
Basic Retrieval-Augmented Generation (RAG) (opens new window) Datenpipelines verlassen sich oft auf fest codierte Schritte und folgen jedes Mal einem vordefinierten Pfad, wenn sie ausgeführt werden. In diesen Systemen gibt es keine Echtzeit-Entscheidungsfindung und sie passen ihre Aktionen nicht dynamisch anhand der Eingabedaten an. Diese Einschränkung kann die Flexibilität und Reaktionsfähigkeit in komplexen oder sich ändernden Umgebungen verringern und eine wesentliche Schwäche herkömmlicher RAG-Systeme aufzeigen.
LlamaIndex löst diese Einschränkung, indem es Agenten (opens new window) einführt. Agenten gehen über unsere Abfrage-Engines hinaus, da sie nicht nur aus einer statischen Datenquelle "lesen" können, sondern Daten aus verschiedenen Tools dynamisch aufnehmen und modifizieren können. Diese Agenten, die von einem LLM angetrieben werden, sind darauf ausgelegt, eine Reihe von Aktionen auszuführen, um eine bestimmte Aufgabe zu erledigen, indem sie die am besten geeigneten Tools aus einem bereitgestellten Satz auswählen. Diese Tools können so einfach wie grundlegende Funktionen oder so komplex wie umfassende LlamaIndex-Abfrage-Engines sein. Sie verarbeiten Benutzereingaben oder Abfragen, treffen interne Entscheidungen darüber, wie diese Eingaben behandelt werden sollen, und entscheiden, ob zusätzliche Schritte erforderlich sind oder ob ein endgültiges Ergebnis geliefert werden kann. Diese Fähigkeit zur automatisierten Schlussfolgerung und Entscheidungsfindung macht Agenten äußerst anpassungsfähig und effizient für komplexe Datenverarbeitungsaufgaben.
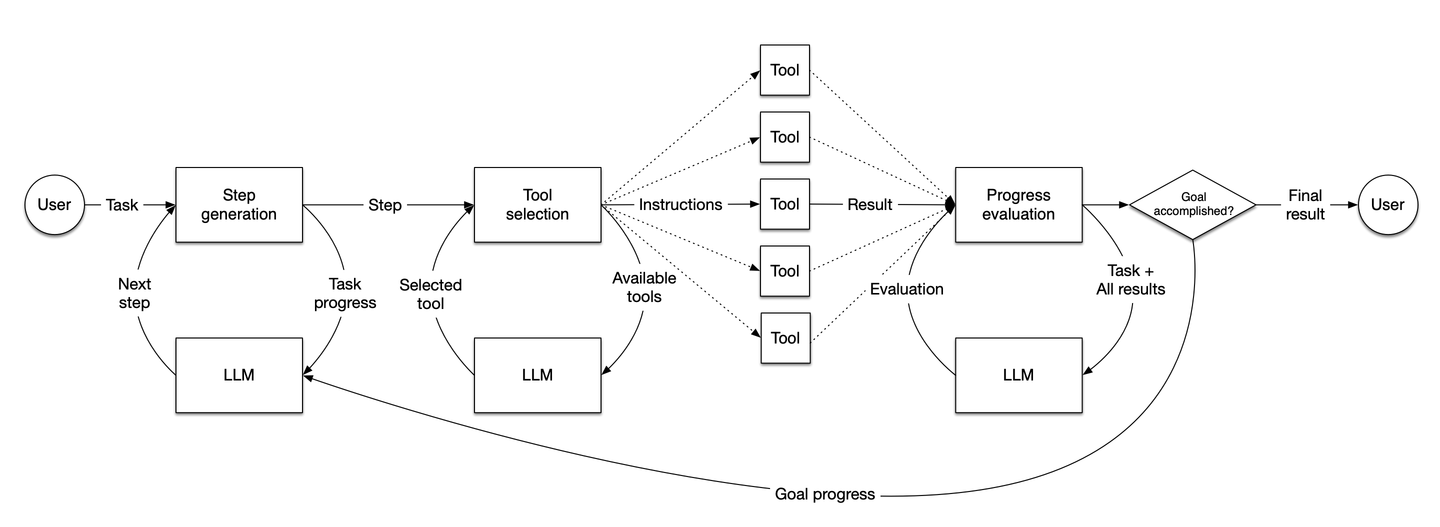
Quelle: LlamaIndex
Das Diagramm veranschaulicht den Arbeitsablauf von LlamaIndex-Agenten. Wie sie Schritte generieren, Entscheidungen treffen, Tools auswählen und den Fortschritt bewerten, um Aufgaben basierend auf Benutzereingaben dynamisch zu erledigen.
# Kernkomponenten eines LlamaIndex-Agenten
Ein Agent in LlamaIndex besteht aus zwei Hauptkomponenten: AgentRunner und AgentWorker.
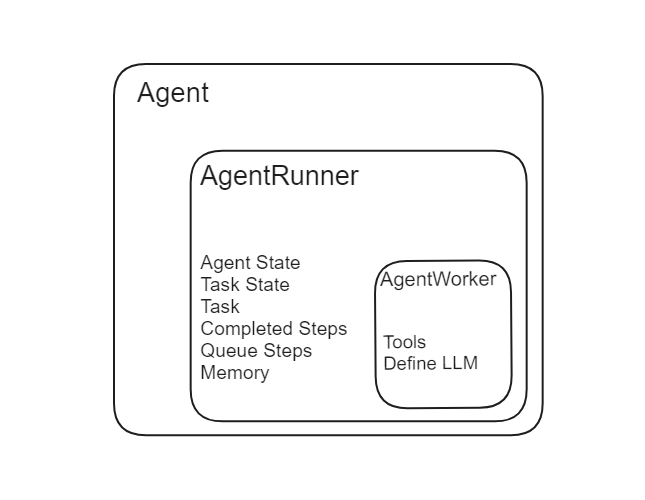
Quelle: LlamaIndex
# AgentRunner
Der AgentRunner ist der Orchestrierer in LlamaIndex. Er verwaltet den Zustand des Agenten, einschließlich des Gesprächsgedächtnisses, und bietet eine hochrangige Schnittstelle für die Benutzerinteraktion. Er erstellt und verwaltet Aufgaben und ist für die Ausführung von Schritten in jeder Aufgabe verantwortlich. Hier ist eine detaillierte Aufschlüsselung seiner Funktionalitäten:
- Aufgabenerstellung: Der AgentRunner erstellt Aufgaben basierend auf Benutzerabfragen oder -eingaben.
- Zustandsverwaltung: Er speichert und verwaltet den Zustand des Gesprächs und der Aufgaben.
- Gedächtnisverwaltung: Er verwaltet das Gesprächsgedächtnis intern und stellt sicher, dass der Kontext über Interaktionen hinweg erhalten bleibt.
- Aufgabenausführung: Er führt Schritte in jeder Aufgabe aus und koordiniert sich mit dem AgentWorker.
Im Gegensatz zu LangChain-Agenten (opens new window), bei denen Entwickler das Gedächtnis manuell definieren und übergeben müssen, übernimmt LlamaIndex die Gedächtnisverwaltung intern.
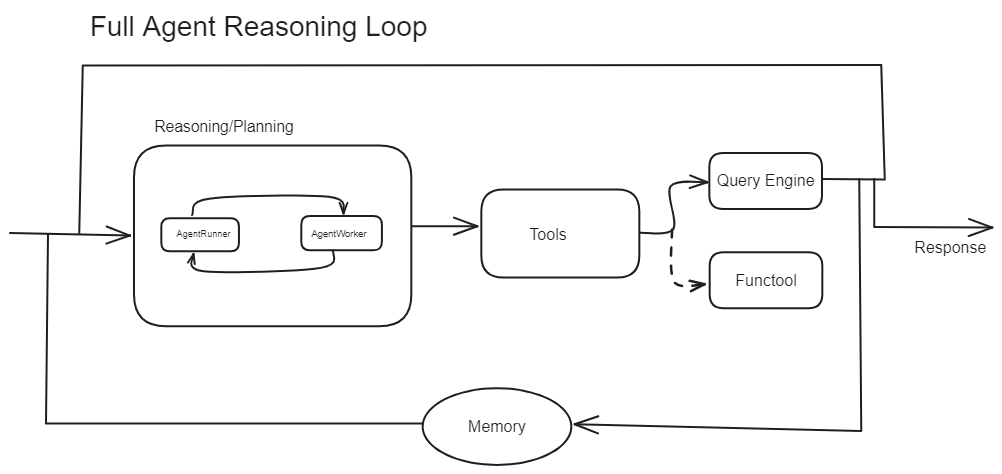
Quelle: LlamaIndex
# AgentWorker
Der AgentWorker steuert die schrittweise Ausführung einer Aufgabe, die vom AgentRunner angegeben wird. Er ist dafür verantwortlich, den nächsten Schritt in einer Aufgabe basierend auf der aktuellen Eingabe zu generieren. AgentWorker können anpassbar sein und spezifische Schlussfolgerungslogik enthalten, was sie äußerst anpassungsfähig für verschiedene Aufgaben macht. Zu den wichtigsten Aspekten gehören:
- Schrittgenerierung: Bestimmt den nächsten Schritt in der Aufgabe basierend auf den aktuellen Daten.
- Anpassungsfähigkeit: Dies kann an spezifische Arten von Schlussfolgerungen oder Datenverarbeitung angepasst werden.
Der AgentRunner verwaltet die Aufgabenerstellung und den Zustand, während der AgentWorker die Schritte jeder Aufgabe ausführt und als operative Einheit unter der Leitung des AgentRunner fungiert.
# Arten von Agenten in LlamaIndex
LlamIndex bietet verschiedene Arten von Agenten, die für spezifische Aufgaben und Funktionen entwickelt wurden.
# Datenagenten
Datenagenten (opens new window) sind spezialisierte Agenten, die eine Vielzahl von Datenaufgaben, einschließlich Abruf und Manipulation, bewältigen können. Sie können sowohl im Lese- als auch im Schreibmodus arbeiten und nahtlos mit verschiedenen Datenquellen interagieren.
Datenagenten können Daten in verschiedenen Datenbanken und APIs suchen, abrufen, aktualisieren und manipulieren. Sie unterstützen die Interaktion mit Plattformen wie Slack, Shopify, Google und mehr und ermöglichen eine einfache Integration mit diesen Diensten. Datenagenten können komplexe Datenoperationen wie Datenbankabfragen, API-Aufrufe, Aktualisierung von Datensätzen und Durchführung von Datenumwandlungen durchführen. Ihre anpassungsfähige Gestaltung macht sie für eine Vielzahl von Anwendungen geeignet, von einfacher Datenabfrage bis hin zu komplexen Datenverarbeitungspipelines.
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# Tools importieren und definieren
...
# LLM initialisieren
llm = OpenAI(model="gpt-3.5-turbo")
# OpenAI-Agent initialisieren
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# ReAct-Agent initialisieren
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# Agent verwenden
response = agent.chat("Was ist (121 * 3) + 42?")
# Benutzerdefinierte Agenten
Benutzerdefinierte Agenten bieten Ihnen viel Flexibilität und Anpassungsmöglichkeiten. Durch Unterklasse CustomSimpleAgentWorker können Sie spezifische Logik und Verhalten für Ihre Agenten definieren. Dies umfasst die Behandlung komplexer Abfragen, die Integration mehrerer Tools und die Implementierung von Fehlerbehandlungsmechanismen.
Sie können benutzerdefinierte Agenten an spezifische Anforderungen anpassen, indem Sie schrittweise Logik, Wiederholungsmechanismen und verschiedene Tools integrieren. Diese Anpassung ermöglicht es Ihnen, Agenten zu erstellen, die komplexe Aufgaben und Workflows verwalten und sich so an verschiedene Szenarien anpassen können. Ob Sie komplexe Datenoperationen verwalten oder sich mit einzigartigen Diensten integrieren möchten, benutzerdefinierte Agenten bieten Ihnen die Werkzeuge, die Sie benötigen, um spezialisierte, effiziente Lösungen zu entwickeln.
# Tools und Tool-Spezifikationen
Tools (opens new window) sind die wichtigste Komponente eines Agenten. Sie ermöglichen es dem Agenten, verschiedene Aufgaben auszuführen und seine Funktionalität zu erweitern. Durch die Verwendung verschiedener Arten von Tools kann ein Agent spezifische Operationen ausführen, wie sie benötigt werden. Dadurch wird der Agent äußerst anpassungsfähig und effizient.
# Funktionswerkzeuge
Funktionswerkzeuge ermöglichen es Ihnen, jede Python-Funktion in ein Werkzeug umzuwandeln, das ein Agent verwenden kann. Diese Funktion ist nützlich, um benutzerdefinierte Operationen zu erstellen und die Fähigkeit des Agenten zu erweitern, eine Vielzahl von Aufgaben auszuführen.
Sie können einfache Funktionen in Werkzeuge umwandeln, die der Agent in seinen Arbeitsablauf integriert. Dies kann mathematische Operationen, Datenverarbeitungsfunktionen und andere benutzerdefinierte Logik umfassen.
Sie können Ihre Python-Funktion in ein Werkzeug wie folgt umwandeln:
from llama_index.core.tools import FunctionTool
def multiply(a: int, b: int) -> int:
"""Multipliziert zwei Ganzzahlen und gibt das Ergebnis als Ganzzahl zurück."""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
Die Methode FunctionTool in LlamaIndex ermöglicht es Ihnen, jede Python-Funktion in ein Werkzeug umzuwandeln, das ein Agent verwenden kann. Der Name der Funktion wird zum Namen des Werkzeugs, und der Docstring der Funktion dient als Beschreibung des Werkzeugs.
# QueryEngine-Werkzeuge
QueryEngine-Werkzeuge umhüllen vorhandene Abfrage-Engines und ermöglichen es Agenten, komplexe Abfragen über Datenquellen durchzuführen. Diese Werkzeuge integrieren sich nahtlos mit verschiedenen Datenbanken und APIs und ermöglichen es dem Agenten, Daten effizient abzurufen und zu manipulieren.
Diese Werkzeuge ermöglichen es Agenten, mit bestimmten Datenquellen zu interagieren, komplexe Abfragen durchzuführen und relevante Informationen abzurufen. Diese Integration ermöglicht es dem Agenten, die Daten effektiv in seinen Entscheidungsprozessen zu verwenden.
Um eine Abfrage-Engine in ein Abfrage-Engine-Werkzeug umzuwandeln, können Sie den folgenden Code verwenden:
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = QueryEngineTool(
query_engine="Ihre_Index_als_Abfrage-Engine_hier",
metadata=ToolMetadata(
name="Name_Ihres_Werkzeugs",
description="Geben Sie die Beschreibung an",
),
)
Die Methode QueryEngineTool ermöglicht es Ihnen, eine Abfrage-Engine in ein Werkzeug umzuwandeln, das ein Agent verwenden kann. Die Klasse ToolMetadata hilft dabei, den Namen und die Beschreibung dieses Werkzeugs festzulegen. Der Name des Werkzeugs wird durch das Attribut name festgelegt, und die Beschreibung wird durch das Attribut description festgelegt.
Hinweis: Die Beschreibung des Werkzeugs ist äußerst wichtig, da sie dem LLM hilft zu entscheiden, wann dieses Werkzeug verwendet werden soll.

# Erstellen eines KI-Agenten mit MyScaleDB und LlamaIndex
Erstellen wir einen KI-Agenten (opens new window) unter Verwendung eines Abfrage-Engine-Werkzeugs und eines Funktionswerkzeugs, um zu demonstrieren, wie diese Werkzeuge integriert und effektiv genutzt werden können.
# Installieren der erforderlichen Bibliotheken
Installieren Sie zunächst die erforderlichen Bibliotheken, indem Sie den folgenden Befehl in Ihrem Terminal ausführen:
pip install myscale-client llama-index
Wir werden MyScaleDB (opens new window) als Vektorsuchmaschine verwenden, um die Abfrage-Engine zu entwickeln. Es handelt sich um eine fortschrittliche SQL-Vektordatenbank, die speziell für skalierbare Anwendungen entwickelt wurde.
# Daten für die Abfrage-Engine erhalten
Wir werden den Nike-Katalogdatensatz (opens new window) für dieses Beispiel verwenden. Laden Sie die Daten herunter und bereiten Sie sie mit dem folgenden Code vor:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = 'https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(input_files=["Nike_Catalog.pdf"])
documents = reader.load_data()
Dieser Code lädt den Nike-Katalog-PDF herunter und lädt die Daten für die Verwendung in der Abfrage-Engine.
# Verbindung mit MyScaleDB herstellen
Bevor Sie MyScaleDB verwenden können, müssen Sie eine Verbindung herstellen:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='Ihr_Host_Hier',
port=443,
username='Ihr_Benutzername_Hier',
password='Ihr_Passwort_Hier'
)
Um Details zum Cluster zu erhalten und mehr über MyScale zu erfahren, können Sie sich an die MyScaleDB-Schnellstartanleitung (opens new window) wenden.
# Erstellen des Abfrage-Engine-Werkzeugs
Lassen Sie uns zunächst das erste Werkzeug für unseren Agenten erstellen, das das Abfrage-Engine-Werkzeug ist. Dazu entwickeln wir zunächst die Abfrage-Engine mit MyScaleDB und fügen die Nike-Katalogdaten zum Vektorstore hinzu.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
Sobald die Daten in den Vektorstore aufgenommen und ein Index erstellt wurde, ist der nächste Schritt, die Abfrage-Engine in ein Werkzeug umzuwandeln. Dazu verwenden wir die Methode QueryEngineTool von LlamaIndex.
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tool = QueryEngineTool(
query_engine=index,
metadata=ToolMetadata(
name="nike_data",
description="Informationen über die Nike-Produkte bereitstellen. Verwenden Sie eine detaillierte Klartextfrage als Eingabe für das Werkzeug."
),
)
Das QueryEngineTool nimmt query_engine und meta_data als Argumente entgegen. In den Metadaten definieren wir den Namen des Werkzeugs und die Beschreibung.
# Erstellen des Funktionswerkzeugs
Unser nächstes Werkzeug ist eine einfache Python-Funktion, die zwei Zahlen multipliziert. Diese Methode wird mit Hilfe des FunctionTool von LlamaIndex in ein Werkzeug umgewandelt.
from llama_index.core.tools import FunctionTool
# Definieren Sie eine einfache Python-Funktion
def multiply(a: int, b: int) -> int:
"""Multipliziert zwei Ganzzahlen und gibt das Ergebnis zurück."""
return a * b
# Funktion in ein Werkzeug umwandeln
multiply_tool = FunctionTool.from_defaults(fn=multiply)
Danach sind wir mit den Werkzeugen fertig. Die LlamaIndex-Agenten nehmen Werkzeuge als Python-Liste entgegen. Fügen wir also die Werkzeuge einer Liste hinzu.
tools = [multiply_tool, query_engine_tool]
# LLM definieren
Definieren wir das LLM, das Herz eines jeden LlamaIndex-Agenten. Die Wahl des LLM ist entscheidend, denn je besser das Verständnis und die Leistung des LLM, desto effektiver kann es als Entscheidungsträger agieren und komplexe Probleme bewältigen. Wir werden das Modell gpt-3.5-turbo von OpenAI verwenden.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
# Agent initialisieren
Wie wir zuvor gesehen haben, besteht ein Agent aus einem AgentRunner und einem AgentWorker. Dies sind zwei Bausteine eines Agenten. Nun werden wir sehen, wie sie in der Praxis funktionieren. Den folgenden Code haben wir auf zwei Arten implementiert:
- Benutzerdefinierter Agent: Die erste Methode besteht darin, den AgentWorker zuerst mit den Werkzeugen und dem LLM zu initialisieren. Anschließend wird der AgentWorker an den AgentRunner übergeben, um den gesamten Agenten zu verwalten. Hier importieren Sie die erforderlichen Module und erstellen Ihren eigenen Agenten.
from llama_index.core.agent import AgentRunner
from llama_index.agent.openai import OpenAIAgentWorker
# Methode 2: AgentRunner mit OpenAIAgentWorker initialisieren
openai_step_engine = OpenAIAgentWorker.from_tools(tools, llm=llm, verbose=True)
agent1 = AgentRunner(openai_step_engine)
- Vordefinierter Agent verwenden: Die zweite Methode besteht darin, die Agents zu verwenden, die Unterklasse von
AgentRunnersind und denOpenAIAgentWorkerim Hintergrund bündeln. Daher müssen wir den AgentRunner oder AgentWorker nicht selbst definieren, da sie auf der Backend-Seite implementiert sind.
from llama_index.agent.openai import OpenAIAgent
# OpenAIAgent initialisieren
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
Hinweis: Wenn verbose=true in LLMs gesetzt ist, erhalten wir Einblick in den Denkprozess des Modells, was es uns ermöglicht, zu verstehen, wie es zu seinen Antworten kommt, indem es detaillierte Erklärungen und Schlussfolgerungen liefert.
Unabhängig von der Initialisierungsmethode können Sie die Agenten mit der gleichen Methode testen. Testen wir zuerst den benutzerdefinierten Agenten:
# Benutzerdefinierten Agenten aufrufen
agent = agent.chat("Wie viel kostet BOYS NIKE DF STOCK RECRUIT PANT DJ573?")
Sie sollten ein ähnliches Ergebnis wie dieses erhalten:
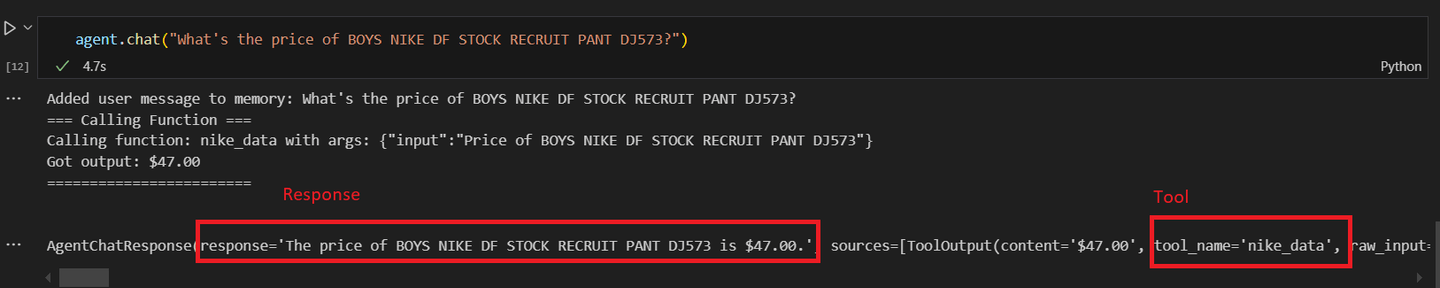
Nun rufen wir den ersten benutzerdefinierten Agenten mit der mathematischen Operation auf.
# Den zweiten Agenten aufrufen
response = agent1.chat("Was ist 2+2?")
Nachdem der zweite Agent aufgerufen wurde und nach einer mathematischen Operation gefragt wurde, erhalten Sie eine ähnliche Antwort:
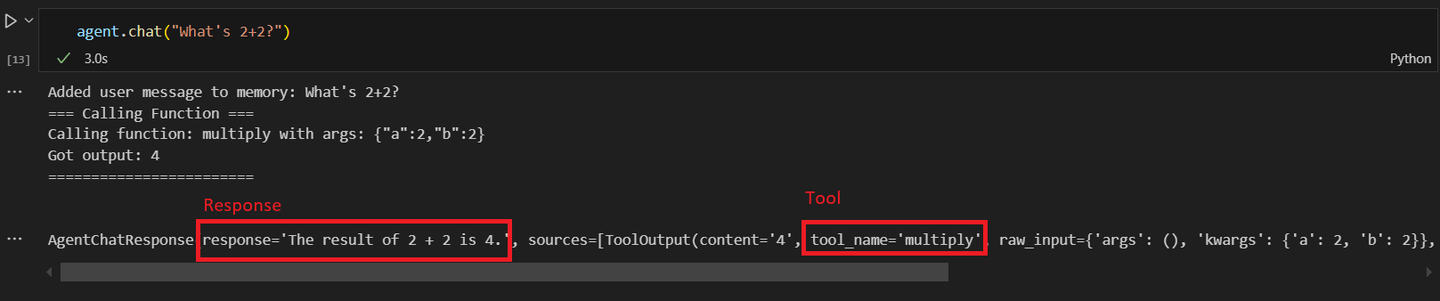
Das Potenzial von KI-Agenten, komplexe Aufgaben autonom zu bewältigen, nimmt zu und macht sie in Unternehmen unverzichtbar, wo sie routinemäßige Aufgaben verwalten und menschliche Mitarbeiter für wertschöpfendere Tätigkeiten freisetzen können. Mit fortschreitender Entwicklung wird erwartet, dass die Nutzung von KI-Agenten weiter zunimmt und damit die Art und Weise, wie wir mit Technologie interagieren und unsere Arbeitsabläufe optimieren, revolutioniert.
# Fazit
LlamaIndex-Agenten bieten eine intelligente Möglichkeit, Daten zu verwalten und zu verarbeiten, die über herkömmliche RAG-Systeme hinausgeht. Im Gegensatz zu statischen Datenpipelines treffen diese Agenten Echtzeitentscheidungen und passen ihre Aktionen anhand eingehender Daten an. Diese automatisierte Schlussfolgerung macht sie äußerst anpassungsfähig und effizient für komplexe Aufgaben. Sie integrieren verschiedene Werkzeuge, von grundlegenden Funktionen bis hin zu fortschrittlichen Abfrage-Engines, um Eingaben intelligent zu verarbeiten und optimierte Ergebnisse zu liefern.
MyScaleDB ist eine erstklassige Vektordatenbank, die besonders für große KI-Anwendungen geeignet ist. Ihr MSTG-Algorithmus (opens new window) übertrifft andere in Bezug auf Skalierbarkeit und Effizienz und eignet sich daher ideal für anspruchsvolle Umgebungen. MyScaleDB wurde entwickelt, um große Datensätze und komplexe Abfragen (opens new window) schnell zu verarbeiten und stellt so eine schnelle und präzise Datenabfrage sicher. Dies macht es zu einem unverzichtbaren Werkzeug für die Erstellung robuster und skalierbarer KI-Anwendungen, die nahtlos in andere Vektordatenbanken integriert werden können und eine überlegene Leistung im Vergleich zu anderen Vektordatenbanken bieten.
Wenn Sie mehr über den Aufbau eines KI-Agenten mit MyScaleDB erfahren möchten, folgen Sie uns auf X (Twitter) (opens new window) oder treten Sie unserer Discord (opens new window)-Community bei. Lassen Sie uns gemeinsam die Zukunft von Daten und KI gestalten!



