
Retrieval augmented generation (opens new window) (RAG) war ein großer Durchbruch im Bereich der natürlichen Sprachverarbeitung (NLP), insbesondere für die Entwicklung von KI-Anwendungen. RAG kombiniert eine große Wissensbasis und die sprachlichen Fähigkeiten großer Sprachmodelle (LLMs) mit Datenabruf-Fähigkeiten. Die Fähigkeit, Informationen in Echtzeit abzurufen und zu nutzen, macht KI-Interaktionen authentischer und informierter.
RAG hat zweifellos die Art und Weise verbessert, wie Benutzer mit KI interagieren. Zum Beispiel können Chatbots, die von LLMs unterstützt werden, bereits komplizierte Fragen bearbeiten und ihre Antworten auf individuelle Benutzer zuschneiden. RAG-Anwendungen verbessern dies, indem sie nicht nur die Trainingsdaten verwenden, sondern auch aktuelle Informationen während der Interaktion abrufen.
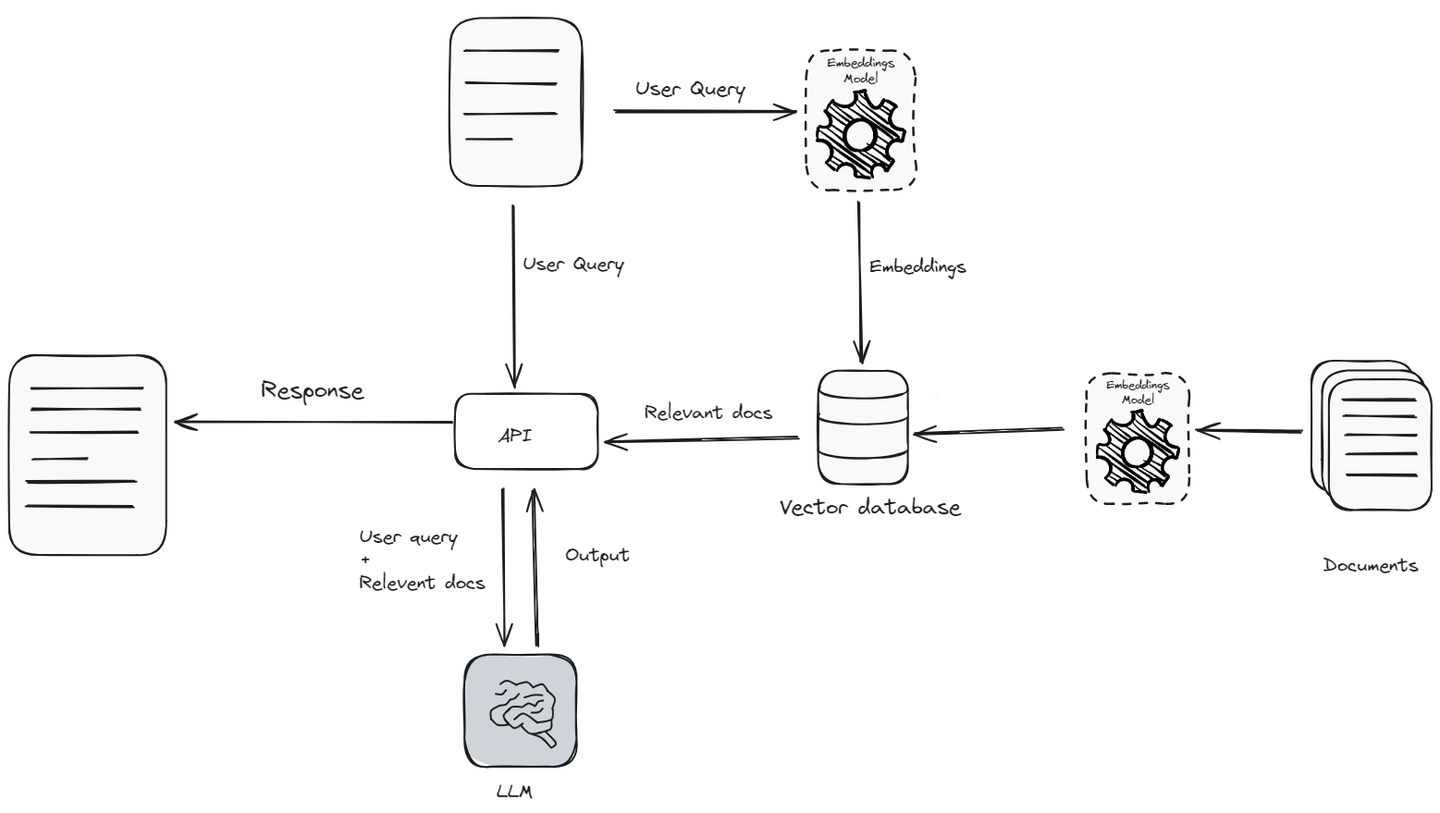
Jedoch funktionieren RAG-Anwendungen gut, wenn sie im kleinen Maßstab verwendet werden, stellen jedoch erhebliche Herausforderungen dar, wenn sie skaliert werden sollen, wie die Verwaltung der API- und Datenspeicherkosten, die Reduzierung der Latenzzeit und die Steigerung der Durchsatzrate, die effiziente Suche in großen Wissensbasen und die Gewährleistung der Benutzerdatenschutz.
In diesem Blog werden wir die verschiedenen Herausforderungen untersuchen, die bei der Skalierung von RAG-Anwendungen auftreten, sowie effektive Lösungen, um ihnen zu begegnen.
# Verwaltung der Kosten: Datenspeicherung und API-Nutzung
Eine der größten Hürden bei der Erweiterung von RAG-Anwendungen ist die Kostenverwaltung, insbesondere aufgrund der Abhängigkeit von APIs großer Sprachmodelle (LLMs) wie OpenAI (opens new window) oder Gemini (opens new window). Bei der Entwicklung einer RAG-Anwendung gibt es drei wesentliche Kostenfaktoren zu berücksichtigen:
- LLM-API
- Embeddings-Modelle-API
- Vektordatenbank
Die Kosten dieser APIs sind höher, da die Dienstanbieter alles auf ihrer Seite verwalten, wie z.B. Rechenkosten, Training usw. Diese Einrichtung mag für kleinere Projekte nachhaltig sein, aber wenn die Nutzung Ihrer Anwendung zunimmt, können die Kosten schnell zu einer erheblichen Belastung werden.
Angenommen, Sie verwenden gpt-4 in Ihrer RAG-Anwendung und Ihre RAG-Anwendung verarbeitet täglich über 10 Millionen Eingabe- und 3 Millionen Ausgabetokens, könnten Sie mit Kosten von rund 480 US-Dollar pro Tag rechnen, was eine erhebliche Menge ist, um eine Anwendung zu betreiben. Gleichzeitig müssen die Vektordatenbanken regelmäßig aktualisiert und mit dem Wachstum Ihrer Daten skaliert werden, was die Kosten weiter erhöht.
# Strategien zur Kostenreduzierung
Wie bereits erwähnt, können bestimmte Komponenten in der RAG-Architektur ziemlich teuer sein. Lassen Sie uns einige Strategien zur Kostenreduzierung für diese Komponenten besprechen.
- Feinabstimmung eines LLMs und Embeddings-Modells: Um die Kosten für die LLM-API und das Embeddings-Modell zu minimieren, ist der effektivste Ansatz die Auswahl eines Open-Source LLMs und Embeddings-Modells und deren Feinabstimmung mit Ihren Daten. Dies erfordert jedoch viele Daten, technisches Know-how und Rechenressourcen.
- Caching: Die Verwendung eines Caches zur Speicherung von Antworten eines LLMs kann die Kosten für API-Aufrufe reduzieren und Ihre Anwendung schneller und effizienter machen. Wenn eine Antwort im Cache gespeichert ist, kann sie bei Bedarf schnell abgerufen werden, ohne das LLM ein zweites Mal danach fragen zu müssen. Die Verwendung eines Caches kann die Kosten für API-Aufrufe um bis zu 10% reduzieren. Sie können verschiedene Caching-Techniken von langchain verwenden.
- Kompakte Eingabeaufforderungen: Sie können die Anzahl der für die Eingabe erforderlichen Tokens reduzieren, indem Sie die Eingabeaufforderungen verfeinern und verkürzen. Dies ermöglicht es dem Modell nicht nur, die Benutzeranfrage besser zu verstehen, sondern senkt auch die Kosten, da weniger Tokens verwendet werden.
- Begrenzung der Ausgabetokens: Durch das Festlegen einer Begrenzung für die Anzahl der Ausgabetokens kann verhindert werden, dass das Modell unnötig lange Antworten generiert, wodurch die Kosten kontrolliert werden, während relevante Informationen bereitgestellt werden.
# Reduzierung der Kosten von Vektordatenbanken
Eine Vektordatenbank spielt eine entscheidende Rolle in einer RAG-Anwendung, und die Art der eingegebenen Daten ist ebenso wichtig. Wie das Sprichwort sagt: "Müll rein, Müll raus".
- Vorverarbeitung: Das Ziel der Vorverarbeitung der Daten besteht darin, eine Textstandardisierung und -konsistenz zu erreichen. Die Textstandardisierung entfernt irrelevante Details und Sonderzeichen und macht die Daten reich an Kontext und konsistent. Durch Fokussierung auf Klarheit, Kontext und Korrektheit wird nicht nur die Effizienz des Systems verbessert, sondern auch das Datenvolumen reduziert. Die Reduzierung des Datenvolumens bedeutet, dass weniger gespeichert werden muss, was die Speicherkosten senkt und die Effizienz der Datenabfrage verbessert.
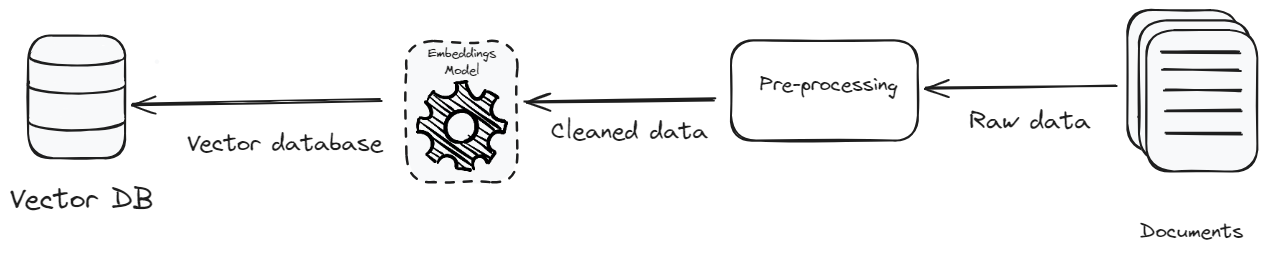
- Kosteneffiziente Vektordatenbank: Eine weitere Methode zur Kostensenkung besteht darin, eine weniger teure Vektordatenbank auszuwählen. Derzeit gibt es viele Optionen auf dem Markt, aber es ist wichtig, eine zu wählen, die nicht nur erschwinglich, sondern auch skalierbar ist. MyScaleDB ist eine Vektordatenbank, die speziell für die Entwicklung skalierbarer RAG-Anwendungen entwickelt wurde und dabei mehrere Faktoren, insbesondere die Kosten, berücksichtigt. Sie ist eine der günstigsten Vektordatenbanken auf dem Markt und bietet eine deutlich bessere Leistung als ihre Konkurrenten.
Wenn eine RAG-Anwendung skaliert wird, muss sie nicht nur eine steigende Anzahl von Benutzern unterstützen, sondern auch Geschwindigkeit, Effizienz und Zuverlässigkeit gewährleisten. Dies erfordert die Optimierung des Systems, um eine Spitzenleistung auch bei einer großen Anzahl gleichzeitiger Benutzer sicherzustellen.
Latenzzeit: Für Echtzeitanwendungen wie Chatbots ist es wichtig, eine geringe Latenzzeit aufrechtzuerhalten. Latenzzeit bezieht sich auf die Verzögerung, bevor ein Datenübertragungsvorgang nach einer Anweisung für die Übertragung beginnt. Techniken zur Minimierung der Latenzzeit umfassen die Optimierung von Netzwerkpfaden, die Reduzierung der Komplexität der Datenverarbeitung und die Verwendung schnellerer Hardware für die Verarbeitung. Eine effektive Möglichkeit, die Latenzzeit zu verwalten, besteht darin, die Größe der Eingabeaufforderungen auf wesentliche Informationen zu beschränken und komplexe Anweisungen zu vermeiden, die die Verarbeitung verlangsamen können.
Durchsatzrate: Während Zeiten hoher Nachfrage bezeichnet die Fähigkeit, eine große Anzahl von Anfragen gleichzeitig ohne Verlangsamung zu verarbeiten, den Durchsatz. Dies kann erheblich verbessert werden, indem Techniken wie kontinuierliches Stapeln verwendet werden, bei denen Anfragen dynamisch gruppiert werden, sobald sie eintreffen, anstatt auf das Auffüllen einer Stapel zu warten.
# Vorschläge zur Leistungsverbesserung:
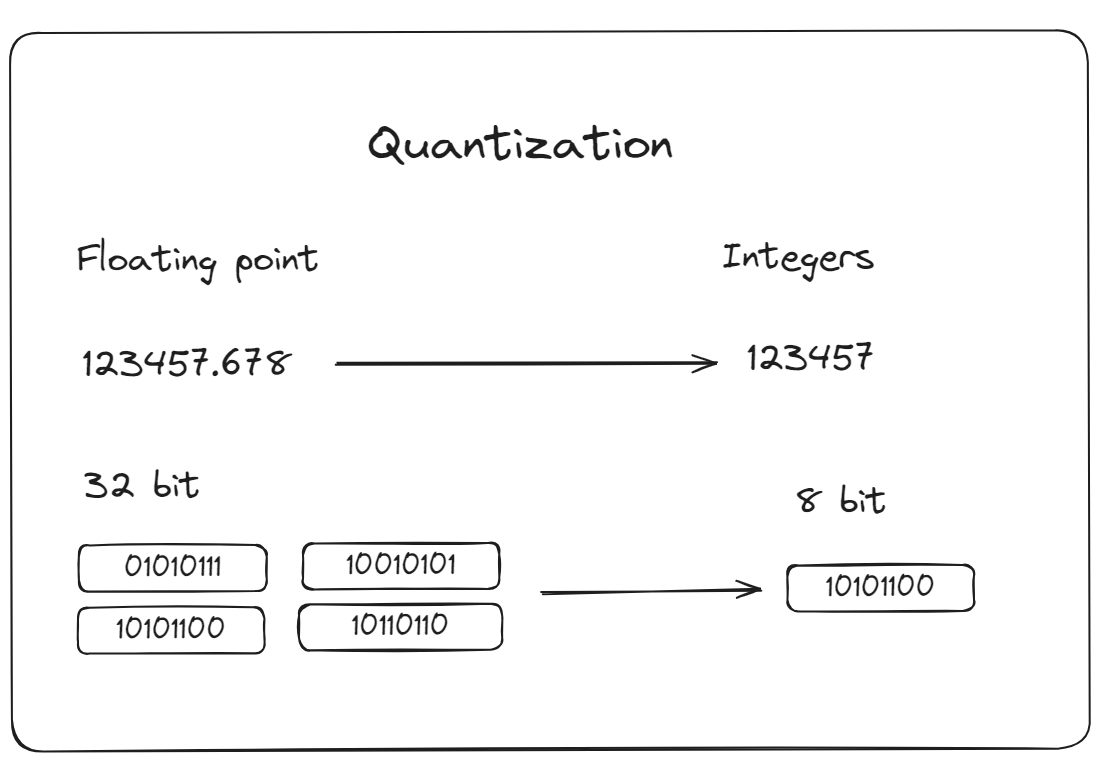
- Quantisierung😗* Dies ist ein Prozess zur Reduzierung der Genauigkeit der zur Darstellung von Modellparametern verwendeten Zahlen. Dadurch werden die Modellberechnungen reduziert, was den Bedarf an Rechenressourcen verringern und die Inferenzzeiten beschleunigen kann. MyScaleDB bietet fortschrittliche Vektorindexierungsoptionen wie IVFPQ (Inverted File Partitioning and Quantization) oder HNSWSQ (Hierarchical Navigable Small World Quantization). Diese Methoden sind darauf ausgelegt, die Leistung Ihrer Anwendung durch Optimierung der Datenabrufprozesse zu verbessern.
Neben diesen beliebten Algorithmen hat MyScaleDB Multi-Scale Tree Graph (MSTG) entwickelt (eine Unternehmensfunktion), das neuartige Strategien zur Quantisierung und gestuften Speicherung bietet. Dieser Algorithmus wird empfohlen, um sowohl niedrige Kosten als auch hohe Präzision im Vergleich zu IVFPQ oder HNSWSQ zu erreichen. Durch die Verwendung von Speicher in Kombination mit schnellen NVMe-SSDs reduziert MSTG den Ressourcenverbrauch erheblich im Vergleich zu IVF- und HNSW-Algorithmen und bietet gleichzeitig eine außergewöhnliche Leistung und Präzision.
Multithreading: Multithreading ermöglicht es Ihrer Anwendung, mehrere Anfragen gleichzeitig zu verarbeiten, indem die Fähigkeiten von Mehrkernprozessoren genutzt werden. Dadurch werden Verzögerungen minimiert und die Gesamtgeschwindigkeit des Systems erhöht, insbesondere bei der Verwaltung vieler Benutzer oder komplexer Abfragen.
Dynamisches Stapeln: Anstatt Anfragen an große Sprachmodelle (LLMs) sequenziell zu verarbeiten, gruppiert das dynamische Stapeln mehrere Anfragen intelligent zu einer einzelnen Stapelung. Diese Methode verbessert die Effizienz, insbesondere bei der Arbeit mit Dienstanbietern wie OpenAI und Gemini, die API-Ratenbeschränkungen auferlegen. Durch die Verwendung des dynamischen Stapelns können Sie eine größere Anzahl von Anfragen innerhalb dieser Ratenbeschränkungen bearbeiten, was Ihren Service zuverlässiger macht und die API-Nutzung optimiert.
# Effiziente Suche in den massiven Embedding-Räumen
Eine effiziente Datenabruf hängt hauptsächlich davon ab, wie gut eine Vektordatenbank Daten indiziert und wie schnell und effektiv sie relevante Informationen abruft. Jede Vektordatenbank funktioniert recht gut, wenn der Datensatz klein ist, aber es treten Probleme auf, wenn das Datenvolumen zunimmt. Die Komplexität der Indizierung und des Abrufs relevanter Informationen nimmt zu. Dies kann zu einem langsameren Abrufprozess führen, der in Umgebungen, in denen Echtzeit- oder nahezu Echtzeit-Antworten erforderlich sind, kritisch ist. Darüber hinaus wird es mit zunehmender Größe der Datenbank immer schwieriger, deren Genauigkeit und Konsistenz aufrechtzuerhalten. Fehler, Duplikate und veraltete Informationen können leicht auftreten, was die Qualität der von der LLM-Anwendung bereitgestellten Ausgaben beeinträchtigen kann.
Darüber hinaus bedeutet die Art der RAG-Systeme, die darauf angewiesen sind, die relevantesten Informationen aus umfangreichen Datensätzen abzurufen, dass sich jede Verschlechterung der Datenqualität direkt auf die Leistung und Zuverlässigkeit der Anwendung auswirkt. Mit zunehmendem Datenvolumen wird es immer schwieriger sicherzustellen, dass jede Abfrage mit der genauesten und kontextuell angemessensten Antwort beantwortet wird.
# Lösungen für optimierte Suche:
Um sicherzustellen, dass das Wachstum des Datenvolumens die Leistung des Systems oder die Qualität seiner Ausgaben nicht beeinträchtigt, müssen mehrere Faktoren berücksichtigt werden:
Effiziente Indizierung: Es ist erforderlich, fortschrittlichere Indizierungsmethoden oder effizientere Vektordatenbanklösungen zu verwenden, um große Datensätze ohne Beeinträchtigung der Geschwindigkeit zu verarbeiten. MyScaleDB bietet eine hochmoderne fortschrittliche Vektorindexierungsmethode, MSTG, die für die Verarbeitung sehr großer Datensätze entwickelt wurde. Sie hat auch andere Indizierungsmethoden mit 390 QPS (Abfragen pro Sekunde) auf dem LAION 5M-Datensatz übertroffen, eine Wiederfindungsrate von 95% erreicht und eine durchschnittliche Abfrageverzögerung von 18 ms mit dem s1.x1-Pod beibehalten.
Bessere Datenqualität: Um die Qualität der Daten zu verbessern, die für die Genauigkeit und Zuverlässigkeit von RAG-Systemen sehr wichtig ist, sind mehrere Vorverarbeitungstechniken erforderlich. Dadurch können wir den Datensatz verfeinern, das Rauschen reduzieren und die Präzision der abgerufenen Informationen erhöhen. Dies wirkt sich direkt auf die Effektivität der RAG-Anwendung aus.
Datenbereinigung und Optimierung: Sie können den Datensatz regelmäßig überprüfen und bereinigen, um veraltete oder irrelevante Vektoren zu entfernen und die Datenbank schlank und effizient zu halten.
Darüber hinaus hat MyScaleDB auch andere Vektordatenbanken in Bezug auf die Eingabezeit von Daten übertroffen, indem es Aufgaben für 5 Millionen Datenpunkte in nur etwa 30 Minuten abgeschlossen hat. Wenn Sie sich anmelden, können Sie einen x1-Pod kostenlos nutzen, der bis zu 5 Millionen Vektoren verarbeiten kann.
# Das Risiko eines Datenlecks besteht immer
Bei RAG-Anwendungen sind Datenschutzbedenken aufgrund von zwei Hauptaspekten besonders wichtig: der Verwendung einer LLM-API und der Speicherung von Daten in einer Vektordatenbank. Wenn private Daten über eine LLM-API übertragen werden, besteht das Risiko, dass die Daten Dritten auf Servern zugänglich gemacht werden und möglicherweise zu Verstößen gegen sensible Informationen führen. Darüber hinaus können die Speicherung von Daten in einer Vektordatenbank, die möglicherweise nicht vollständig sicher ist, auch Risiken für den Datenschutz darstellen.
# Lösungen zur Verbesserung des Datenschutzes:
Um mit diesen Risiken umzugehen, insbesondere bei sensiblen oder hoch vertraulichen Daten, sollten Sie folgende Strategien in Betracht ziehen:
In-House-LMM-Entwicklung: Anstatt sich auf LLM-APIs von Drittanbietern zu verlassen, können Sie ein beliebiges Open-Source LLM auswählen und es intern mit Ihren Daten feinabstimmen. Auf diese Weise bleibt alle sensible Daten in der kontrollierten Umgebung Ihrer Organisation, was die Wahrscheinlichkeit von Datenlecks erheblich reduziert.
Gesicherte Vektordatenbank: Stellen Sie sicher, dass Ihre Vektordatenbank mit den neuesten Verschlüsselungsstandards und Zugriffskontrollen gesichert ist. MyScaleDB wird von Teams und Organisationen aufgrund seiner robusten Sicherheitsfunktionen vertraut. Es arbeitet auf einem mandantenfähigen Kubernetes-Cluster, der auf einer sicheren, vollständig verwalteten AWS-Infrastruktur gehostet wird. MyScaleDB schützt Kundendaten, indem es sie in isolierten Containern speichert und kontinuierlich operative Metriken überwacht, um die Systemgesundheit und -leistung aufrechtzuerhalten. Darüber hinaus hat es erfolgreich die SOC 2 Type 1-Prüfung abgeschlossen und erfüllt die höchsten globalen Standards für Datensicherheit. Mit MyScaleDB können Sie sicher sein, dass Ihre Daten streng vertraulich bleiben.

# Fazit
Obwohl Retrieval-Augmented Generation (RAG) ein großer Fortschritt in der KI ist, hat es seine Herausforderungen. Dazu gehören hohe Kosten für APIs und Datenspeicherung, erhöhte Latenzzeiten und die Notwendigkeit eines effizienten Durchsatzes, wenn mehr Benutzer hinzukommen. Datenschutz und Datensicherheit werden ebenfalls kritisch, wenn die Menge der gespeicherten Daten wächst.
Diese Probleme können mit verschiedenen Strategien angegangen werden. Kosten können durch die Verwendung von internen, feinabgestimmten Open-Source LLMs und Caching zur Reduzierung der API-Nutzung reduziert werden. Zur Verbesserung von Latenzzeit und Durchsatz können Techniken wie dynamisches Stapeln und fortschrittliche Quantisierung verwendet werden, um die Verarbeitung schneller und effizienter zu machen. Für eine bessere Sicherheit ist die Entwicklung eigener LLMs und die Verwendung einer Vektordatenbank wie MyScaleDB eine gute Option.
Wenn Sie Vorschläge haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).



