
In der sich ständig weiterentwickelnden Landschaft der künstlichen Intelligenz hat uns die Suche nach intelligenteren, reaktionsschnelleren und kontextbewussten Chatbots in eine neue Ära geführt. Willkommen in der Welt von RAG - Retrieval-Augmented Generation (RAG) (opens new window), einem bahnbrechenden Ansatz, der das umfangreiche Wissen von Retrieval-Systemen mit der kreativen Leistungsfähigkeit von generativen Modellen kombiniert. Die RAG-Technologie ermöglicht es Chatbots, jede Art von Benutzeranfrage effektiv zu bearbeiten, indem sie auf eine Wissensbasis zugreifen. Um diese Leistungsfähigkeit jedoch effektiv nutzen zu können, benötigen wir eine Speicherlösung, die ihre Geschwindigkeit und Effizienz erreichen kann. Hier kommen Vektordatenbanken ins Spiel, die einen Quantensprung in der Verwaltung und Abfrage großer Datenmengen bieten.
In diesem Blog zeigen wir Ihnen, wie Sie in wenigen Minuten einen RAG-betriebenen Chatbot mit Google Gemini-Modellen und MyScaleDB (opens new window) erstellen können.
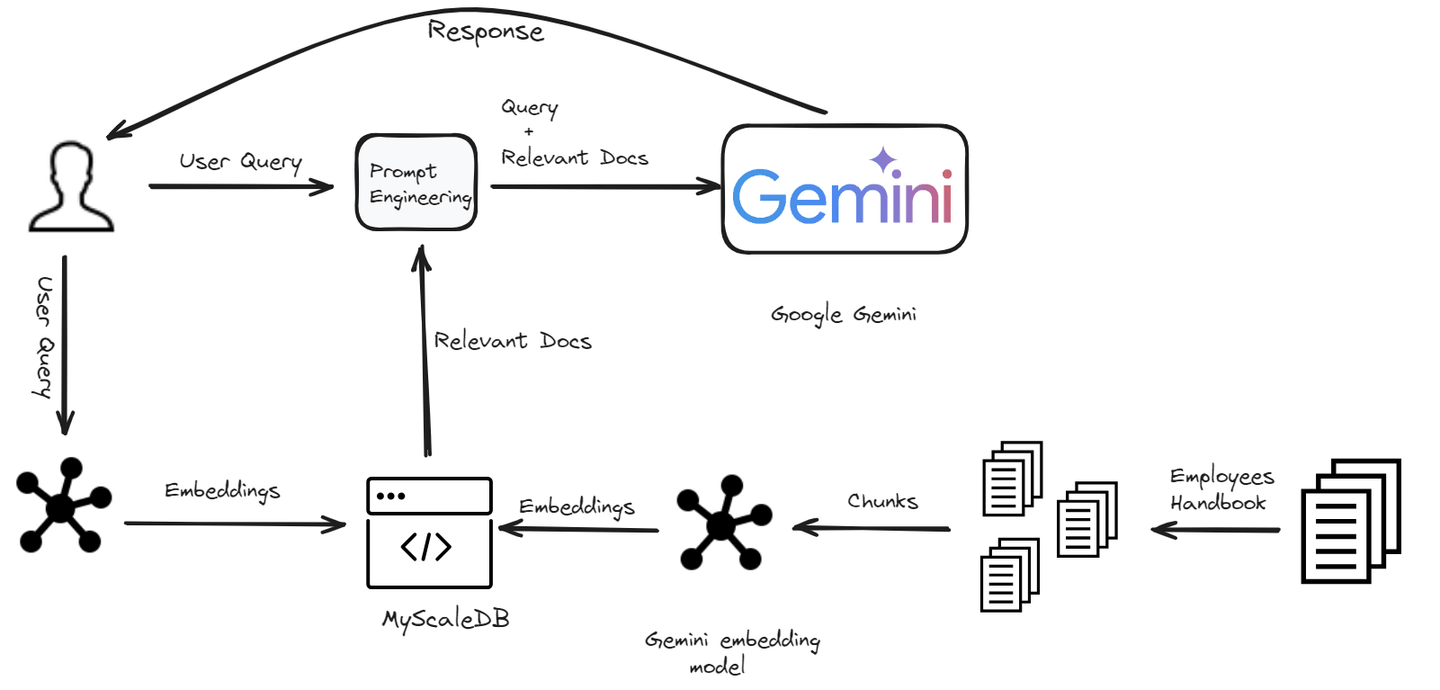
# Einrichten der Umgebung
# Installation der erforderlichen Software
Um unsere Reise zur Entwicklung eines Chatbots zu beginnen, müssen wir sicherstellen, dass die erforderlichen Abhängigkeiten installiert sind. Hier ist eine Aufschlüsselung der benötigten Tools:
Python (opens new window): Wir werden Python als Programmiersprache verwenden, um diesen Chatbot zu erstellen.
Gemini API (opens new window): Wir werden die Gemini API verwenden, um auf das Gemini LLM zuzugreifen und es in unserem Chatbot zu verwenden.
LangChain (opens new window): Es handelt sich um ein Framework, das Entwicklern ermöglicht, große Sprachmodelle und Vektordatenbanken zu integrieren, um skalierbare RAG-Anwendungen zu erstellen.
MyScaleDB (opens new window): Es handelt sich um eine SQL-Vektordatenbank, die speziell für die Entwicklung von KI-Anwendungen entwickelt wurde.
# Installation von Python
Wenn Python bereits auf Ihrem System installiert ist, können Sie diesen Schritt überspringen. Andernfalls befolgen Sie die folgenden Schritte.
Python herunterladen: Gehen Sie zur offiziellen Python-Website (opens new window) und laden Sie die neueste Version herunter.
Python installieren: Führen Sie den heruntergeladenen Installer aus und folgen Sie den Anweisungen auf dem Bildschirm. Stellen Sie sicher, dass Sie das Kontrollkästchen aktivieren, um Python zum Systempfad hinzuzufügen.
# Installation von Gemini, LangChain und MyScaleDB
Um all diese Abhängigkeiten zu installieren, geben Sie den folgenden Befehl in Ihrem Terminal ein:
pip install gemini-api langchain clickhouse-client
Der obige Befehl sollte alle erforderlichen Pakete installieren, um einen Chatbot zu entwickeln. Jetzt können wir mit dem Entwicklungsprozess beginnen.
# Aufbau des Chatbots
Wir bauen einen Chatbot, der speziell für Mitarbeiter eines Unternehmens entwickelt wurde. Dieser Chatbot wird den Mitarbeitern bei Fragen zu Unternehmensrichtlinien helfen. Vom Verständnis des Dresscodes bis zur Klärung von Urlaubsrichtlinien liefert der Chatbot schnelle und genaue Antworten.
# Laden und Aufteilen von Dokumenten
Der erste Schritt besteht darin, die Daten zu laden und mit dem PyPDFLoader-Modul von LangChain aufzuteilen.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
pages = pages[4:] # Die ersten Seiten werden übersprungen, da sie nicht benötigt werden
text = "\n".join([doc.page_content for doc in pages])
Wir laden das Dokument und teilen es in Seiten auf, wobei die ersten Seiten übersprungen werden. Der Text aller Seiten wird dann zu einem einzigen String zusammengefügt.
Note:
Wir verwenden dieses Handbuch aus einem Kaggle-Repository (opens new window).
Als nächstes teilen wir diesen Text in kleinere Abschnitte auf, um ihn im Chatbot leichter verarbeiten zu können.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=150,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.create_documents([text])
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
Hier verwenden wir RecursiveCharacterTextSplitter, um den Text in Abschnitte von jeweils 500 Zeichen aufzuteilen, wobei eine Überlappung von 150 Zeichen gewährleistet ist, um die Kontinuität zu gewährleisten.
# Generieren von Einbettungen
Um unseren Chatbot in die Lage zu versetzen, relevante Informationen zu verstehen und abzurufen, müssen wir für jeden Textabschnitt Einbettungen generieren. Diese Einbettungen sind numerische Darstellungen des Textes, die die semantische Bedeutung des Textes erfassen.
import os
import google.generativeai as genai
import pandas as pd
os.environ["GEMINI_API_KEY"] = "your_key_here"
# Diese Funktion nimmt einen Satz als Argument und gibt seine Einbettungen zurück
def get_embeddings(text):
# Das Einbettungsmodell definieren
model = 'models/embedding-001'
# Die Einbettungen abrufen
embedding = genai.embed_content(model=model,
content=text,
task_type="retrieval_document")
return embedding['embedding']
# Die page_content aus den Dokumenten abrufen und eine neue Liste erstellen
content_list = [doc.page_content for doc in docs]
# Eine page_content nach der anderen senden
embeddings = [get_embeddings(content) for content in content_list]
# Ein DataFrame erstellen, um es in die Datenbank einzufügen
dataframe = pd.DataFrame({
'page_content': content_list,
'embeddings': embeddings
})
Wir definieren eine Funktion get_embeddings, die Google Gemini verwendet, um Einbettungen für jeden Textabschnitt zu generieren. Diese Einbettungen werden in einem DataFrame für weitere Verarbeitung gespeichert.
Note:
Wir verwenden das Modell embedding-001 aus den Gemini-Modellen und Sie können die Gemini API hier (opens new window) erhalten.
# Speichern der Daten in MyScaleDB
Nachdem wir die Textabschnitte und die zugehörigen Einbettungen bereit haben, ist der nächste Schritt, diese Daten in MyScaleDB zu speichern. Dadurch können wir später effiziente Abrufoperationen durchführen. Beginnen wir zunächst mit dem Herstellen einer Verbindung zu MyScaleDB.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your_host_name',
port="port_number,
username='your_username',
password='yiur_password_hhere'
)
Um die Anmeldeinformationen Ihres MyScaleDB-Kontos zu erhalten, folgen Sie der Schnellstartanleitung (opens new window).
# Erstellen einer Tabelle und Einfügen der Daten
Nachdem eine Verbindung zur Datenbank hergestellt wurde, besteht der nächste Schritt darin, eine Tabelle zu erstellen (weil MyScaleDB eine SQL-VektorDB ist) und die Daten einzufügen.
# Eine Tabelle mit dem Namen 'handbook' erstellen
client.command("""
CREATE TABLE default.handbook (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 768
) ENGINE = MergeTree()
ORDER BY id
""")
# Die CONSTRAINT stellt sicher, dass die Länge jedes Einbettungsvektors 768 beträgt
# Die Daten in Stapeln einfügen
batch_size = 10
num_batches = len(dataframe) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = dataframe[start_idx:end_idx]
# Die Daten einfügen
client.insert("default.handbook", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} eingefügt.")
# Einen Vektorindex erstellen, um Daten schnell abrufen zu können
client.command("""
ALTER TABLE default.handbook
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
Die Daten werden stapelweise eingefügt, um die Effizienz zu steigern, und es wird ein Vektorindex hinzugefügt, um schnelle Ähnlichkeitssuchen zu ermöglichen.
# Abrufen relevanter Dokumente
Sobald die Daten gespeichert sind, besteht der nächste Schritt darin, die relevantesten Dokumente für eine bestimmte Benutzeranfrage mithilfe der Einbettungen abzurufen.
def get_relevant_docs(user_query):
# Die Funktion get_embeddings erneut aufrufen, um die Benutzeranfrage in Vektoreinbettungen umzuwandeln
query_embeddings = get_embeddings(user_query)
# Die Abfrage durchführen
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.handbook ORDER BY dist LIMIT 3
""")
relevant_docs = []
for row in results.named_results():
relevant_docs.append(row['page_content'])
return relevant_docs
Diese Funktion generiert zunächst Einbettungen für die Benutzeranfrage und ruft dann die 3 relevantesten Textabschnitte aus der Datenbank basierend auf der Ähnlichkeit ihrer Einbettungen ab.
# Generieren einer Antwort
Schließlich verwenden wir die abgerufenen Dokumente, um eine Antwort auf die Benutzeranfrage zu generieren.
def make_rag_prompt(query, relevant_passage):
relevant_passage = ' '.join(relevant_passage)
prompt = (
f"Sie sind ein hilfsbereiter und informativer Chatbot, der Fragen mithilfe von Text aus dem unten stehenden Referenzabschnitt beantwortet. "
f"Antworten Sie in einem vollständigen Satz und stellen Sie sicher, dass Ihre Antwort für alle leicht verständlich ist. "
f"Behalten Sie einen freundlichen und gesprächigen Ton bei. Wenn der Abschnitt irrelevant ist, können Sie ihn ignorieren.\n\n"
f"FRAGE: '{query}'\n"
f"ABSCHNITT: '{relevant_passage}'\n\n"
f"ANTWORT:"
)
return prompt
import google.generativeai as genai
def generate_response(user_prompt):
model = genai.GenerativeModel('gemini-pro')
answer = model.generate_content(user_prompt)
return answer.text
def generate_answer(query):
relevant_text = get_relevant_docs(query)
text = " ".join(relevant_text)
prompt = make_rag_prompt(query, relevant_passage=relevant_text)
answer = generate_response(prompt)
return answer
answer = generate_answer(query="Was ist der Dresscode für die Arbeit?")
print(answer)
Die Funktion make_rag_prompt erstellt einen Hinweis für den Chatbot unter Verwendung der relevanten Dokumente. Die Funktion generate_response verwendet Google Gemini, um basierend auf dem Hinweis eine Antwort zu generieren, und die Funktion generate_answer verknüpft alles miteinander, ruft relevante Dokumente ab und generiert eine Antwort auf die Benutzeranfrage.
Hinweis: In diesem Blog verwenden wir Gemini Pro 1.0 (opens new window), da es in der kostenlosen Version mehr Anfragen pro Minute ermöglicht. Obwohl Gemini fortschrittlichere Modelle wie Gemini 1.5 Pro (opens new window) und Gemini 1.5 Flash (opens new window) bietet, haben diese Modelle strengere kostenlose Stufen und höhere Kosten bei umfangreicher Nutzung.
Einige Ausgaben des Chatbots sehen folgendermaßen aus:

Als der Chatbot nach der Mittagszeit im Büro gefragt wurde:

Indem Sie diese Schritte in Ihren Chatbot-Entwicklungsprozess integrieren, können Sie die Leistungsfähigkeit von Google Gemini und MyScaleDB nutzen, um einen anspruchsvollen, KI-gesteuerten Chatbot zu erstellen. Experimentieren Sie, um die Leistungsfähigkeit Ihres Chatbots kontinuierlich zu verbessern. Bleiben Sie neugierig, bleiben Sie innovativ und beobachten Sie, wie sich Ihr Chatbot zu einem beeindruckenden Gesprächspartner entwickelt!

# Fazit
Die Einführung von RAG hat den Prozess der Chatbot-Entwicklung revolutioniert, indem große Sprachmodelle wie Gemini oder GPT integriert wurden. Diese fortschrittlichen LLMs verbessern die Leistung von Chatbots, indem sie relevante Informationen aus einer Vektordatenbank abrufen und genauere, faktisch korrekte und kontextuell angemessene Antworten generieren. Diese Verschiebung reduziert nicht nur die Entwicklungszeit und -kosten, sondern verbessert auch das Benutzererlebnis mit intelligenteren und reaktionsschnelleren Chatbots erheblich.
Die Leistung eines RAG-Modells hängt stark von der Effizienz seiner Vektordatenbank ab. Die Fähigkeit einer Vektordatenbank, relevante Dokumente schnell abzurufen, ist entscheidend für die Bereitstellung schneller Antworten an Benutzer. Bei der Skalierung eines RAG-Systems wird die Aufrechterhaltung dieses hohen Leistungsniveaus noch wichtiger. MyScaleDB ist dafür eine ausgezeichnete Wahl, da es von ClickHouse eine hohe Skalierbarkeit erbt und blitzschnelle Abfrageantworten mit minimaler Latenz bietet. Sie dürfen nicht verpassen, dass es neuen Benutzern 5 Millionen kostenlose Vektorspeicher bietet, die problemlos für die Entwicklung einer Anwendung im kleinen Maßstab verwendet werden können.
Wenn Sie mehr mit uns besprechen möchten, sind Sie herzlich eingeladen, unserem MyScale Discord (opens new window) beizutreten, um Ihre Gedanken und Feedbacks zu teilen.



