
Die OpenAI Assistants API ermöglicht es Entwicklern, mühelos robuste KI-Assistenten in ihren Anwendungen zu erstellen. Diese API bietet folgende Funktionen/Funktionalitäten:
- Beseitigt die Notwendigkeit, den Verlauf von Unterhaltungen zu verwalten,
- Bietet Zugang zu von OpenAI gehosteten Tools wie Code Interpreter und Retrieval und
- Verbessert den Aufruf von Funktionen für Tools von Drittanbietern.
In diesem Artikel werden wir uns die Assistants API genauer ansehen und wie wir mithilfe von Vektordatenbanken wie MyScale eine benutzerdefinierte Wissensdatenbank aufbauen und mit der Assistants API verknüpfen können, um eine größere Flexibilität, Genauigkeit und Kosteneinsparungen zu erzielen.
![]()
![]()
# Was ist ein OpenAI-Assistent?
Ein OpenAI-Assistent ist ein automatisierter Workflow, der Large Language Models (LLMs), Tools und Wissensdatenbanken nutzen kann, um Benutzeranfragen zu beantworten. Wie oben erwähnt, müssen Sie die Assistants API verwenden, um einen OpenAI-Assistenten zu erstellen.
Beginnen wir damit, uns die Assistants API genauer anzusehen:
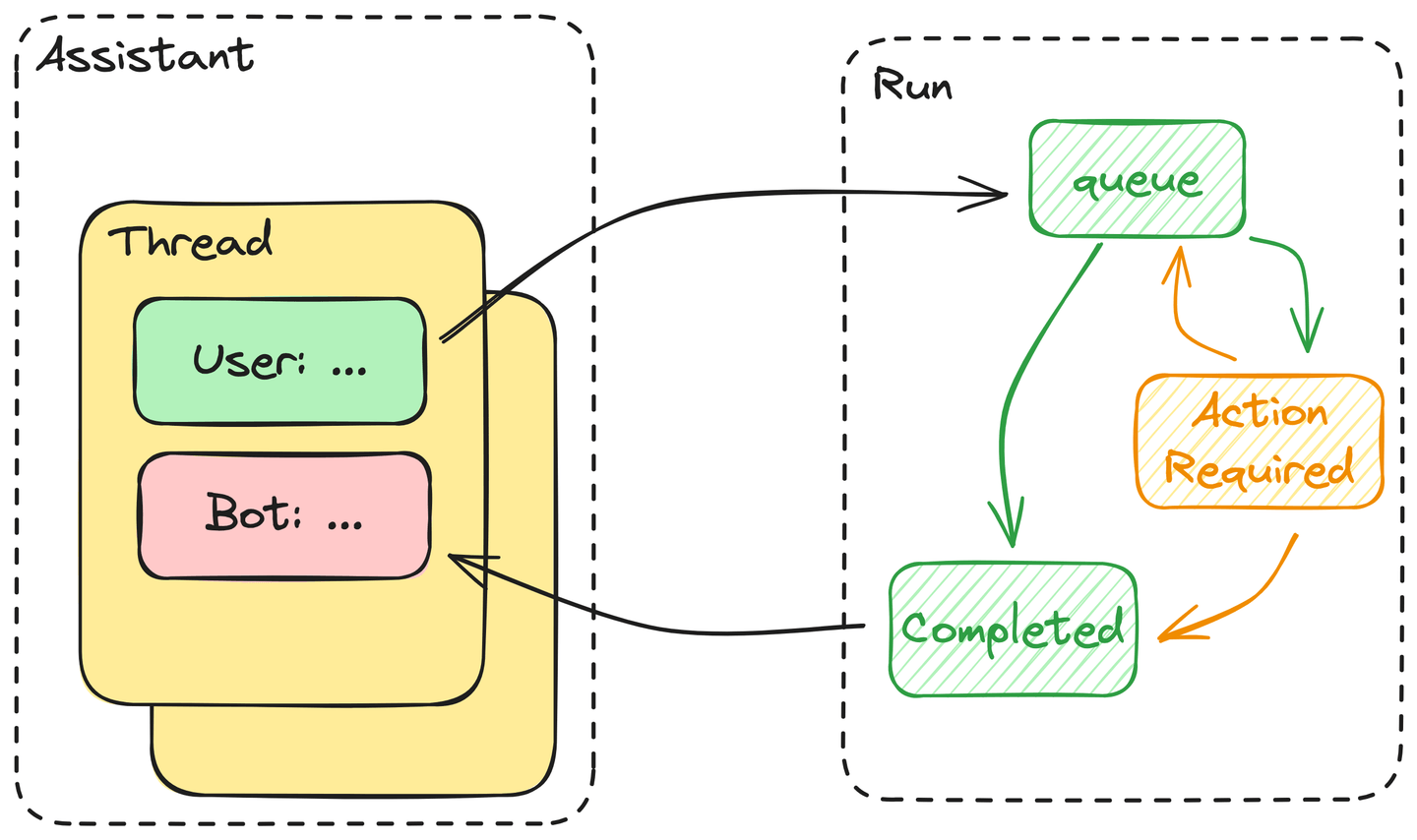
# Komponenten
Die Assistants API besteht aus den folgenden Kernkomponenten:
- Assistent: Ein Assistent enthält die Definition der Tools, die er verwenden kann, die Dateien, die er lesen kann, und die Systemanweisungen, die er den darin erstellten Threads zuordnet.
- Thread: Threads bestehen aus Nachrichten, die die Unterhaltungen des Assistenten steuern.
- Nachrichten: Nachrichten sind die grundlegenden Elemente, aus denen ein Thread besteht, und enthalten alle Texte, einschließlich der Eingaben des Benutzers und der generierten Antworten.
- Run: Benutzer müssen jedes Mal, wenn sie eine Antwort vom Assistenten anfordern, einen Run starten. In der Praxis führt der Assistent alle Nachrichten in einem Thread aus. Der Benutzer muss die Ausgabe des Tools an den Run übermitteln, wenn Aktionen erforderlich sind.
# Starten eines Runs mit den Tools der Assistants API
Es ist ein Zeichen von künstlicher Intelligenz, dass diese Assistenten wissen, wie sie die ihnen über API-Aufrufe gegebenen Tools verwenden. Zu diesem Zweck hat OpenAI gezeigt, dass GPT Benutzeranfragen in formatierte Verwendungstools umwandeln kann, die über einen Funktionsaufruf an die API übergeben werden. In menschlicher Sprache entspricht dies also dem Wissen, wie man ein Werkzeug verwendet.
Darüber hinaus können diese Assistenten während der Ausführung eines einzelnen Runs entscheiden, wann und welche Tools verwendet werden sollen. Wenn wir diesen Prozess vereinfachen, stellen wir fest, dass:
- Alle Nachrichten in einem Thread werden in die Warteschlange gestellt, sobald der Benutzer den Run startet. Diese Nachrichten werden dann aus der Warteschlange abgerufen, sobald Ressourcen verfügbar sind, um sie zu verarbeiten.
- Der Assistent entscheidet dann, ob er eines der in der Definition des Assistenten bereitgestellten Tools verwenden wird. Wenn ja, tritt der Assistent in einen Zustand "ActionRequired" ein - die Ausgabe des Tools blockiert ihn, bis die erforderliche Aktion bereitgestellt wird. Wenn nicht, gibt der Assistent sofort die Antwort zurück und markiert diesen Run als "Completed".
- Der Assistent wartet auf die Ausgabe für Tool-Aufrufe, bis die Zeitüberschreitung überschritten ist. Wenn alles nach Plan verläuft, fügt der Assistent die Ausgabe des Tools dem Thread hinzu, gibt die Antwort zurück und markiert den Run wie oben beschrieben als abgeschlossen.
Zusammenfassend lässt sich sagen, dass die Ausführung eines Runs im Wesentlichen ein Automat ist, der von einem LLM gesteuert wird.
# Verknüpfung von MyScale mit OpenAI's Assistant
MyScale verfügt über eine SQL-Schnittstelle, was ein großer Vorteil für automatisierte Abfragen ist. Darüber hinaus sind LLMs gut darin, Code zu schreiben, einschließlich SQL. Daher haben wir die SQL WHERE-Filter mit einer Vektorsuche kombiniert, wie in unserer Funktionsaufruf-Dokumentation (opens new window) beschrieben.
Betrachten wir nun die Erweiterung dieses Funktionsaufrufs zu einer Verknüpfung zwischen MyScale und der Assistants API von OpenAI.
# Verwenden Sie niemals das Retrieval-Tool des Assistenten
OpenAI enthält ein Retrieval-Tool in der Assistants API, das 0,2 $ / (GB * num_assistants) pro Tag kostet. Nehmen wir zum Beispiel den Arxiv-Datensatz: Seine Daten betragen ca. 24 GB mit der Einbettung. Dies kostet Sie jeden Tag 5 $ (150 $ monatlich) für nur einen Assistenten. Außerdem wissen Sie nie, wie die Retrieval-Leistung in Bezug auf Genauigkeit und Zeitverbrauch sein wird. Nur GPT weiß, ob es wertvolles Wissen enthält oder nicht. Daher ist eine externe Vektordatenbank ein Muss, wenn Sie Tonnen von Daten speichern und durchsuchen möchten.
# Definition einer Wissensdatenbank als Tool für einen Assistenten
Gemäß der offiziellen Dokumentation der Assistants API können Sie einen Assistenten mit OpenAI().beta.create_assistants.create erstellen. Hier ist ein Beispiel, wenn Sie einen Assistenten mit einer vorhandenen Wissensdatenbank erstellen möchten:
from openai import OpenAI
client = OpenAI()
assistant = client.beta.assistants.create(
name="ChatData",
instructions=(
"You are a helpful assistant. Do your best to answer the questions. "
),
tools=[
{
"type": "function",
"function": {
"name": "get_wiki_pages",
"description": (
"Get some related wiki pages.\n"
"You should use schema here to build WHERE string:\n\n"
"CREATE TABLE Wikipedia (\n"
" `id` String,\n"
" `text` String, -- abstract of the wiki page. avoid using this column to do LIKE match\n"
" `title` String, -- title of the paper\n"
" `view` Float32,\n"
" `url` String, -- URL to this wiki page\n"
"ORDER BY id\n"
"You should avoid using LIKE on long text columns."
),
"parameters": {
"type": "object",
"properties": {
"subject": {"type": "string", "description": "a sentence or phrase describes the subject you want to query."},
"where_str": {
"type": "string",
"description": "a sql-like where string to build filter.",
},
"limit": {"type": "integer", "description": "default to 4"},
},
"required": ["subject", "where_str", "limit"],
},
},
}
],
model="gpt-3.5-turbo",
)
Die bereitgestellte Funktion hat drei Eingaben: subject, where_str und limit, die der Implementierung des MyScale vectorstore in LangChain (opens new window) entsprechen.
Wie in der Anweisung beschrieben:
subjectist der Text, der für die Vektorsuche verwendet wird, undwhere_strist der strukturierte Filter im SQL-Format.
Wir fügen auch das Tabellenschema zur Toolbeschreibung hinzu, um dem Assistenten zu helfen, Filter mit den richtigen SQL-Funktionen zu schreiben.
# Externes Wissen von MyScale in den Assistenten einfügen
Um externes Wissen von MyScale in unseren Assistenten einzufügen, benötigen wir ein Tool, um dieses Wissen basierend auf den Argumenten abzurufen, die vom Assistenten generiert werden. Als Beispiel haben wir die Implementierung auf den MyScale Vector Store reduziert, wie der folgende Code zeigt:
import clickhouse_connect
db = clickhouse_connect.get_client(
host='msc-950b9f1f.us-east-1.aws.myscale.com',
port=443,
username='chatdata',
password='myscale_rocks'
)
must_have_cols = ['text', 'title', 'views']
database = 'wiki'
table = 'Wikipedia'
def get_related_pages(subject, where_str, limit):
q_emb = emb_model.encode(subject).tolist()
q_emb_str = ",".join(map(str, q_emb))
if where_str:
where_str = f"WHERE {where_str}"
else:
where_str = ""
q_str = f"""
SELECT dist, {','.join(must_have_cols)}
FROM {database}.{table}
{where_str}
ORDER BY distance(emb, [{q_emb_str}])
AS dist ASC
LIMIT {limit}
"""
docs = [r for r in db.query(q_str).named_results()]
return '\n'.join([str(d) for d in docs])
tools = {
"get_wiki_pages": lambda subject, where_str, limit: get_related_pages(subject, where_str, limit),
}
Zweitens benötigen wir einen neuen Thread, um unsere Eingabe zu halten:
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is Ring in mathematics? Please query the related documents to answer this.",
)
client.beta.threads.messages.list(thread_id=thread.id)
Runs werden aus Threads erstellt und sind einem bestimmten Assistenten zugeordnet. Unterschiedliche Runs können unterschiedliche Assistenten haben. Ein Thread kann daher Nachrichten enthalten, die mit verschiedenen Tools generiert wurden.
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions= "You must use query tools to look up relevant information for every answer to a user's question.",
)
Es ist wichtig, den Status dieses Runs ständig zu überprüfen und für jede Funktion, die der Assistent aufruft, Ausgaben bereitzustellen.
import json
from time import sleep
while True:
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
if run.status == 'completed':
print(client.beta.threads.messages.list(thread_id=thread.id))
# Wenn der Run abgeschlossen ist, müssen Sie überhaupt nichts tun
break
elif len(run.required_action.submit_tool_outputs.tool_calls) > 0:
print("> Aktion erforderlich <")
print(run.required_action.submit_tool_outputs.tool_calls)
# Wenn der Run Aktionen erfordert, müssen Sie Tools ausführen und die Ausgaben übermitteln
break
sleep(1)
tool_calls = run.required_action.submit_tool_outputs.tool_calls
outputs = []
# Tools für jede erforderliche Aktion aufrufen
for call in tool_calls:
func = call.function
outputs.append({"tool_call_id": call.id, "output": tools[func.name](**json.loads(func.arguments))})
if len(tool_calls) > 0:
# Alle ausstehenden Ausgaben übermitteln
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=outputs
)
Sobald die Ausgaben übermittelt wurden, wechselt der Run wieder in den Zustand "queued".
Hinweis: Wir müssen auch den Status dieses Runs ständig überprüfen.
from time import sleep
while client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
).status != 'completed':
print("> waiting for results... <")
sleep(1)
messages = client.beta.threads.messages.list(thread_id=thread.id).data[0].content[0].text.value
print("> generated texts <\n\n", messages)
Abschließend zeigt dieses Beispiel, wie die Assistants API verwendet wird.

# Fazit
Die Integration der MyScale Vektordatenbank als externe Wissensdatenbank in die Assistants API von OpenAI eröffnet Entwicklern neue Möglichkeiten, ihre KI-Assistenten zu verbessern. Durch die nahtlose Integration dieser wertvollen Ressource können Entwickler die Leistungsfähigkeit von MyScale zusammen mit von OpenAI gehosteten Tools wie Code Interpreter und Retrieval nutzen.
Diese Synergie vereinfacht nicht nur den Entwicklungsprozess, sondern stattet KI-Assistenten auch mit einer breiteren Wissensbasis aus, die den Benutzern ein robusteres und intelligenteres Erlebnis bietet. Während wir weiterhin Fortschritte in der Erforschung der künstlichen Intelligenz machen, markieren solche Integrationen einen bedeutenden Schritt hin zur Schaffung vielseitiger und leistungsfähiger virtueller Assistenten.
Treten Sie noch heute unserem Discord (opens new window) bei, um Ihre Gedanken zur Assistants API zu teilen!



