
In der Welt des maschinellen Lernens gab es früher eine Begrenzung für Modelle - sie konnten immer nur einen Datentyp gleichzeitig verarbeiten. Das ultimative Ziel des maschinellen Lernens ist es jedoch, die kognitive Leistungsfähigkeit des menschlichen Geistes zu erreichen, der mühelos verschiedene Datenmodalitäten gleichzeitig versteht. Neueste Durchbrüche, wie sie beispielsweise von Modellen wie GPT-4V verkörpert werden, haben nun die bemerkenswerte Fähigkeit gezeigt, gleichzeitig mehrere Datenmodalitäten zu verarbeiten. Dies eröffnet aufregende Möglichkeiten für Entwickler, KI-Anwendungen zu entwickeln, die in der Lage sind, verschiedene Arten von Daten nahtlos zu verwalten, was als Multi-Modale Anwendungen bezeichnet wird.
Ein überzeugendes Anwendungsbeispiel, das immense Popularität erlangt hat, ist die Multi-Modale Bildsuche. Damit können Benutzer ähnliche Bilder finden, indem sie Merkmale oder visuellen Inhalt analysieren. Dank der raschen Fortschritte in den Bereichen Computer Vision und Deep Learning ist die Bildsuche unglaublich leistungsfähig geworden.
In diesem Artikel werden wir eine Multi-Modale Bildsuchanwendung mit einem Modell aus der Hugging Face-Bibliothek erstellen. Bevor wir uns in die praktische Umsetzung stürzen, gehen wir einige Grundlagen durch, um die Bühne für unsere Erkundung zu bereiten.
# Was ist ein Multi-Modales System?
Ein Multi-Modales System bezieht sich auf ein System, das mehr als eine Art der Interaktion oder Kommunikation verwenden kann. Es handelt sich um ein System, das verschiedene Arten von Eingaben gleichzeitig verarbeiten und verstehen kann, wie z.B. Text, Bilder, Sprache und manchmal sogar Berührung oder Gesten, und auch Ergebnisse auf verschiedene Arten zurückgeben kann.
Beispielsweise ist GPT-4V (opens new window), entwickelt von OpenAI, ein fortschrittliches Multi-Modales Modell, das mehrere "Modalitäten" von Text- und Bildeingaben gleichzeitig verarbeiten kann. Wenn dem Modell ein Bild zusammen mit einer beschreibenden Abfrage zur Verfügung gestellt wird, kann das Modell den visuellen Inhalt auf der Grundlage des bereitgestellten Textes analysieren.
# Was sind Multi-Modale Embeddings?
Multi-Modale Embeddings, eine fortschrittliche maschinelle Lernmethode, ist der Prozess der Erzeugung einer numerischen Repräsentation mehrerer Modalitäten, wie Bilder, Text und Audio, in einem Vektorformat. Im Gegensatz zu grundlegenden Embedding-Techniken, die nur einen einzigen Datentyp in einem Vektorraum darstellen, können Multi-Modale Embeddings verschiedene Datentypen in einem vereinheitlichten Vektorraum darstellen. Dies ermöglicht beispielsweise die Korrelation einer Textbeschreibung mit einem entsprechenden Bild. Mit Hilfe von Multi-Modalen Embeddings könnte ein System ein Bild analysieren und es mit relevanten Textbeschreibungen in Beziehung setzen oder umgekehrt.
Nun wollen wir besprechen, wie man dieses Projekt entwickelt und welche Technologien wir verwenden werden.
# Werkzeuge und Technologien
In diesem Projekt verwenden wir CLIP (opens new window), MyScale (opens new window) und Unsplash-25k Dataset (opens new window). Schauen wir uns diese im Detail an.
- CLIP: Sie werden ein vortrainiertes Multi-Modales CLIP (opens new window) Modell von OpenAI aus der Hugging Face-Bibliothek verwenden. Dieses Modell wird verwendet, um Text und Bilder zu integrieren.
- MyScale: MyScale ist eine SQL-Vektor-Datenbank, die dazu verwendet wird, strukturierte und unstrukturierte Daten auf optimierte Weise zu speichern und zu verarbeiten. Sie werden MyScale verwenden, um die Vektor-Embeddings zu speichern und die relevanten Bilder abzufragen.
- Unsplash-25k Dataset: Das von Unsplash bereitgestellte Dataset enthält etwa 25.000 Bilder. Es umfasst einige komplexe Szenen und Objekte.
# Einrichtung von Hugging Face und MyScale
Um Hugging Face und MyScale in der lokalen Umgebung zu verwenden, müssen Sie einige Python-Pakete installieren. Öffnen Sie Ihr Terminal und geben Sie den folgenden pip-Befehl ein:
pip install datasets clickhouse-connect requests transformers torch tqdm
Sobald die Installation abgeschlossen ist, können Sie dies überprüfen, indem Sie den folgenden Befehl in Ihrem Terminal eingeben.
pip freeze | egrep '(datasets|clickhouse-connect|requests|transformers|torch|tqdm)'
Es werden die neu installierten Abhängigkeiten mit Versionen angezeigt.
# Dataset herunterladen und laden
Der erste Schritt besteht darin, das Dataset herunterzuladen und lokal zu extrahieren. Sie können dies tun, indem Sie die folgenden Befehle in Ihrem Terminal eingeben.
# Download the dataset
wget https://unsplash-datasets.s3.amazonaws.com/lite/latest/unsplash-research-dataset-lite-latest.zip
# unzip the downloaded files into a temporary directory
unzip unsplash-research-dataset-lite-latest.zip -d tmp
Lassen Sie uns die erforderlichen Daten aus den extrahierten Dateien in Python-Datenrahmen laden.
# Import pandas
import pandas as pd
# Load the photos file from the directory
df_photos = pd.read_csv("tmp/photos.tsv", sep='\t', header=0)
df_photos
Wir laden die photos-Datei aus dem Verzeichnis, die Informationen über die Fotos im Dataset enthält. Ein Foto-Profil sieht folgendermaßen aus:
| photo_id | photo_url | photo_image_url |
|---|---|---|
| xapxF7PcOzU | https://unsplash.com/photos/wud-eV6Vpwo | https://images.unsplash.com/photo-143924685475... |
| psIMdj26lgw | https://unsplash.com/photos/psIMdj26lgw | https://images.unsplash.com/photo-144077331099... |
Der Unterschied zwischen photo_url und photo_image_url besteht darin, dass die photo_url die URL zur Beschreibungsseite eines Bildes enthält, auf der der Autor und andere Metainformationen des Fotos angegeben sind. Die photo_image_url enthält nur die URL zum Bild und wir werden sie verwenden, um das Bild herunterzuladen.
# Modell laden und Embeddings erhalten
Nachdem das Dataset geladen wurde, laden wir zuerst das clip-vit-base-patch32 (opens new window)-Modell und schreiben eine Python-Funktion, um Bilder in Vektor-Embeddings zu transformieren. Diese Funktion wird das CLIP-Modell verwenden, um die Embeddings zu repräsentieren.
# Import pytorch
import torch
# Import transformers to load the model and processor from Hugging Face
from transformers import CLIPProcessor, CLIPModel
# Load the CLIP model from Hugging Face
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
# Load the processor used to pre-process the images and make them compatible with the model
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Define the method
def create_embeddings(image=None, text=None):
# Initialize embeddings
image_embeddings = None
text_embeddings = None
# Process the image if provided
if image is not None:
image_embeddings = extract_image_features(image)
image_embeddings = torch.tensor(image_embeddings)
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
# Process the text if provided
if text is not None:
text_inputs = processor(text=[text], return_tensors="pt", padding=True)
with torch.no_grad():
text_outputs = model.get_text_features(**text_inputs)
text_embeddings = text_outputs / text_outputs.norm(dim=-1, keepdim=True)
text_embeddings = text_embeddings.squeeze(0).tolist()
# Combine the embeddings if both image and text are provided, and normalize
if image_embeddings is not None and text_embeddings is not None:
combined_embeddings = (image_embeddings + torch.tensor(text_embeddings)) / 2
combined_embeddings = combined_embeddings / combined_embeddings.norm(dim=-1, keepdim=True)
return combined_embeddings.tolist()
# Return only image or text embeddings if one of them is provided
return image_embeddings.tolist() if text_embeddings is None else text_embeddings
Der obige Code ist darauf ausgelegt, sowohl Text- als auch Bildeingaben separat oder gleichzeitig zu verarbeiten und die entsprechenden Embeddings zurückzugeben. Schauen wir uns an, wie sie funktionieren:
- Wenn Sie sowohl ein Bild als auch Text angeben, gibt der Code einen einzelnen Vektor zurück, der die Embeddings beider kombiniert.
- Wenn Sie entweder Text oder Bild angeben (aber nicht beides), gibt der Code einfach die Embeddings des angegebenen Textes oder Bildes zurück.
Hinweis:
Wir verwenden eine einfache Methode, um zwei Embeddings zu kombinieren, um uns auf das Multi-Modale Konzept zu konzentrieren. Es gibt jedoch bessere Möglichkeiten, Embeddings zu kombinieren, wie z.B. Konkatenation und Aufmerksamkeitsmechanismen.
Wir laden, laden herunter und übergeben die ersten 1000 Bilder aus dem Dataset an die oben genannte create_embeddings-Funktion. Die zurückgegebenen Embeddings werden dann in einer neuen Spalte photo_embed gespeichert.
# Import the Image moduke for image processing
from PIL import Image
# Import the requests module for making HTTP requests
import requests
# Import tqdm for processing bar visualization
from tqdm.auto import tqdm
# Get the first 1000 images
photo_ids = df_photos['photo_id'][:1000]
# Filter the DataFrame to get the required columns
df_photos = df_photos.loc[photo_ids.index, ['photo_id', 'photo_image_url']]
# Create a session to make HTTP requests
session = requests.Session()
# Define the Python function to download and get embeddings
def process_image(url):
try:
# Make a GET request to download the image
response = session.get(url, stream=True)
response.raise_for_status()
image = Image.open(response.raw)
# Get the embeddings and return
return create_embeddings(image)
except requests.RequestException:
return None
# construct a URL to download the image with a smaller size
df_photos['photo_image_url'] = df_photos['photo_image_url'].apply(lambda x: x + "?q=75&fm=jpg&w=200&fit=max")
# Pass the images one by one to the 'process_image' and save the embeddings to the newly created column 'photo_embed'
df_photos['photo_embed'] = [process_image(url) for url in tqdm(df_photos['photo_image_url'], total=len(df_photos))]
# Remove rows where image processing failed
df_photos.dropna(subset=['photo_embed'], inplace=True)
# Reset the index and rename the 'id' column to 'index'
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index().rename(columns={'index': 'id'})
# Close the session
session.close()
Hinweis:
Dieser Vorgang dauert einige Zeit und hängt auch von Ihrer Internetgeschwindigkeit ab.
Nach diesem Vorgang ist unser Dataset abgeschlossen. Der nächste Schritt besteht darin, eine neue Tabelle zu erstellen und die Daten in MyScale zu speichern.
# Verbindung mit MyScale herstellen
Um die Anwendung mit MyScale zu verbinden, müssen Sie einige Schritte für die Einrichtung und Konfiguration durchführen.
- Kontoerstellung: Beginnen Sie damit, ein Konto auf MyScale (opens new window) zu erstellen.
- Cluster-Erstellung: Als nächstes müssen Sie einen Cluster erstellen. Dazu können Sie die Dokumentation "Cluster erstellen (opens new window)" von MyScale mit detaillierten Anweisungen verwenden.
- Abrufen der Verbindungsdetails: Sobald Ihr Cluster eingerichtet ist, ist der nächste Schritt, die Verbindungsdetails abzurufen (opens new window), um eine Verbindung zwischen Ihrer Anwendung und dem MyScale-Cluster herzustellen.
Sobald Sie die Verbindungsdetails haben, können Sie die Werte im folgenden Code ersetzen:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='Ihre-Host-Adresse',
port=443,
username='Ihr-Benutzername',
password='Ihr-Passwort'
)
# Eine Tabelle erstellen
Sobald die Verbindung hergestellt ist, ist der nächste Schritt das Erstellen einer Tabelle. Schauen wir uns zunächst unseren Datenrahmen mit diesem Befehl an:
df_photos
Der Datenrahmen sieht folgendermaßen aus:
| photo_id | photo_image_url | photo_embed |
|---|---|---|
| wud-eV6Vpwo | https://images.unsplash.com/uploads/1411949294... | [0.0028754104860126972, 0.02760922536253929, 0... |
| psIMdj26lgw | https://images.unsplash.com/photo-141633941111... | [0.019032524898648262, -0.04198262840509415, 0... |
| 2EDjes2hlZo | https://images.unsplash.com/photo-142014251503... | [-0.015412664040923119, 0.01923416182398796, 0... |
Lassen Sie uns eine Tabelle abhängig vom Datenrahmen erstellen.
# Check if a table with the same name exists or not. If exists, drop that table
client.command("DROP TABLE IF EXISTS default.myscale_photos")
# create a table for photos
client.command("""
CREATE TABLE default.myscale_photos
(
id UInt64,
photo_id String,
photo_image_url String,
photo_embed Array(Float32),
CONSTRAINT vector_len CHECK length(photo_embed) = 512
)
ORDER BY id
""")
Die obigen Befehle erstellen eine Tabelle in Ihrem MyScale-Cluster.
# Die Daten einfügen
Lassen Sie uns die Daten in die neu erstellte Tabelle einfügen:
# upload data from datasets
client.insert("default.myscale_photos", df_photos.to_records(index=False).tolist(),
column_names=df_photos.columns.tolist())
# check count of inserted data
print(f"photos count: {client.command('SELECT count(*) FROM default.myscale_photos')}")
# create vector index with cosine
client.command("""
ALTER TABLE default.myscale_photos
ADD VECTOR INDEX photo_embed_index photo_embed
TYPE MSTG
('metric_type=Cosine')
""")
# check the status of the vector index, make sure vector index is ready with 'Built' status
get_index_status="SELECT status FROM system.vector_indices WHERE name='photo_embed_index'"
print(f"index build status: {client.command(get_index_status)}")
Der obige Code fügt die Daten in die Tabelle ein und erstellt einen Index mit dem Algorithmus MSTG. Indizes werden erstellt, um eine schnelle Abfrage von Daten aus der Tabelle zu ermöglichen. Der letzte Befehl wird verwendet, um sicherzustellen, dass der Index erfolgreich erstellt wurde oder nicht. Wenn ja, sehen Sie "Index-Build-Status: Built".
Hinweis:
Der MSTG-Algorithmus wurde von MyScale erstellt und ist wesentlich schneller als andere Indexierungsalgorithmen wie IVF und HNSW.

# Abfrage von MyScale
Nachdem die Daten eingefügt wurden, sind wir bereit, MyScale zu nutzen, um Daten abzufragen und die Multi-Modalität zu nutzen, um Bilder zu erhalten. Lassen Sie uns zunächst versuchen, ein zufälliges Bild aus der Tabelle zu erhalten.
import requests
import matplotlib.pyplot as plt
from PIL import Image
from io import BytesIO
# download image with its url
def download(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
def show_image(url, title=None):
img = download(url)
fig = plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.show()
random_image = client.query("SELECT * FROM default.myscale_photos ORDER BY rand() LIMIT 1")
target_image_url = random_image.first_item["photo_image_url"]
print("Lade Zielbild...")
show_image(target_image_url)
Der obige Code sollte ein zufälliges Bild aus der Tabelle suchen und es in Ihrem Code-Editor anzeigen.
# Erhalten von relevanten Bildern mit Text und Bild
Wie Sie gelernt haben, kann ein Multi-Modales Modell gleichzeitig mehrere Datenmodalitäten verarbeiten. Ähnlich kann unser Modell gleichzeitig sowohl Bilder als auch Text verarbeiten und relevante Bilder liefern. Wir werden das folgende Bild zusammen mit dem Text bereitstellen: 'Ein Mann steht am Strand.'

Lassen Sie uns die Bild-URL zusammen mit dem Text an die create_embeddings-Funktion übergeben.
image_url="https://images.unsplash.com/photo-1701443478334-c1a4bfda91ff?q=80&w=1936&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
query_text="Ein Mann steht am Strand"
embeddings=create_embeddings(download(url),query_text)
Der nächste Schritt besteht darin, eine Abfrage zu schreiben, um top_k relevante Ergebnisse aus dem Dataset zu erhalten.
top_k = 5
# Query to get the relevant results from the database
results = client.query(f"""
SELECT photo_id, photo_image_url, distance(photo_embed, {embeddings}) as dist
FROM default.myscale_photos
ORDER BY dist ASC
LIMIT {top_k}
""")
# Download the relevant images
images_url = []
for r in results.named_results():
# construct a URL to download an image with a smaller size by modifying the image URL
url = r['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
images_url.append(download(url))
# display the images
print("Loading candidate images...")
for row in range(int(top_k / 5)):
fig, axs = plt.subplots(1, 5, figsize=(20, 4))
for i, img in enumerate(images_url[row * 5:row * 5 + 5]):
axs[i % 5].imshow(img)
plt.show()
Hinweis:
Die Distanzfunktion berechnet die euklidische Distanz zwischen dem Abfragevektor und allen relevanten Vektoren.
Der obige Code generiert Ergebnisse, die ähnlich aussehen wie diese:
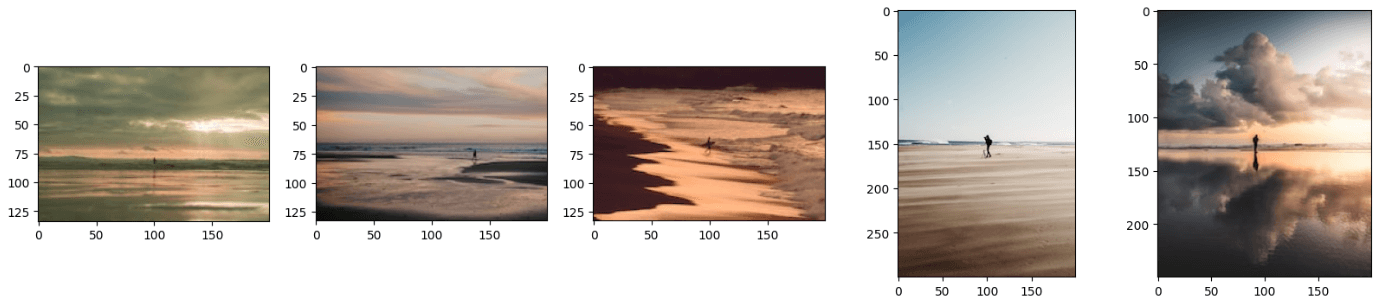
Hinweis:
Sie können die Ergebnisse weiter verbessern, indem Sie bessere Techniken zur Kombination der Embeddings verwenden.
Sie haben vielleicht bemerkt, dass die resultierenden Bilder wie eine Kombination aus Text und Bild aussehen. Sie können auch die Ergebnisse erhalten, indem Sie nur ein Bild oder Text an dieses Modell übergeben, und es funktioniert einwandfrei. Dazu müssen Sie einfach entweder die image_url oder die query_text-Codezeile auskommentieren.
# Fazit
Traditionelle Modelle werden verwendet, um die Vektorrepräsentationen nur eines einzigen Datentyps zu erhalten, aber neueste Modelle werden auf viel mehr Daten trainiert und können nun verschiedene Datentypen in einem vereinheitlichten Vektorraum repräsentieren. Wir haben die Fähigkeiten eines neuesten Modells, CLIP, genutzt, um eine Anwendung zu entwickeln, die sowohl Text als auch Bilder als Eingabe akzeptiert und die relevanten Bilder zurückgibt.
Die Möglichkeiten von Multi-Modalen Embeddings sind nicht auf Bildsuchanwendungen beschränkt, sondern Sie können diese innovative Technik auch nutzen, um modernste Empfehlungssysteme, Visual Question Answering-Anwendungen, bei denen Benutzer Fragen zu Bildern stellen können, und vieles mehr zu entwickeln. Bei der Entwicklung dieser Anwendungen sollten Sie in Betracht ziehen, MyScale (opens new window) zu verwenden, eine integrierte SQL-Vektor-Datenbank, die es Ihnen ermöglicht, Vektor-Embeddings und tabellarische Daten aus Ihrem Dataset mit superschneller Datenabfrage zu speichern.
Wenn Sie eine Bildsuch-App entwickeln, sind Sie herzlich eingeladen, Ihre Ideen oder Feedback im MyScale Discord (opens new window) auszutauschen.



