
In der heutigen Welt sind Empfehlungssysteme von entscheidender Bedeutung, um die Benutzererfahrung auf verschiedenen Plattformen wie E-Commerce, Streaming-Diensten, Nachrichtenfeeds, sozialen Medien und personalisiertem Lernen zu verbessern.
Im Bereich der Empfehlungssysteme basierten herkömmliche Ansätze auf der Analyse von Benutzer-Item-Interaktionen und der Bewertung von Item-Ähnlichkeiten. Mit den Fortschritten im Bereich der künstlichen Intelligenz hat sich auch das Gebiet der Empfehlungssysteme weiterentwickelt und die Präzision verbessert sowie Empfehlungen an individuelle Vorlieben angepasst.
# Weit verbreitete Ansätze für die Inhalts-Empfehlung
Es gibt drei Arten von Filtern, die für Empfehlungssysteme für Inhalte verwendet werden. Einige verwenden kollaboratives Filtern (opens new window), einige verwenden inhaltbasiertes Filtern (opens new window), und einige verwenden eine Kombination dieser beiden Methoden. Lassen Sie uns diese im Detail besprechen.
# Inhaltsbasiertes Filtern
Das inhaltsbasierte Filtern konzentriert sich auf die Eigenschaften der Items selbst. Es empfiehlt Items, die denen ähnlich sind, an denen ein Benutzer zuvor Interesse gezeigt hat.
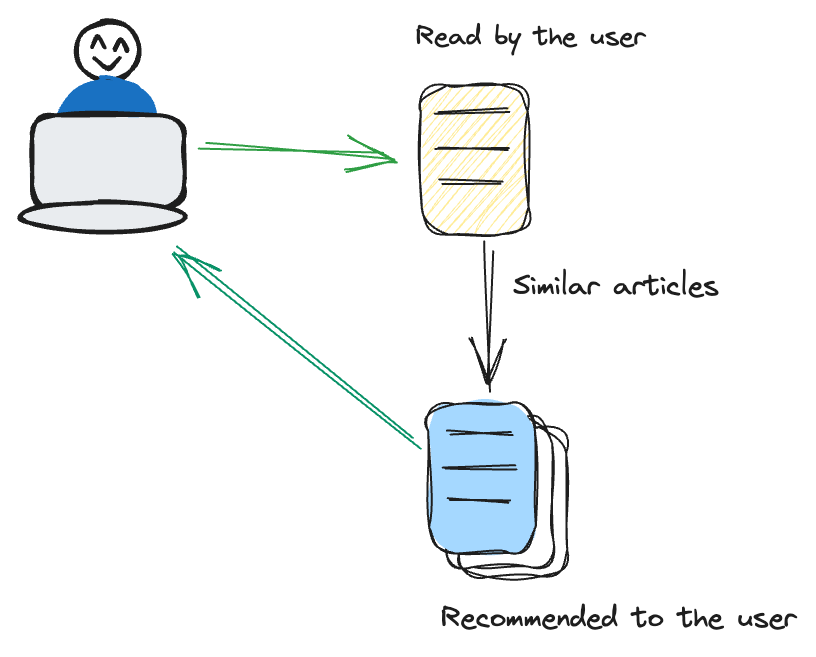
Wenn ein Benutzer zum Beispiel häufig Thriller-Filme ansieht, nimmt das Empfehlungssystem einen maßgeschneiderten Ansatz an, indem es zusätzliche Filme im Thriller-Genre vorschlägt. Diese Methode legt einen erheblichen Schwerpunkt auf die inhärenten Eigenschaften der Items wie Genre, Autor oder Künstler. Durch die Konzentration auf diese Attribute stellt das System eine gezieltere und inhaltsbezogene Empfehlungsstrategie sicher, die eng an die Vorlieben des Benutzers angepasst ist.
# Kollaboratives Filtern
Das kollaborative Filtern ist benutzerzentriert. Es analysiert Muster und Ähnlichkeiten im Benutzerverhalten, um Empfehlungen zu erstellen.
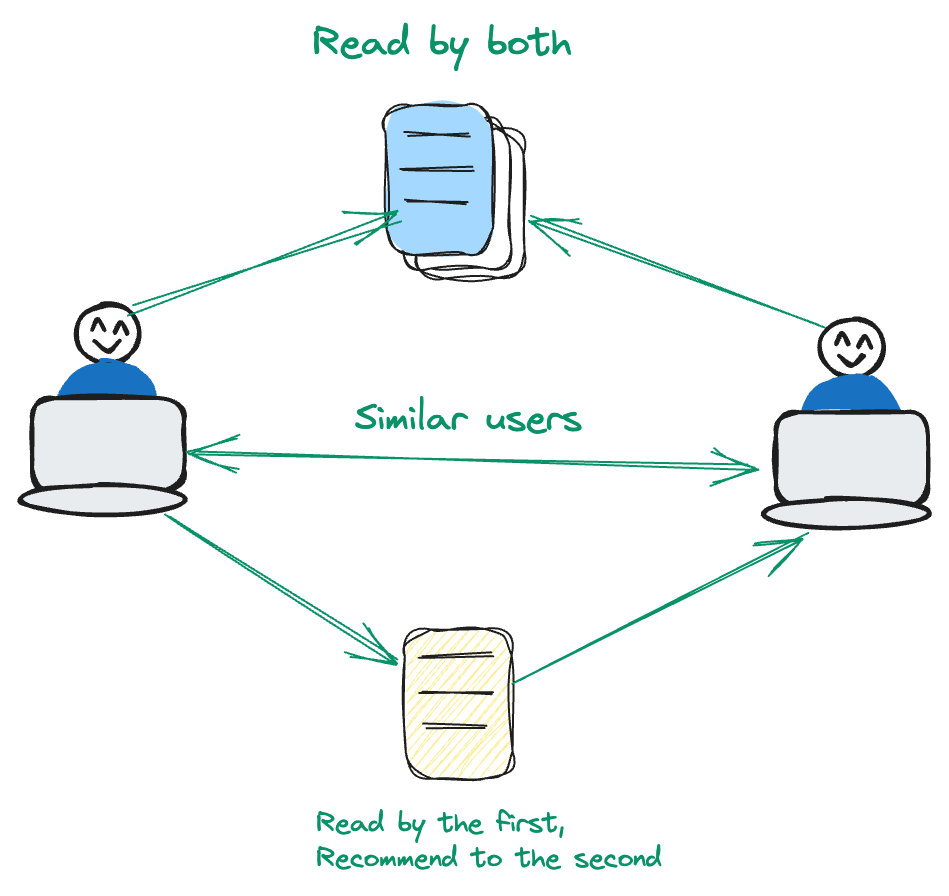
Nehmen wir an, Benutzer A und Benutzer B haben ein gemeinsames Interesse an einer bestimmten Reihe von Filmen. Wenn Benutzer B zum Beispiel einen Film mag, den Benutzer A noch nicht gesehen hat, nimmt das Empfehlungssystem dies zur Kenntnis. Bei dieser Methode liegt der Schwerpunkt auf der Nutzung von Benutzerinteraktionen und -präferenzen und weicht von einem inhaltszentrierten Ansatz ab. Durch Priorisierung der dynamischen Beziehungen zwischen Benutzern und Items verfeinert das System seine Empfehlungen für eine personalisierte Benutzererfahrung.
# Hybridtechniken
Hybridtechniken integrieren geschickt die Stärken von sowohl inhaltsbasiertem als auch kollaborativem Filtern, um die Empfehlungsgenauigkeit zu verbessern. Durch die Nutzung eines dualen Ansatzes, der sowohl Item-Eigenschaften als auch Benutzerpräferenzmuster einbezieht, bewältigt diese Methode geschickt inhärente Einschränkungen, die auftreten, wenn man sich ausschließlich auf jeden Ansatz einzeln verlässt. Hybridtechniken sind besonders effektiv bei der Bereitstellung raffinierter und vielfältiger Empfehlungen.
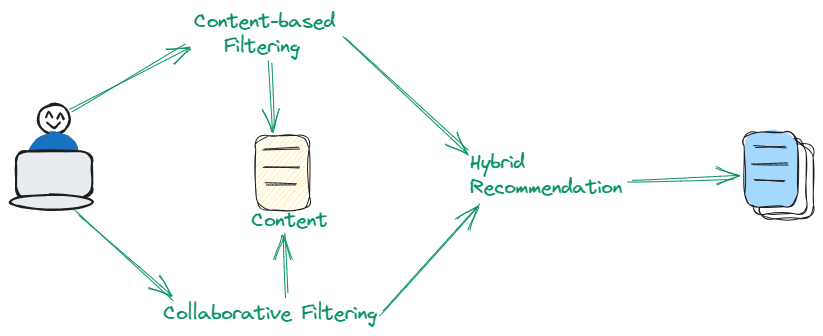
# Fortgeschrittener Ansatz für die Inhalts-Empfehlung
Der Aufstieg der Large Language Models (LLMs) hat verschiedene Aufgaben erheblich vereinfacht, insbesondere die Entwicklung von Empfehlungssystemen. Für moderne Empfehlungssysteme hat die herkömmliche Abhängigkeit von inhalts- oder kollaborativem Filtern einem anspruchsvolleren Ansatz Platz gemacht. Durch die Nutzung der Semantik navigieren moderne Empfehlungssysteme durch die Bedeutung von Sprache, um verwandte Items vorzuschlagen.
In diesem Blog zeige ich Ihnen, wie Sie ein Empfehlungssystem für Inhalte mit diesem fortschrittlichen Ansatz erstellen können. Schauen wir uns zunächst die für dieses System erforderlichen Tools an.
![]()
# Werkzeuge und Technologien
In diesem Projekt verwenden wir das OpenAI-Text-Einbettungsmodell (opens new window), MyScale als Vektordatenbank (opens new window) und TMDB 5000 Movie Dataset (opens new window).
- OpenAI: Wir verwenden das Modell
text-embedding-3-smallvon OpenAI, um die Einbettungen des Textes zu erhalten und diese Einbettungen dann zur Entwicklung des Modells zu verwenden. - MyScale: MyScale ist eine SQL-Vektordatenbank, mit der strukturierte und unstrukturierte Daten auf optimierte Weise gespeichert und verarbeitet werden können.
- TMDB 5000 Movie Dataset: Dieser Datensatz enthält eine Sammlung von Filmmetadaten, einschließlich Besetzung, Crew, Budget- und Umsatzdetails.
# Laden der Daten
Wir haben zwei wichtige CSV-Dateien: tmdb_5000_credits.csv und tmdb_5000_movies.csv. Diese Dateien enthalten wesentliche Informationen über eine vielfältige Auswahl von Filmen, die die Grundlage unseres Empfehlungssystems bilden werden.
import pandas as pd
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
# Datenverarbeitung
Die Datenverarbeitung ist entscheidend, um die Qualität des Empfehlungssystems sicherzustellen. Wir werden die beiden CSV-Dateien zusammenführen und uns auf die relevantesten Spalten konzentrieren - title, overview, genres, cast und crew. Dieser Schritt dient dazu, die Daten für unser Modell geeignet zu machen.
credits.rename(columns = {'movie_id':'id'}, inplace = True)
df = credits.merge(movies, on = 'id')
df.dropna(subset = ['overview'], inplace=True)
df = df[['id', 'title_x', 'genres', 'overview', 'cast', 'crew']]
Durch das Zusammenführen und Filtern unserer Daten haben wir einen sauberen und fokussierten Datensatz für das System erstellt.
# Generieren des Korpus
Als nächstes generieren wir für jeden Film einen corpus, indem wir overview, genres, cast und crew zu einem einzigen String kombinieren. Diese umfassenden Informationen helfen dem System, genaue Empfehlungen zu machen.
import pandas as pd
# Angenommen, 'df' ist Ihr DataFrame und es hat die Spalten 'overview', 'genres', 'cast' und 'crew'
def generate_corpus(row):
overview, genre, cast, crew = row['overview'], row['genres'], row['cast'], row['crew']
corpus = ""
genre = ','.join([i['name'] for i in eval(genre)])
cast = ','.join([i['name'] for i in eval(cast)[:3]])
crew = ','.join(list(set([i['name'] for i in eval(crew) if i['job'] == 'Director' or i['job'] == 'Producer'])))
corpus += overview + " " + genre + " " + cast + " " + crew
return pd.Series([corpus, crew, cast, genre], index=['corpus', 'crew', 'cast', 'genres'])
# Wenden Sie die Funktion auf jede Zeile an
df[['corpus', 'crew', 'cast', 'genres']] = df.apply(generate_corpus, axis=1)
# Abrufen der Einbettungen
Wir verwenden dann das Einbettungsmodell text-embedding-3-small von OpenAI, um unseren Korpus in Einbettungen umzuwandeln, die numerische Darstellungen des Inhalts des Films sind.
import os
import numpy as np
import openai
os.environ["OPENAI_API_KEY"] = "your-api-key"
def get_embeddings(text):
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data
# Holen Sie sich die ersten 1000 Einträge, da wir das gesamte Dataset mit 5000 Einträgen nicht an das Einbettungsmodell übergeben können. Wenn Sie die Einbettungen des gesamten Datensatzes erhalten möchten, können Sie eine Schleife anwenden
df=df[0:1000]
embeddings=get_embeddings(df["corpus"].tolist())
vectors = [embedding.embedding for embedding in embeddings]
array = np.array(vectors)
embeddings_series = pd.Series(list(array))
df['embeddings'] = embeddings_series
Indem wir die Vektorrepräsentation des Textes erhalten, können wir jetzt leicht semantische Suche mit MyScale anwenden.
# Einrichten von MyScale
Wie bereits erwähnt, verwenden wir MyScale als Vektordatenbank zum Speichern und Verwalten von Daten. Hier stellen wir eine Verbindung zu MyScale her, um uns auf die Datenspeicherung vorzubereiten.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
Hinweis: Weitere Informationen zur Verbindung mit dem MyScale-Cluster finden Sie unter Verbindungsdetails (opens new window).
# Erstellen einer Tabelle
Wir erstellen nun eine Tabelle entsprechend unserem DataFrame. Alle Daten werden in dieser Tabelle gespeichert, einschließlich der Einbettungen.
client.command("""
CREATE TABLE default.movies (
id Int64,
title_x String,
genres String,
overview String,
cast String,
crew String,
corpus String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id
""")
Die obigen SQL-Anweisungen erstellen eine Tabelle mit dem Namen movies auf dem Cluster. Der CONSTRAINT stellt sicher, dass alle Vektoreinbettungen die gleiche Länge von 1536 haben.
# Speichern der Daten und Erstellen eines Indexes in MyScale
In diesem Schritt fügen wir die verarbeiteten Daten in MyScale ein. Dies beinhaltet das Stapel-Einfügen der Daten, um eine effiziente Speicherung und Abfrage zu gewährleisten.
batch_size = 100 # Je nach Bedarf anpassen
num_batches = len(df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = df[start_idx:end_idx]
client.insert("default.movies", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} eingefügt.")
client.command("""
ALTER TABLE default.movies
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Generieren von Filmempfehlungen
Schließlich erstellen wir eine Funktion, die basierend auf Benutzereingaben Filmempfehlungen generiert. Diese Funktion verwendet einen exponentiellen Abnahmefaktor, um kürzlich angesehene Filme stärker zu berücksichtigen und die Qualität der Empfehlungen zu verbessern.
import numpy as np
from IPython.display import clear_output
genres = []
for i in range(3):
genre = input("Geben Sie ein Genre ein: ")
genres.append(genre)
genre_string = ', '.join(genres)
genre_embeddings=get_embeddings(genre_string)
embeddings=genre_embeddings[0].embedding
embeddings = np.array(genre_embeddings[0].embedding) # In ein Numpy-Array konvertieren
decay_factor = 0.9 # Je nach Bedarf anpassen für exponentiellen Abfall
while True:
clear_output(wait=True)
# Verwenden Sie die kombinierten Einbettungen, um die Datenbank abzufragen
results = client.query(f"""
SELECT title_x, genres,
distance(embeddings, {embeddings.tolist()}) as dist FROM default.movies ORDER BY dist LIMIT 10
""")
# Zeigen Sie die Ergebnisse an
print("Empfohlene Filme:")
movies = []
for row in results.named_results():
print(row["title_x"])
movies.append(row['title_x'])
# Fordern Sie den Benutzer auf, einen Film auszuwählen
selection = int(input("Wählen Sie einen Film aus (oder geben Sie 0 ein, um zu beenden): "))
if selection == 0:
break
selected_movie = movies[selection - 1]
# Holen Sie sich die Einbettungen des ausgewählten Filmtitels
selected_movie_embeddings = get_embeddings(selected_movie)[0].embedding
selected_movie_embeddings_array = np.array(selected_movie_embeddings)
# Wenden Sie den exponentiellen Abfall an und aktualisieren Sie die kombinierten Einbettungen
embeddings = decay_factor * embeddings + (1 - decay_factor) * selected_movie_embeddings_array
# Normalisieren Sie die kombinierten Einbettungen
embeddings = embeddings / np.linalg.norm(embeddings)
Wir haben nun ein voll funktionsfähiges Filmempfehlungssystem mit MyScale und Vektoreinbettungen erstellt. Fühlen Sie sich frei, mit diesem Tutorial zu experimentieren oder Ihr eigenes entsprechend den Anforderungen zu erstellen.

# Zusammenfassung
In diesem Tutorial haben wir erkundet, wie man LLMs mit einer Vektordatenbank wie MyScale kombiniert, um ein Empfehlungssystem für Inhalte zu erstellen. Die Auswahl der richtigen Vektordatenbank ist für die Entwicklung einer effizienten Anwendung sehr wichtig. MyScale zeichnet sich durch die Handhabung von Vektordaten sowie strukturierten Metadaten aus und gewährleistet schnelle und genaue Abfrageergebnisse. Dank seiner effizienten Skalierbarkeit bietet es eine starke Leistung, auch wenn Datensätze wachsen. Mit fortschrittlichen Indexierungs- und Abfragefunktionen verbessert MyScale die Leistung und Genauigkeit Ihrer Anwendung erheblich.
Haben Sie Pläne, eine KI-Anwendung mit MyScale zu entwickeln? Teilen Sie Ihre Gedanken mit uns auf Twitter (opens new window) und Discord (opens new window).



