
Große Sprachmodelle (LLMs) haben mit ihrer Fähigkeit, menschenähnlichen Text zu verstehen und zu generieren, einen immensen Mehrwert gebracht. Diese Modelle bringen jedoch auch bemerkenswerte Herausforderungen mit sich. Sie werden auf umfangreichen Datensätzen trainiert, die einen erheblichen Aufwand an Kosten und Zeit erfordern. Der hohe Aufwand an Kosten und Zeit, um diese Modelle regelmäßig neu zu trainieren, macht es nahezu unmöglich, sie regelmäßig zu aktualisieren. Diese Einschränkung bedeutet, dass sie oft nicht mit den neuesten Daten aktualisiert werden und bei Abfragen zu unbekannten Themen potenzielle Ungenauigkeiten auftreten können. Dieses Phänomen wird als "Halluzination" bezeichnet und kann die Leistung von Anwendungen beeinträchtigen und Bedenken hinsichtlich ihrer Zuverlässigkeit und Authentizität aufwerfen.
Um Halluzinationen zu überwinden, werden verschiedene Techniken eingesetzt, wobei die Retrieval Augmented Generation (RAG) die am weitesten verbreitete ist, aufgrund ihrer Effizienz und Leistung.
Ich werde zeigen, wie man ein vollständiges fortschrittliches RAG-System entwirft, das in Produktionsumgebungen eingesetzt werden kann.
# Was ist Retrieval Augmented Generation
RAG ist die am weitesten verbreitete Technik zur Überwindung von Halluzinationen. Sie stellt sicher, dass LLMs auf dem neuesten Stand der neuesten Informationen bleiben und bessere Antworten liefern. Dabei werden relevante externe Daten während der Antwortgenerierungsphase des Modells dynamisch abgerufen. Dieser Ansatz ermöglicht es dem LLM, auf die aktuellsten Informationen zuzugreifen, ohne dass eine häufige Neuschulung erforderlich ist. Dadurch werden die Antworten des Modells genauer und kontextuell angemessen.
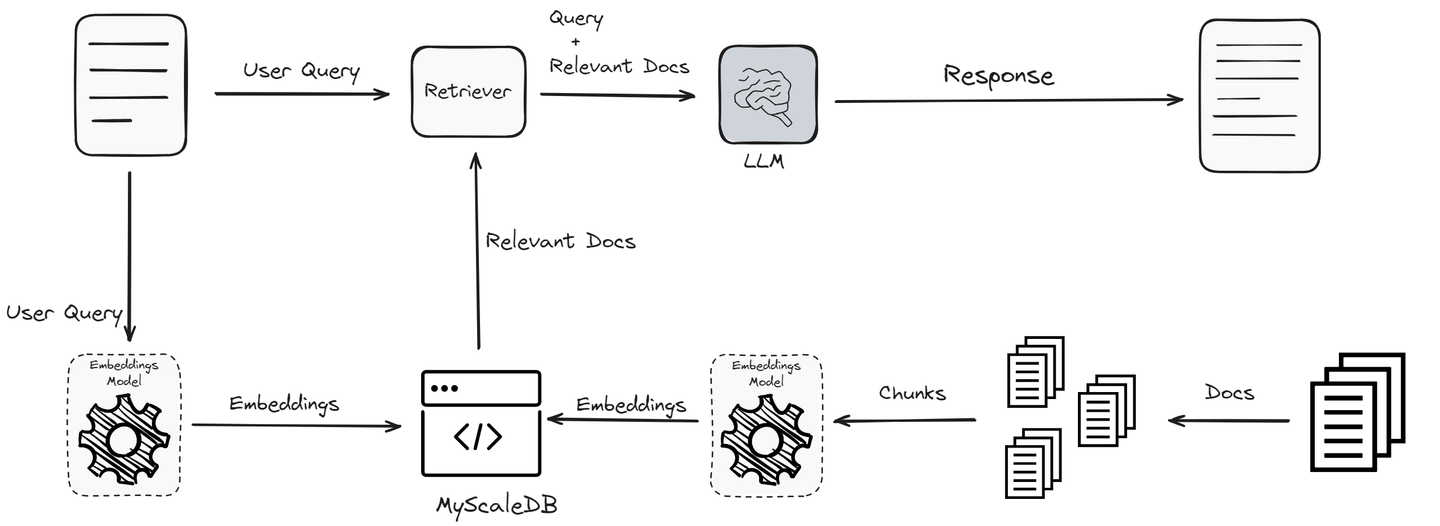
Der Prozess beginnt mit einer Benutzerabfrage, die mithilfe eines Einbettungsmodells in Einbettungen umgewandelt wird, um ihre semantische Essenz zu erfassen. Diese Einbettungen werden dann einer Ähnlichkeitssuche gegen Vektoren in einer Wissensbasis oder Vektor-Datenbank unterzogen, um die relevantesten Informationen zu identifizieren. Die Top-"K" Ergebnisse dieser Suche werden als zusätzlicher Kontext in das LLM integriert.
Durch die Verarbeitung sowohl der ursprünglichen Abfrage als auch dieser ergänzenden Daten ist das LLM in der Lage, genauere und kontextuell relevantere Antworten zu generieren. Dies behebt nicht nur das Problem der Halluzinationen, sondern stellt auch sicher, dass die Ausgaben des Modells auf dem neuesten Stand und zuverlässig bleiben, ohne dass eine häufige Neuschulung erforderlich ist.
Verwandte Artikel: Wie funktioniert RAG (opens new window)
# Was ist LlamaIndex
LlamaIndex (opens new window), früher bekannt als GPT Index, fungiert als Bindeglied, das Ihnen hilft, LLMs und Wissensbasen zu verbinden. Es bietet einige integrierte Methoden zum Abrufen von Daten aus verschiedenen Quellen und zur Verwendung in Ihren RAG-Anwendungen. Dazu gehören verschiedene Dateiformate wie PDFs und PowerPoints, Anwendungen wie Notion und Slack sowie Datenbanken wie Postgres und MyScaleDB.
LlamaIndex bietet wichtige Tools, die bei der Sammlung, Organisation, Abfrage und Integration von Daten mit verschiedenen Anwendungsframeworks helfen. Es erleichtert den Zugriff und die Verwendung Ihrer Daten und ermöglicht es Ihnen, leistungsstarke, maßgeschneiderte LLM-Anwendungen und Workflows zu erstellen.
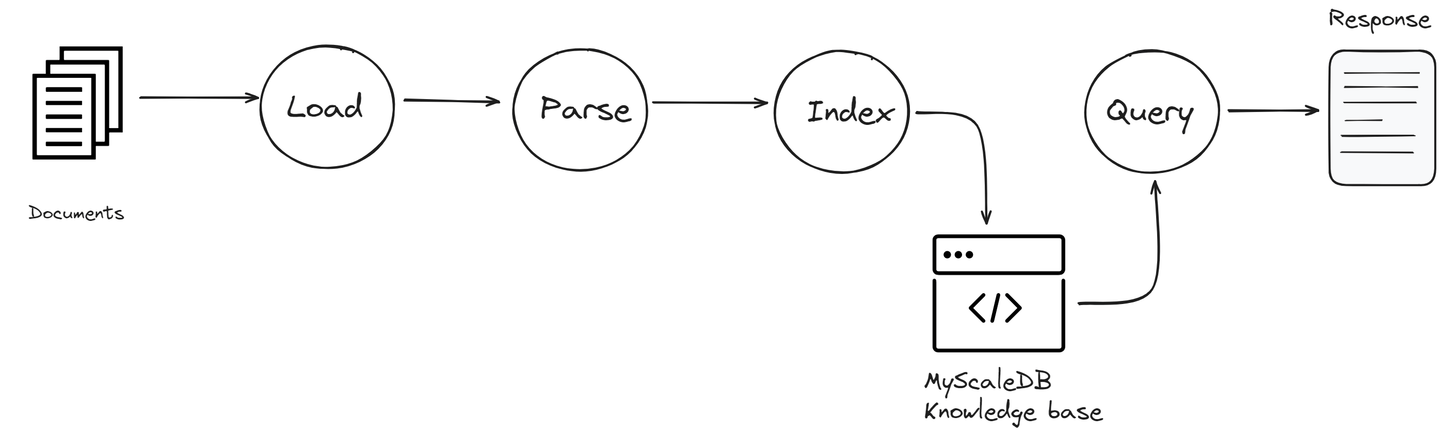
Einige der Hauptkomponenten von LlamaIndex sind:
- Datenverbindungen: Diese ermöglichen es LlamaIndex, auf verschiedene Datenquellen zuzugreifen. Ob Verbindung zu einem lokalen Dateisystem, einem Cloud-basierten Speicherdienst oder einer Datenbank, diese Verbindungen erleichtern das Abrufen der erforderlichen Informationen.
- Index: Der Index in LlamaIndex ist eine entscheidende Komponente, die Daten so organisiert, dass sie schnell zugänglich sind. Er kategorisiert die Informationen aus allen verbundenen Quellen in einem strukturierten Format, das leicht durchsucht werden kann. Dies beschleunigt den Abrufvorgang und stellt sicher, dass die relevantesten Informationen für das LLM verfügbar sind, wenn sie benötigt werden.
- Abfrage-Engine: Diese Komponente ist darauf ausgelegt, effizient durch die verbundenen Datenquellen zu suchen. Sie verarbeitet Ihre Abfragen, findet relevante Informationen und ruft sie ab, damit das LLM sie zur Generierung von Antworten verwenden kann.
Jede Komponente von LlamaIndex spielt eine wichtige Rolle bei der Verbesserung der Fähigkeiten von RAG-Anwendungen, indem sie sicherstellt, dass sie effizient auf eine Vielzahl von Daten zugreifen und diese nutzen können.
# Ein Überblick über MyScaleDB
MyScaleDB (opens new window) ist eine Open-Source-SQL-Vektor-Datenbank, die speziell für die Verwaltung großer Datenmengen für KI-Anwendungen entwickelt und optimiert wurde. Sie basiert auf ClickHouse (opens new window), einer SQL-Datenbank, die die Möglichkeit der Vektor-Ähnlichkeitssuche mit voller SQL-Unterstützung kombiniert.
Im Gegensatz zu spezialisierten Vektor-Datenbanken integriert MyScaleDB Vektor-Suchalgorithmen nahtlos mit strukturierten Datenbanken, sodass sowohl Vektoren als auch strukturierte Daten in derselben Datenbank verwaltet werden können. Diese Integration bietet Vorteile wie vereinfachte Kommunikation, flexible Metadatenfilterung, Unterstützung für SQL- und Vektor-Joint-Abfragen (opens new window) und Kompatibilität mit etablierten Tools, die normalerweise mit vielseitigen Datenbanken für allgemeine Zwecke verwendet werden.
Die Integration von MyScaleDB in RAG-Anwendungen verbessert RAG-Anwendungen, indem sie komplexere Dateninteraktionen ermöglicht, die sich direkt auf die Qualität des generierten Inhalts auswirken.
# RAG mit LlamaIndex und MyScaleDB: Ein Schritt-für-Schritt-Anleitung
Um die RAG-Anwendung zu erstellen, müssen wir zunächst ein Konto auf MyScaleDB erstellen, das als Wissensbasis verwendet wird. MyScaleDB bietet jedem neuen Benutzer kostenlosen Speicherplatz für bis zu 5 Millionen Vektoren, sodass keine anfängliche Zahlung erforderlich ist.
Sobald Sie Ihr Konto erstellt haben, gehen Sie zur Homepage und klicken Sie oben rechts auf "+ Neuer Cluster". Dadurch wird ein Dialogfeld wie dieses geöffnet:
Geben Sie den Namen des Clusters ein und klicken Sie auf "Weiter". Es dauert einige Sekunden, um Ihren Cluster zu initialisieren, und danach können Sie darauf zugreifen.
Um auf den Cluster zuzugreifen, können Sie zu Ihrem MyScaleDB-Profil zurückkehren, über den drei vertikal ausgerichteten Punkten unter dem Text "Aktionen" schweben und auf die Verbindungsdetails klicken.
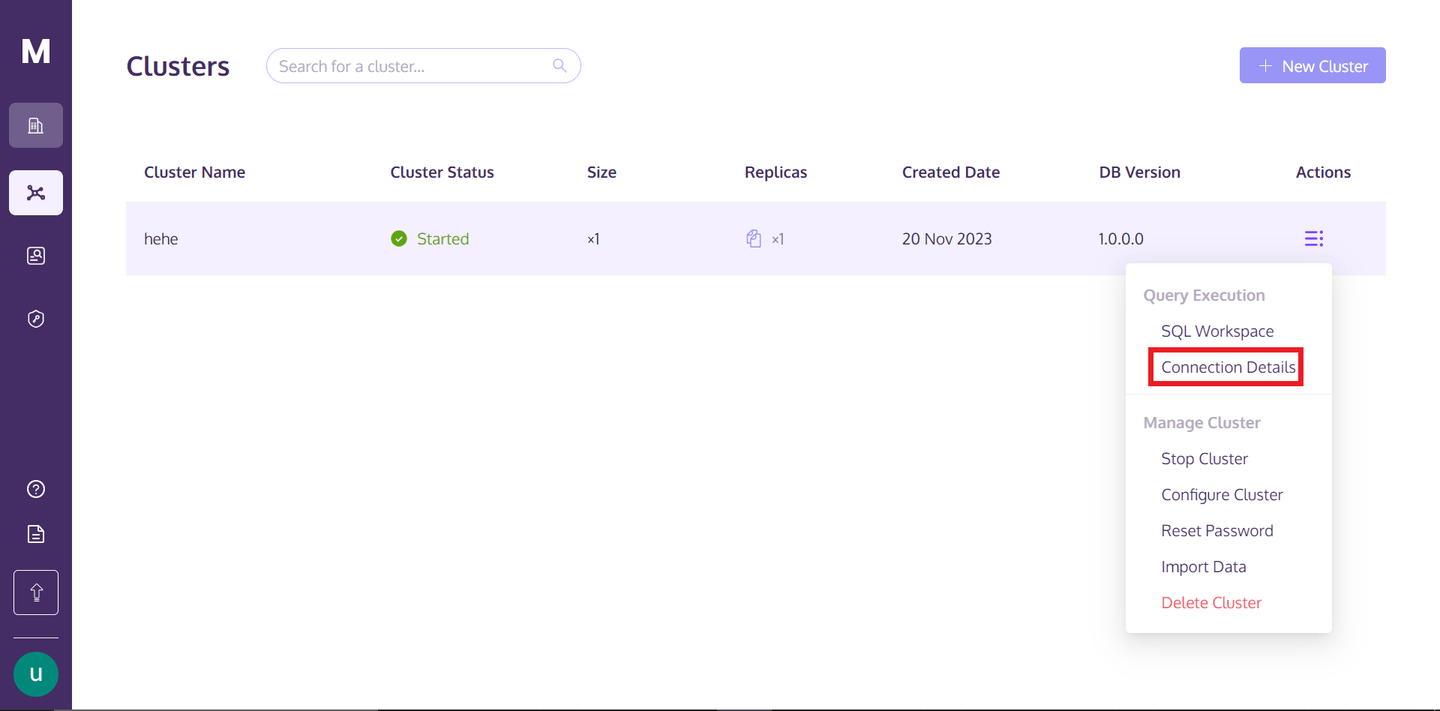
Sobald Sie auf "Verbindungsdetails" klicken, sehen Sie folgendes Feld:
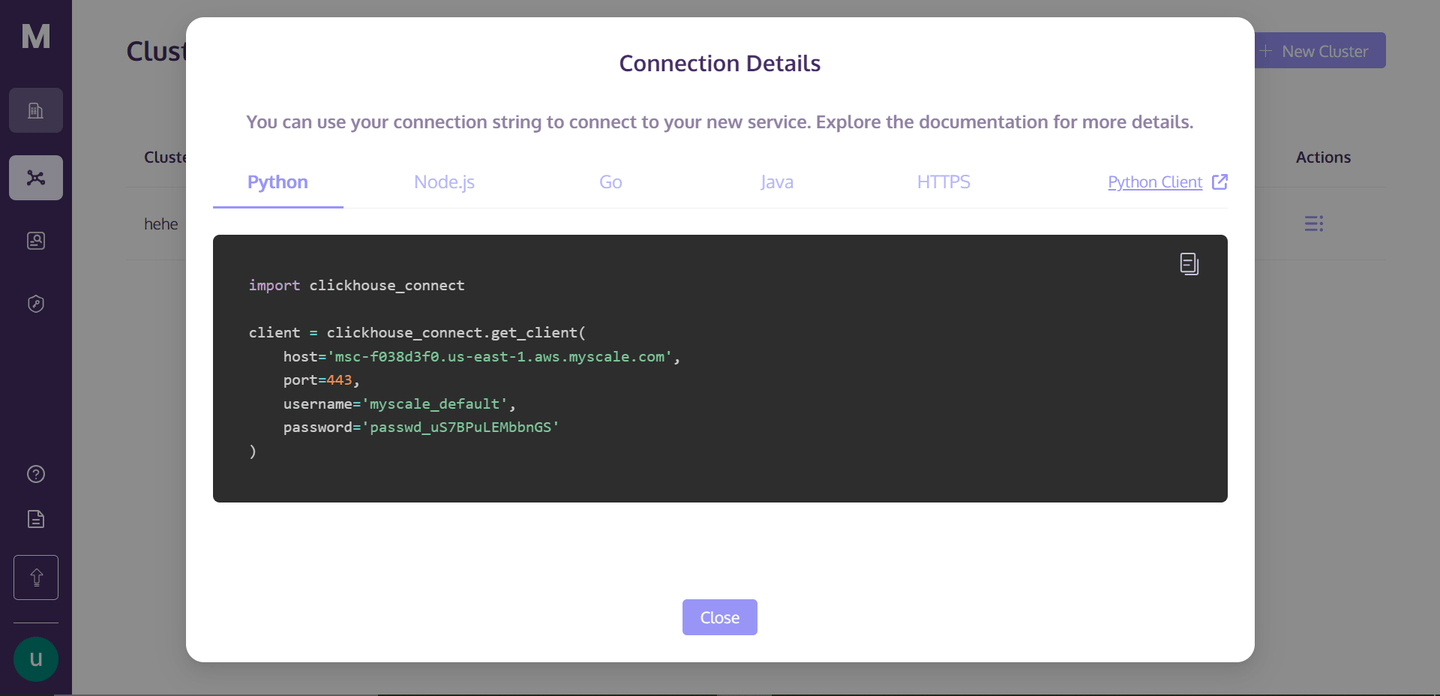
Dies sind die Verbindungsdetails, die Sie benötigen, um eine Verbindung zum Cluster herzustellen. Erstellen Sie einfach eine Python-Notebook-Datei in Ihrem Verzeichnis, und wir werden mit dem Aufbau unserer RAG-Anwendung beginnen.

# Einrichten der Umgebung
Um die Abhängigkeiten zu installieren, öffnen Sie Ihr Terminal und geben Sie den Befehl ein:
pip install -U llama-index clickhouse-connect llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-myscale
Dieser Befehl installiert alle erforderlichen Abhängigkeiten. Hier verwenden wir Jina Reranker (opens new window), dessen Algorithmus die Suchergebnisse signifikant verbessert, mit einer Steigerung der Trefferquote um mehr als 8% und einer Steigerung des durchschnittlichen reziproken Rangs um 33%.
# Herstellen einer Verbindung zur Wissensbasis
Zunächst müssen Sie eine Verbindung zur MyScale-Vektor-Datenbank herstellen. Dazu können Sie die Details von der Seite "Verbindungsdetails" kopieren und wie folgt einfügen:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='Ihr-Host',
port=443,
username='Ihr-Benutzername',
password='Ihr-Passwort-hier'
)
Es wird eine Verbindung zu Ihrer Wissensbasis hergestellt und ein Objekt erstellt.
# Daten herunterladen und laden
Hier verwenden wir einen Nike-Produktkatalog-Datensatz. Dieser Code lädt zuerst das .pdf herunter und speichert es lokal. Anschließend wird das .pdf mit dem LlamaIndex-Reader geladen.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = '<https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022>'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
# Kategorisieren der Daten
Diese Funktion kategorisiert die Dokumente in verschiedene Kategorien. Wir werden sie verwenden, wenn wir einige gefilterte Abfragen auf die gesamte Wissensbasis schreiben. Durch die Kategorisierung von Dokumenten können gezielte Suchen durchgeführt werden, was die Effizienz und Relevanz der Abfrage in dem RAG-System erheblich verbessert.
def analyze_and_assign_category(text):
if "Fußball" in text.lower():
return "Fußball"
elif "Basketball" in text.lower():
return "Basketball"
elif "Laufen" in text.lower():
return "Laufen"
else:
return "Nicht kategorisiert"
# Einen Index erstellen
Hier laden wir die Daten in einen Vektor-Speicher, der von MyScaleVectorStore bereitgestellt wird. Zuerst wird die Metadaten für jedes Dokument hinzugefügt und dann dem Vektor-Speicher hinzugefügt. Das Erstellen eines Index ermöglicht schnelle und effiziente Suchoperationen. Durch die Indizierung der Daten kann das System schnelle vektorbasierte Suchen durchführen, die für die Abrufung relevanter Dokumente basierend auf Ähnlichkeitsmaßen in RAG-Anwendungen unerlässlich sind.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for document in documents:
category = analyze_and_assign_category(document.text)
document.metadata = {"Kategorie": category}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
Hinweis: Beim Erstellen eines Index mit MyScaleDB werden Einbettungsmodelle von OpenAI verwendet. Um dies zu ermöglichen, müssen Sie Ihren OpenAI-Schlüssel als Umgebungsvariable hinzufügen.
# Einfache Abfrage
Um eine einfache Abfrage auszuführen, müssen wir unseren vorhandenen Index in eine Abfrage-Engine umwandeln. Die Abfrage-Engine ist ein spezialisiertes Werkzeug, das Suchabfragen verarbeiten und interpretieren kann.
query_engine = index.as_query_engine()
response = query_engine.query("Ich möchte ein paar Laufschuhe")
print(response.source_nodes[0].text)
Mit der Abfrage-Engine führen wir eine Abfrage aus, um "Ich möchte ein paar Laufschuhe" zu finden. Die Engine verarbeitet diese Abfrage und sucht dann in den indizierten Dokumenten nach Übereinstimmungen, die die Abfragebedingungen am besten erfüllen.
# Gefilterte Abfrage
Hier wird die Abfrage-Engine mit Metadatenfiltern mithilfe der Klassen MetadataFilters und ExactMatchFilter konfiguriert. Der ExactMatchFilter wird auf das Metadatenfeld "Kategorie" angewendet, um nur Dokumente einzuschließen, die explizit als "Laufen" kategorisiert sind. Dieser Filter stellt sicher, dass die Abfrage-Engine nur Dokumente berücksichtigt, die mit dem Laufen zusammenhängen, was zu relevanteren und fokussierteren Ergebnissen führen kann. Die Konfiguration similarity_top_k=2 begrenzt die Suche auf die beiden ähnlichsten Dokumente, und vector_store_query_mode="hybrid" schlägt eine Kombination aus Vektor- und traditionellen Suchmethoden für optimale Ergebnisse vor.
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Kategorie", value="Laufen"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("Ich möchte ein paar Laufschuhe?")
print(response.source_nodes[0].text)
Diese Ausgabe sollte der Benutzerabfrage eng entsprechen und zeigen, wie effektiv Metadatenfilter die Präzision der Suchergebnisse verbessern können.
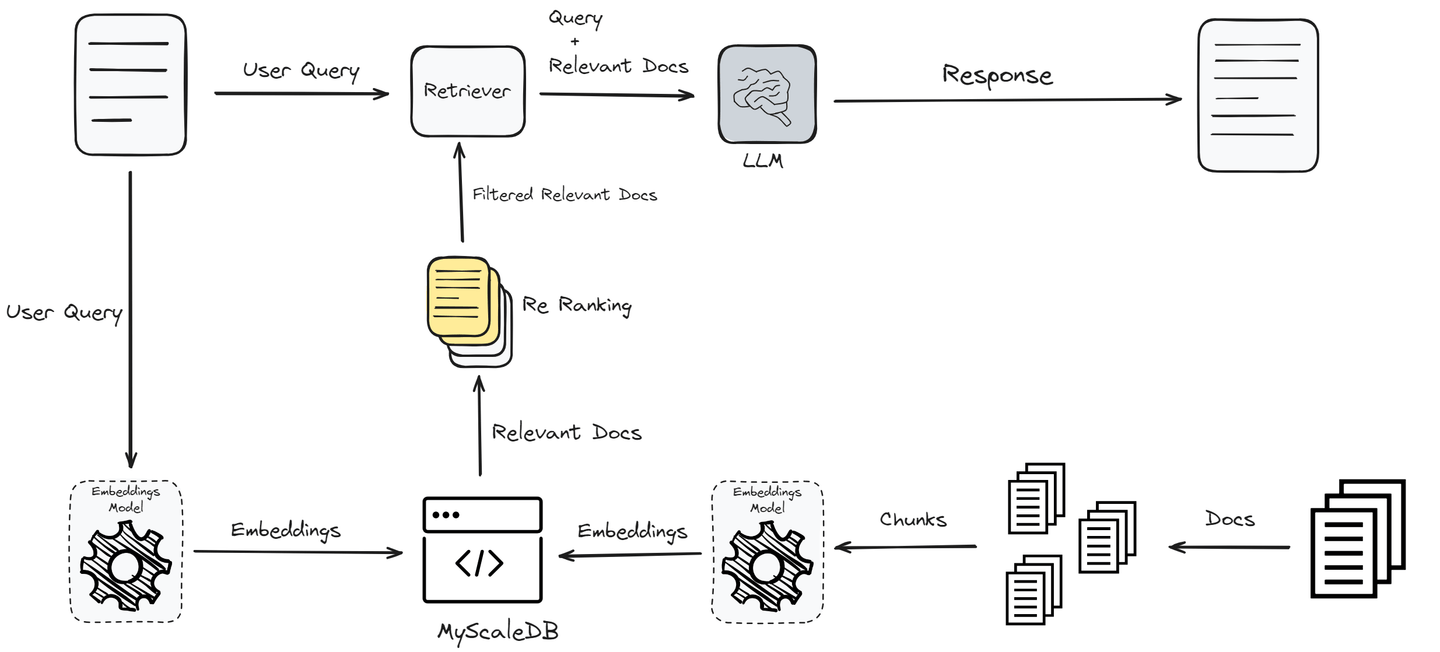
Bisher haben wir RAG in seiner einfachsten Form implementiert, was möglicherweise nicht die beste Leistung liefert. Um die Leistung zu verbessern und den Benutzern genaue Antworten zu liefern, werden wir nun einen Re-Ranker implementieren, der die abgerufenen Dokumente weiter filtert.
# Hinzufügen eines Re-Rankers zur Verbesserung der Dokumentenabfrage
Dieser Code integriert einen Re-Ranking-Mechanismus unter Verwendung von Jina AI, um die durch die anfängliche Abfrage abgerufenen Dokumente zu verfeinern.
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(api_key="API-Schlüssel-hier", top_n=2)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4", temperature=0)
query_engine = index.as_query_engine(
similarity_top_k=10, llm=llm, node_postprocessors=[jina_rerank]
)
response = query_engine.query("Ich möchte ein paar Laufschuhe?")
print(response.source_nodes[0].text)
Hinweis: Den Jina Reranker-Schlüssel finden Sie hier (opens new window). Klicken Sie auf die API und scrollen Sie auf der neu geöffneten Seite nach unten; Sie finden den API-Schlüssel direkt unter dem Abschnitt Reranker-API.
# Fazit
RAG hilft LLMs erheblich dabei, auf dem neuesten Stand zu bleiben und sicherzustellen, dass ihre Antworten genau und relevant sind. Einfache RAG-Systeme werden jedoch oft nicht in produktionsbereiten Anwendungen verwendet, aufgrund ihrer Leistung. Um die Leistung zu verbessern, verwenden wir fortgeschrittene Techniken wie Re-Ranking, Vorverarbeitung und gefilterte Abfragen.
Die Wahl der Vektor-Datenbank ist ein weiterer Faktor, der die Leistung von RAG-Systemen beeinflusst.
Es ist entscheidend, eine Vektor-Datenbank auszuwählen, die auf die Bedürfnisse Ihrer Anwendung zugeschnitten ist. MyScaleDB, als SQL-Vektor-Datenbank, ist eine gute Wahl für Entwickler, da sie eine vertraute SQL-Schnittstelle bietet und zudem erschwinglich, schnell und für Anwendungen auf Produktionsniveau optimiert ist.
Wenn Sie Vorschläge haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).



