
Retrieval-augmented generation (RAG) (opens new window) wird häufig verwendet, um maßgeschneiderte KI-Anwendungen wie Chatbots (opens new window), Empfehlungssysteme (opens new window) und andere personalisierte Tools zu entwickeln. Dieses System nutzt die Stärken von Vektordatenbanken und großen Sprachmodellen (LLMs), um hochwertige Ergebnisse zu liefern.
Die Auswahl des richtigen LLMs für ein RAG-Modell ist sehr wichtig und erfordert die Berücksichtigung von Faktoren wie Kosten, Datenschutzbedenken und Skalierbarkeit. Kommerzielle LLMs wie OpenAI's GPT-4 (opens new window) und Google's Gemini (opens new window) sind effektiv, können jedoch teuer sein und Datenschutzbedenken aufwerfen. Einige Benutzer bevorzugen Open-Source LLMs (opens new window) aufgrund ihrer Flexibilität und Kosteneinsparungen, aber sie erfordern erhebliche Ressourcen für das Feintuning (opens new window) und die Bereitstellung, einschließlich GPUs und spezialisierter Infrastruktur. Darüber hinaus kann die Verwaltung von Modellaktualisierungen und Skalierbarkeit bei lokalen Installationen eine Herausforderung darstellen.
Eine bessere Lösung besteht darin, ein Open-Source LLM auszuwählen und es in der Cloud bereitzustellen. Dieser Ansatz bietet die erforderliche Rechenleistung und Skalierbarkeit ohne die hohen Kosten und Komplexitäten der lokalen Bereitstellung. Dadurch werden nicht nur die anfänglichen Infrastrukturkosten gespart, sondern auch die Wartungsprobleme minimiert.
Lassen Sie uns einen ähnlichen Ansatz erkunden, um eine Anwendung mit Cloud-gehosteten Open-Source LLMs und einer skalierbaren Vektordatenbank zu entwickeln.
# Tools und Technologien
Für die Entwicklung dieser RAG-basierten KI-Anwendung sind mehrere Tools erforderlich. Dazu gehören:
- BentoML (opens new window): BentoML ist eine Open-Source-Plattform, die die Bereitstellung von Machine-Learning-Modellen in produktionsfertige APIs vereinfacht und Skalierbarkeit und einfache Verwaltung gewährleistet.
- LangChain (opens new window): LangChain ist ein Framework zum Erstellen von Anwendungen mit LLMs. Es bietet modulare Komponenten für eine einfache Integration und Anpassung.
- MyScaleDB (opens new window): MyScaleDB ist eine leistungsstarke, skalierbare Datenbank, die für effiziente Datenabfrage und -speicherung optimiert ist und erweiterte Abfragefunktionen unterstützt.
In diesem Tutorial werden Daten aus Wikipedia mithilfe des WikipediaLoader-Moduls von LangChain extrahiert und auf diesen Daten ein LLM erstellt.
Hinweis:
Sie finden das vollständige Python-Notebook (opens new window) im MyScale-Beispielrepository.
# Vorbereitung
# Umgebung einrichten
Beginnen Sie damit, Ihre Umgebung für die Verwendung von BentoML, MyScaleDB und LangChain in Ihrem System einzurichten, indem Sie Ihr Terminal öffnen und Folgendes eingeben:
pip install bentoml langchain clickhouse-connect
Dadurch werden alle drei Pakete in Ihrem System installiert. Danach sind Sie bereit, Code zu schreiben und die RAG-Anwendung zu entwickeln.
# Daten laden
Importieren Sie zunächst den WikipediaLoader (opens new window) aus dem Modul langchain_community.document_loaders.wikipedia. Sie verwenden diesen Loader, um Dokumente zu "Albert Einstein" von Wikipedia abzurufen.
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# Laden Sie die Dokumente
docs = loader.load()
# Zeigen Sie den Inhalt des ersten Dokuments an
print(docs[0].page_content)
Hier wird die Methode load verwendet, um die Dokumente zu "Albert Einstein" abzurufen, und die Methode print, um den Inhalt des ersten Dokuments zur Überprüfung der geladenen Daten anzuzeigen.
# Text in Abschnitte aufteilen
Importieren Sie den CharacterTextSplitter (opens new window) aus langchain_text_splitters, fügen Sie die Inhalte aller Seiten zu einem einzigen String zusammen und teilen Sie den Text in handhabbare Abschnitte auf.
from langchain_text_splitters import CharacterTextSplitter
# Text in Abschnitte aufteilen
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
Der CharacterTextSplitter ist so konfiguriert, dass dieser Text in Abschnitte von 400 Zeichen mit einer Überlappung von 100 Zeichen aufgeteilt wird, um sicherzustellen, dass zwischen den Abschnitten keine Informationen verloren gehen. Der Textinhalt oder Text wird im Array splits gespeichert, das nur den Textinhalt enthält. Sie verwenden das Array splits, um die Einbettungen (opens new window) zu erhalten.
# Modelle mit BentoML bereitstellen
Ihre Daten sind bereit, und der nächste Schritt besteht darin, die Modelle mit BentoML bereitzustellen und sie in Ihrer RAG (opens new window)-Anwendung zu verwenden. Stellen Sie zuerst das LLM bereit. Sie benötigen ein kostenloses BentoML-Konto, und Sie können sich bei Bedarf bei BentoCloud anmelden (opens new window). Navigieren Sie dann zum Bereich "Bereitstellungen" und klicken Sie auf die Schaltfläche "Bereitstellung erstellen" in der oberen rechten Ecke. Es wird eine neue Seite geöffnet, die wie folgt aussieht:
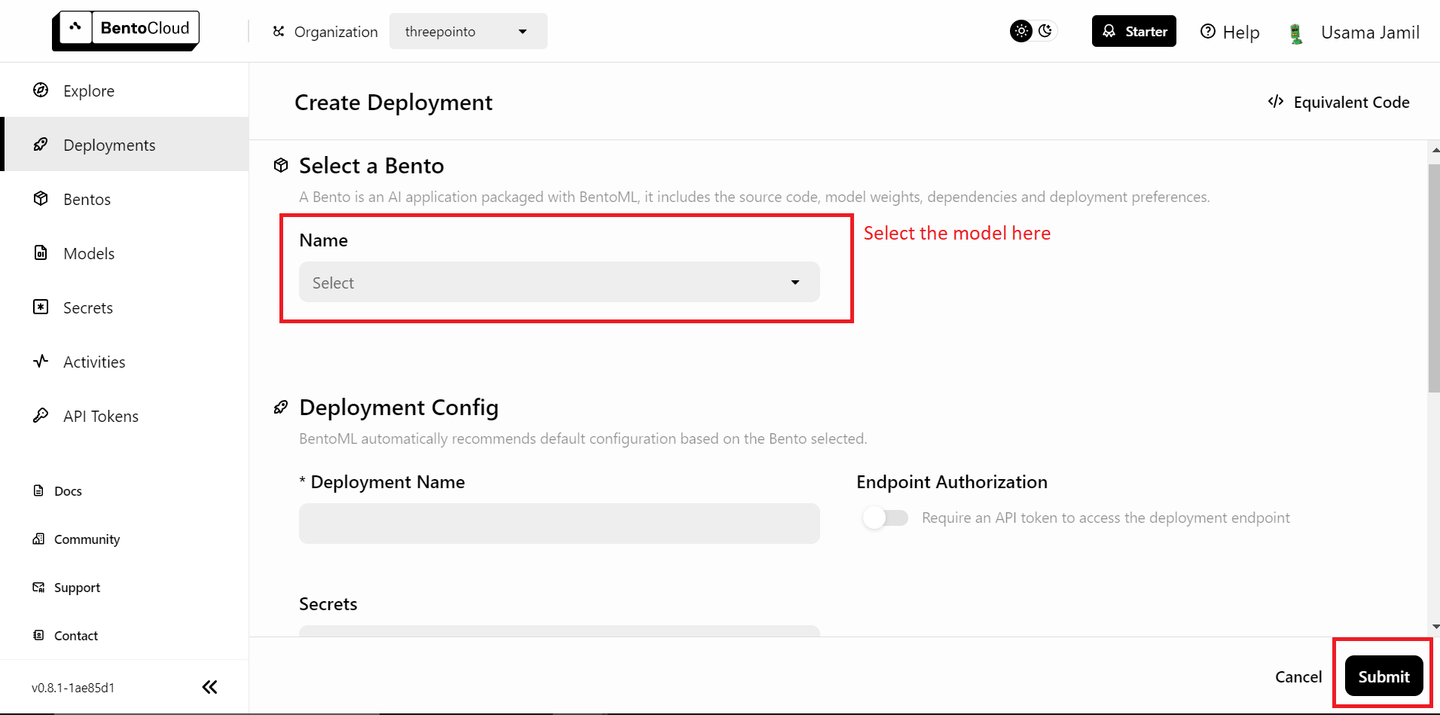
Wählen Sie das Modell "bentoml/bentovllm-llama3-8b-instruct-service (opens new window)" aus dem Dropdown-Menü aus und klicken Sie auf "Senden" in der unteren rechten Ecke. Dadurch wird die Bereitstellung gestartet. Es wird eine neue Seite wie diese geöffnet:
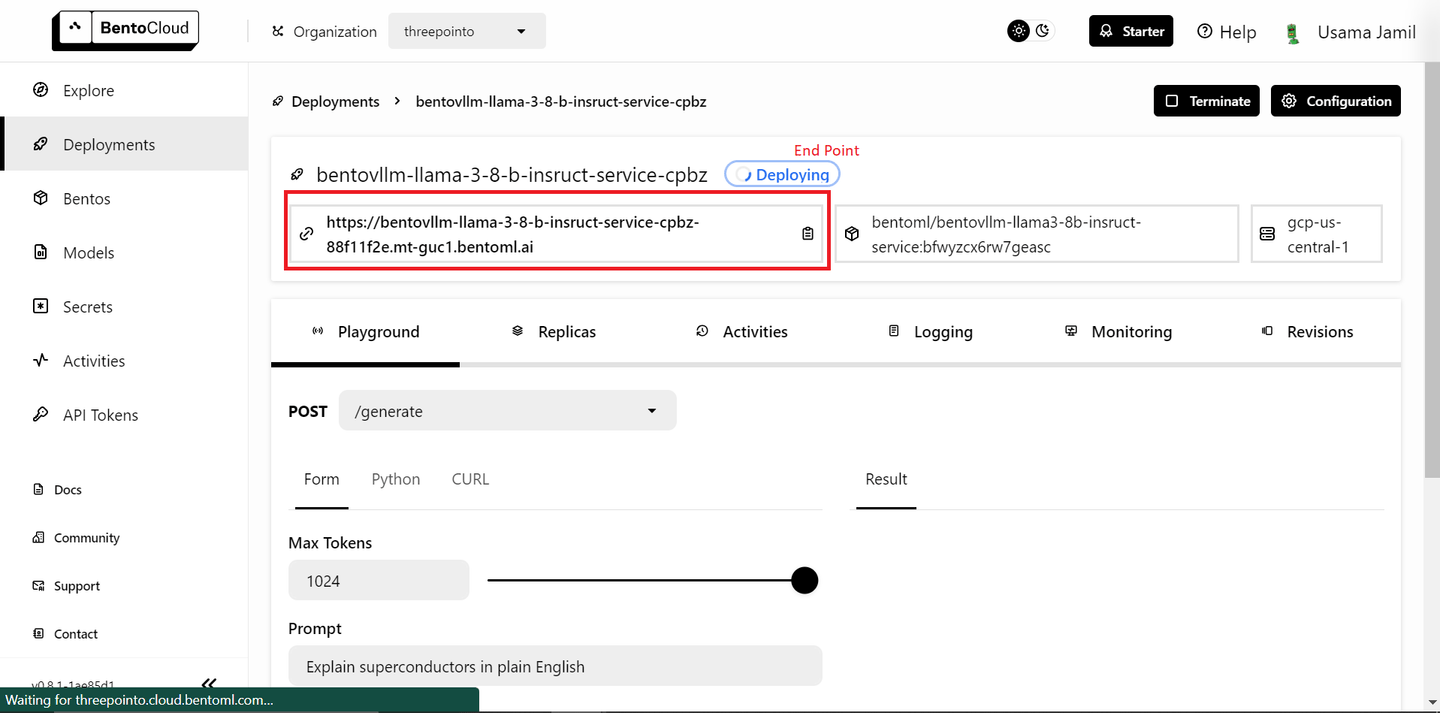
Die Bereitstellung kann einige Zeit dauern. Sobald sie bereitgestellt ist, kopieren Sie den Endpunkt.
Hinweis:
Die kostenlose Stufe von BentoML ermöglicht nur die Bereitstellung eines einzelnen Modells. Wenn Sie einen kostenpflichtigen Plan haben und mehr als ein Modell bereitstellen können, befolgen Sie die unten stehenden Schritte. Andernfalls machen Sie sich keine Sorgen - wir werden ein Open-Source-Modell lokal für Einbettungen verwenden.
Das Bereitstellen des Einbettungsmodells ist sehr ähnlich wie das Bereitstellen des LLMs:
- Gehen Sie zur Seite "Bereitstellungen".
- Klicken Sie auf die Schaltfläche "Bereitstellung erstellen".
- Wählen Sie das Modell
sentence-transformersaus der Liste aus und klicken Sie auf "Senden". - Sobald die Bereitstellung abgeschlossen ist, kopieren Sie den Endpunkt.
Gehen Sie als Nächstes zur API-Token-Seite (opens new window) und generieren Sie einen neuen API-Schlüssel. Jetzt sind Sie bereit, die bereitgestellten Modelle in Ihrer RAG-Anwendung zu verwenden.
# Einbettungsmethode definieren
Definieren Sie eine Funktion namens get_embeddings, um Einbettungen für den bereitgestellten Text zu generieren. Diese Funktion hat drei Argumente. Wenn der BentoML-Endpunkt und das API-Token angegeben sind, verwendet die Funktion den Einbettungsdienst von BentoML. Andernfalls verwendet sie die lokalen Bibliotheken transformers und torch, um das Modell sentence-transformers/all-MiniLM-L6-v2 zu laden und Einbettungen zu generieren.
# Bibliotheken importieren
import subprocess
import sys
import numpy as np
# Pakete installieren, wenn der API-Schlüssel nicht angegeben ist
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# Einbettungsmethode definieren
def get_embeddings(texts: list, BENTO_EMBEDDING_MODEL_END_POINT=None, BENTO_API_TOKEN=None) -> list:
# Wenn der BentoML-Schlüssel angegeben ist, verwendet die Methode das BENTOML-Modell, um Einbettungen zu erhalten
if BENTO_EMBEDDING_MODEL_END_POINT and BENTO_API_TOKEN:
import bentoml
embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT, token=BENTO_API_TOKEN)
return embedding_client.encode(sentences=texts).tolist()
# Andernfalls wird die transformers-Bibliothek verwendet
else:
# Transformers und Torch installieren, wenn sie noch nicht installiert sind
try:
import transformers
except ImportError:
install("transformers")
try:
import torch
except ImportError:
install("torch")
from transformers import AutoTokenizer, AutoModel
# Tokenizer und Modell für Einbettungen initialisieren
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
Diese Einrichtung ermöglicht die Flexibilität für BentoML-Benutzer der kostenlosen Stufe, die jeweils nur ein Modell bereitstellen können. Wenn Sie eine kostenpflichtige Version von BentoML haben und zwei Modelle bereitstellen können, können Sie den BentoML-Endpunkt und das Bento-API-Token übergeben, um das bereitgestellte Einbettungsmodell zu verwenden.
# Einbettungen abrufen
Iterieren Sie über die Textabschnitte (splits) in Stapeln von 25, um Einbettungen mithilfe der oben definierten Funktion get_embeddings zu generieren.
all_embeddings = []
# Die Abschnitte in Stapeln von 25 übergeben
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
# Den Stapel an die Methode get_embeddings übergeben
embeddings_batch = get_embeddings(batch)
# Die Einbettungen der all_embeddings-Liste hinzufügen, die die Einbettungen des gesamten Datensatzes enthält
all_embeddings.extend(embeddings_batch)
Dies verhindert eine Überlastung des Einbettungsmodells mit zu vielen Daten auf einmal, was besonders nützlich sein kann, um den Speicher- und Rechenressourcenbedarf zu verwalten.
# DataFrame erstellen
Erstellen Sie nun ein pandas (opens new window) DataFrame, um die Textabschnitte und ihre entsprechenden Einbettungen zu speichern.
import pandas as pd
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
Dieses strukturierte Format erleichtert die Manipulation und Speicherung der Daten in MyScaleDB.
# Mit MyScaleDB verbinden
Die Wissensbasis ist vollständig, und jetzt ist es an der Zeit, die Daten in der Vektordatenbank zu speichern. In diesem Demo wird MyScaleDB für die Vektorspeicherung verwendet. Starten Sie eine MyScaleDB-Cluster in einer Cloud-Umgebung, indem Sie der Schnellstartanleitung (opens new window) folgen. Anschließend können Sie eine Verbindung zur MyScaleDB-Datenbank mithilfe der Bibliothek clickhouse_connect herstellen.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='Ihr-Host-Name',
port=443,
username='Ihr-Benutzername',
password='Ihr-Passwort'
)
Das hier erstellte Client-Objekt wird verwendet, um SQL-Befehle auszuführen und mit der Datenbank zu interagieren.
# Tabelle erstellen und Daten einfügen
Erstellen Sie eine Tabelle in MyScaleDB, um die Textabschnitte und Einbettungen zu speichern. Das Tabellenschema umfasst eine id, den page_content und die embeddings.
# Tabelle RAG erstellen
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# Daten in die Tabelle einfügen
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} eingefügt.")
Dadurch wird sichergestellt, dass die Einbettungen eine feste Länge von 384 haben. Die Daten aus dem DataFrame werden dann in Stapeln in die Tabelle eingefügt, um große Daten effizient zu verwalten.
# Einen Vektorindex erstellen
Der nächste Schritt besteht darin, einen Vektorindex in der Spalte embeddings in der Tabelle RAG hinzuzufügen. Der Vektorindex ermöglicht effiziente Ähnlichkeitssuchen, die für Retrieval-augmented Generation-Aufgaben unerlässlich sind.
client.command("""
ALTER TABLE default.RAG
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Relevante Vektoren abrufen
Definieren Sie eine Funktion, um relevante Dokumente basierend auf einer Benutzerabfrage abzurufen. Die Abfrageeinbettungen werden mithilfe der Funktion get_embeddings generiert, und es wird eine erweiterte SQL-Vektorabfrage ausgeführt, um die nächstgelegenen Übereinstimmungen in der Datenbank zu finden.
def get_relevant_docs(user_query, top_k):
query_embeddings = get_embeddings(user_query)[0]
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.RAG ORDER BY dist LIMIT {top_k}
""")
relevant_docs = " "
for row in results.named_results():
relevant_docs=relevant_docs + row["page_content"]
return relevant_docs
# Beispielabfrage
message="Wer ist Albert Einstein?"
relevant_docs = get_relevant_docs(message, 8)
print(relevant_docs)
Die Ergebnisse werden nach Entfernung sortiert, und die obersten k Übereinstimmungen werden zurückgegeben. Diese Einrichtung findet die relevantesten Dokumente für eine bestimmte Abfrage.
Hinweis:
Die Methode distance nimmt eine Einbettungsspalte und den Einbettungsvektor der Benutzerabfrage an, um ähnliche Dokumente anhand der Kosinusähnlichkeit zu finden.
# Mit BentoML LLM verbinden
Stellen Sie eine Verbindung zu Ihrem gehosteten LLM in BentoML her. Das llm_client-Objekt wird verwendet, um mit dem LLM zu interagieren und basierend auf den abgerufenen Dokumenten Antworten zu generieren.
import bentoml
BENTO_LLM_END_POINT = "Geben Sie Ihren-Endpunkt-hier-ein"
llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT, token="Geben Sie Ihren-Token-hier-ein")
Ersetzen Sie BENTO_LLM_END_POINT und token durch die Werte, die Sie zuvor während der LLM-Bereitstellung kopiert haben.
# RAG durchführen
Definieren Sie eine Funktion, um RAG durchzuführen. Die Funktion nimmt eine Benutzerfrage und den abgerufenen Kontext als Eingabe entgegen. Sie erstellt eine Anweisung für das LLM, in der es angewiesen wird, die Frage basierend auf dem bereitgestellten Kontext zu beantworten. Die Antwort des LLM wird dann als Antwort zurückgegeben.
def dorag(question: str, context: str):
# Vorlage für die Anweisung definieren
prompt = (f"Du bist ein hilfreicher Assistent. Der Benutzer hat eine Frage. Beantworte die Benutzerfrage nur basierend auf dem Kontext: {context}. \\n"
f"Die Benutzerfrage lautet {question}")
# LLM-Endpunkt mit der oben definierten Vorlage aufrufen
results = llm_client.generate(
max_tokens=1024,
prompt=prompt,
)
res = ""
for result in results:
res += result
return res

# Eine Abfrage stellen
Schließlich können Sie es testen, indem Sie eine Abfrage an die RAG-Anwendung stellen. Stellen Sie die Frage "Wer ist Albert Einstein?" und verwenden Sie die Funktion dorag, um die Antwort basierend auf den zuvor abgerufenen relevanten Dokumenten zu erhalten.
query = "Wer ist Albert Einstein?"
dorag(question=query, context=relevant_docs)
Die Ausgabe liefert eine ausführliche Antwort auf die Frage und demonstriert die Effektivität der RAG-Einrichtung.

Wenn Sie das RAG-Modell nach Albert Einsteins Tod fragen, sollte die Antwort so aussehen:

# Fazit
BentoML zeichnet sich als hervorragende Plattform zur Bereitstellung von Machine-Learning-Modellen aus, einschließlich LLMs, ohne den Aufwand der Ressourcenverwaltung. Mit BentoML können Sie Ihre KI-Anwendungen schnell und skalierbar in der Cloud bereitstellen und sicherstellen, dass sie produktionsbereit und hoch zugänglich sind. Durch seine Einfachheit und Flexibilität ist es eine ideale Wahl für Entwickler, die sich mehr auf Innovation konzentrieren und weniger auf Bereitstellungsprobleme.
Auf der anderen Seite ist MyScaleDB speziell für RAG-Anwendungen entwickelt und bietet eine leistungsstarke SQL-Vektordatenbank. Die vertraute SQL-Syntax von MyScaleDB erleichtert Entwicklern die Integration und Verwendung von MyScaleDB in ihren Anwendungen, da die Lernkurve minimal ist. Der Multi-Scale Tree Graph (MSTG) (opens new window)-Algorithmus von MyScaleDB übertrifft andere Vektordatenbanken in Bezug auf Geschwindigkeit und Genauigkeit. Darüber hinaus enthält MyScaleDB für neue Benutzer den Zugriff auf 5 Millionen 768D-Vektoren an Speicherplatz, was es zu einer attraktiven Option für Entwickler macht, die effiziente und skalierbare KI-Lösungen implementieren möchten.
Was halten Sie von diesem Projekt? Teilen Sie Ihre Gedanken auf Twitter (opens new window) und Discord (opens new window).
Dieser Artikel wurde ursprünglich auf The New Stack veröffentlicht. (opens new window)



