber hinaus ist MyScaleDB aufgrund der leistungsstarken verteilten Speicher- und Verarbeitungsarchitektur von ClickHouse äußerst flexibel skalierbar und kann leicht zu großen Clustern skaliert werden, um wachsenden Datenanforderungen gerecht zu werden.
Darüber hinaus ist MyScaleDB mit den Komponenten des ClickHouse-Ökosystems kompatibel, einschließlich umfangreicher Dokumentationsressourcen und umfangreicher Community-Unterstützung. Es ist auch in beliebte Entwicklertools weltweit integriert, wie Python-Client (opens new window), Node.js (opens new window) und das LLM-Framework, einschließlich OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window) und LlamaIndex (opens new window), was den Benutzern ein besseres Benutzererlebnis und Support bietet.
Schließlich unterstützt MyScaleDB eine Vielzahl von Datentypen und Abfragesyntaxen und ist daher an verschiedene Datenanforderungen und Abfrageszenarien anpassbar. Mit seinen umfassenden SQL-Datenverwaltungsfunktionen, der robusten Datenspeicherung und den Abfragefunktionen wird MyScaleDB in Zukunft eine immer wichtigere Rolle bei der Datenverwaltung und -verarbeitung spielen und den Benutzern reichhaltigere und effizientere Dienste bieten.




