
Die abrufgestützte Generierung (RAG) (opens new window) hat die Art und Weise, wie wir mit Daten interagieren, revolutioniert und bietet eine unübertroffene Leistung bei Ähnlichkeitssuchen. Es zeichnet sich durch die Abfrage relevanter Informationen anhand einfacher Abfragen aus. RAG stößt jedoch oft an seine Grenzen, wenn es um komplexere Aufgaben wie zeitbasierte Abfragen oder komplexe relationale Datenbankabfragen geht. Dies liegt daran, dass RAG hauptsächlich für die erweiterte Textgenerierung mit relevanten Informationen aus externen Quellen entwickelt wurde und nicht für exakte, bedingungsbasierte Abfragen. Diese Einschränkungen beschränken seine Anwendung in Szenarien, die eine präzise und bedingte Datenabfrage erfordern.
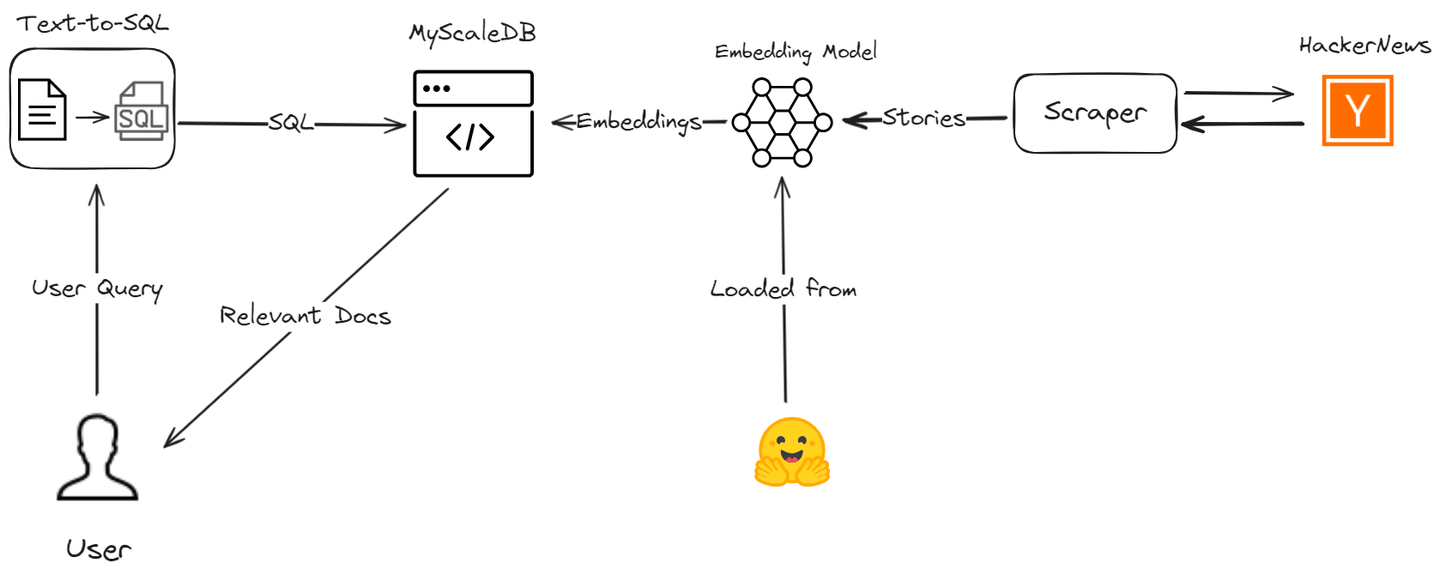
Unser fortgeschrittenes RAG-Modell, das auf einer SQL-Vektordatenbank basiert, verwaltet effizient verschiedene Abfragetypen. Es handhabt nicht nur einfache Ähnlichkeitssuchen, sondern ist auch in zeitbasierten Abfragen und komplexen relationalen Abfragen herausragend.
Lassen Sie uns besprechen, wie wir diese RAG-Einschränkungen überwinden, indem wir einen KI-Assistenten erstellen, der MyScale und LangChain verwendet, um die Genauigkeit und Effizienz des Datenabrufprozesses zu verbessern. Wir werden die neuesten Geschichten von Hacker News abrufen und Sie durch den Prozess führen, um zu demonstrieren, wie Ihre RAG-Anwendung mit fortgeschrittenen SQL-Vektorabfragen verbessert werden kann.
# Werkzeuge und Technologien
Wir werden mehrere Werkzeuge verwenden, darunter MyScaleDB, OpenAI, LangChain, Hugging Face und die HackerNews-API, um diese nützliche Anwendung zu entwickeln.
- MyScaleDB (opens new window): MyScale ist eine SQL-Vektordatenbank, die strukturierte und unstrukturierte Daten effizient speichert und verarbeitet.
- OpenAI (opens new window): Wir werden das Chat-Modell von OpenAI verwenden, um Text in SQL-Abfragen zu generieren.
- LangChain: LangChain hilft beim Aufbau des Workflows und integriert sich nahtlos in MyScale und OpenAI.
- Hugging Face (opens new window): Wir werden das Einbettungsmodell von Hugging Face verwenden, um Texteinbettungen zu erhalten, die in MyScale für weitere Analysen gespeichert werden.
- HackerNews (opens new window) API: Diese API ruft Echtzeitdaten von HackerNews ab, um sie zu verarbeiten und zu analysieren.
# Vorbereitung
# Einrichten der Umgebung
Bevor wir mit dem Schreiben des Codes beginnen, müssen wir sicherstellen, dass alle erforderlichen Bibliotheken und Abhängigkeiten installiert sind. Sie können diese mit pip installieren:
pip install requests clickhouse-connect transformers openai langchain
Dieser pip-Befehl sollte alle für dieses Projekt erforderlichen Abhängigkeiten installieren.
# Bibliotheken importieren und Hilfsfunktionen definieren
Zuerst importieren wir die erforderlichen Bibliotheken und definieren die Hilfsfunktionen, die zum Abrufen und Verarbeiten von Daten von Hacker News verwendet werden.
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# Story-IDs von einem bestimmten Endpunkt abrufen
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# Details eines bestimmten Elements nach ID abrufen
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# Rekursiv Kommentare für eine Geschichte abrufen
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[gelöscht]')
comment_by = comment_details.get('by', 'Anonym')
einzug = ' ' * depth * 2
comments.append(f"{einzug}Kommentar von {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# Liste von Kommentaren in einen einzelnen String umwandeln
def create_comment_string(comments):
return ' '.join(comments)
# Zeitlimit auf 12 Stunden vorher festlegen
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())
Diese Funktionen rufen Story-IDs ab, holen Details zu bestimmten Elementen, rufen Kommentare rekursiv ab und wandeln eine Liste von Kommentaren in einen einzelnen String um.
# Geschichten abrufen und verarbeiten
Als nächstes rufen wir die neuesten und besten Geschichten von Hacker News ab und verarbeiten sie, um relevante Daten zu extrahieren.
# Neueste und beste Geschichten abrufen
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# Die 20 besten Geschichten abrufen
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# Alle neuesten Geschichten der letzten 12 Stunden abrufen
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# Daten für DataFrame vorbereiten
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Titel': story.get('title', 'Kein Titel'),
'URL': story.get('url', 'Keine URL'),
'Punktzahl': story.get('score', 0),
'Zeit': convert_unix_to_datetime(story.get('time', 0)),
'Verfasser': story.get('by', 'Anonym'),
'Kommentare': story.get('descendants', 0) # Anzahl der Kommentare korrekt behandeln
}
# Kommentare abrufen, falls vorhanden
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Kommentar_String'] = create_comment_string(comments)
else:
story_data['Kommentar_String'] = ""
data.append(story_data)
# Neueste und beste Geschichten verarbeiten
process_stories(latest_stories)
process_stories(top_stories)
# DataFrame erstellen
df = pd.DataFrame(data)
# Richtige Datentypen sicherstellen
df['Punktzahl'] = df['Punktzahl'].astype(np.uint64)
df['Kommentare'] = df['Kommentare'].astype(np.uint64)
df['Zeit'] = pd.to_datetime(df['Zeit'])
Wir rufen die neuesten und besten Geschichten von Hacker News mithilfe der oben definierten Hilfsfunktionen ab. Wir verarbeiten die abgerufenen Geschichten, um relevante Informationen wie Titel, URL, Punktzahl, Zeit, Verfasser und Kommentare zu extrahieren. Wir wandeln auch die Liste der Kommentare in einen einzelnen String um.
# Initialisieren des Hugging Face-Modells für Einbettungen
Wir generieren jetzt Einbettungen für die Titel und Kommentare der Geschichten mithilfe eines vortrainierten Modells. Dieser Schritt ist entscheidend für die Erstellung eines abrufgestützten Generierungssystems (RAG).
import torch
from transformers import AutoTokenizer, AutoModel
# Tokenizer und Modell für Einbettungen initialisieren
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Einbettungen generieren, nachdem das DataFrame erstellt wurde
empty_embedding = np.zeros(384, dtype=np.float32) # Annahme: Einbettungsgröße beträgt 384
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()
Wir laden ein vortrainiertes Modell für die Generierung von Einbettungen mithilfe der Hugging Face transformers-Bibliothek und generieren Einbettungen für die Titel und Kommentare der Geschichten.
# Umgang mit langen Kommentaren
Um mit langen Kommentaren umzugehen, die die maximale Tokenlänge des Modells überschreiten, teilen wir sie in handhabbare Teile auf.
# Funktion zum Umgang mit langen Kommentaren
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts
Diese Funktion teilt lange Kommentare in Teile auf, die in die maximale Tokenlänge des Modells passen.
# Geschichten für Einbettungen verarbeiten
Schließlich verarbeiten wir jede Geschichte, um Einbettungen für Titel und Kommentare zu generieren und erstellen ein endgültiges DataFrame.
# Jede Geschichte für Einbettungen verarbeiten
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Titel']]).tolist()
comments_string = story['Kommentar_String']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # Verwenden Sie die maximale Tokenlänge des Modells
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Titel': story['Titel'],
'URL': story['URL'],
'Punktzahl': story['Punktzahl'],
'Zeit': story['Zeit'],
'Verfasser': story['Verfasser'],
'Kommentare': story['Kommentare'],
'Kommentar_String': part_comments_string,
'Titel_Einbettung': title_embedding,
'Kommentar_Einbettung': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Titel': story['Titel'],
'URL': story['URL'],
'Punktzahl': story['Punktzahl'],
'Zeit': story['Zeit'],
'Verfasser': story['Verfasser'],
'Kommentare': story['Kommentare'],
'Kommentar_String': comments_string,
'Titel_Einbettung': title_embedding,
'Kommentar_Einbettung': comments_embeddings
})
else:
story['Titel_Einbettung'] = title_embedding
story['Kommentar_Einbettung'] = empty_embedding.tolist()
final_data.append(story)
# Endgültiges DataFrame erstellen
final_df = pd.DataFrame(final_data)
# Richtige Datentypen im endgültigen DataFrame sicherstellen
final_df['Punktzahl'] = final_df['Punktzahl'].astype(np.uint64)
final_df['Kommentare'] = final_df['Kommentare'].astype(np.uint64)
final_df['Zeit'] = pd.to_datetime(final_df['Zeit'])
In diesem Schritt verarbeiten wir jede Geschichte, um Einbettungen für Titel und Kommentare zu generieren, lange Kommentare gegebenenfalls zu handhaben und ein endgültiges DataFrame mit allen verarbeiteten Daten zu erstellen.
# Verbindung zu MyScaleDB herstellen und Tabelle erstellen
MyScaleDB ist eine fortschrittliche SQL-Vektordatenbank, die RAG-Modelle durch effiziente Handhabung komplexer Abfragen (opens new window) und Ähnlichkeitssuchen wie Volltextsuche (opens new window) und gefilterte Vektorabfrage (opens new window) verbessert.
Wir stellen eine Verbindung zu MyScaleDB mit clickhouse-connect her und erstellen eine Tabelle, um die abgerufenen Geschichten zu speichern.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='dein-host',
port=443,
username='dein-benutzername',
password='dein-passwort'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Titel String,
URL String,
Punktzahl UInt64,
Zeit DateTime64,
Verfasser String,
Kommentare UInt64,
Titel_Einbettung Array(Float32),
Kommentar_Einbettung Array(Float32),
CONSTRAINT check_data_length CHECK length(Titel_Einbettung) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
Dieser Code importiert die clickhouse-connect-Bibliothek und stellt eine Verbindung zu MyScaleDB mit den angegebenen Anmeldeinformationen her. Wenn die Tabelle default.posts bereits vorhanden ist, wird sie gelöscht und eine neue Tabelle mit dem angegebenen Schema erstellt.
Hinweis: MyScaleDB bietet einen kostenlosen Pod für die Vektorspeicherung von 5 Millionen Vektoren. Sie können also MyScaleDB in Ihrer RAG-Anwendung ohne anfängliche Zahlungen verwenden.
# Daten einfügen und einen Vektorindex erstellen
Jetzt fügen wir die verarbeiteten Daten in die MyScaleDB-Tabelle ein und erstellen einen Index, um einen effizienten Abruf der Daten zu ermöglichen.
batch_size = 20 # Je nach Bedarf anpassen
num_batches = len(final_df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = final_df[start_idx:end_idx]
client.insert("default.posts", batch_data, column_names=['Titel', 'URL', 'Punktzahl', "Zeit",'Verfasser', 'Kommentare','Titel_Einbettung','Kommentar_Einbettung'])
print(f"Batch {i+1}/{num_batches} eingefügt.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Titel_Einbettung
TYPE MSTG
('metric_type=Cosine')
""")
Dieser Code fügt die Daten in die Tabelle default.posts in Chargen ein, um große Datenmengen effizient zu verarbeiten. Der Vektorindex wird auf der Spalte Titel_Einbettung erstellt.
# Einrichten der Vorlagenabfrage für die Abfragegenerierung
Wir richten eine Vorlagenabfrage ein, um natürlichsprachliche Abfragen in MyScaleDB-SQL-Abfragen umzuwandeln.
prompt_template = """
Sie sind ein MyScaleDB-Experte. Geben Sie eine syntaktisch korrekte MyScaleDB-Abfrage ein, um sie auszuführen, und sehen Sie sich dann die Ergebnisse der Abfrage an, um die Antwort auf die Eingabeaufforderung zurückzugeben.
MyScaleDB-Abfragen verfügen über eine Vektorabstandsfunktion namens `DISTANCE(column, array)`, um die Relevanz zur Frage des Benutzers zu berechnen und die Feature-Array-Spalte nach Relevanz zu sortieren. Die Funktion `DISTANCE(column, array)` akzeptiert nur eine Array-Spalte als ersten Argument und eine `Embeddings(entity)` als zweites Argument. Sie benötigen auch eine benutzerdefinierte Funktion namens `Embeddings(entity)`, um das Array der Entität abzurufen.
Wenn die Abfrage nach den nächstgelegenen Zeilen basierend auf einem bestimmten Schlüsselwort fragt (z. B. "KI-Bereich" oder "kritisiert"), müssen Sie diese Distanzfunktion verwenden, um die Distanz zum Array der Entität in der Vektorspalte zu berechnen und nach der Distanz zu sortieren, um relevante Zeilen abzurufen. Wenn die Frage zeitliche Einschränkungen enthält (z. B. "letzte 7 Stunden"), verwenden Sie die Funktion `today()`, um das aktuelle Datum und die aktuelle Uhrzeit zu erhalten.
Wenn die Frage die Anzahl der zu erhaltenden Beispiele angibt, verwenden Sie diese Zahl. Andernfalls fragen Sie höchstens {top_k} Ergebnisse mit der LIMIT-Klausel ab, wie es MyScale vorgibt. Sortieren Sie nur nach der Distanzfunktion, wenn dies erforderlich ist. Fragen Sie niemals alle Spalten aus einer Tabelle ab. Fragen Sie nur die für die Beantwortung der Frage erforderlichen Spalten ab und umschließen Sie jeden Spaltennamen in doppelten Anführungszeichen (") als begrenzte Bezeichner.
Achten Sie darauf, nur die in den unten aufgeführten Tabellen vorhandenen Spaltennamen zu verwenden und stellen Sie sicher, dass Sie wissen, welche Spalte zu welcher Tabelle gehört. Die `ORDER BY`-Klausel sollte immer nach der `WHERE`-Klausel stehen. Fügen Sie kein Semikolon am Ende des SQL hinzu.
Beachten Sie die folgenden Schritte beim Erstellen der Abfrage:
1. Identifizieren Sie Schlüsselwörter in der Eingabeaufforderung (z. B. "meist gevotete Artikel", "letzte 7 Stunden", "KI-Bereich").
2. Ordnen Sie Schlüsselwörter bestimmten Abfrageteilen zu (z. B. "meist gevotet" wird zu "Punktzahl DESC").
3. Wenn die Frage die Relevanz zu einem Schlüsselwort betrifft (z. B. "kritisiert"), verwenden Sie die Distanzfunktion. Andernfalls verwenden Sie Standard-SQL-Klauseln.
4. Wenn die Frage explizit den Titel oder die Kommentare erwähnt, berechnen Sie die Distanz entsprechend. Berechnen Sie standardmäßig die Distanz mit dem Titel.
5. Verwenden Sie `Embeddings(keyword)`, um Einbettungen für Schlüsselwörter abzurufen, und verwenden Sie sie in der `DISTANCE`-Funktion nur dann, wenn die Abfrage eine Schlüsselwortrelevanzsuche beinhaltet.
6. Achten Sie darauf, die Kommentarspalte zu berücksichtigen, wenn sie in der Frage explizit erwähnt wird.
7. Verwenden Sie dist nicht in einer Abfrage, in der Sie keine Distanz gefunden haben, und stellen Sie sicher, dass Sie bei anderen Spalten, bei denen die Distanz berechnet wird, nach dist sortieren.
Beispielhafte Fragen und deren Bearbeitung:
1. "Was sind die meist gevoteten Artikel der letzten 7 Stunden im KI-Bereich?"
- Extrahieren Sie Schlüsselwörter: "meist gevotete Artikel", "letzte 7 Stunden", "KI-Bereich".
- Ordnen Sie "meist gevotet" "Punktzahl DESC" zu.
- Erstellen Sie eine Abfrage für die meist gevoteten Artikel der letzten 7 Stunden:
- `SELECT DISTINCT "Titel", "URL", "Punktzahl", DISTANCE("Titel_Einbettung", Embeddings('KI-Bereich')) FROM posts1 WHERE Zeit >= today() - INTERVAL 7 HOUR ORDER BY Punktzahl DESC LIMIT {top_k}`
2. "Geben Sie mir einige Kommentare, in denen die Leute den Inhalt kritisieren."
- Extrahieren Sie Schlüsselwörter: "Kommentare", "kritisiert".
- Ordnen Sie "kritisiert" der DISTANCE-Funktion zu.
- Erstellen Sie eine Abfrage für relevante Kommentare:
- `SELECT DISTINCT "Kommentare", "Punktzahl", DISTANCE("Kommentar_Einbettung", Embeddings('kritisiert')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. "Was waren die meist gevoteten Geschichten der letzten 6 Stunden?"
- Extrahieren Sie Schlüsselwörter: "meist gevotete Geschichten", "letzte 6 Stunden".
- Ordnen Sie "meist gevotet" "Punktzahl DESC" zu.
- Erstellen Sie eine einfache Abfrage für die meist gevoteten Geschichten der letzten 6 Stunden:
- `SELECT DISTINCT "Titel", "URL", "Punktzahl" FROM posts1 WHERE Zeit >= today() - INTERVAL 6 HOUR ORDER BY Punktzahl DESC LIMIT {top_k}`
4. "Was sind die aktuellen Trends im KI-Bereich?"
- Extrahieren Sie Schlüsselwörter: "Trends", "KI-Bereich".
- Ordnen Sie "Trends" "Punktzahl DESC" zu.
- Erstellen Sie eine Abfrage für die aktuellen Trends im KI-Bereich:
- `SELECT DISTINCT "Titel", "URL", "Punktzahl", DISTANCE("Titel_Einbettung", Embeddings('KI-Bereich')) as dist FROM posts1 ORDER BY dist, Punktzahl DESC LIMIT {top_k}`
5. "Geben Sie mir einige Kommentare, in denen über die neuesten Trends von LLMs diskutiert wird."
- Extrahieren Sie Schlüsselwörter: "Kommentare", "neueste Trends von LLMs".
- Ordnen Sie "neueste Trends von LLMs" der DISTANCE-Funktion zu.
- Erstellen Sie eine Abfrage für Kommentare, die über die neuesten Trends von LLMs diskutieren:
- `SELECT DISTINCT "Kommentare", "Punktzahl", DISTANCE("Kommentar_Einbettung", Embeddings('neueste Trends von LLMs')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
Nun erstellen wir die Abfrage basierend auf der bereitgestellten Eingabe.
======== Tabelleninformationen ========
{table_info}
Frage: {input}
SQL-Abfrage: "
Entfernen Sie \n,\, " oder irgendeinen überflüssigen Buchstaben aus der Abfrage und achten Sie darauf, keine Spalten abzufragen, die nicht vorhanden sind.
"""
def generate_final_prompt(input, table_info, top_k=5):
final_prompt = prompt_template.format(input=input, table_info=table_info, top_k=top_k)
return final_prompt
Dieser Code richtet eine Vorlagenabfrage ein, die das LLM dabei unterstützt, korrekte MyScaleDB-Abfragen basierend auf den Eingabeaufforderungen zu generieren.
# Festlegen der Abfrageparameter
Wir legen die Parameter für die Abfragegenerierung fest.
top_k = 5
table_info = """
posts1 (
id UInt64,
Titel String,
URL String,
Punktzahl UInt64,
Zeit DateTime64,
Verfasser String,
Kommentare UInt64,
Titel_Einbettung Array(Float32),
Kommentar_Einbettung Array(Float32)
)
"""
Dieser Code legt die Anzahl der zu erhaltenden Top-Ergebnisse (top_k) fest, definiert die Tabelleninformationen (table_info) und legt einen leeren Eingabestring (input) für die Frage fest.
# Einrichten des Modells
In diesem Schritt richten wir das OpenAI-Modell ein, um Benutzereingaben in SQL-Abfragen umzuwandeln.
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(openai_api_key="open-ai-api-key")
# Text in SQL umwandeln
Diese Methode generiert zunächst eine endgültige Eingabeaufforderung basierend auf der Benutzereingabe und den Tabelleninformationen und verwendet dann das OpenAI-Modell, um den Text in eine SQL-Vektorabfrage umzuwandeln.
def get_query(user_input):
final_prompt = generate_final_prompt(user_input, table_info, top_k)
response_text = model.predict(final_prompt)
return response_text
user_input="Was sind die meist gevoteten Geschichten?"
response=get_query(user_input)
Nach diesem Schritt erhalten wir eine Abfrage wie diese:
'SELECT DISTINCT "Titel", "URL", "Punktzahl", DISTANCE("Titel_Einbettung", Embeddings(\'KI-Bereich\')) as dist FROM posts1 ORDER BY dist, Punktzahl DESC LIMIT 5'
Aber MyScaleDB DISTANCE erwartet DISTANCE(Spalte, Array) . Daher müssen wir den Teil Embeddings(\'KI-Bereich\') in Vektoreinbettungen umwandeln.
# Einbettungen in einer Abfragezeichenkette verarbeiten und ersetzen
Diese Methode wird verwendet, um Embeddings("Extrahierte Schlüsselwörter") durch ein Array von float32 zu ersetzen.
import re
def process_query(query):
pattern = re.compile(r'Embeddings\(([^)]+)\)')
matches = pattern.findall(query)
for match in matches:
processed_embedding = str(list(generate_embeddings(match)))
query = query.replace(f'Embeddings({match})', processed_embedding)
return query
query=process_query1(f"""{response}""")
Diese Methode nimmt die Abfrage als input und gibt die aktualisierte Abfrage zurück, wenn in der Abfragezeichenkette eine Embeddings-Methode vorhanden ist.

# Eine Abfrage ausführen
Schließlich führen wir eine Abfrage aus, um die relevanten Geschichten aus der Vektordatenbank abzurufen.
query=query.replace("\n","")
results = client.query(f"""{query}""")
for row in results.named_results():
print("Titel ", row["Titel"])
Darüber hinaus können Sie die von dem Modell zurückgegebene Abfrage nehmen, die angegebenen Spalten extrahieren und sie verwenden, um Spalten wie oben gezeigt abzurufen. Diese Ergebnisse können dann an ein Chat-Modell zurückgegeben werden, um einen vollständigen KI-Chat-Assistenten zu erstellen. Auf diese Weise kann der Assistent dynamisch auf Benutzeranfragen mit relevanten Daten antworten, die direkt aus den Ergebnissen extrahiert wurden, und so ein nahtloses und interaktives Erlebnis gewährleisten.
# Fazit
Einfaches RAG hat aufgrund seines Fokus auf einfache Ähnlichkeitssuchen begrenzte Verwendungsmöglichkeiten. Wenn es jedoch mit fortschrittlichen Tools wie MyScaleDB, LangChain usw. kombiniert wird, können RAG-Anwendungen nicht nur den Anforderungen des Big-Data-Managements im großen Maßstab gerecht werden, sondern diese sogar übertreffen. Sie können eine breitere Palette von Abfragen behandeln, einschließlich zeitbasierter und komplexer relationaler Abfragen, und so die Leistung und Effizienz Ihrer aktuellen Systeme erheblich verbessern.
Wenn Sie Vorschläge haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).
Dieser Artikel wurde ursprünglich auf The New Stack veröffentlicht. (opens new window)



