
Der Aufstieg der KI hat eine Welle der LLM-basierten Anwendungsentwicklung ausgelöst, wobei Vektordatenbanken eine entscheidende Rolle spielen, indem sie große strukturierte und unstrukturierte Daten effizient verarbeiten. Unter ihnen hat sich MyScaleDB, eine SQL-Vektordatenbank auf Basis von ClickHouse, als erste Wahl für Entwickler herauskristallisiert. MyScaleDB ist vollständig mit SQL kompatibel und ermöglicht Entwicklern den Aufbau generativer KI-Anwendungen mit minimalem Lernaufwand. In Kombination mit Low-Code-Plattformen senkt es die Entwicklungshürden noch weiter.
Kürzlich hat MyScaleDB eine Integration mit DronaHQ, einer führenden Low-Code-Plattform, vorgenommen, um ein noch zugänglicheres Entwicklungserlebnis zu bieten. In diesem Blog wird gezeigt, wie Sie mit MyScaleDBs leistungsstarker Vektorsuche auf DronaHQ ein intelligentes Restaurant-Empfehlungssystem erstellen können, das personalisierte Vorschläge zur Verbesserung der Benutzererfahrung liefert.
# Was ist DronaHQ
DronaHQ (opens new window) ist eine leistungsstarke Low-Code-Plattform zur Anwendungsentwicklung, die Entwickler aller Kenntnisstufen zusammenbringt, um alles von einfachen Mikrowerkzeugen bis hin zu robusten Unternehmensanwendungen wie Dashboards, Datenbank-GUIs, Admin-Panels, Genehmigungs-Apps, Kundensupport-Tools usw. zu erstellen, um ihre Geschäftsabläufe zu verbessern. Die Plattform ermöglicht es Entwicklern, einfach mehrseitige Anwendungen auf verschiedenen Datenbanken zu erstellen, Drittanbieter-APIs zu integrieren und robuste Sicherheitsfunktionen, umfangreiche UI-Elemente und flexible Freigabeoptionen nach der Bereitstellung zu nutzen. DronaHQ minimiert den Engineering-Aufwand zur Entwicklung einer Anwendung ohne die Probleme des Backends. Einer der Schwerpunkte der Plattform ist die Drag-and-Drop-Funktion, bei der Entwickler freie Hand haben, um Code zu schreiben und Bibliotheksfunktionen zu verwenden, um die Benutzeroberfläche und Anpassung zu gestalten sowie Logik zu schreiben und zu debuggen.
Mit DronaHQs Low-Code-Plattform können Sie umfassende Anwendungen erstellen, die erweiterte Datenfunktionen wie Vektorsuche mit benutzerfreundlichen App-Building-Tools integrieren. Am Ende dieses Artikels haben Sie gelernt, wie Sie:
- Die Grundlagen der Vektorsuche und ihre Anwendungen verstehen.
- Daten in MyScaleDB vorbereiten und verwalten, um effektivere Suchen durchzuführen.
- MyScaleDB nahtlos in DronaHQ integrieren, um eine standortbasierte Restaurant-Empfehlungs-App zu erstellen.
- Schnell eine leistungsstarke App erstellen und bereitstellen, die erweiterte Suchfunktionen nutzt, alles innerhalb der DronaHQ-Plattform.
# Was ist Vektorsuche
Die Vektorsuche (opens new window) ist eine fortgeschrittene Technik, bei der Daten in Vektoren in einem mehrdimensionalen Raum umgewandelt werden, wobei jeder Vektor die Schlüsselfunktionen der Daten repräsentiert. Mithilfe der Kosinusähnlichkeit werden diese Vektoren dann anhand ihrer Nähe zueinander in diesem Raum verglichen. Dies hilft dabei festzustellen, wie konzeptionell oder kontextuell ähnlich sich zwei Datenpunkte sind, auch wenn sie nicht die exakt gleichen Wörter teilen. Dieser Ansatz geht über herkömmliche Stichwortsuchen hinaus, die bestimmte Schlüsselwörter abgleichen. Die Vektorsuche ist besonders nützlich, wenn Sie Elemente finden möchten, die semantisch ähnlich sind, auch wenn sie nicht identisch sind.
In einem Restaurant-Empfehlungssystem kann die Vektorsuche verschiedene Faktoren wie Ambiente, Benutzerbewertungen und gastronomische Erfahrungen analysieren und vergleichen, indem diese Aspekte in Vektorrepräsentationen umgewandelt werden. Dadurch kann das System Restaurants identifizieren, die sich in Bezug auf das gesamte gastronomische Erlebnis ähnlich sind, anstatt nur bestimmte Kriterien wie die Art der Küche oder Preisklasse abzugleichen.
# Vorbereitung der Daten in MyScaleDB
Für diesen Blog verwenden wir MyScaleDB (opens new window), eine Open-Source-SQL-Vektordatenbank mit hoher Leistung. Sie wurde entwickelt, um erweiterte Vektorsuchfunktionen mit der vertrauten SQL-Abfragesprache bereitzustellen. MyScaleDB kann sowohl strukturierte als auch vektorisierte Daten in einem vereinheitlichten System effizient verwalten und ist daher eine ideale Wahl für KI-Anwendungen im großen Maßstab.
Einer der Hauptgründe, MyScaleDB für dieses Projekt zu wählen, ist der Multi-Scale Tree Graph (MSTG) (opens new window)-Indexierungsalgorithmus. Dieser Algorithmus ermöglicht schnelle Vektoroperationen und effiziente Speicherung von Daten und übertrifft spezialisierte Vektordatenbanken sowohl in Bezug auf Kosten als auch Leistung. Am wichtigsten ist, dass MyScaleDB den neuen Benutzern erlaubt, bis zu 5 Millionen Vektoren kostenlos zu speichern, sodass wir für diese MVP-App nichts bezahlen müssen.
# Erstellen eines MyScaleDB-Clusters
Um MyScaleDB in unserer DronaHQ-Anwendung zu verwenden, müssen wir zunächst einen Cluster in der MyScaleDB-Cloud für die Datenspeicherung erstellen. Besuchen Sie dazu die MyScaleDB-Konsole (opens new window), registrieren Sie sich, melden Sie sich an und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Neuer Cluster", um Ihren MyScale-Cluster zu erstellen.
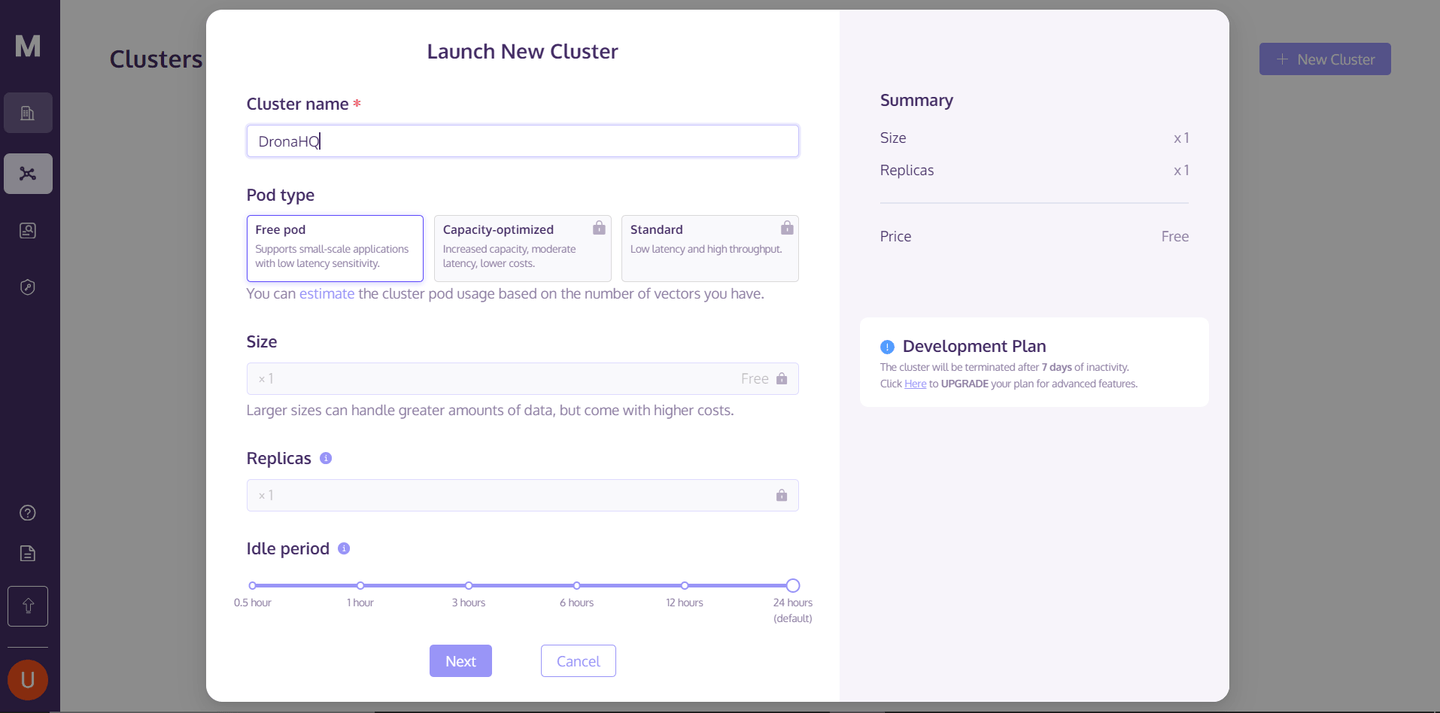
Geben Sie nach Eingabe des Cluster-Namens auf die Schaltfläche "Weiter" und warten Sie, bis der Cluster gestartet ist.
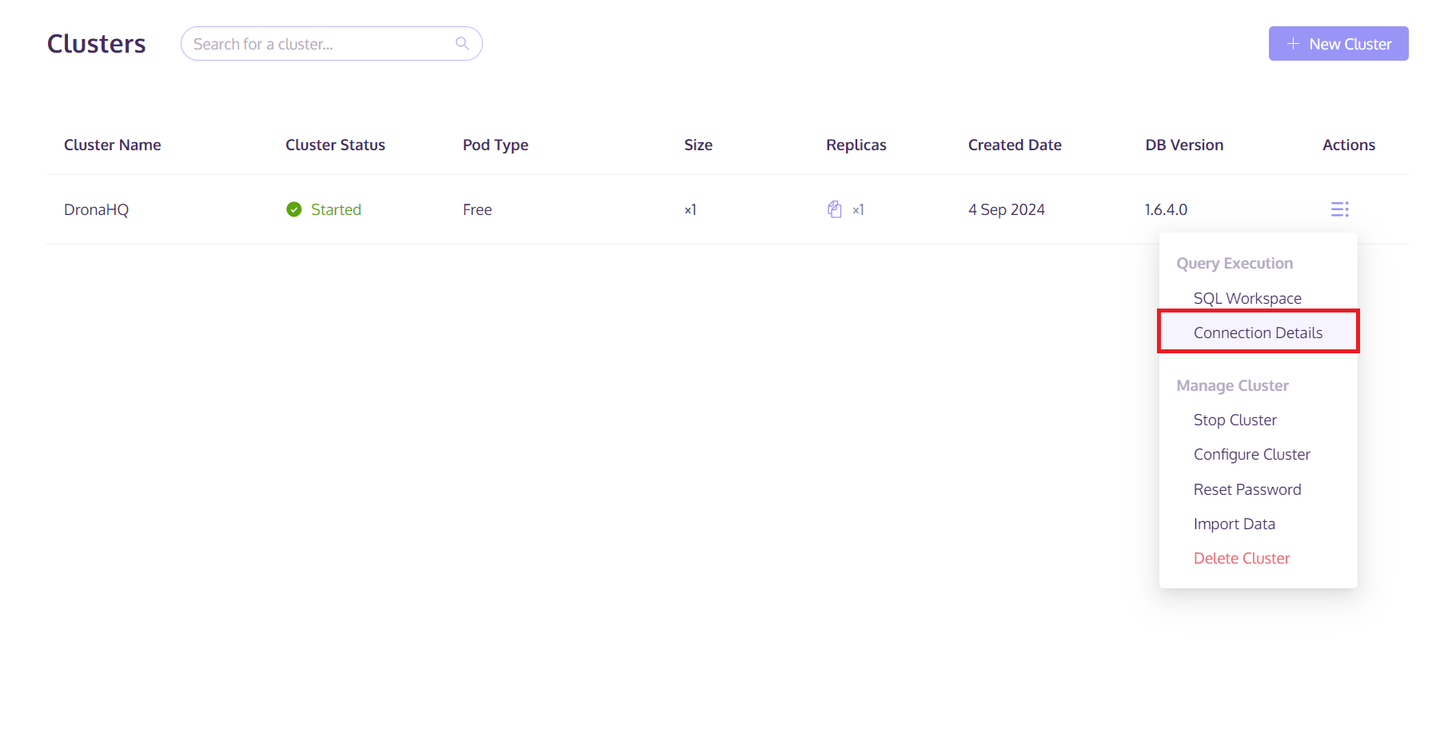
Nachdem der Cluster erstellt wurde, klicken Sie auf die Schaltfläche "Aktionen" auf der rechten Seite des Clusters. Wählen Sie dann "Verbindungsdetails" aus der Popup-Liste aus. Speichern Sie die Host/Port/Benutzername/Passwort-Informationen aus dem Tab "Python". Diese Informationen werden verwendet, um auf den MyScaleDB-Cluster zuzugreifen und die Daten zu speichern.
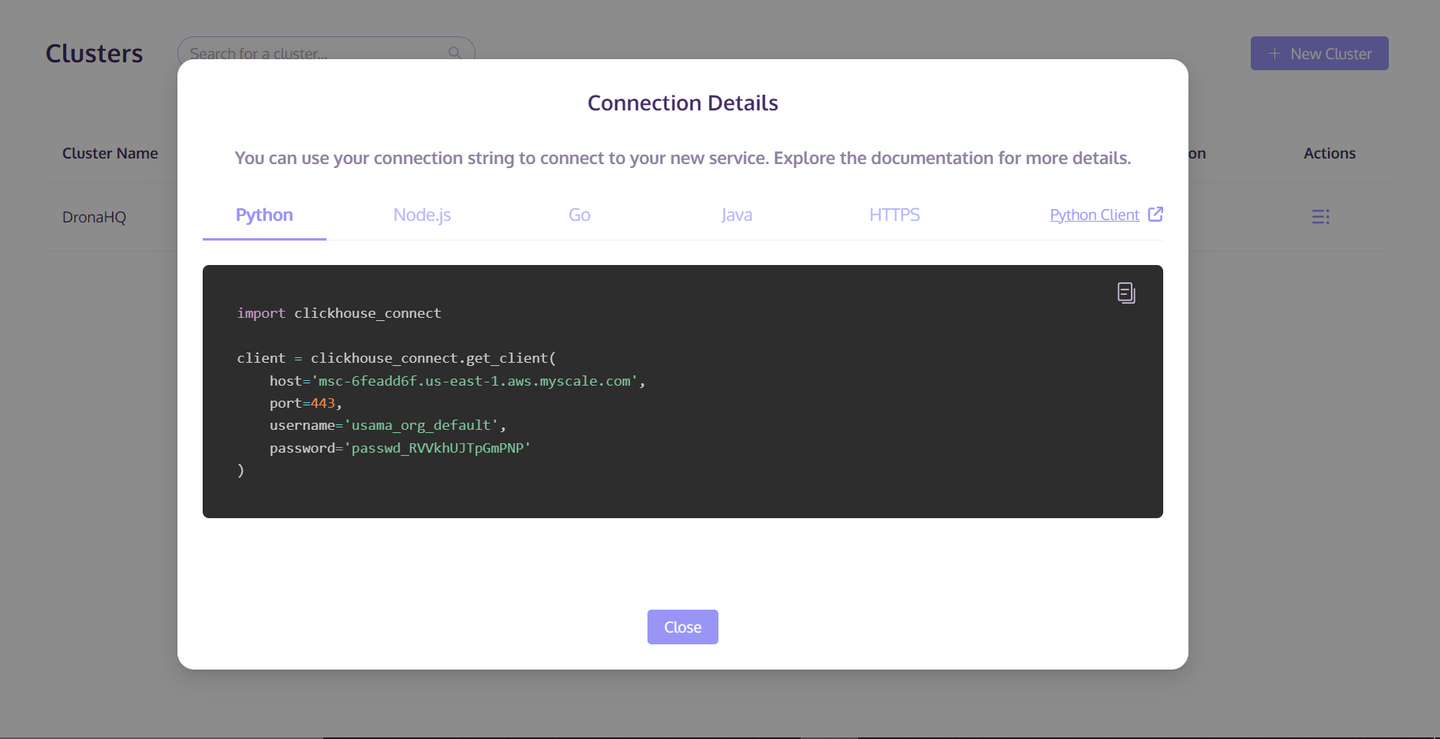
Nun, da wir alle MyScaleDB-Konfigurationen eingerichtet haben, geht es als nächstes darum, die Daten für diesen neu erstellten Cluster vorzubereiten und zu speichern.
# Daten vorbereiten und speichern
Wir verwenden synthetisch generierte Daten, die speziell auf unsere Anforderungen zugeschnitten sind und mit einem großen Sprachmodell (LLM) erstellt wurden. Sie können auf diesen Datensatz über das entsprechende GitHub-Repository (opens new window) zugreifen.
# Abhängigkeiten installieren
Zunächst müssen wir die erforderlichen Bibliotheken installieren. Entkommentieren Sie die folgende Zeile und führen Sie sie aus, um die erforderlichen Pakete zu installieren. Wenn die Bibliotheken auf Ihrem System installiert sind, können Sie diesen Schritt überspringen.
# pip install sentence-transformers clickhouse_connect
# Daten laden
Als nächstes müssen Sie die Daten, die Sie von GitHub abgerufen haben, in Ihr lokales Verzeichnis laden. Stellen Sie sicher, dass die Pfade zu Ihren Dateien korrekt angegeben sind. So können Sie die Daten laden:
import pandas as pd
# Daten aus CSV-Dateien laden
df_restaurants = pd.read_csv("restaurants.csv")
df_users = pd.read_csv("users.csv")
df_reviews = pd.read_csv("reviews.csv")
Hier haben wir drei CSV-Dateien:
restaurants.csv: Enthält Details über Restaurants wie Name, Bewertung, Küche, durchschnittlicher Preis und Standort.reviews.csv: Enthält Benutzerbewertungen, die angeben, welcher Benutzer welchem Restaurant welche Bewertung gegeben hat.users.csv: Speichert Benutzervorlieben, einschließlich bevorzugter Küche, durchschnittlicher Bewertung und durchschnittlicher Ausgaben.
# Einbettungsmodell laden
Als nächstes verwenden wir ein Einbettungsmodell von Huggingface, um Einbettungen für unsere Textdaten zu generieren. Das Modell, das wir verwenden, ist kostenlos und heißt sentence-transformers/all-MiniLM-L6-v2.
import torch
from transformers import AutoTokenizer, AutoModel
# Initialisieren des Tokenizers und Modells für Einbettungen
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
Die Methode get_embeddings nimmt eine Liste von Zeichenketten entgegen und gibt ihre Einbettungen zurück.
# Einbettungen generieren
Generieren wir nun Einbettungen für bestimmte Felder in unseren Daten – Küchentyp für Restaurants, bevorzugte Küchen für Benutzer und Bewertungen für jedes Restaurant. Diese Einbettungen sind entscheidend für die Durchführung von Ähnlichkeitssuchen später.
# Einbettungen für Küchentypen und Benutzervorlieben generieren
df_restaurants["cuisine_embeddings"] = get_embeddings(df_restaurants["cuisine"].tolist())
df_users["cuisine_preference_embeddings"] = get_embeddings(df_users["cuisine_preference"].tolist())
# Einbettungen für Bewertungen generieren
df_reviews["review_embeddings"] = get_embeddings(df_reviews["review"].tolist())
# Mit MyScaleDB verbinden
Um eine Verbindung zu Ihrem MyScaleDB-Cluster herzustellen, verwenden Sie die Verbindungsdetails, die Sie während des Cluster-Erstellungsprozesses kopiert haben. Dadurch können Sie eine Verbindung zu Ihrer MyScaleDB-Instanz herstellen.
import clickhouse_connect
# Mit MyScaleDB verbinden
client = clickhouse_connect.get_client(
host='Ihr_Host_Name_hier',
port=443,
username='Ihr_Benutzername_hier',
password='Ihr_Passwort_hier'
)
# Tabellen erstellen
Der nächste Schritt besteht darin, Tabellen in Ihrem MyScaleDB-Cluster zu erstellen, in denen Sie Ihre Daten speichern können. Basierend auf den Anforderungen Ihrer Anwendung erstellen Sie Tabellen für Benutzer, Restaurants und Bewertungen.
# Erstellen Sie die Benutzertabelle
client.command("""
CREATE TABLE default.users (
userId Int64,
cuisine_preference String,
rating_preference Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_preference_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_preference_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# Erstellen Sie die Bewertungstabelle
client.command("""
CREATE TABLE default.reviews (
userId Int64,
restaurantId Int64,
rating Float32,
review String,
review_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(review_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# Erstellen Sie die Restauranttabelle
client.command("""
CREATE TABLE default.restaurants (
restaurantId Int64,
name String,
cuisine String,
rating Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY restaurantId
""")
# Daten in Tabellen einfügen
Mit den erstellten Tabellen können Sie nun die Daten in diese Tabellen einfügen, indem Sie die Insert-Methode verwenden.
# Daten in die Benutzertabelle einfügen
client.insert("default.users", df_users.to_records(index=False).tolist(), column_names=df_users.columns.tolist())
# Daten in die Bewertungstabelle einfügen
client.insert("default.reviews", df_reviews.to_records(index=False).tolist(), column_names=df_reviews.columns.tolist())
# Daten in die Restauranttabelle einfügen
client.insert("default.restaurants", df_restaurants.to_records(index=False).tolist(), column_names=df_restaurants.columns.tolist())
# Den MSTG-Index erstellen
Schließlich erstellen Sie einen MSTG-Index für jede der Tabellen, um effiziente Suchvorgänge in Ihren Daten zu ermöglichen.
# MSTG-Index für Benutzer erstellen
client.command("""
ALTER TABLE default.users
ADD VECTOR INDEX user_index cuisine_preference_embeddings
TYPE MSTG
""")
# MSTG-Index für Restaurants erstellen
client.command("""
ALTER TABLE default.restaurants
ADD VECTOR INDEX restaurant_index cuisine_embeddings
TYPE MSTG
""")
# MSTG-Index für Bewertungen erstellen
client.command("""
ALTER TABLE default.reviews
ADD VECTOR INDEX reviews_index review_embeddings
TYPE MSTG
""")
Bis jetzt haben wir die Backend-Entwicklung unserer Anwendung abgeschlossen. Jetzt konzentrieren wir uns darauf, das Frontend mit DronaHQ zu erstellen. Schauen wir uns an, wie wir das machen können.
# App-Building mit DronaHQ
DronaHQ ist eine Low-Code-App-Entwicklungsplattform, die entwickelt wurde, um benutzerdefinierte Web- und Mobilanwendungen 10-mal schneller zu erstellen. Mit ihren leistungsstarken Bausteinen wie vorgefertigten UI-Komponenten, Datenverbindungen und Workflow-Automatisierungstools reduziert DronaHQ erheblich den Zeit- und Arbeitsaufwand für die Entwicklung und ermöglicht es Ihnen, Apps schnell zu erstellen, ohne sich mit komplexen Frontend-Frameworks auseinandersetzen zu müssen.
Egal, ob Sie ein Full-Stack-Entwickler sind, der sich auf Backend- oder Frontend-Arbeiten konzentriert, oder ob Sie gerade erst Ihre Reise als Entwickler beginnen, DronaHQ ermöglicht es Ihnen, UI-Elemente per Drag & Drop zu platzieren, eine Verbindung zu verschiedenen Datenquellen herzustellen und beeindruckende Anwendungen zu erstellen.
Erstellen wir eine funktionierende Anwendung, die Vektorsuchen in der MyScale-Datenbank durchführt und eine Empfehlungsschnittstelle für Restaurants erstellt.
# Integration von MyScale mit DronaHQ
Um MyScale mit DronaHQ zu integrieren, können Sie den ClickHouse-Connector nutzen, da MyScaleDB unter der Haube auf ClickHouse basiert. So richten Sie es ein:
- Wählen Sie den ClickHouse-Connector: Navigieren Sie in DronaHQ zum Abschnitt "Connectors" und wählen Sie den ClickHouse-Connector aus. Dies dient als Schnittstelle für die Verbindung mit MyScaleDB.

Geben Sie MyScaleDB-Anmeldeinformationen ein: Geben Sie die erforderlichen Details für Ihre MyScaleDB-Instanz ein:
- Datenbank-URL: Der Endpunkt, an dem Ihre MyScaleDB-Instanz gehostet wird.
- Benutzername und Passwort: Ihre Authentifizierungsdaten.
- Datenbankname: Setzen Sie dies auf
default, es sei denn, Ihre Konfiguration gibt eine andere Datenbank an.
Testen und Speichern: Nachdem Sie die Anmeldeinformationen eingegeben haben, klicken Sie auf "Test", um sicherzustellen, dass die Verbindung erfolgreich hergestellt wurde. Wenn der Test erfolgreich ist, speichern Sie die Konfiguration. Dadurch wird ein Connector in DronaHQ erstellt, der bereit ist, mit Ihrer MyScaleDB zu interagieren.
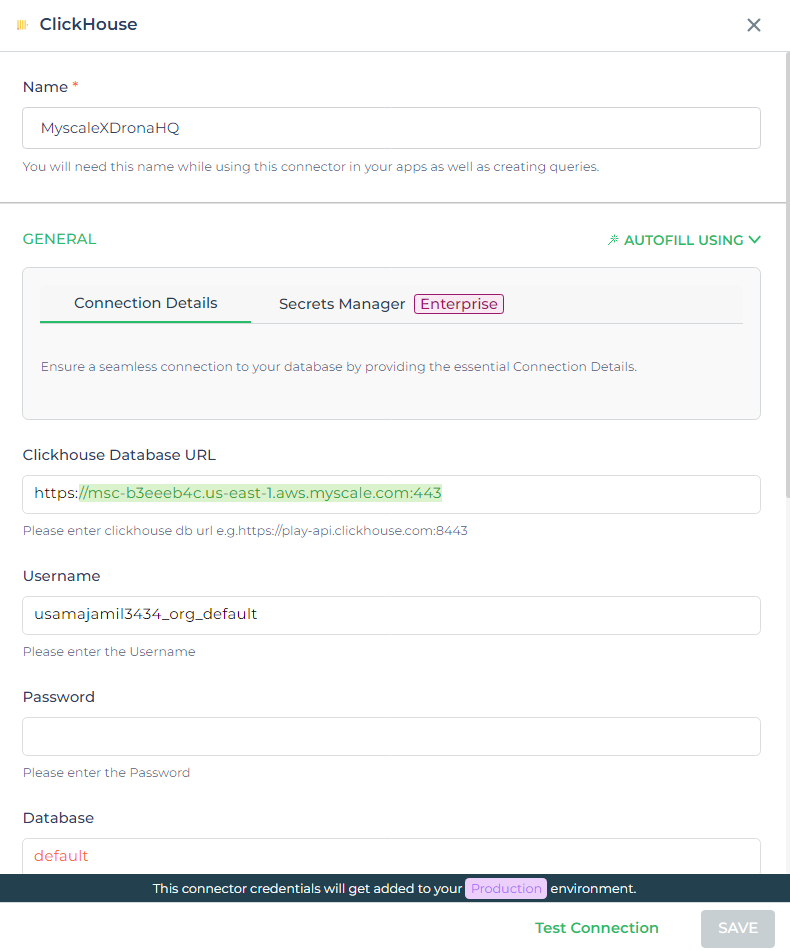
Indem Sie diesen Schritten folgen, haben Sie einen voll funktionsfähigen Connector in DronaHQ, der mit MyScaleDB kommunizieren kann und es Ihnen ermöglicht, Abfragen auszuführen, Daten abzurufen und Ihre Anwendungen mit erweiterten Datenbankfunktionen zu unterstützen.
# Schreiben von Abfragen für den Restaurant Finder
Mit dem in DronaHQ konfigurierten MyScaleDB-Connector können wir jetzt Abfragen schreiben, um Restaurantempfehlungen basierend auf Benutzereingaben abzurufen. Die Abfragen passen sich dynamisch an die bevorzugte Küche des Benutzers und den Preisbereich an.
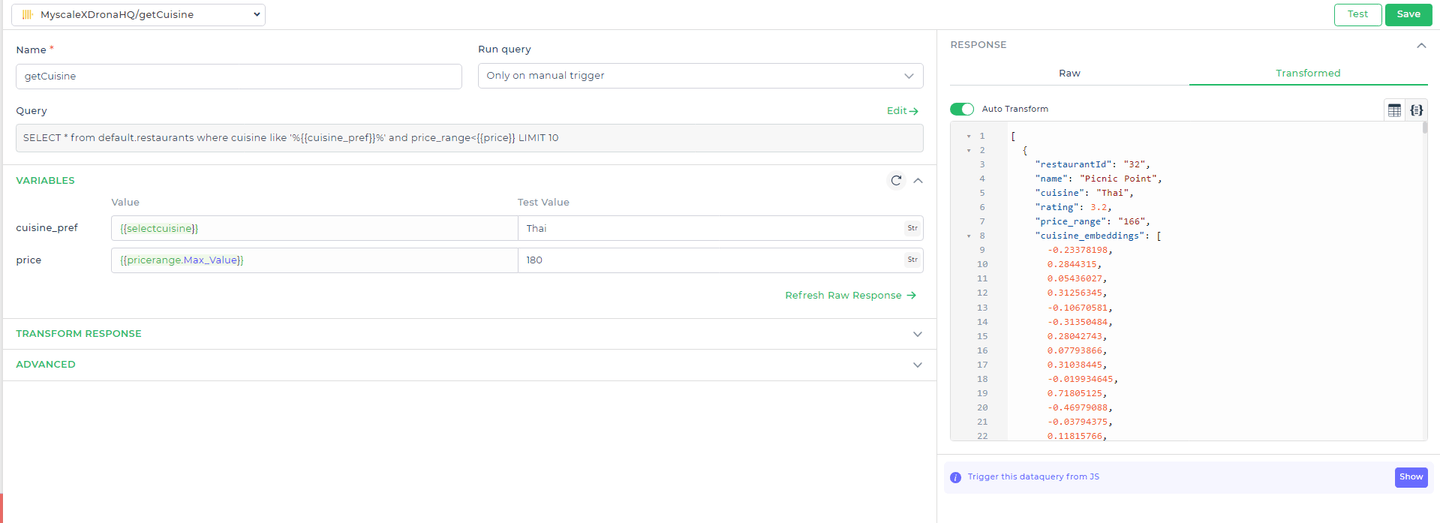
# Abfrage 1: Abrufen der anfänglichen Restaurantempfehlungen
Zunächst müssen wir eine Liste von Restaurants abrufen, die dem bevorzugten Küchentyp des Benutzers entsprechen und sich innerhalb seines angegebenen Preisbereichs befinden. Die folgende Abfrage erreicht dies:
Abfrage:
SELECT * FROM default.restaurants
WHERE cuisine LIKE '%{{cuisine_pref}}%'
AND price_range < {{price}}
LIMIT 10;
Erklärung:
default.restaurants: Bezieht sich auf die Tabelle in MyScaleDB, in der die Restaurantdaten gespeichert sind.cuisine LIKE '%{ { cuisine_pref } }%': Diese Bedingung filtert die Ergebnisse basierend auf der bevorzugten Küche des Benutzers. Der Platzhalter{ { cuisine_pref } }wird von DronaHQ dynamisch durch die tatsächliche Benutzereingabe ersetzt.price_range < { { price } }: Filtert Restaurants nach solchen, die einen Preis niedriger als das vom Benutzer angegebene Budget haben, das durch den Platzhalter{ { price } }repräsentiert wird.LIMIT 10: Begrenzt die Ergebnisse auf die ersten 10 übereinstimmenden Restaurants, um sicherzustellen, dass die Abfrage eine überschaubare Anzahl von Empfehlungen zurückgibt.
# Abfrage 2: Durchführen einer Vektorsuche für erweiterte Empfehlungen
Nachdem die anfängliche Liste der Restaurants präsentiert wurde, möchten wir eine Vektorsuche durchführen, um zusätzliche Empfehlungen basierend auf den Eigenschaften der anfänglichen Auswahl zu liefern. Dadurch kann die Anwendung Restaurants vorschlagen, die in Bezug auf das Konzept oder das Erlebnis ähnlich sind, auch wenn sie nicht genau auf Schlüsselwörter abgestimmt sind.
Abfrage:
SELECT *, distance(cuisine_embeddings, {{embedding}}) AS dist
FROM default.restaurants
ORDER BY dist
LIMIT 5;
Erklärung:
distance(cuisine_embeddings, { { embedding } }) AS dist: Dieser Ausdruck berechnet den Abstand zwischen der Vektoreinbettung der Küche jedes Restaurants und der Vektoreinbettung der bevorzugten Küche des Benutzers. Der Platzhalter{ { embedding } }repräsentiert die von DronaHQ in einen Vektor transformierte Benutzervorliebe, die dann mit den in der Datenbank gespeichertencuisine_embeddingsverglichen wird.ORDER BY dist: Die Ergebnisse werden nach dem berechneten Abstand sortiert, wobei die nächstgelegenen Übereinstimmungen (d.h. diejenigen mit dem kleinsten Abstand) zuerst angezeigt werden.LIMIT 5: Begrenzt die Ergebnisse auf die ersten 5 nächstgelegenen Übereinstimmungen, um sicherzustellen, dass die Empfehlungen hoch relevant sind.
Diese Kombination aus standardmäßiger SQL-Filterung und Vektorsuche ermöglicht es der Anwendung, sowohl präzise als auch kontextuell relevante Restaurantempfehlungen bereitzustellen und so die Benutzererfahrung zu verbessern.
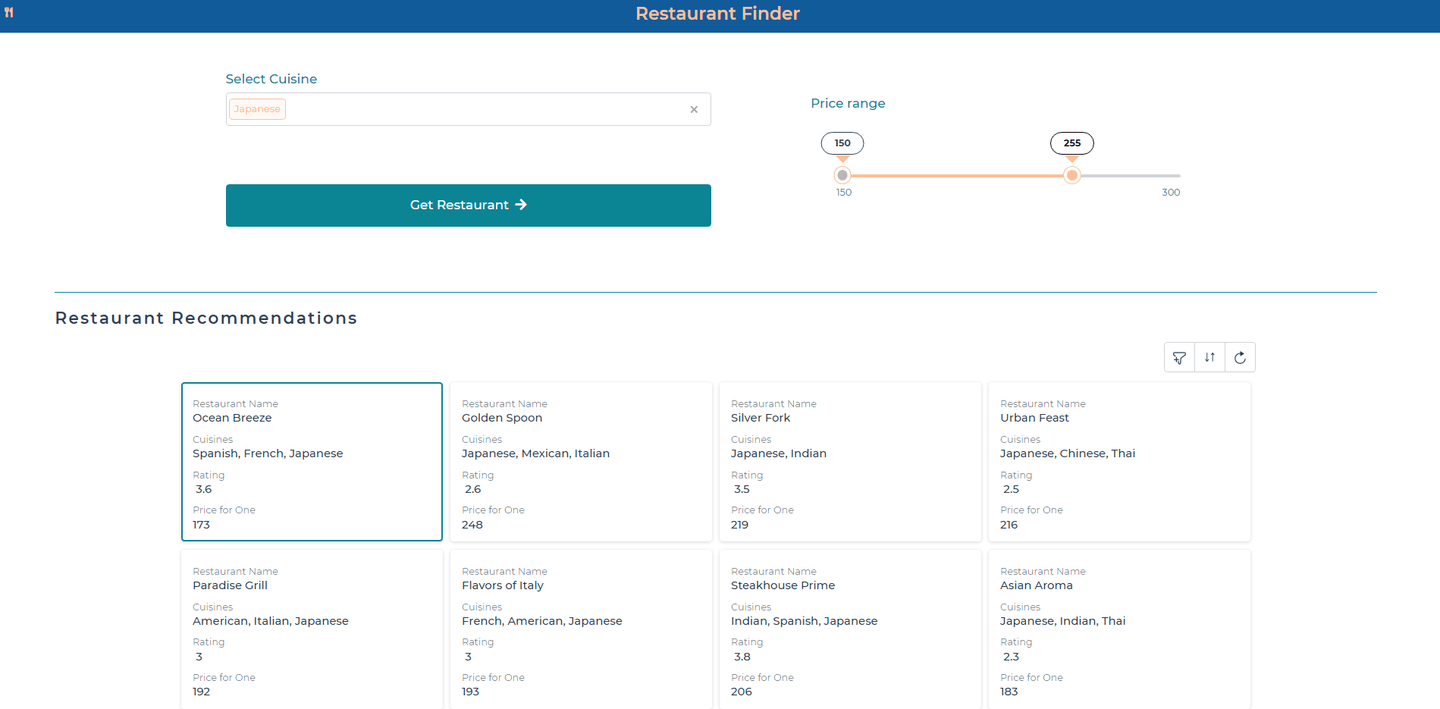
# Entwurf der Benutzeroberfläche
Bei der Gestaltung des Restaurantfinders liegt unser Hauptaugenmerk auf der Schaffung einer hochfunktionalen Benutzeroberfläche. Mit der umfangreichen Komponentenbibliothek von DronaHQ ist es möglich, dies mit minimalem Codieren zu erreichen.
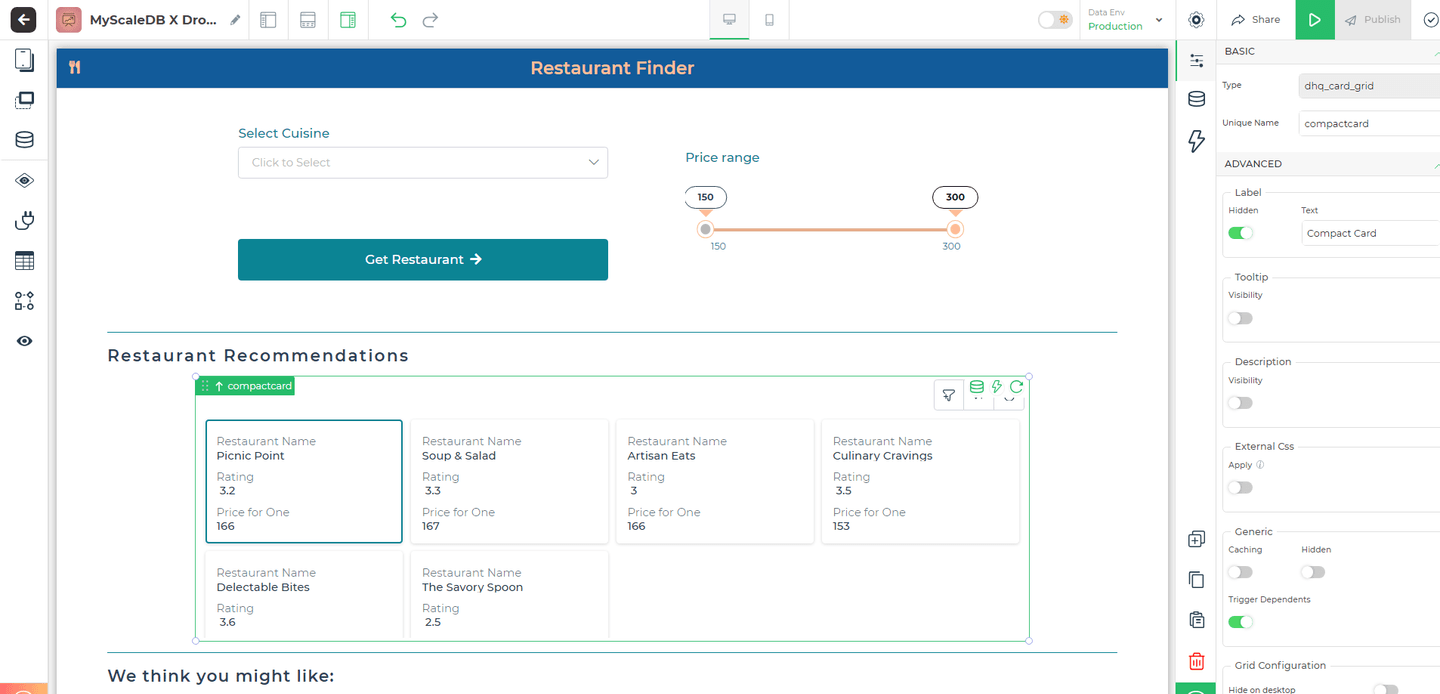
Die Anwendung beginnt damit, Benutzern die Auswahl ihrer bevorzugten Küche aus einem Dropdown-Menü und die Anpassung eines Preisschiebereglers zur Filterung von Restaurants nach Budget zu ermöglichen, wobei sofortiges Feedback zur Verfeinerung ihrer Suche gegeben wird. Empfehlungen werden in responsiven Karten angezeigt, die den Namen des Restaurants, die Bewertung und den Preis pro Mahlzeit anzeigen und mit DronaHQs Rasterlayout angeordnet sind. Um die Benutzererfahrung zu verbessern, werden Empfehlungen in die Abschnitte "Restaurantempfehlungen" und "Wir denken, Ihnen könnte auch gefallen" unterteilt, um sowohl gezielte als auch explorative Optionen anzubieten.
# Erstellen eines Aktionsflusses zur Anzeige der Ergebnisse
Mit Ihren Datenbankabfragen und der bereiten Benutzeroberfläche ist der letzte Schritt das Einrichten eines Aktionsflusses (opens new window), der diese Abfragen auslöst und die Ergebnisse in Echtzeit an Benutzer anzeigt.
Beginnen Sie damit, zur Aktionsflusskonfiguration der Schaltflächenkomponente in Ihrer Anwendung zu navigieren. Hier fügen Sie die erforderlichen Connector-Aktionen hinzu, die mit Ihren Abfragen interagieren werden.
- Verknüpfen der Abfrage mit Benutzereingaben
Wählen Sie die Abfrage aus, die entwickelt wurde, um Restaurantdetails basierend auf Benutzereingaben abzurufen. Verknüpfen Sie in der Variablen-Sektion die Eingabefelder, wie z.B. Küchentyp und Preisspanne, mit den entsprechenden Komponenten in Ihrer Benutzeroberfläche. Dadurch wird sichergestellt, dass die Abfrage die vom Benutzer bereitgestellten Daten verwendet. Nachdem Sie diese verknüpft haben, testen Sie den Aktionsfluss, um sicherzustellen, dass er korrekt funktioniert, und speichern Sie die Konfiguration.
- Verwendung von Einbettungen zur Suche nach ähnlichen Optionen Sobald die erste Abfrage erfolgreich Daten abruft, richten Sie eine weitere Connector-Aktion ein, die eine einbettungsbasierte Suche auslöst. Diese Suche verwendet die Einbettungsdaten aus dem Ergebnis der vorherigen Abfrage (speziell den Index 0 des Einbettungsarrays), um ähnliche Optionen zu finden. Dadurch wird die Relevanz der dem Benutzer angezeigten Ergebnisse verbessert.
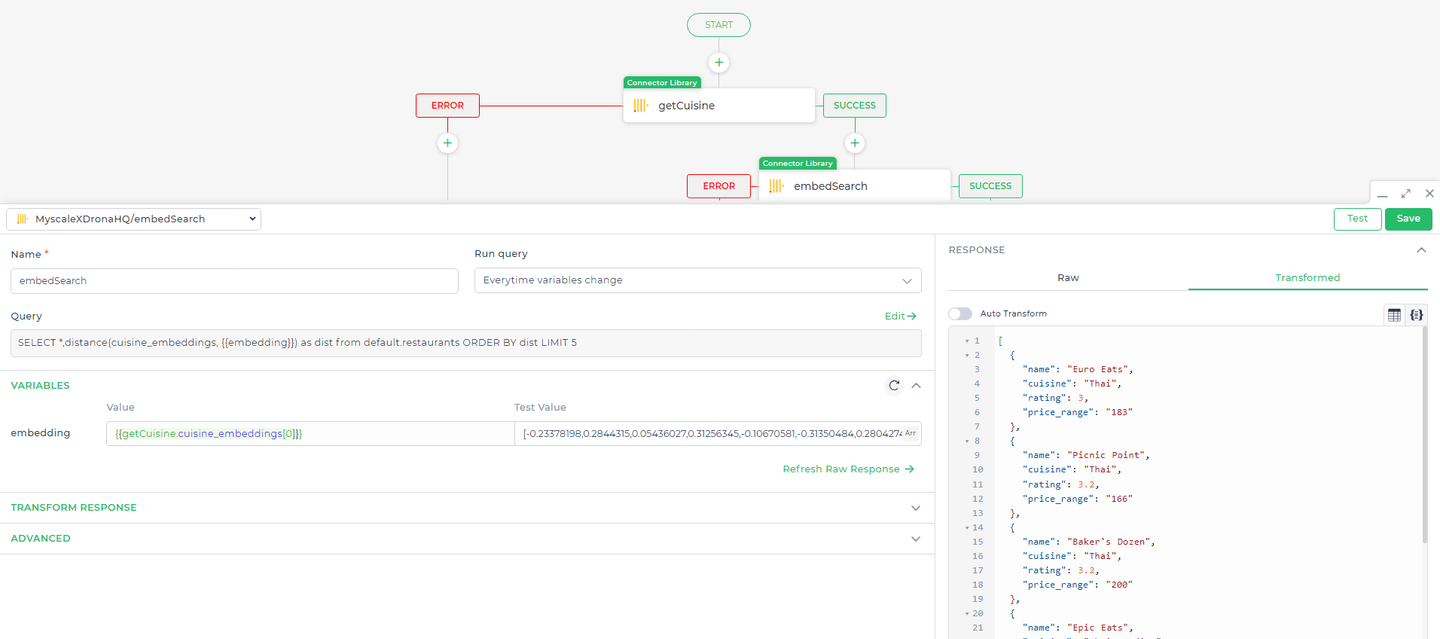
- Anzeige der Ergebnisse in der Benutzeroberfläche Der letzte Schritt besteht darin, die Steuerungswerte festzulegen. Dadurch wird sichergestellt, dass die aus Ihren Abfragen abgerufenen Daten in den Benutzeroberflächenkomponenten, wie z.B. Listen oder Karten, ordnungsgemäß angezeigt werden, mit denen die Benutzer interagieren. Durch das korrekte Festlegen der Steuerungswerte ermöglichen Sie eine dynamische Anzeige, die sich entsprechend den Benutzereingaben aktualisiert.
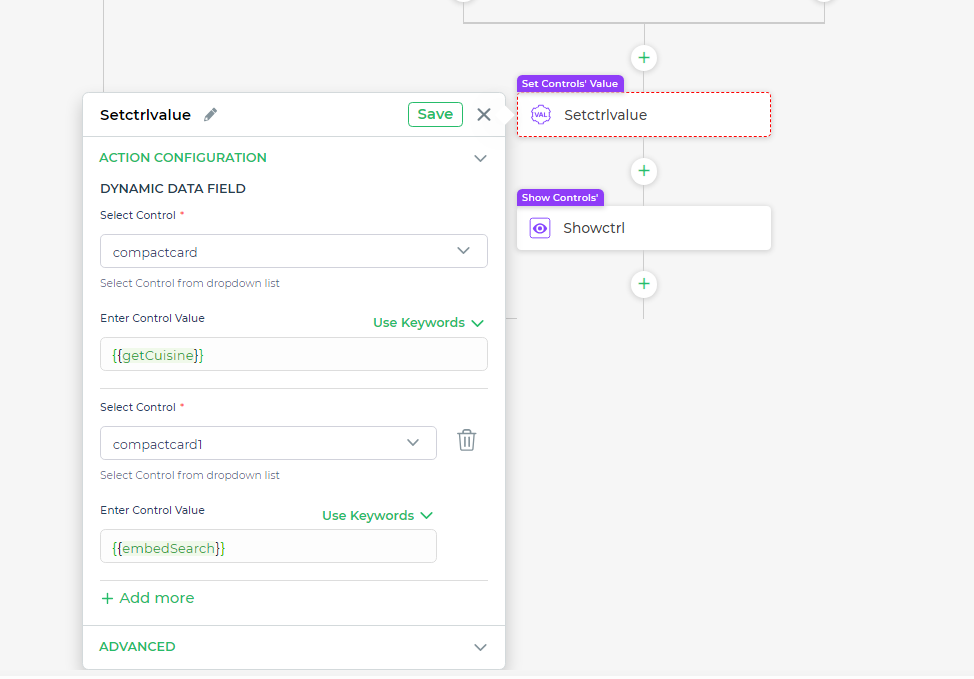

# Fazit
Durch die Kombination der Leistungsfähigkeit der Vektorsuche von MyScaleDB mit der Low-Code-Umgebung von DronaHQ haben wir einen anspruchsvollen Restaurant Finder (opens new window) erstellt, der hochpersonalisierte Empfehlungen liefert. Diese Integration ermöglicht nicht nur eine präzise Filterung basierend auf den Benutzervorlieben, sondern verbessert auch die Benutzererfahrung, indem sie ähnliche Restaurants durch fortschrittliche Einbettungstechniken vorschlägt. Das Ergebnis ist eine intelligentere und intuitivere Anwendung, die die Benutzerbindung durch die Bereitstellung relevanter und kontextbewusster Auswahlmöglichkeiten erhöht.
Über Restaurant Finder hinaus kann die Kombination von MyScaleDB und DronaHQ auf eine Vielzahl anderer Szenarien angewendet werden, wie z.B. den Aufbau intelligenter Chatbots oder sogar Beobachtungssysteme für große Sprachmodelle (LLMs). Die Flexibilität einer Vektordatenbank in Kombination mit einer Low-Code-Plattform beschleunigt die Entwicklung, ohne die für moderne KI-Anwendungen erforderliche Komplexität zu beeinträchtigen. Dies führt zu schnellerem Prototyping, Skalierbarkeit und der Möglichkeit, erweiterte Funktionen nahtlos in alltägliche Apps zu integrieren, während Entwicklungszeit gespart wird.
Der Originalartikel wurde auf DronaHQ (opens new window) veröffentlicht.



