
Dieser Artikel wurde ursprünglich auf The New Stack (opens new window) veröffentlicht.
Große Sprachmodelle (LLMs) sind intelligent genug, um den Kontext zu verstehen. Sie können Fragen beantworten und mithilfe ihrer umfangreichen Trainingsdaten kohärente und kontextuell relevante Antworten liefern, unabhängig davon, ob es sich um Astronomie, Geschichte oder sogar Physik handelt. Aufgrund ihrer Unfähigkeit, Zusammenhänge herzustellen und sich an alle Details zu erinnern, können LLMs, insbesondere kleinere Modelle wie llama2-13b-chat, Halluzinationen haben, selbst wenn das angeforderte Wissen in den Trainingsdaten vorhanden ist.
Eine neue Technik namens Retrieval Augmented Generation (RAG) füllt die Wissenslücken, reduziert Halluzinationen und erweitert die Prompts mit externen Daten. In Kombination mit einer Vektordatenbank (wie MyScale (opens new window)) erhöht sie die Leistungsgewinne in extraktiven Frage-Antwort-Systemen, selbst bei umfangreichen Wissensbasen wie Wikipedia im Trainingsset.
In diesem Artikel liegt der Fokus darauf, den Leistungsgewinn mit RAG anhand des weit verbreiteten MMLU-Datensatzes zu bestimmen. Wir stellen fest, dass sowohl die Leistung kommerzieller als auch quelloffener LLMs signifikant verbessert werden kann, wenn Wissen mithilfe einer Vektordatenbank aus Wikipedia abgerufen werden kann. Interessanterweise wird dieses Ergebnis auch dann erzielt, wenn Wikipedia bereits im Trainingsset dieser Modelle enthalten ist.
Den Code für das Benchmark-Framework und dieses Beispiel finden Sie hier (opens new window).
# Retrieval Augmented Generation
Aber zuerst beschreiben wir Retrieval Augmented Generation (RAG).
Forschungsprojekte zielen darauf ab, LLMs wie gpt-3.5 durch Kopplung mit externen Wissensbasen (wie Wikipedia), Datenbanken oder dem Internet zu verbessern, um Wissensgebiete besser zu verstehen und kontextbewusstere Systeme zu schaffen. Angenommen, ein Benutzer fragt ein LLM nach dem wichtigsten Ergebnis von Newton. Um dem LLM bei der Suche nach den richtigen Informationen zu helfen, können wir nach Newtons Wiki suchen und die Wiki-Seite dem LLM als Kontext zur Verfügung stellen.
Diese Methode wird Retrieval Augmented Generation (RAG) genannt. Lewis et al. definieren in Retrieval Augmented Generation for Knowledge-Intensive NLP Tasks (opens new window) Retrieval Augmented Generation wie folgt:
"Ein Typ von Sprachgenerierungsmodell, das vortrainierte parametrische und nicht-parametrische Speicher für die Sprachgenerierung kombiniert."
Darüber hinaus stellen die Autoren dieses wissenschaftlichen Artikels fest, dass sie:
"Vortrainierte, parametrische Speicher-Generierungsmodelle durch einen nicht-parametrischen Speicher durch einen allgemeinen Feinabstimmungsansatz erweitern."
Hinweis:
Parametrische Speicher-LLMs sind umfangreiche, eigenständige Wissensspeicher wie ChatGPT und Googles PaLM. Nicht-parametrische Speicher-LLMs nutzen externe Ressourcen, die zusätzlichen Kontext zu parametrischen Speicher-LLMs hinzufügen.
Die Kombination externer Ressourcen mit LLMs scheint machbar zu sein, da LLMs gute Lernende sind und die Bezugnahme auf spezifische externe Wissensdomänen die Wahrhaftigkeit verbessern kann. Aber wie viel Verbesserung wird diese Kombination bringen?
Zwei Hauptfaktoren beeinflussen ein RAG-System:
- Wie viel ein LLM aus dem externen Kontext lernen kann
- Wie genau und relevant der externe Kontext ist
Beide Faktoren sind schwer zu bewerten. Das vom LLM aus dem Kontext gewonnene Wissen ist implizit, daher ist der praktischste Weg, diese Faktoren zu bewerten, die Antwort des LLM zu untersuchen. Die Genauigkeit des abgerufenen Kontexts ist jedoch ebenfalls schwierig zu bewerten.
Die Relevanz zwischen Absätzen zu messen, insbesondere in Frage-Antwort- oder Information-Retrieval-Aufgaben, kann eine komplexe Aufgabe sein. Die Relevanzbewertung ist entscheidend, um festzustellen, ob ein bestimmter Abschnitt Informationen enthält, die direkt mit einer bestimmten Frage zusammenhängen. Dies ist besonders wichtig bei Aufgaben, bei denen Informationen aus großen Datensätzen oder Dokumenten extrahiert werden, wie dem WikiHop (opens new window)-Datensatz.
Manchmal verwenden Datensätze mehrere Annotatoren, um die Relevanz zwischen Absätzen und Fragen zu bewerten. Die Verwendung mehrerer Annotatoren zur Abstimmung über die Relevanz hilft, Subjektivität und mögliche Vorurteile zu mindern, die von einzelnen Annotatoren herrühren können. Diese Methode trägt auch zu einer Konsistenz bei und stellt sicher, dass das Relevanzurteil zuverlässiger ist.
Als Folge all dieser Unsicherheiten haben wir eine Open-Source-End-to-End-Bewertung des RAG-Systems entwickelt. Diese Bewertung berücksichtigt verschiedene Modellkonfigurationen, Abrufpipelines, Wissensbasisoptionen und Suchalgorithmen.
Wir möchten wertvolle Grundlinien für RAG-Systemdesigns bereitstellen und hoffen, dass sich mehr Entwickler und Forscher uns anschließen, um ein umfassendes und systematisches Benchmark aufzubauen. Weitere Ergebnisse helfen uns dabei, diese beiden Faktoren zu entwirren und einen Datensatz zu erstellen, der den RAG-Systemen in der realen Welt näher kommt.
Hinweis:
Teilen Sie Ihre Bewertungsergebnisse auf GitHub (opens new window). Pull Requests sind sehr willkommen!
# Eine einfache End-to-End-Grundlinie für ein RAG-System
![]()
In diesem Artikel konzentrieren wir uns auf eine einfache Grundlinie, die anhand eines MMLU (Massive Multitask Language Understanding) Datensatzes (opens new window) bewertet wird, einem weit verbreiteten Benchmark für LLMs (opens new window), der Multiple-Choice-Einzelfragen zu vielen Themen wie Geschichte, Astronomie und Wirtschaft enthält.
Wir möchten herausfinden, ob ein LLM aus zusätzlichen Kontexten lernen kann, indem wir es Multiple-Choice-Fragen beantworten lassen.
Um unser Ziel zu erreichen, haben wir Wikipedia als unsere Wahrheitsquelle gewählt, da es viele Themen und Wissensdomänen abdeckt. Wir haben die von Cohere.ai (opens new window) auf Hugging Face bereinigte Version verwendet, die 34.879.571 Absätze zu 5.745.033 Titeln enthält. Eine umfassende Suche in diesen Absätzen würde ziemlich lange dauern, daher müssen wir die geeigneten ANNS (Approximate Nearest Neighbor Search)-Algorithmen verwenden, um relevante Dokumente abzurufen. Darüber hinaus verwenden wir die MyScale-Datenbank mit dem MSTG-Vektorindex, um die relevanten Dokumente abzurufen.
# Semantisches Suchmodell
Semantisches Suchen ist ein gut erforschtes Thema mit vielen Modellen (opens new window) und detaillierten Benchmarks (opens new window). Wenn es mit Vektor-Embeddings kombiniert wird, erhält semantisches Suchen die Fähigkeit, paraphrasierte Ausdrücke, Synonyme und den Kontext zu erkennen.
Darüber hinaus bieten Embeddings dichte und kontinuierliche Vektorrepräsentationen, die die Berechnung sinnvoller Relevanzmetriken ermöglichen. Diese dichten Metriken erfassen semantische Beziehungen und Kontext und sind daher wertvoll für die Bewertung der Relevanz in LLM-Information-Retrieval-Aufgaben.
Unter Berücksichtigung der oben genannten Faktoren haben wir uns entschieden, das Modell paraphrase-multilingual-mpnet-base-v2 (opens new window) von Hugging Face zu verwenden, um Features für Retrieval-Aufgaben zu extrahieren. Dieses Modell ist Teil der MPNet-Familie und wurde entwickelt, um hochwertige Embeddings zu generieren, die für verschiedene NLP-Aufgaben wie semantische Ähnlichkeit und Retrieval geeignet sind.
# Große Sprachmodelle (LLMs)
Für unsere LLMs haben wir uns für OpenAIs gpt-3.5-turbo und llama2-13b-chat mit Quantisierung in 6 Bits entschieden. Diese Modelle sind die beliebtesten in kommerziellen und Open-Source-Trends. Das LLaMA2-Modell wird von llama.cpp (opens new window) quantisiert. Wir haben diese 6-Bit-Quantisierung gewählt, da sie erschwinglich ist, ohne die Leistung zu beeinträchtigen.
Hinweis:
Sie können auch andere Modelle ausprobieren, um ihre RAG-Leistung zu testen.
# Unser RAG-System
Das folgende Bild beschreibt, wie ein einfaches RAG-System formuliert wird:
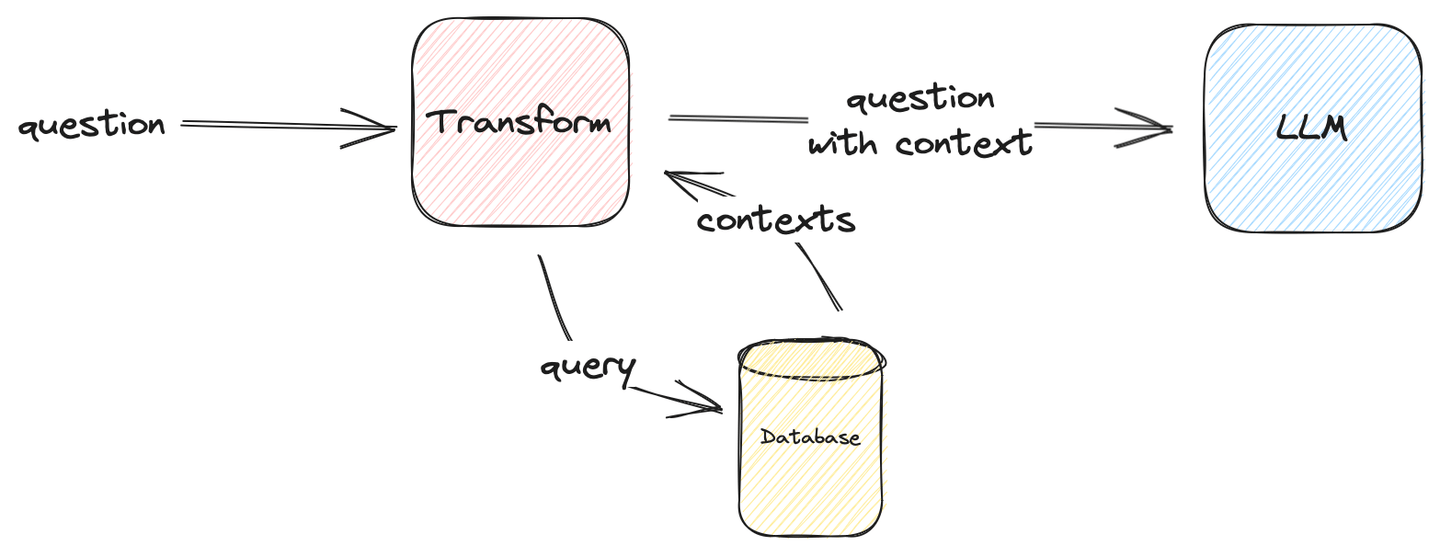
Abbildung 1: Einfaches Benchmarking RAG
Hinweis:
Transform kann alles sein, solange es dem LLM zugeführt werden kann und die richtige Antwort zurückgibt. In unserem Anwendungsfall fügt Transform dem Fragekontext Informationen hinzu.
Unser endgültiger LLM-Prompt lautet wie folgt:
template = \
("The following are multiple choice questions (with answers) with context:"
"\n\n{context}Question: {question}\n{choices}Answer: ")
Nun gehen wir zum Ergebnis über!
# Mehrere Erkenntnisse aus dem Benchmark
Unsere Benchmark-Testergebnisse sind in Tabelle 1 zusammengefasst.
Aber zuerst unsere zusammengefassten Erkenntnisse:
- Zusätzlicher Kontext hilft normalerweise
- Mehr Kontext hilft manchmal
- Kleinere Modelle sind wissenshungriger
Tabelle 1: Abrufgenauigkeit mit verschiedenen Kontexten
| Setup | Dataset | Average | |||||
|---|---|---|---|---|---|---|---|
| LLM | Contexts | mmlu-astronomy | mmlu-prehistory | mmlu-global-facts | mmlu-college-medicine | mmlu-clinical-knowledge | |
| gpt-3.5-turbo | ❌ | 71.71% | 70.37% | 38.00% | 67.63% | 74.72% | 68.05% |
| ✅ (Top-1) | 75.66% (+3.95%) | 78.40% (+8.03%) | 46.00% (+8.00%) | 67.05% (-0.58%) | 73.21% (-1.51%) | 71.50% (+3.45%) | |
| ✅ (Top-3) | 76.97% (+5.26%) | 81.79% (+11.42%) | 48.00% (+10.00%) | 65.90% (-1.73%) | 73.96% (-0.76%) | 72.98% (+4.93%) | |
| ✅ (Top-5) | 78.29% (+6.58%) | 79.63% (+9.26%) | 42.00% (+4.00%) | 68.21% (+0.58%) | 74.34% (-0.38%) | 72.39% (+4.34%) | |
| ✅ (Top-10) | 78.29% (+6.58%) | 79.32% (+8.95%) | 44.00% (+6.00%) | 71.10% (+3.47%) | 75.47% (+0.75%) | 73.27% (+5.22%) | |
| llama2-13b-chat-q6_0 | ❌ | 53.29% | 57.41% | 33.00% | 44.51% | 50.19% | 50.30% |
| ✅ (Top-1) | 58.55% (+5.26%) | 61.73% (+4.32%) | 45.00% (+12.00%) | 46.24% (+1.73%) | 54.72% (+4.53%) | 55.13% (+4.83%) | |
| ✅ (Top-3) | 63.16% (+9.87%) | 63.27% (+5.86%) | 49.00% (+16.00%) | 46.82% (+2.31%) | 55.85% (+5.66%) | 57.10% (+6.80%) | |
| ✅ (Top-5) | 63.82% (+10.53%) | 65.43% (+8.02%) | 51.00% (+18.00%) | 51.45% (+6.94%) | 57.74% (+7.55%) | 59.37% (+9.07%) | |
| ✅ (Top-10) | 65.13% (+11.84%) | 66.67% (+9.26%) | 46.00% (+13.00%) | 49.71% (+5.20%) | 57.36% (+7.17%) | 59.07% (+8.77%) | |
| * Der Benchmark verwendet MyScale MSTG als Vektorindex * Dieser Benchmark kann mit unserem GitHub-Repository retrieval-qa-benchmark reproduziert werden | |||||||
# 1. Zusätzlicher Kontext hilft normalerweise
In diesen Benchmark-Tests haben wir die Leistung mit und ohne Kontext verglichen. Der Test ohne Kontext repräsentiert, wie internes Wissen Fragen lösen kann. Zweitens zeigt der Test mit Kontext, wie ein LLM aus dem Kontext lernen kann.
Hinweis:
Sowohl llama2-13b-chat als auch gpt-3.5-turbo werden insgesamt um etwa 3-5% verbessert, selbst mit nur einem zusätzlichen Kontext.
Die Tabelle zeigt, dass einige Zahlen negativ sind, zum Beispiel, wenn wir Kontext in clinical-knowledge in gpt-3.5-turbo einfügen.
Dies könnte mit der Wissensbasis zusammenhängen, da Wikipedia nicht viele Informationen über klinisches Wissen enthält, oder weil die Nutzungsbedingungen und Richtlinien von OpenAI klar angeben, dass die Verwendung ihrer KI-Modelle für medizinische Ratschläge stark abgeraten wird und sogar verboten sein kann. Trotzdem ist der Anstieg für beide Modelle deutlich erkennbar.
Besonders die Ergebnisse des gpt-3.5-turbo deuten darauf hin, dass das RAG-System möglicherweise leistungsstark genug ist, um mit anderen Sprachmodellen zu konkurrieren. Einige der gemeldeten Zahlen, wie die zu prehistory und astronomy, tendieren in Richtung der Leistung von gpt4 mit zusätzlichen Tokens, was darauf hindeutet, dass RAG eine weitere Lösung für spezialisierte künstliche Allgemeine Intelligenz (AGI) sein könnte, im Vergleich zum Feinabstimmungsverfahren.
Hinweis:
RAG ist praktischer als Feinabstimmungsmodelle, da es eine Plug-in-Lösung ist und sowohl mit selbst gehosteten als auch mit Remote-Modellen funktioniert.
# 2. Mehr Kontext hilft manchmal
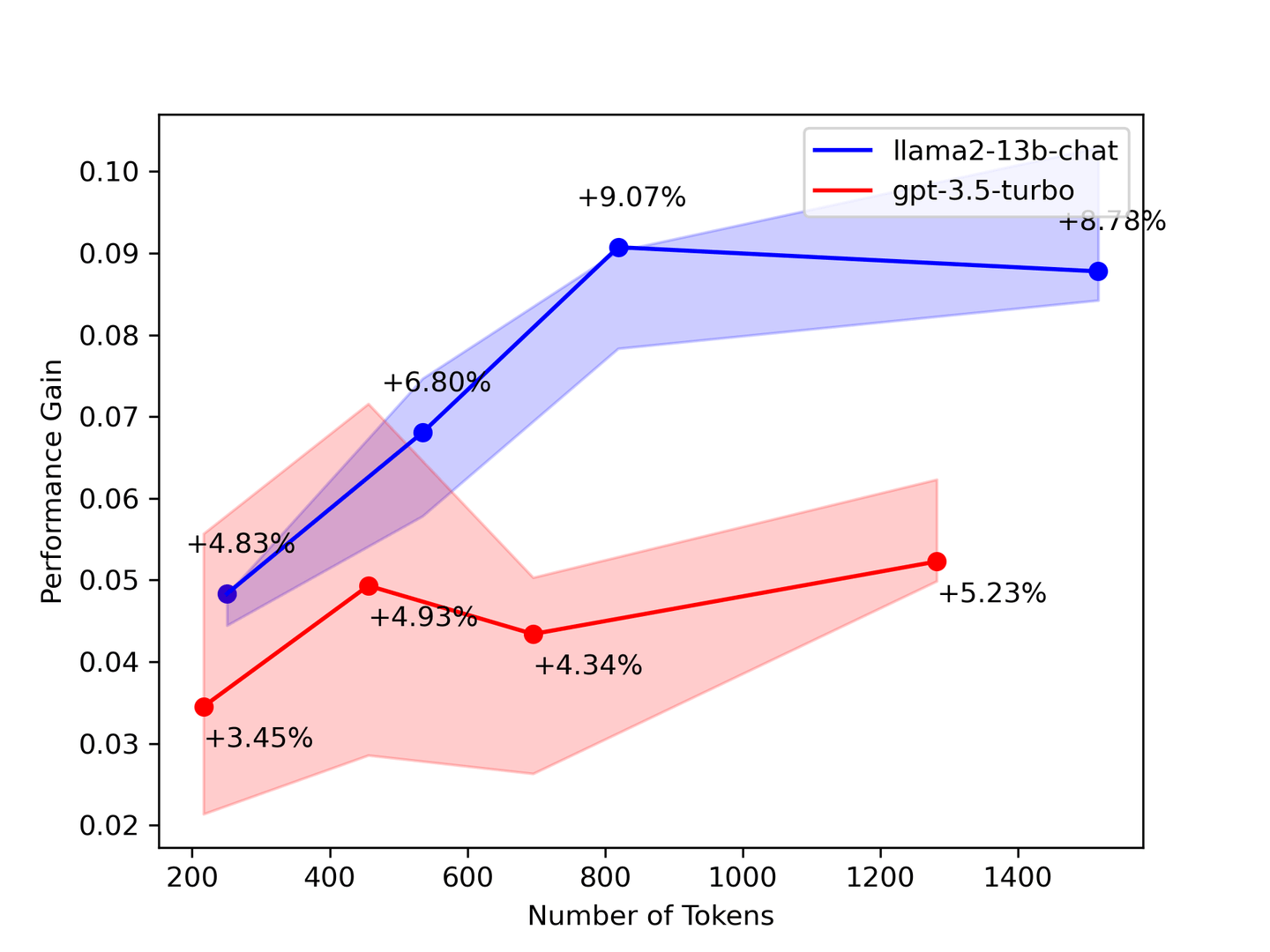
Abbildung 2: Leistungszuwachs vs. Anzahl der Kontexte
Der obige Benchmark legt nahe, dass Sie so viel Kontext wie möglich benötigen. In den meisten Fällen werden LLMs aus allen bereitgestellten Kontexten lernen. Theoretisch liefert das Modell bessere Antworten, je mehr abgerufene Dokumente vorhanden sind. Unsere Benchmarking-Ergebnisse zeigen jedoch, dass einige Zahlen umso mehr sanken, je mehr Kontexte abgerufen wurden.
Um unsere Benchmarking-Ergebnisse zu validieren, legt ein Paper der Stanford University mit dem Titel "Lost in the Middle: How Language Models Use Long Contexts" (opens new window) nahe, dass das LLM nur den Anfang und das Ende des Kontexts betrachtet. Wählen Sie daher weniger, aber genauere Kontexte aus dem Abrufsystem aus, um Ihr LLM zu ergänzen.
# 3. Kleinere Modelle sind wissenshungriger
Je größer das LLM, desto mehr Wissen speichert es. Größere LLMs haben tendenziell eine größere Kapazität, Informationen zu speichern und zu verstehen, was oft zu einer breiteren Wissensbasis allgemein verstandener Fakten führt. Unsere Benchmarking-Tests erzählen die gleiche Geschichte: Die kleineren LLMs haben weniger Wissen und sind wissenshungriger.
Unsere Ergebnisse zeigen, dass llama2-13b-chat einen größeren Wissenszuwachs aufweist als gpt-3.5-turbo, was darauf hindeutet, dass Kontext einem LLM mehr Wissen für die Informationsabrufung vermittelt. Darüber hinaus legen diese Ergebnisse nahe, dass gpt-3.5-turbo bereits bekannte Informationen erhalten hat, während llama2-13b-chat immer noch aus dem Kontext lernt.
# Zuletzt, aber nicht zuletzt ...
Fast jedes LLM verwendet den Wikipedia-Korpus als Trainingsdatensatz, was bedeutet, dass sowohl gpt-3.5-turbo als auch llama2-13b-chat mit den dem Prompt hinzugefügten Kontexten vertraut sein sollten. Daher stellen sich folgende Fragen:
- Was ist der Grund für die Zunahmen in diesem Benchmark-Test?
- Lernt das LLM wirklich mithilfe der bereitgestellten Kontexte?
- Oder helfen diese zusätzlichen Kontexte dabei, aus dem im Trainingssatz gelernten Wissen zu erinnern?
Wir haben derzeit keine Antworten auf diese Fragen. Daher ist weitere Forschung erforderlich.

# Beitrag zum gemeinsamen Aufbau eines RAG-Benchmarks
Tragen Sie zur Forschung bei, um anderen zu helfen.
Wir können in diesem Artikel nur eine begrenzte Anzahl von Bewertungen abdecken. Aber wir wissen, dass mehr benötigt wird. Die Ergebnisse jedes Benchmark-Tests sind wichtig, unabhängig davon, ob es sich um Replikationen bestehender Tests oder um neue Erkenntnisse auf der Grundlage neuartiger RAGs handelt.
Mit dem Ziel, allen dabei zu helfen, Benchmark-Tests für ihre RAG-Systeme zu erstellen, haben wir unser End-to-End-Benchmark-Framework (opens new window) als Open Source veröffentlicht. Besuchen Sie unsere GitHub-Seite, um unser Repository zu fork!
Dieses Framework enthält die folgenden Tools:
- Ein universeller Profiler, der den Zeitverbrauch für die Abruf- und LLM-Generierung messen kann.
- Eine Graphenausführungsmaschine, mit der Sie komplexe Abrufpipelines erstellen können.
- Eine einheitliche Konfiguration, in der Sie alle Ihre Experimenteinstellungen an einem Ort festhalten können.
Es liegt an Ihnen, Ihren eigenen Benchmark zu erstellen. Wir glauben, dass RAG eine mögliche Lösung für AGI sein kann. Daher haben wir dieses Framework für die Community entwickelt, um alles nachvollziehbar und reproduzierbar zu machen.
Pull Requests sind willkommen!
# Abschließend
Wir haben eine kleine Teilmenge von MMLU mit einem einfachen RAG-System, das verschiedene LLMs und Vektor-Suchalgorithmen verwendet, evaluiert und unseren Prozess und unsere Ergebnisse in diesem Artikel beschrieben. Wir haben auch das Bewertungsframework der Community zur Verfügung gestellt und zu weiteren RAG-Benchmarks aufgerufen. Wir werden weiterhin Benchmark-Tests durchführen und die neuesten Ergebnisse auf GitHub und im MyScale-Blog aktualisieren. Folgen Sie uns auf Twitter (opens new window) oder treten Sie unserem Discord (opens new window) bei, um auf dem Laufenden zu bleiben.



