
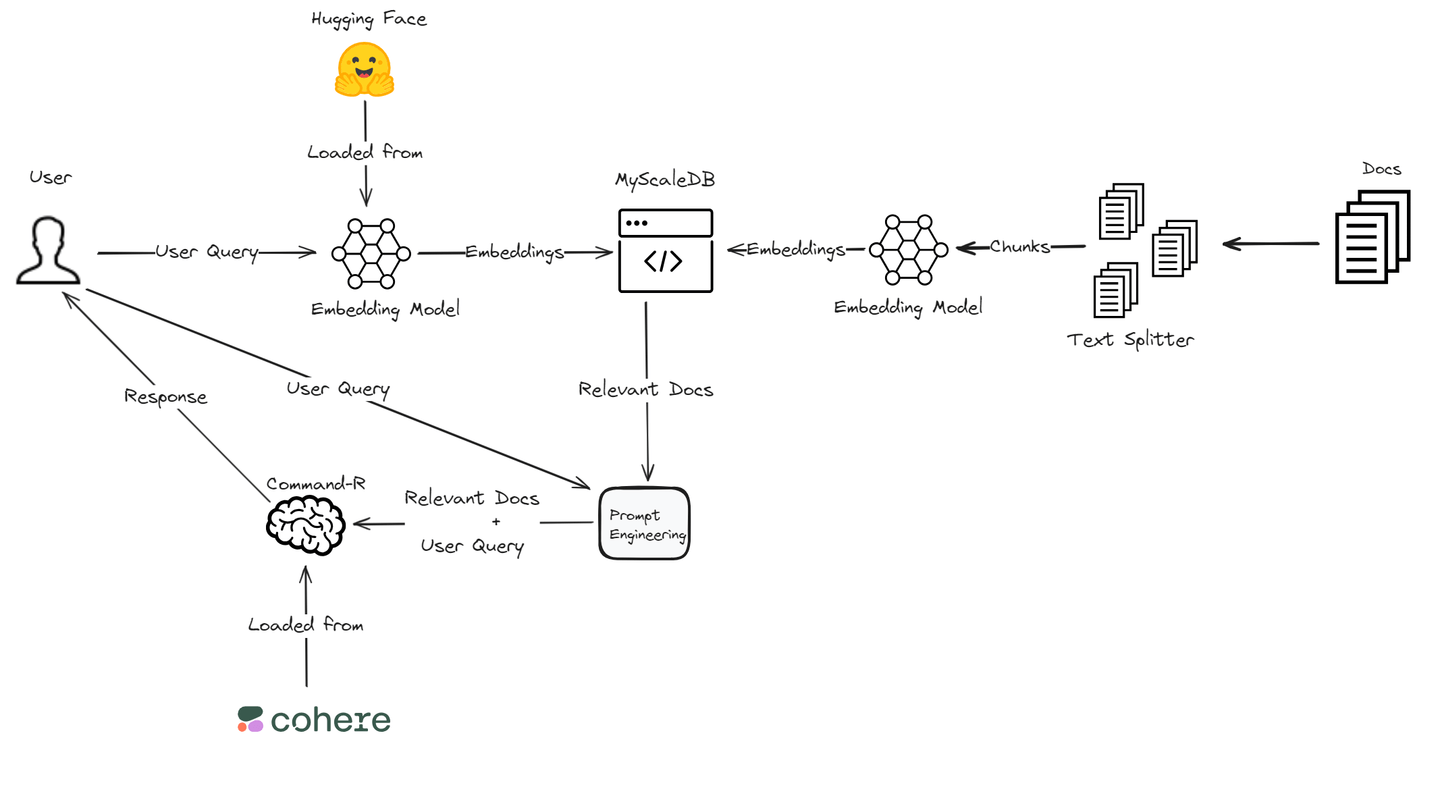
Retrieval-Augmented Generation (RAG) (opens new window) ist eine Technik, die die Ausgabe großer Sprachmodelle durch den Bezug auf externe Wissensquellen verbessert. Dieser Ansatz gewährleistet genauere und kontextuell relevantere Antworten, ohne dass das Modell erneut trainiert werden muss. Es handelt sich um eine kostengünstige Möglichkeit, die Leistung von Sprachmodellen in verschiedenen Bereichen zu steigern.
In diesem Blog werden wir eine RAG-Anwendung mit Cohere's Command R-Modell (opens new window) erstellen, da es eine hervorragende Leistung in RAG bietet. Es bietet eine hohe Genauigkeit bei der Suche und Generierung relevanter Informationen. Für Einbettungen (opens new window) werden wir uns auf die Transformers-Bibliothek von Hugging Face (opens new window) verlassen, die umfangreiche Unterstützung für verschiedene NLP-Aufgaben bietet und gut mit Deep-Learning-Frameworks integriert ist. Darüber hinaus wird die leistungsstarke und kosteneffiziente MyScaleDB verwendet, um die Einbettungen und Textabschnitte zu speichern. Diese technische Kombination gewährleistet ein leistungsstarkes und effizientes RAG-System, das auf unsere spezifischen Anwendungsanforderungen zugeschnitten ist.
# Was ist Cohere?
Cohere (opens new window) ist eine Plattform, die sich auf die Entwicklung fortschrittlicher Sprachmodelle spezialisiert hat, um Unternehmen bei der Automatisierung und Verbesserung der Kundeninteraktion zu unterstützen. Sie bieten modernste große Sprachmodelle (LLMs) wie Command, das Anwendungen wie Konversationsagenten und Zusammenfassungen unterstützt, und Rerank, das die Relevanz von Suchergebnissen optimiert. Diese Tools verbessern die Kommunikationseffizienz und -genauigkeit für Unternehmen.
Neben ihren primären LLMs bietet Cohere Modelle wie Embed für Aufgaben wie Textklassifikation und semantische Suche sowie RAG-Funktionen, um Informationen aus Dokumenten und Unternehmensdatenquellen zu integrieren und abzurufen. Diese Modelle ermöglichen es Unternehmen, sichere, skalierbare KI-Lösungen bereitzustellen, um ihre gesamte betriebliche Effizienz und Kundenerfahrung zu verbessern.
# Was ist Hugging Face?
Hugging Face (opens new window) ist eine Plattform, die für ihre fortschrittlichen Sprachmodelle bekannt ist und sich darauf spezialisiert hat, modernste maschinelle Lernverfahren einem breiten Publikum zugänglich zu machen. Ihr Kernprodukt, die Transformers-Bibliothek, ist Open Source und unterstützt Aufgaben wie Textgenerierung, Zusammenfassung und Übersetzung. Diese Bibliothek ist mit beliebten Deep-Learning-Frameworks wie PyTorch und TensorFlow kompatibel und ermöglicht es Benutzern, modernste NLP-Modelle wie BERT und GPT-2 einfach zu implementieren.
Neben leistungsstarken NLP-Tools bietet Hugging Face verschiedene No-Code- und Low-Code-Lösungen für die Bereitstellung generativer KI-Modelle. Ihre Plattform umfasst Funktionen wie Inference Endpoints für die einfache Bereitstellung von Modellen und Spaces für die Hosting von Machine-Learning-Anwendungen. Hugging Face unterstützt auch die Zusammenarbeit über ihren Model Hub, wo Benutzer Tausende von Modellen, Datensätzen und Anwendungen teilen und darauf zugreifen können. Dieser gemeinschaftsgetriebene Ansatz trägt zur Demokratisierung des maschinellen Lernens bei und fördert Innovationen im KI-Bereich.
# Bausteine einer RAG-Anwendung mit Cohere und Hugging Face
Lassen Sie uns in die wesentlichen Komponenten eintauchen, um eine robuste RAG-Anwendung mit Cohere und Hugging Face zu erstellen.
# Integration des Command-R-Modells von Cohere
Bei der Verwendung von Cohere für Ihre RAG-Anwendung ist eine wichtige Funktion das Command-R-Modell. Dieses Modell verbessert die retrieval-augmented generation, indem es sich mit externen Datenquellen verbindet, um relevante Informationen abzurufen, was die Relevanz und Genauigkeit (opens new window) der Antworten verbessert. Durch die Verwendung dieser Funktion kann Ihre Anwendung aussagekräftigere und kontextuell angemessene Antworten liefern.
# Zugriff auf vortrainierte Modelle mit Hugging Face
Die Integration von vortrainierten Modellen von Hugging Face in Ihre RAG-Anwendung bietet einen erheblichen Vorteil in Bezug auf Effizienz und Genauigkeit. Diese Modelle sind umfangreich auf vielfältigen Datensätzen trainiert und können hochwertige Antworten in verschiedenen Bereichen generieren. Durch die Nutzung dieser vortrainierten Modelle können Sie den Entwicklungsprozess beschleunigen und gleichzeitig einen hohen Qualitätsstandard der Ausgabe beibehalten.
Hinweis:
Um Hugging Face-Modelle in Ihrem Projekt zu nutzen, erstellen Sie zunächst ein Konto auf Hugging Face und erhalten Sie den Access Token (opens new window).
# Einrichten Ihrer Umgebung
Bevor Sie Ihre RAG-Anwendung starten, stellen Sie sicher, dass Sie die erforderlichen Tools und Konten bereit haben. Sie benötigen Zugriff auf Plattformen wie Cohere und Hugging Face sowie Konten auf diesen Plattformen. Darüber hinaus ist die Installation wichtiger Bibliotheken wie Cohere's API und Hugging Face Transformers entscheidend für eine nahtlose Integration.
pip install cohere transformers clickhouse-connect
Wir werden MyScaleDB (opens new window) als Vektordatenbank für diese RAG-Anwendung verwenden. MyScaleDB ist eine SQL-Vektordatenbank, die mit ihrer vertrauten SQL-Syntax relevante Dokumente für die LLMs effizient abrufen kann. Es bietet 5 Millionen kostenlose Vektorspeicher, sodass wir seine Funktionen ohne Kosten nutzen können.

# Erstellen Ihrer RAG-Anwendung
Sobald Sie mit Cohere und Hugging Face die Grundlage für Ihre RAG-Anwendung gelegt haben, ist es an der Zeit, Ihre Kreation zu testen und ihre Leistung für optimale Ergebnisse zu optimieren.
# Laden der Daten
Zunächst müssen wir die Daten mit dem TextLoader aus dem Modul langchain.document_loaders laden. Für dieses Tutorial verwenden wir den Microsoft WikiQA Corpus (opens new window).
from langchain.document_loaders import TextLoader
loader = TextLoader('wikiQA-dev.txt', encoding='utf-8')
documents = loader.load()
text = documents[0].page_content
# Aufteilen des Textes
Als nächstes teilen wir den geladenen Text mit dem CharacterTextSplitter in Abschnitte auf. Dies hilft dabei, große Dokumente zu verwalten, indem sie in kleinere, handhabbare Teile aufgeteilt werden. Das Aufteilen des Textes ist notwendig, um große Dokumente effizient zu verarbeiten und eine bessere Handhabung und Abruf spezifischer Abschnitte zu ermöglichen.
from langchain_text_splitters import CharacterTextSplitter
# Text in Abschnitte aufteilen
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
# Laden des vortrainierten Modells und des Tokenizers
Wir verwenden das Modell sentence-transformers/all-MiniLM-L6-v2 von Hugging Face, um Texteinbettungen zu generieren. Der Tokenizer und das Modell werden geladen, und eine Funktion wird definiert, um Texteinbettungen zu erhalten. Einbettungen sind numerische Darstellungen von Text, die seine semantische Bedeutung erfassen, was für Ähnlichkeitssuchen und Vergleiche wesentlich ist.
from transformers import AutoTokenizer, AutoModel
import torch
# Vortrainierten Tokenizer und Modell laden
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Funktion zum Abrufen von Texteinbettungen
def get_text_embeddings(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
embeddings = model(inputs).last_hidden_state.mean(dim=1)
return embeddings.numpy().flatten()
# Generieren von Einbettungen für Textabschnitte
Für jeden Textabschnitt generieren wir Einbettungen und speichern sie in einem DataFrame zusammen mit dem ursprünglichen Text. Dieser Schritt hilft uns, die Daten effektiver zu verwalten und erleichtert die Speicherung.
import pandas as pd
# Einbettungen für jeden Textabschnitt generieren
page_contents = []
embeddings_list = []
for segment in texts:
embeddings_list.append(get_text_embeddings(segment.page_content))
page_contents.append(segment.page_content)
df = pd.DataFrame({
'page_content': page_contents,
'embeddings': embeddings_list
})
# Verbindung zu MyScaleDB herstellen
Wir stellen eine Verbindung zur MyScaleDB (opens new window)-Datenbank her, um die Einbettungen und Textabschnitte zu speichern. Befolgen Sie die Schritte, um die Anmeldeinformationen Ihres MyScaleDB-Clusters zu erhalten (opens new window).
import clickhouse_connect
# Verbindung zu ClickHouse herstellen
client = clickhouse_connect.get_client(
host='your_host',
port=443,
username='your_user_name',
password='your_password'
)
# MyScaleDB-Tabelle erstellen und befüllen
Wir erstellen eine Tabelle in MyScale, um die Textabschnitte und Einbettungen zu speichern, und fügen dann die Daten in die Tabelle ein. Dieser Schritt strukturiert die Daten in der Datenbank und bereitet sie auf effiziente Abfragen und Abrufe vor.
# Tabelle erstellen
client.command("""
CREATE TABLE IF NOT EXISTS default.QnA (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree() ORDER BY id
""")
# Daten in die Tabelle einfügen
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.QnA', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} eingefügt.")
# Vektorindex zur Tabelle hinzufügen
Wir fügen der Tabelle einen Vektorindex hinzu, um effiziente Ähnlichkeitssuchen zu ermöglichen. Der Vektorindex verbessert den Abrufprozess, indem er schnelle Suchvorgänge von Einbettungen ermöglicht, was für die Suche nach ähnlichen Dokumenten basierend auf ihrem semantischen Inhalt entscheidend ist.
# Vektorindex zur Tabelle hinzufügen
client.command("""
ALTER TABLE default.QnA
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Relevante Dokumente abrufen
Wir definieren eine Funktion, um die relevantesten Dokumente basierend auf der Abfrage eines Benutzers abzurufen. Die Funktion berechnet die Distanz zwischen den Abfrageeinbettungen und den gespeicherten Einbettungen, um die relevantesten Dokumente zu finden.
# Funktion zum Abrufen relevanter Dokumente
def get_relevant_docs(user_query, top_k):
query_embeddings = get_text_embeddings(user_query).tolist()
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.QnA ORDER BY dist LIMIT {top_k}
""")
relevant_docs = []
doc_counter = 1
for row in results.named_results():
doc_key = f"doc{doc_counter}"
relevant_docs.append({doc_key: row['page_content']})
doc_counter += 1
return relevant_docs
# Beispielabfrage
query = "Wie sind epitheliale Gewebe miteinander verbunden?"
relevant_docs = get_relevant_docs(query, 8)
print(relevant_docs)
# Verwendung von Cohere für verbesserte Antworten
Wir verwenden die Cohere-API, um die Antworten durch Abfragen der abgerufenen Dokumente zu verbessern. Das Cohere-Sprachmodell verarbeitet die Abfrage und die abgerufenen Dokumente, um eine umfassendere und genauere Antwort zu generieren. Dieser Schritt integriert die Leistungsfähigkeit fortschrittlicher Sprachmodelle in unser Abrufsystem.
import cohere
# Verbindung zu Cohere herstellen
co = cohere.Client('your-cohere-client-api')
# Abfrage der relevanten Dokumente mit Cohere
response = co.chat(
model='command-r-plus',
message="Wie sind epitheliale Gewebe miteinander verbunden?",
documents=relevant_docs
)
print(response.text)
# Fazit und nächste Schritte
Wenn wir unsere Reise zur Erkundung von RAG-Anwendungen mit Cohere und Hugging Face abschließen, ist es wichtig, über die Herausforderungen nachzudenken, denen wir begegnet sind, und das Wachstum, das wir während dieses Prozesses erlebt haben.
Die Entwicklung einer RAG-Pipeline (opens new window) kann unerwartete Hürden mit sich bringen und Fragen zu Leistungsunterschieden aufwerfen. Durch die Nutzung von Tools wie Cohere's Command-R-Modell und Hugging Face's vortrainierten Modellen können Entwickler diese Herausforderungen effektiv bewältigen. Die Integration von Abruf- und Generierungsmethoden erfordert eine sorgfältige Feinabstimmung, um optimale Ergebnisse zu erzielen, eine Aufgabe, die Ausdauer und strategische Anpassungen erfordert.
Ein weiterer wichtiger Faktor, der die Leistung von RAG-Systemen direkt beeinflusst, ist die Vektordatenbank, die bestimmt, wie schnell Ihre Daten abgerufen werden können und wie schnell Benutzer Antworten erhalten. Die Wahl der richtigen Vektordatenbank ist daher äußerst wichtig bei der Gestaltung eines RAG-Systems.
Viele Datenbanken werden jedoch beim Skalieren langsamer. MyScaleDB (opens new window) ist eine Open-Source-SQL-Vektordatenbank, die auf ClickHouse aufbaut. Ihre hohe Skalierbarkeit, die sie von ClickHouse erbt, ermöglicht eine mühelose Verwaltung großer Datenmengen und bietet Benutzern eine leistungsstarke und flexible Lösung für das Datenmanagement, um skalierbare RAG-Systeme aufzubauen. Darüber hinaus hat sie in Bezug auf Geschwindigkeit und Genauigkeit bessere Leistung (opens new window) als die meisten ihrer Konkurrenten gezeigt.
Durch die Vertiefung in die fortgeschrittenen Funktionen von Cohere und Hugging Face können Entwickler neue Dimensionen von Effizienz und Leistungsfähigkeit in ihren RAG-Anwendungen erschließen. Von der Optimierung der Abrufmechanismen bis zur Anpassung der Generierungsprozesse bieten diese Plattformen eine Vielzahl von Tools, um die Anwendungsfähigkeiten weiter zu verbessern.



