
Große Sprachmodelle (LLMs) (opens new window) haben das Gebiet der Natürlichen Sprachverarbeitung (NLP) (opens new window) durch die Generierung von textähnlichen Inhalten, Beantwortung komplexer Fragen und Analyse großer Informationsmengen mit beeindruckender Genauigkeit revolutioniert. Ihre Fähigkeit, verschiedene Anfragen zu verarbeiten und detaillierte Antworten zu liefern, macht sie in vielen Bereichen unverzichtbar, von Kundenservice bis hin zur medizinischen Forschung. Allerdings stoßen LLMs bei der Verarbeitung größerer Datenmengen auf Herausforderungen bei der Verwaltung langer Dokumente und der effizienten Suche nach relevanten Informationen.
Obwohl LLMs gut darin sind, textähnliche Inhalte zu verarbeiten und zu generieren, haben sie ein begrenztes "Kontextfenster". Das bedeutet, dass sie nur eine bestimmte Menge an Informationen gleichzeitig im Speicher behalten können, was es schwierig macht, sehr lange Dokumente zu verwalten. Es ist auch eine Herausforderung für LLMs, die relevantesten Informationen aus großen Datensätzen schnell zu finden. Darüber hinaus werden LLMs auf festen Daten trainiert, so dass sie veraltet werden können, wenn neue Informationen auftauchen. Um genau und nützlich zu bleiben, benötigen sie regelmäßige Aktualisierungen.
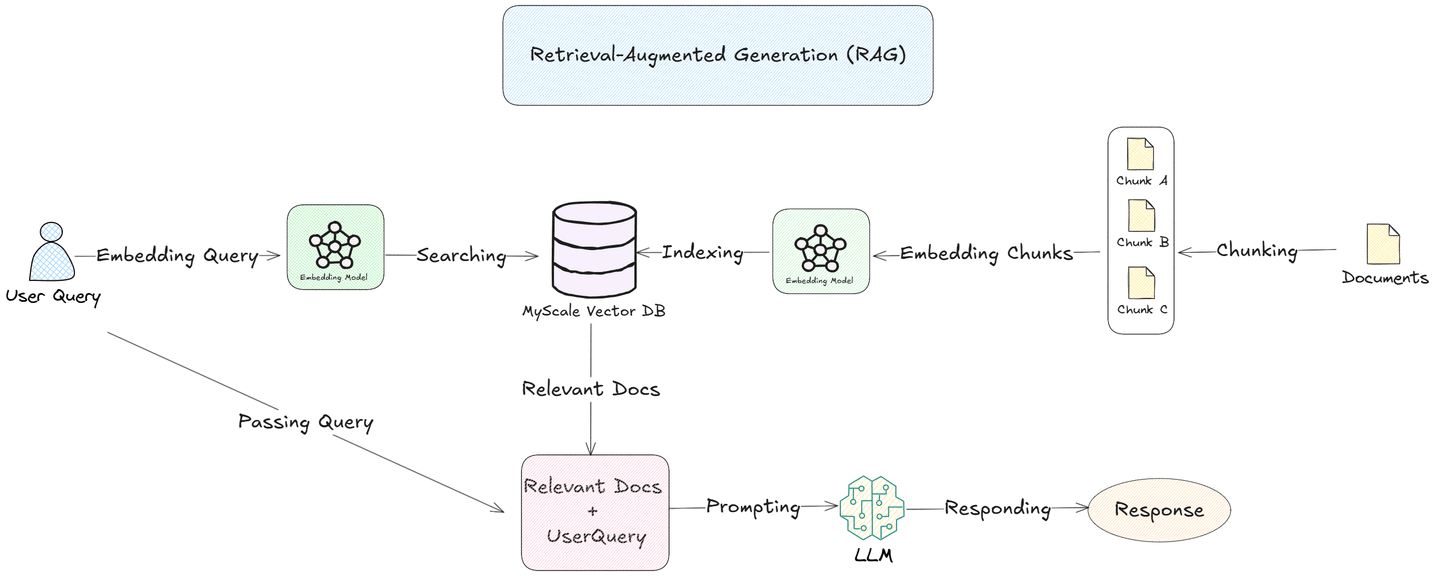
Retrieval-Augmented Generation (RAG) (opens new window) begegnet diesen Herausforderungen. Durch Chunking von Dokumenten in kleinere, bedeutungsvolle Segmente und Einbetten in eine Vektor-Datenbank wie die MyScale (opens new window) Datenbank können RAG-Systeme nur die relevantesten Segmente für jede Abfrage suchen und abrufen. Dieser Ansatz ermöglicht es LLMs, sich auf spezifische Informationen zu konzentrieren, was die Genauigkeit und Effizienz der Antworten verbessert.
In diesem Blog werden wir das Chunking und seine verschiedenen Strategien genauer untersuchen und ihre Rolle bei der Optimierung von LLMs für reale Anwendungen beleuchten.
# Was ist Chunking?
Chunking bedeutet, große Datenquellen in kleinere, handhabbare Teile oder "Chunks" aufzuteilen. Diese Chunks werden in Vektor-Datenbanken gespeichert, die schnelle und effiziente Suchen basierend auf Ähnlichkeit ermöglichen. Wenn ein Benutzer eine Abfrage stellt, findet die Vektor-Datenbank die relevantesten Chunks und sendet sie an das Sprachmodell. Auf diese Weise kann das Modell sich nur auf die relevantesten Informationen konzentrieren, was zu schnelleren und genaueren Antworten führt. Durch die Einschränkung der zu betrachtenden Daten hilft das Chunking Sprachmodellen, große Datensätze reibungsloser zu verarbeiten und präzise Antworten zu liefern.
Für Anwendungen, die schnelle und präzise Antworten erfordern - wie Kundensupport oder die Suche in rechtlichen Dokumenten - ist das Chunking eine wesentliche Strategie, die sowohl die Leistung als auch die Zuverlässigkeit verbessert.
Hier sind einige der wichtigsten Chunking-Strategien, die in RAG verwendet werden:
- Fixed-size Chunking (Chunking mit fester Größe)
- Recursive Chunking (Rekursives Chunking)
- Semantic Chunking (Semantisches Chunking)
- Agentic Chunking (Agentic Chunking)
Nun wollen wir uns jede Chunking-Strategie im Detail ansehen.
# Fixed-size Chunking (Chunking mit fester Größe)
Beim Chunking mit fester Größe wird die Daten in gleich große Abschnitte unterteilt, um die Verarbeitung großer Dokumente zu erleichtern. Manchmal fügen Entwickler zwischen den Chunks eine leichte Überlappung hinzu, bei der ein kleiner Teil eines Segments am Anfang des nächsten wiederholt wird. Dieser Überlappungsansatz hilft dem Modell, den Kontext über die Grenzen jedes Chunks hinweg zu bewahren und sicherzustellen, dass wichtige Informationen an den Rändern nicht verloren gehen. Diese Strategie ist besonders nützlich für Aufgaben, die einen kontinuierlichen Informationsfluss erfordern, da sie dem Modell ermöglicht, Text genauer zu interpretieren und die Beziehung zwischen den Segmenten zu verstehen, was zu kohärenteren und kontextbewussten Antworten führt.

Die obige Abbildung ist ein perfektes Beispiel für das Chunking mit fester Größe, bei dem jeder Chunk durch eine eindeutige Farbe repräsentiert wird. Der grüne Abschnitt zeigt den Überlappungsteil zwischen den Chunks an und stellt sicher, dass das Modell beim Verarbeiten des nächsten Chunks Zugriff auf den relevanten Kontext des vorherigen Chunks hat.
Diese Überlappung verbessert die Fähigkeit des Modells, den gesamten Text zu verarbeiten und zu verstehen, was zu einer besseren Leistung bei Aufgaben wie Zusammenfassung oder Übersetzung führt, bei denen die Aufrechterhaltung des Informationsflusses über Chunk-Grenzen hinweg entscheidend ist.
# Beispielcode
Nun wollen wir dieses Beispiel mit Hilfe eines Programmierbeispiels nachstellen, bei dem wir LangChain (opens new window) verwenden, um das Chunking mit fester Größe zu implementieren.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Funktion zum Aufteilen des Textes in Chunks mit fester Größe und Überlappung
def split_text_with_overlap(text, chunk_size, overlap_size):
# Erstellen eines Textsplitters mit Überlappung
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap_size
)
# Text aufteilen
chunks = text_splitter.split_text(text)
return chunks
# Beispieltext
text = """Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning."""
# Größe der Chunks und Überlappungsgröße definieren
chunk_size = 80 # 80 Zeichen pro Chunk
overlap_size = 10 # 10 Zeichen Überlappung zwischen den Chunks
# Chunks mit Überlappung erhalten
chunks = split_text_with_overlap(text, chunk_size, overlap_size)
# Chunks und Überlappungen ausgeben
for i in range(len(chunks)):
print(f"Chunk {i+1}:")
print(chunks[i]) # Den Chunk selbst ausgeben
# Wenn es einen nächsten Chunk gibt, die Überlappung zwischen dem aktuellen und dem nächsten Chunk ausgeben
if i < len(chunks) - 1:
overlap = chunks[i][-overlap_size:] # Den Überlappungsteil erhalten
print(f"Überlappung mit Chunk {i+2}:")
print(overlap)
print("\n" + "="*50 + "\n")
Bei Ausführung des obigen Codes wird folgende Ausgabe erzeugt:
Chunk 1:
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben
Überlappung mit Chunk 2:
für Aufgaben
==================================================
Chunk 2:
für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat
Überlappung mit Chunk 3:
at hat
==================================================
Chunk 3:
Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und
Überlappung mit Chunk 4:
entwickelt
==================================================
Chunk 4:
entwickelt die Leistung durch maschinelles Lernen und Deep Learning.
# Rekursives Chunking
Das rekursive Chunking ist eine Methode, bei der umfangreicher Text systematisch in kleinere, handhabbare Abschnitte unterteilt wird, indem er wiederholt in Unterabschnitte aufgeteilt wird. Dieser Ansatz ist besonders effektiv für komplexe oder hierarchische Dokumente und stellt sicher, dass jeder Abschnitt kohärent und inhaltlich intakt bleibt. Der Prozess wird fortgesetzt, bis der Text eine für die effiziente Verarbeitung geeignete Größe erreicht.
Nehmen wir zum Beispiel ein langes Dokument, das von einem Sprachmodell mit begrenztem Kontextfenster verarbeitet werden muss. Das rekursive Chunking würde das Dokument zunächst in Hauptabschnitte aufteilen. Wenn diese Abschnitte immer noch zu groß sind, würde die Methode sie weiter in Unterabschnitte unterteilen und diesen Prozess fortsetzen, bis jeder Chunk in die Verarbeitungsfähigkeiten des Modells passt. Diese hierarchische Aufteilung bewahrt den logischen Fluss und den Kontext des ursprünglichen Dokuments und ermöglicht es dem Modell, lange Texte effektiver zu verarbeiten.
In der Praxis kann das rekursive Chunking mit verschiedenen Strategien implementiert werden, z.B. durch Aufteilung nach Überschriften, Absätzen oder Sätzen, abhängig von der Struktur des Dokuments und den spezifischen Anforderungen der Aufgabe.

In der Abbildung wird der Text in vier Chunks aufgeteilt, die jeweils in einer anderen Farbe dargestellt werden, indem das rekursive Chunking verwendet wird. Der Text wird in kleinere, handhabbare Teile aufgeteilt, wobei jeder Chunk bis zu 80 Wörter enthält. Es gibt keine Überlappung zwischen den Chunks. Die Farbcodierung zeigt, wie der Inhalt in logische Abschnitte aufgeteilt wird, was es dem Modell erleichtert, lange Texte zu verarbeiten und zu verstehen, ohne wichtigen Kontext zu verlieren.
# Beispielcode
Nun wollen wir ein Beispiel programmieren, in dem wir das rekursive Chunking implementieren.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Funktion zum Aufteilen des Textes in Chunks mit rekursivem Chunking
def split_text_recursive(text, chunk_size=80):
# Initialisierung des RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # Maximale Größe jedes Chunks (80 Wörter)
chunk_overlap=0 # Keine Überlappung zwischen den Chunks
)
# Text in Chunks aufteilen
chunks = text_splitter.split_text(text)
return chunks
# Beispieltext
text = """Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning."""
# Text mit rekursivem Chunking aufteilen
chunks = split_text_recursive(text, chunk_size=80)
# Die resultierenden Chunks ausgeben
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}:")
print(chunk)
print("="*50)
Der obige Code erzeugt folgende Ausgabe:
Chunk 1:
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben
==================================================
Chunk 2:
wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von
==================================================
Chunk 3:
regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die
==================================================
Chunk 4:
Leistung durch maschinelles Lernen und Deep Learning.
==================================================
Nachdem wir nun beide Chunking-Strategien, die auf der Länge basieren, verstanden haben, ist es an der Zeit, eine Chunking-Strategie zu verstehen, die sich mehr auf die Bedeutung/den Kontext des Textes konzentriert.
# Semantisches Chunking
Das semantische Chunking bezieht sich auf die Aufteilung des Textes in Chunks basierend auf der Bedeutung oder dem Kontext des Inhalts. Diese Methode verwendet in der Regel Techniken des maschinellen Lernens oder der natürlichen Sprachverarbeitung (NLP), wie z.B. Satzeinbettungen, um Abschnitte des Textes zu identifizieren, die eine ähnliche Bedeutung oder semantische Struktur haben.

In der Abbildung wird jeder Chunk durch eine andere Farbe dargestellt - blau für KI und gelb für Prompt Engineering. Diese Chunks sind getrennt, weil sie unterschiedliche Ideen abdecken. Diese Methode stellt sicher, dass das Modell jeden Bereich klar verstehen kann, ohne sie zu vermischen.
# Beispielcode
Nun wollen wir ein Beispiel programmieren, in dem wir das semantische Chunking implementieren.
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# Den OpenAI API-Schlüssel als Umgebungsvariable festlegen (mit Ihrem tatsächlichen API-Schlüssel ersetzen)
os.environ["OPENAI_API_KEY"] = "ersetzen Sie dies durch Ihren tatsächlichen OpenAI API-Schlüssel"
# Funktion zum Aufteilen des Textes in semantische Chunks
def split_text_semantically(text, breakpoint_type="percentile"):
# Initialisierung des SemanticChunker mit OpenAI-Einbettungen
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type=breakpoint_type)
# Dokumente (Chunks) erstellen
docs = text_splitter.create_documents([text])
# Liste der Chunks zurückgeben
return [doc.page_content for doc in docs]
def main():
# Beispielinhalt (State of the Union-Rede oder eigener Text)
document_content = """
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning.
Prompt Engineering beinhaltet das Entwerfen von Eingabeaufforderungen, um KI-Modelle bei der Erzeugung genauer und relevanter Antworten zu unterstützen und Aufgaben wie Textgenerierung und Zusammenfassung zu verbessern.
"""
# Text mit dem gewählten Schwellenwerttyp (Percentile) aufteilen
threshold_type = "percentile"
print(f"\nChunks mit {threshold_type}-Schwellenwert:")
chunks = split_text_semantically(document_content, breakpoint_type=threshold_type)
# Den Inhalt jedes Chunks ausgeben
for idx, chunk in enumerate(chunks):
print(f"Chunk {idx+1}:")
print(chunk)
print()
if __name__ == "__main__":
main()
Der obige Code erzeugt folgende Ausgabe:
Chunks mit Percentile-Schwellenwert:
Chunk 1:
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning.
Chunk 2:
Prompt Engineering beinhaltet das Entwerfen von Eingabeaufforderungen, um KI-Modelle bei der Erzeugung genauer und relevanter Antworten zu unterstützen und Aufgaben wie Textgenerierung und Zusammenfassung zu verbessern.
# Agentic Chunking
Agentic Chunking ist eine leistungsstarke Strategie unter diesen Strategien. Bei dieser Strategie nutzen wir LLMs wie GPT, um als Agenten im Chunking-Verfahren zu fungieren. Anstatt manuell zu bestimmen, wie der Inhalt aufgeteilt wird, organisiert oder teilt das LLM die Informationen proaktiv entsprechend seiner Verständniseingabe auf. Das LLM bestimmt die beste Methode, um den Inhalt in handhabbare Stücke aufzuteilen, beeinflusst durch den Kontext der Aufgabe.
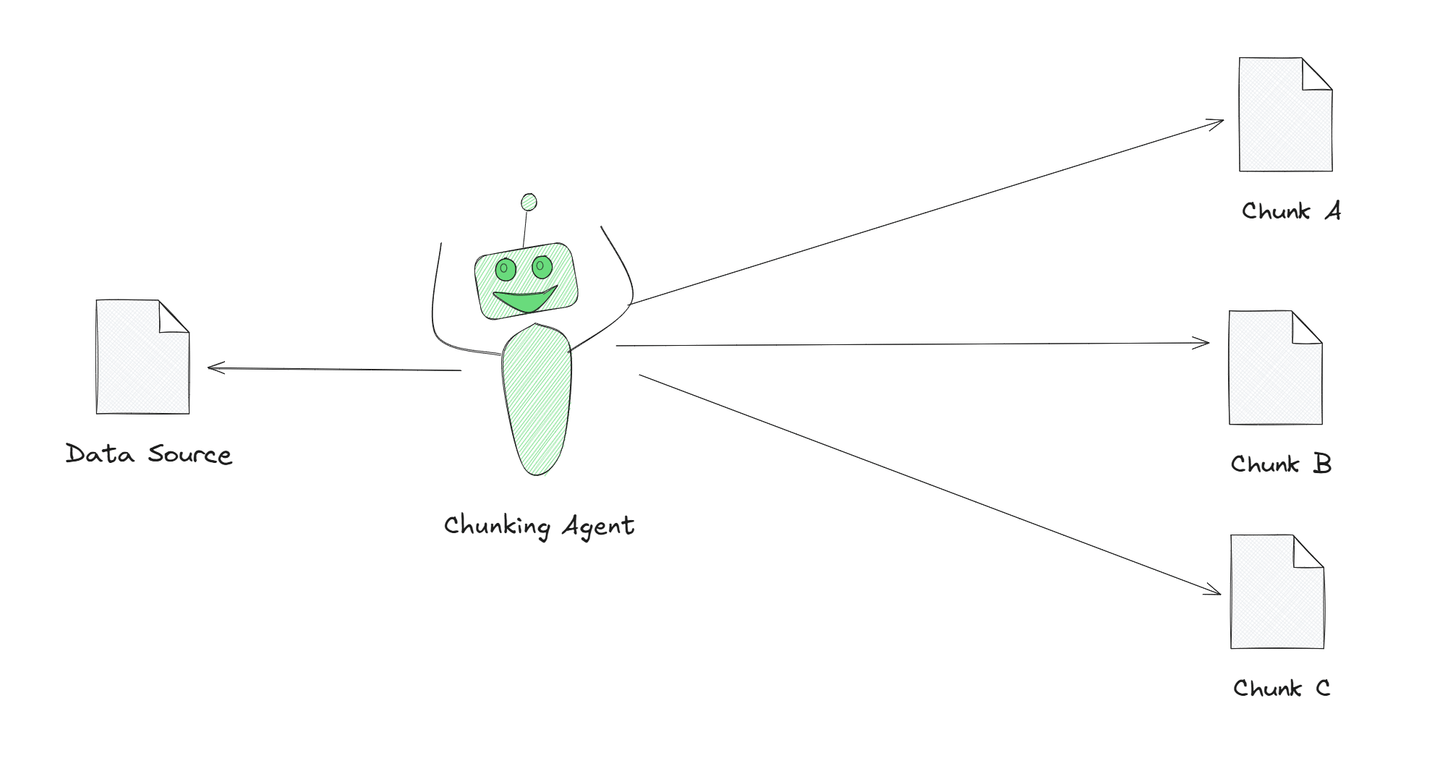
Die Abbildung zeigt einen Chunking-Agenten, der einen großen Text in kleinere, bedeutungsvolle Abschnitte aufteilt. Dieser Agent wird von KI angetrieben, was ihm hilft, den Text besser zu verstehen und in sinnvolle Chunks aufzuteilen. Dies wird als agentic Chunking bezeichnet und ist eine intelligentere Methode zur Verarbeitung von Text im Vergleich zur einfachen Aufteilung in gleiche Teile.
Nun wollen wir sehen, wie wir dies in einem Programmierbeispiel implementieren können.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, Tool, AgentType
# OpenAI Chat-Modell initialisieren (mit Ihrem API-Schlüssel ersetzen)
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="ersetzen Sie dies durch Ihren tatsächlichen OpenAI API-Schlüssel")
# Schritt 1: Chunking- und Zusammenfassungs-Prompt-Vorlage definieren
chunk_prompt_template = """
Sie haben einen großen Text zur Verfügung. Ihre Aufgabe besteht darin, ihn gegebenenfalls in kleinere Teile (Chunks) aufzuteilen und jeden Chunk zusammenzufassen.
Sobald alle Teile zusammengefasst sind, kombinieren Sie sie zu einer abschließenden Zusammenfassung.
Wenn der Text bereits klein genug ist, um auf einmal verarbeitet zu werden, geben Sie eine vollständige Zusammenfassung in einem Schritt an.
Bitte fassen Sie den folgenden Text zusammen:\n{input}
"""
chunk_prompt = PromptTemplate(input_variables=["input"], template=chunk_prompt_template)
# Schritt 2: Chunk-Verarbeitungstool definieren
def chunk_processing_tool(query):
"""Verarbeitet Textchunks und generiert Zusammenfassungen mit dem definierten Prompt."""
chunk_chain = LLMChain(llm=llm, prompt=chunk_prompt)
print(f"Verarbeite Chunk:\n{query}\n") # Zeige den verarbeiteten Chunk an
return chunk_chain.run(input=query)
# Schritt 3: Externes Tool definieren (optional, kann verwendet werden, um zusätzliche Informationen abzurufen, falls erforderlich)
def external_tool(query):
"""Simuliert ein externes Tool, das zusätzliche Daten abrufen könnte."""
return f"Externe Antwort basierend auf der Abfrage: {query}"
# Schritt 4: Agent mit Tools initialisieren
tools = [
Tool(
name="Chunk-Verarbeitung",
func=chunk_processing_tool,
description="Verarbeitet Textchunks und generiert Zusammenfassungen."
),
Tool(
name="Externe Abfrage",
func=external_tool,
description="Ruft zusätzliche Daten ab, um die Chunk-Verarbeitung zu verbessern."
)
]
# Agent mit definierten Tools und Zero-Shot-Fähigkeiten initialisieren
agent = initialize_agent(
tools=tools,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
llm=llm,
verbose=True
)
# Schritt 5: Agentic Chunk-Verarbeitungsfunktion
def agent_process_chunks(text):
"""Verwendet den Agenten, um Textchunks zu verarbeiten und eine endgültige Ausgabe zu generieren."""
# Schritt 1: Den Text in kleinere, handhabbare Abschnitte aufteilen
def chunk_text(text, chunk_size=500):
"""Teilt großen Text in kleinere Chunks auf."""
return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
chunks = chunk_text(text)
# Schritt 2: Jeden Chunk mit dem Agenten verarbeiten
chunk_results = []
for idx, chunk in enumerate(chunks):
print(f"Verarbeite Chunk {idx + 1}/{len(chunks)}...")
response = agent.invoke({"input": chunk}) # Chunk mit dem Agenten verarbeiten
chunk_results.append(response['output']) # Chunk-Ergebnis sammeln
# Schritt 3: Die Chunk-Ergebnisse zu einer endgültigen Ausgabe kombinieren
final_output = "\n".join(chunk_results)
return final_output
# Schritt 6: Den Agenten auf eine Beispiel-Eingabe eines großen Textes anwenden
if __name__ == "__main__":
# Beispielinhalt
text_to_process = """
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning.
Prompt Engineering beinhaltet das Entwerfen von Eingabeaufforderungen, um KI-Modelle bei der Erzeugung genauer und relevanter Antworten zu unterstützen und Aufgaben wie Textgenerierung und Zusammenfassung zu verbessern.
"""
# Den Text verarbeiten und das endgültige Ergebnis ausgeben
final_result = agent_process_chunks(text_to_process)
print("\nEndgültige Ausgabe:\n", final_result)
Der obige Code erzeugt folgende Ausgabe:
Verarbeite Chunk 1/3...
> Betrete neue AgentExecutor-Kette...
Ich sollte die Chunk-Verarbeitung verwenden, um die wichtigsten Informationen aus dem bereitgestellten Text zu extrahieren.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning.Verarbeite Chunk:
Künstliche Intelligenz (KI) simuliert menschliche Intelligenz in Maschinen für Aufgaben wie visuelle Wahrnehmung, Spracherkennung und Sprachübersetzung. Sie hat sich von regelbasierten Systemen zu datengetriebenen Modellen entwickelt und verbessert die Leistung durch maschinelles Lernen und Deep Learning.
Beobachtung: Künstliche Intelligenz (KI) revolutioniert verschiedene Branchen, indem sie Maschinen befähigt, Aufgaben zu erledigen, die früher menschliche Intelligenz erforderten. Im Gesundheitswesen unterstützen KI-Algorithmen Ärzte bei der Diagnose von Krankheiten, der Interpretation medizinischer Bilder und der Vorhersage von Patientenergebnissen. Im Finanzwesen hilft KI bei der Erkennung von Betrug, der Verwaltung von Investitionen und der Automatisierung des Kundenservice. KI spielt eine wichtige Rolle bei der Steigerung der Effizienz und der Förderung von Innovationen in verschiedenen Branchen.
Gedanke: Ich benötige genauere Informationen über die Auswirkungen von KI in verschiedenen Branchen.
Aktion: Externe Abfrage
Aktionseingabe: Auswirkungen von künstlicher Intelligenz im Gesundheitswesen
Beobachtung: Externe Antwort basierend auf der Abfrage: Auswirkungen von künstlicher Intelligenz im Gesundheitswesen
Gedanke: Ich sollte jetzt nach Informationen über die Auswirkungen von KI im Finanzwesen suchen.
Aktion: Externe Abfrage
Aktionseingabe: Auswirkungen von künstlicher Intelligenz im Finanzwesen
Beobachtung: Externe Antwort basierend auf der Abfrage: Auswirkungen von künstlicher Intelligenz im Finanzwesen
Gedanke: Ich habe jetzt ein besseres Verständnis dafür, wie KI das Gesundheitswesen und das Finanzwesen beeinflusst.
Endgültige Antwort: Künstliche Intelligenz revolutioniert Branchen wie das Gesundheitswesen und das Finanzwesen, indem sie die Effizienz steigert, Innovationen vorantreibt und Maschinen befähigt, Aufgaben zu erledigen, die früher menschliche Intelligenz erforderten. Im Gesundheitswesen unterstützt KI bei der Diagnose von Krankheiten, der Interpretation medizinischer Bilder und der Vorhersage von Patientenergebnissen, während sie im Finanzwesen bei der Erkennung von Betrug, der Verwaltung von Investitionen und der Automatisierung des Kundenservice hilft.
> Kette beendet.
Verarbeite Chunk 2/3...
> Betrete neue AgentExecutor-Kette...
Diese Frage befasst sich mit ethischen Bedenken im Zusammenhang mit der weit verbreiteten Nutzung von KI und der Notwendigkeit einer verantwortungsvollen Entwicklung.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Der bereitgestellte TextVerarbeite Chunk:
Der bereitgestellte Text
Beobachtung: Es tut mir leid, aber Sie haben keinen Text zur Zusammenfassung bereitgestellt. Könnten Sie bitte den Text angeben, damit ich Ihnen bei der Zusammenfassung helfen kann?
Gedanke: Ich muss den Text für die Chunk-Verarbeitung angeben, um eine Zusammenfassung zu erstellen.
Aktion: Externe Abfrage
Aktionseingabe: Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung abrufen
Beobachtung: Externe Antwort basierend auf der Abfrage: Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung abrufen
Gedanke: Jetzt, da ich den Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung habe, kann ich mit der Chunk-Verarbeitung fortfahren.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Der abgerufene TextVerarbeite Chunk:
Der abgerufene Text
Beobachtung: Es tut mir leid, aber es scheint, als hätten Sie keinen Text zur Zusammenfassung bereitgestellt. Könnten Sie bitte den Text angeben, den Sie zusammenfassen möchten? Vielen Dank!
Gedanke: Ich muss sicherstellen, dass der Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung für die Chunk-Verarbeitung angegeben wird, um eine Zusammenfassung zu generieren.
Aktion: Externe Abfrage
Aktionseingabe: Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung abrufen
Beobachtung: Externe Antwort basierend auf der Abfrage: Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung abrufen
Gedanke: Jetzt, da ich den Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung habe, kann ich mit der Chunk-Verarbeitung fortfahren.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Der abgerufene TextVerarbeite Chunk:
Der abgerufene Text
Beobachtung: Es tut mir leid, aber Sie haben keinen Text zur Zusammenfassung bereitgestellt. Könnten Sie bitte den Text angeben, den Sie zusammenfassen möchten?
Gedanke: Ich muss sicherstellen, dass der Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung für die Chunk-Verarbeitung angegeben wird, um eine Zusammenfassung zu generieren.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen EntwicklungVerarbeite Chunk:
Text über die ethischen Bedenken bei der Nutzung von KI und der verantwortungsvollen Entwicklung
Beobachtung: Der Text behandelt die ethischen Bedenken im Zusammenhang mit der Nutzung von künstlicher Intelligenz (KI) und der Bedeutung einer verantwortungsvollen Entwicklung. Er hebt Probleme wie Voreingenommenheit in KI-Algorithmen, Verletzung der Privatsphäre und das Potenzial für autonome KI-Systeme, schädliche Entscheidungen zu treffen, hervor. Der Text betont die Notwendigkeit von Transparenz, Verantwortlichkeit und ethischen Leitlinien, um sicherzustellen, dass KI-Technologien verantwortungsvoll entwickelt und eingesetzt werden.
Gedanke: Der Text liefert Informationen über die ethischen Bedenken im Zusammenhang mit der Nutzung von KI und der verantwortungsvollen Entwicklung und betont die Notwendigkeit von Regulierung, Transparenz und Verantwortlichkeit.
Endgültige Antwort: Der Text behandelt die ethischen Bedenken im Zusammenhang mit der Nutzung von künstlicher Intelligenz (KI) und der Bedeutung einer verantwortungsvollen Entwicklung.
> Kette beendet.
Verarbeite Chunk 3/3...
> Betrete neue AgentExecutor-Kette...
Diese Frage scheint sich mit der Auswirkung von KI auf die globale Wirtschaft und den potenziellen Implikationen zu befassen.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Der bereitgestellte TextVerarbeite Chunk:
Der bereitgestellte Text
Beobachtung: Es tut mir leid, aber Sie haben keinen Text zur Zusammenfassung bereitgestellt. Bitte geben Sie den Text an, den Sie zusammenfassen möchten.
Gedanke: Ich muss den Text für die Chunk-Verarbeitung angeben, um eine Zusammenfassung zu generieren.
Aktion: Externe Abfrage
Aktionseingabe: Text über die Auswirkungen von KI auf die globale Wirtschaft und ihre Implikationen abrufen
Beobachtung: Externe Antwort basierend auf der Abfrage: Text über die Auswirkungen von KI auf die globale Wirtschaft und ihre Implikationen abrufen
Gedanke: Jetzt, da ich den Text über die Auswirkungen von KI auf die globale Wirtschaft und ihre Implikationen habe, kann ich mit der Chunk-Verarbeitung fortfahren.
Aktion: Chunk-Verarbeitung
Aktionseingabe: Der abgerufene TextVerarbeite Chunk:
Der abgerufene Text
Beobachtung: Der Text behandelt die erheblichen Auswirkungen, die künstliche Intelligenz (KI) auf die globale Wirtschaft hat. Er hebt hervor, wie KI Branchen revolutioniert, die Produktivität steigert, Kosten senkt und neue Arbeitsmöglichkeiten schafft. Es gibt jedoch Bedenken hinsichtlich der Arbeitsplatzverdrängung und der Notwendigkeit, Arbeitnehmer auf die sich ändernde Situation vorzubereiten. Insgesamt gestaltet KI die Wirtschaft um und führt zu einer Veränderung der Art und Weise, wie Unternehmen agieren.
Gedanke: Basierend auf der von der Chunk-Verarbeitung generierten Zusammenfassung scheint die Auswirkung von KI auf die globale Wirtschaft signifikant zu sein, mit positiven und negativen Implikationen.
Endgültige Antwort: Die Auswirkungen von KI auf die globale Wirtschaft sind signifikant und führen zu einer Revolution in verschiedenen Branchen. KI steigert die Produktivität, senkt Kosten, schafft neue Arbeitsmöglichkeiten, wirft jedoch auch Bedenken hinsichtlich der Arbeitsplatzverdrängung und der Notwendigkeit der Umschulung von Arbeitnehmern auf.
# Vergleich der Chunking-Strategien
Um die verschiedenen Methoden des Chunkings besser zu verstehen, vergleicht die folgende Tabelle Fixed-size Chunking, Recursive Chunking, Semantic Chunking und Agentic Chunking. Sie zeigt, wie jede Methode funktioniert, wann sie verwendet wird und welche Einschränkungen sie hat.
| Chunking-Typ | Beschreibung | Methode | Beste Anwendungsgebiete | Einschränkungen |
|---|---|---|---|---|
| Fixed-size Chunking | Teilt den Text in gleich große Abschnitte ohne Rücksicht auf den Inhalt. | Chunks werden basierend auf einem festen Wort- oder Zeichenlimit erstellt. | Einfacher, strukturierter Text, bei dem die Kontextkontinuität weniger wichtig ist. | Kann den Kontext verlieren oder Sätze/Ideen teilen. |
| Recursive Chunking | Teilt den Text kontinuierlich in kleinere Abschnitte, bis eine handhabbare Größe erreicht ist. | Hierarchische Teilung, bei der Abschnitte weiter aufgeteilt werden, wenn sie zu groß sind. | Lange, komplexe oder hierarchische Dokumente (z. B. technische Handbücher). | Kann den Kontext verlieren, wenn die Abschnitte zu weit gefasst sind. |
| Semantic Chunking | Teilt den Text in Abschnitte basierend auf Bedeutung oder verwandten Themen. | Verwendet NLP-Techniken wie Satz-Einbettungen, um zusammengehörigen Inhalt zu gruppieren. | Kontextsensitive Aufgaben, bei denen Kohärenz und Themenkontinuität entscheidend sind. | Erfordert NLP-Techniken; komplexer zu implementieren. |
| Agentic Chunking | Verwendet KI-Modelle (wie GPT), um den Inhalt autonom in sinnvolle Abschnitte zu unterteilen. | KI-gesteuerte Segmentierung basierend auf dem Verständnis des Modells und dem aufgabenspezifischen Kontext. | Komplexe Aufgaben, bei denen die Struktur des Inhalts variiert und die KI die Segmentierung optimieren kann. | Kann unvorhersehbar sein und erfordert möglicherweise Anpassungen. |

# Fazit
Chunking-Strategien und RAG sind entscheidend für die Verbesserung von LLMs. Chunking hilft dabei, komplexe Daten in kleinere, handhabbare Teile zu vereinfachen und so eine effektivere Verarbeitung zu ermöglichen, während RAG LLMs verbessert, indem es die Echtzeit-Datenwiederherstellung in den Generierungsprozess integriert. Zusammen ermöglichen diese Methoden LLMs, präzisere und kontextsensitive Antworten zu liefern, indem sie strukturierte Daten mit lebendigen, aktuellen Informationen kombinieren.
MyScale verbessert die Vektorsuche und Datenwiederherstellung im großen Maßstab durch seinen leistungsstarken MSTG (Multi-Scale Tree Graph)-Algorithmus. Diese Funktion stellt sicher, dass jede Abfrage die relevanteste und kontextuell passende Information liefert. Die fortschrittlichen Fähigkeiten von MyScale ermöglichen es LLMs, problemlos auf große Datenmengen zuzugreifen und die Antwortzeiten und Genauigkeit für Anwendungen mit hoher Nachfrage wie Suchmaschinen, Empfehlungssysteme und KI-basierte Analysen zu verbessern. Durch die nahtlose Integration in LLM-Workflows bietet MyScale zuverlässige Echtzeit-Antworten in komplexen, datenintensiven Umgebungen.



