
Dieser Artikel basiert auf der Keynote-Rede des CEO von MyScale auf der AI Conference 2023 (opens new window).
# Vektordatenbanken + LLMs sind ein Schlüsselstapel für den Aufbau von GenAI-Anwendungen
In einer Welt mit sich rasant entwickelnden KI-Technologien hat sich die Fusion von Large Language Models (LLMs) wie GPT und Vektordatenbanken als kritischer Bestandteil des Infrastruktur-Stacks herausgestellt, der zur Entwicklung von hochmodernen KI-Anwendungen verwendet wird. Diese bahnbrechende Kombination ermöglicht die Verarbeitung unstrukturierter Daten und ebnet den Weg für genauere Ergebnisse und den Echtzeitzugriff auf aktuelle Informationen. Viele Modelle wie OpenAI's GPT, Bard, Anthropic und Open-Source-Modelle wie LLaMA haben revolutioniert, wie wir Probleme lösen.
LLMs weisen jedoch erhebliche Einschränkungen auf, wenn sie für realitätsnahe Anwendungsfälle eingesetzt werden. Erstens können sie über spezifische oder aktuelle Informationen verfügen, die nicht Teil ihrer Trainingsdaten waren, was zu einem Phänomen führt, das als Halluzination oder Informationsbegrenzung bekannt ist, bei dem das Modell falsche oder seltsame Antworten generiert.
Während das Feintuning das Verhalten des LLMs anpasst, sind Vektordatenbanken entscheidend, um die Informationsbegrenzung (oder Halluzination) durch Erweiterung des Wissens des Modells zu lösen. Deshalb sind LLM + Vektordatenbanken der Schlüsselstapel für den Aufbau generativer KI-Anwendungen.
# Das Dilemma: Bequemlichkeit vs. Vektorleistung
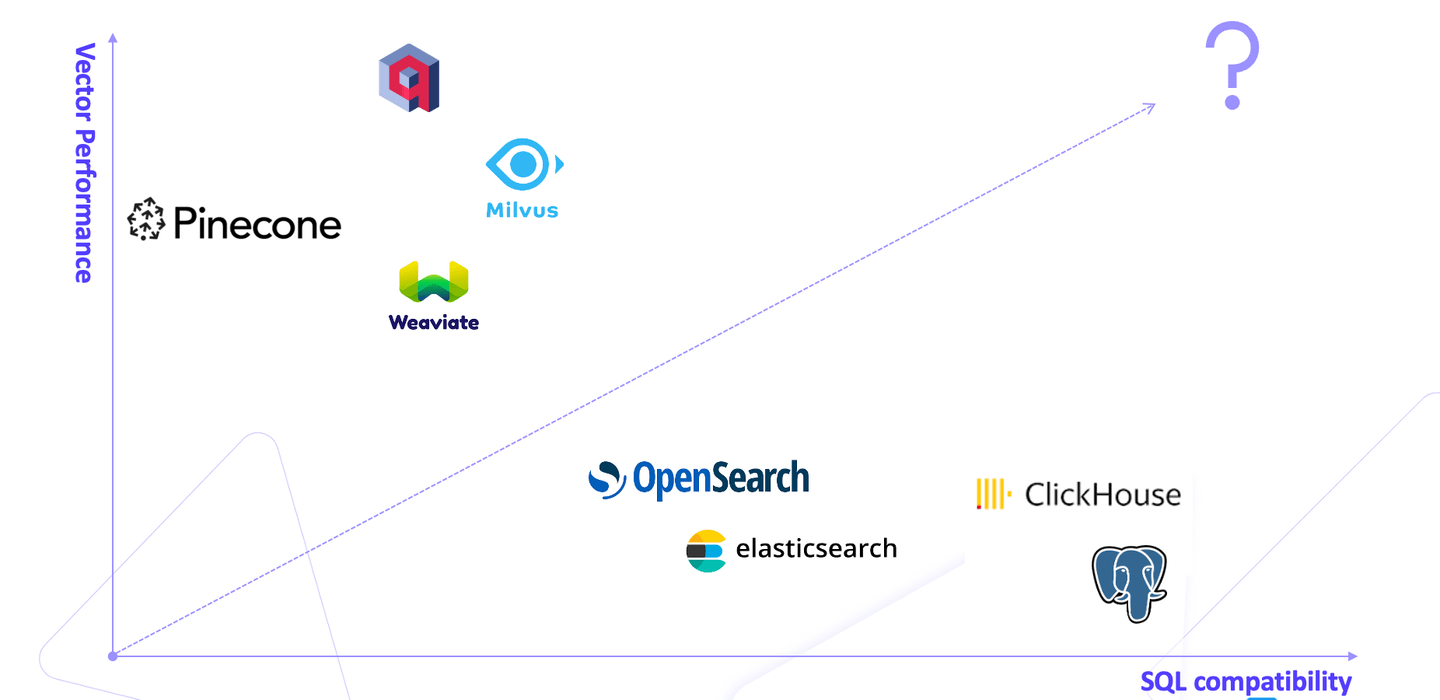
Der Markt ist voll von Vektordatenbanken, die jeweils in eine von zwei Kategorien fallen: spezialisierte Vektordatenbanken wie Pinecone, die eine hohe Vektorleistung bieten, und relationale Datenbanken wie PostgreSQL, die Bequemlichkeit bieten. Dies stürzt die Benutzer in ein Dilemma, einen Kampf zwischen der Zuverlässigkeit relationaler Datenbanken und den hochleistungsfähigen Vektoroperationen spezialisierter Datenbanken.
Stellen Sie sich vor, ein Benutzer ist auf PostgreSQL angewiesen, weil es bequem und zuverlässig ist, aber Vektorsuchen durchführen muss. Es ist jedoch umständlich und umständlich, zwischen PostgreSQL und Pinecone zu interagieren, was zu erhöhter Komplexität und potenziellen Problemen mit der Datenkonsistenz führt.
# Die ideale Lösung: MyScale - eine relationale Vektordatenbank
Hier kommt MyScale (opens new window) ins Spiel als Lösung, die die Kluft zwischen traditionellen relationalen Datenbanken und hochleistungsfähigen Vektordatenbanken überbrückt. Im Gegensatz zu proprietären Vektordatenbanken wie Milvus, Qdrant und Weaviate basiert MyScale auf der Open-Source, SQL-kompatiblen ClickHouse-Datenbank, was es Benutzern ermöglicht, Vektorsuchen mit SQL auszuführen und somit die Unannehmlichkeiten des Wechsels zwischen verschiedenen Arten von Datenbanken zu beseitigen.
Es wird allgemein angenommen, dass relationale Datenbanken keine Leistung bieten können, die mit der von Vektordatenbanken vergleichbar ist. MyScale widerlegt diesen Mythos. Es bietet eine ausgewogene, optimierte und effiziente Lösung für Benutzer, die mit einem solchen Dilemma konfrontiert sind. Es übertrifft spezialisierte Vektordatenbanken und behält dabei alle Vorteile relationaler Datenbanken bei.

Das ist erst der Anfang!
Unter der Haube integriert MyScale strukturierte Daten und Vektoren nahtlos mit einer Reihe von algorithmischen und systemtechnischen Innovationen. Im Gegensatz zu anderen Vektordatenbanken, die IVF oder HNSW als ihren Kernalgorithmus verwenden, haben wir unsere eigenen Algorithmen entwickelt. Wir helfen Benutzern, sowohl strukturierte Daten als auch Vektoreinbettungen mit sehr hoher Leistung zu vektorisieren und zu durchsuchen.
# Anwendungsfälle: Das Potenzial von MyScale ausschöpfen
Betrachten wir nun die folgenden zwei Anwendungsfälle, die die Vorteile von SQL+Vektor beschreiben:
# 1. BitCap - MyScale ermöglicht Benutzern die Ausführung komplexer Abfragen
Der erste Anwendungsfall stammt von BitCap, einem führenden Unternehmen für digitales Assetmanagement. Sie mussten Vektorsuchen durchführen und dabei nach bestimmten Datentypen filtern, z. B. Zeitstempel, über eine erhebliche Menge an Daten.
In diesem Szenario war das Datenvolumen immens, und BitCap benötigte die Möglichkeit, SQL-Syntax für ihre präzisen Filterabfragen zu verwenden. Es ist erwähnenswert, dass nicht nur die Vektorsuche, sondern auch die Filterung für viele realitätsnahe Anwendungen von entscheidender Bedeutung ist. Darüber hinaus benötigte BitCap Unterstützung für verschiedene Datentypen, einschließlich Datum und Zeichenketten, um ihre Anforderungen effektiv zu erfüllen.

Darüber hinaus hatte BitCap zusätzliche Anforderungen:
- Integration unserer Lösung mit Langchain
- Bereitstellung von Self-Queries und anderen anspruchsvollen Anwendungen
MyScale ermöglichte es ihnen, alle ihre Anforderungen in einer einzigen Abfrage zu erfüllen. Im Vergleich zu den anderen Alternativen ist MyScale für BitCap die beste Wahl, da es sehr einfach zu bedienen ist und eine hohe Leistung bietet.
# 2. MyScale hilft akademischen Benutzern, die beste Kostenwirksamkeit zu erzielen
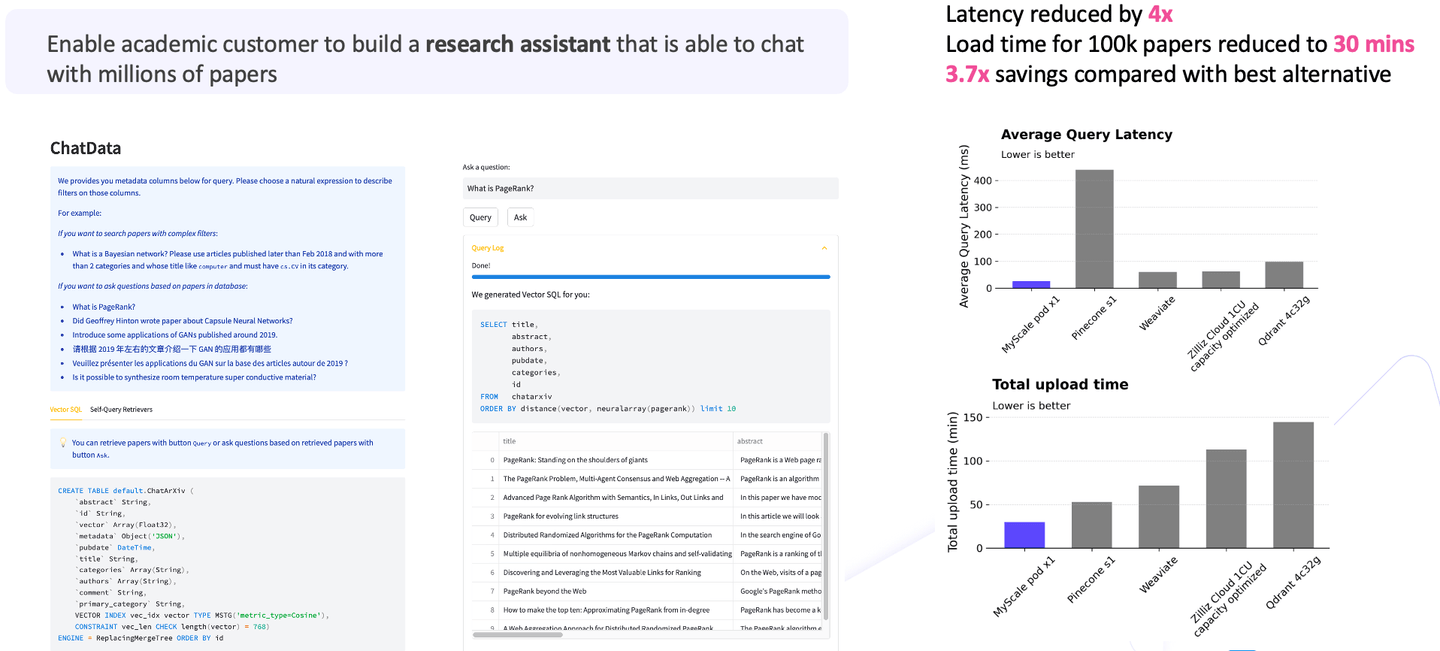
Im zweiten Anwendungsfall haben wir akademischen Benutzern geholfen, einen Forschungsassistenten zu erstellen, der mit Millionen von wissenschaftlichen Arbeiten chatten kann. Das Szenario umfasste die Aufnahme von einer Million wissenschaftlichen Arbeiten und die Aktivierung von Frage-Antwort-Fähigkeiten unter Verwendung dieser Arbeiten.
Angesichts des großen Datenvolumens, wenn Sie die Kosten vergleichen, werden Sie feststellen, dass die Large Language Models etwa achtzig bis neunzig Prozent der Gesamtkosten ausmachen. Gleichzeitig ist die Vektorsuche ein wesentlicher Bestandteil der anfänglichen Anforderungen. Wenn also die Vektorsuche in die Gleichung einbezogen wird, reduziert MyScale im Vergleich zu anderen Optionen die Latenz um das 4-fache und die Ladezeit auf 30 Minuten; insgesamt liegen die Kosteneinsparungen mehr als 3-fach über den anderen Optionen.
Wie aus dem Diagramm ersichtlich ist, bietet MyScale eine hohe Leistung, geringe Latenz und herausragende Kostenwirksamkeit. Diese Leistungen sind besonders bemerkenswert bei der Arbeit mit groß angelegten Anwendungen.
Aus diesen Anwendungsfällen wird deutlich, dass eine relationale Datenbank erforderlich ist, um diese Herausforderung effektiv anzugehen. Und die Ausstattung mit der besten Vektorfunktionalität eröffnet eine Welt voller Möglichkeiten.

# Das Potenzial für Leistungs-, Kosten- und Qualitätssteigerungen ist enorm
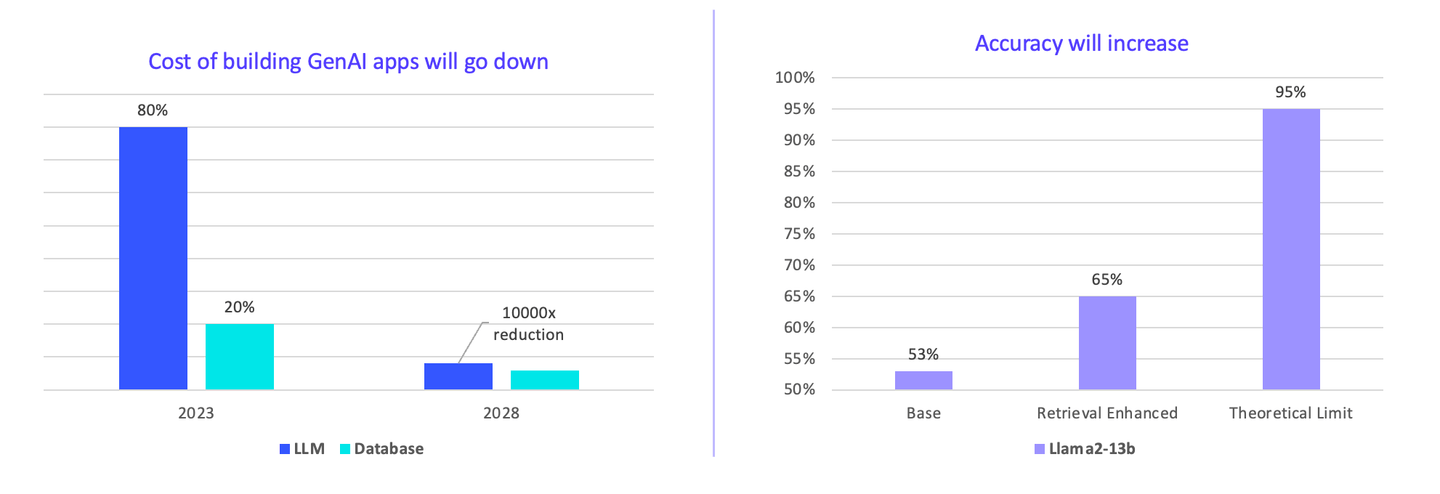
Ich denke, Unternehmen zahlen derzeit zu viel für KI. LLMs machen 80-90% der Gesamtkosten aus. In Zukunft werden die Kosten für den Aufbau von Anwendungen sinken. Wir können den Preis schneller senken, indem wir uns auf einen Konsens einigen. Es ist zu erkennen, dass es einen Raum für eine Kostenreduktion von 10000-fach gibt.
Wie ist das möglich?
- Das Hosting eigener Modelle anstelle der Verwendung kommerzialisierter APIs reduziert die Kosten um das 10-fache,
- Fortgeschrittene Caching-Systeme tragen weitere 10-fache bei,
- Andere Techniken tragen gemeinsam 100-fach bei.
Nicht jeder kennt diese Techniken.
Darüber hinaus kann die Genauigkeit der Vektorsuche erhöht werden. Derzeit ist das Basismodell Llama2, und mit einem Vektordatenbank-Plugin steigt die Genauigkeit signifikant von 53% auf 65%.
Hinweis:
Die Datenbank ist bereits im Trainingssatz enthalten, aber die Verwendung einer Vektordatenbank erhöht die Leistung erheblich.
Die theoretische Grenze ist viel höher, wenn wir größere Vektordatenbanken verwenden. Die Kosten sind viel niedriger im Vergleich zur Verwendung von GPUs allein für die Bereitstellung von LLMs. Wir glauben, dass dies eine zukünftige Richtung ist.
# Die Zukunft
Werfen wir einen Blick in die Zukunft:
SQL+Vektorrelationale Datenbanken stellen einen bahnbrechenden Ansatz zur Stärkung von GenAI-Anwendungen dar. MyScale überbrückt die Kluft zwischen relationalen und Vektordatenbanken, bietet sowohl Bequemlichkeit als auch hohe Leistungsfähigkeit und zeigt, dass relationale Datenbanken spezialisierte Datenbanken in Bezug auf Vektorleistung übertreffen können, während sie alle Vorteile von SQL beibehalten. Indem sie Möglichkeiten neu definiert und Kosten senkt, ebnet MyScale den Weg für eine Zukunft, in der KI-Anwendungen zugänglicher und leistungsstärker sind als je zuvor. Und es gibt einen großen Raum für Kostenreduktion und Genauigkeitsverbesserung, was die Richtung ist, in die wir gehen. Wenn Sie weitere Fragen haben oder an unserem Angebot interessiert sind, zögern Sie nicht, uns über Discord (opens new window) zu kontaktieren oder MyScale auf Twitter (opens new window) zu folgen.
Vielen Dank!




