
Vektoren ermöglichen es uns, über zeitaufwändiges Lernen hinauszugehen und einfache Suchen durchzuführen, die viel schneller und dennoch so effektiv sind. Vektordatenbanken sind sehr hilfreich beim Speichern von hochdimensionalen Vektordaten wie numerischen, Text- oder Bilddaten. SQL-Vektordatenbanken wie MyScale ersparen den Menschen die Mühe, sich um komplexe Datenverarbeitung und andere Backend-Operationen zu kümmern, indem sie die Leistung von SQL und einige andere coole Funktionen wie MSTG-Indizierung nutzen.
Amazon (opens new window)Bedrock (opens new window) ist ein verwalteter Dienst, der es uns ermöglicht, KI-Anwendungen mit Grundlagenmodellen (für Text und Bild) zu erstellen. Es bietet Vorteile wie die Skalierbarkeit von AWS, die es uns ermöglicht, das Modell privat anzupassen, usw. Wir können diese Dienste nahtlos wie normale Python-Bibliotheken wie Scikit-learn oder NLTK aufrufen.
In diesem Artikel wird gezeigt, wie man mithilfe von Amazon Bedrock und MyScale eine semantische Suchanwendung für E-Books erstellt. Herkömmliche E-Reader wie Acrobat Reader, Kindle, Apple Books oder andere Reader beschränken Suchen oft auf exakte Schlüsselwortübereinstimmungen. Durch die Nutzung der Grundlagenmodelle von Amazon Bedrock für die Einbettungsgenerierung und der Fähigkeiten der Vektordatenbank von MyScale erstellen wir eine intelligentere Suchfunktion, die über die Schlüsselwortübereinstimmung hinausgeht und semantisches Verständnis ermöglicht. Durch die Nutzung der Stärken der KI-Modelle von Bedrock zusammen mit der effizienten Speicherung und Suchfunktion von MyScale können Sie die Effektivität von Textsuchen in einer Vielzahl von Anwendungen verbessern.
# Installation der Bibliotheken
Bei jedem Python-Projekt ist es eine gute Praxis, eine Umgebung zu erstellen. Hier verwenden wir Conda, um eine Umgebung für das Projekt zu erstellen:
conda create --name AWS python=3.12
Nach der Aktivierung installieren wir die entsprechenden Bibliotheken.
pip install boto3 langchain-aws clickhouse-connect
# Verbindung mit MyScale herstellen
Nachdem Sie ein Konto auf MyScale (opens new window) erstellt haben, können Sie den Cluster von der Konsole (opens new window) aus ausführen. Sie finden die Verbindungszeichenfolge in den Clusterdetails. Kopieren Sie sie einfach und stellen Sie eine Verbindung mit dem Cluster her.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='Ihr-Host-Name-hier',
port=443,
username='Ihr-Benutzername-hier',
password='Ihr-Passwort-hier')
Hinweis:
Für detailliertere schrittweise Anweisungen können Sie der Schnellstartanleitung (opens new window) folgen, um die Verbindungsdetails zu erhalten.
# Verbindung testen
Es ist nützlich, die Verbindung und die Installation der entsprechenden Bibliothek durch Erstellen einer kleinen Testtabelle zu überprüfen.
# Tabelle mit einem 128-dimensionalen Float-Vektor erstellen.
client.command("""
CREATE TABLE default.TestTable (
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id
""")
#['0', 'chi-msc-af209a77-msc-af209a77-0-0', 'OK', '0', '0']
Sie können alle Tabellen im Cluster überprüfen und die Verbindung testen, indem Sie einfach die Abfrage "SHOW TABLES" verwenden.
# Namen aller Tabellen in der aktuellen Datenbank abrufen und ausgeben.
res = client.query("SHOW TABLES").named_results()
print([r['name'] for r in res])
# ['TestTable']
# Auswahl des Einbettungsmodells
Als nächstes müssen wir ein geeignetes Einbettungsmodell auswählen. Es stehen zwei Methoden zur Verfügung, um eine Verbindung zu Amazon Bedrock herzustellen: Eine besteht darin, die offizielle Website von AWS aufzurufen, um einen IAM-Benutzer für Bedrock zu erstellen; die andere Methode besteht darin, die Funktion "EmbedText" von MyScale direkt zu nutzen, die einen schnelleren Weg bietet, um Amazon Bedrock aufzurufen.
# Verbindung mit Amazon Bedrock herstellen
Amazon Bedrock ist einer der verschiedenen Dienste von AWS. Es hostet eine Reihe von Grundlagenmodellen für die Erstellung von generativen KI-Anwendungen. RAG ist eines der spezialisierten Gebiete von Bedrock. Einige der Gründe, die Bedrock zu einer guten Option machen, sind:
- AWS-Hosting: AWS-Hostings sind ausgezeichnet (sogar die besten) und wir können uns daher keine Gedanken über Probleme wie Skalierbarkeit, Sicherheit, Betriebszeit usw. machen.
- Einfache API: Die API, wie wir gleich sehen werden, ist sehr einfach zu bedienen.
- Pay-as-you-go: Es ist nicht erforderlich, große Hosting-Pläne zu kaufen. Die Pay-as-you-go-Funktion ermöglicht es uns, unsere Nutzung an unsere Bedürfnisse anzupassen.
# Kontoerstellung
Zunächst müssen Sie einen IAM-Benutzer (bedrock_test in diesem Fall) erstellen, um Bedrock verwenden zu können.
Dann benötigen Sie einen Zugriffsschlüssel für den Terminalzugriff.

Es ist nützlich, ihn als .csv-Datei herunterzuladen, falls Sie den Zugriffsschlüssel vergessen. Natürlich ist ein Passwort-Manager die bessere Option, damit Sie ihn von dort aus kopieren können, wenn Sie ihn benötigen.
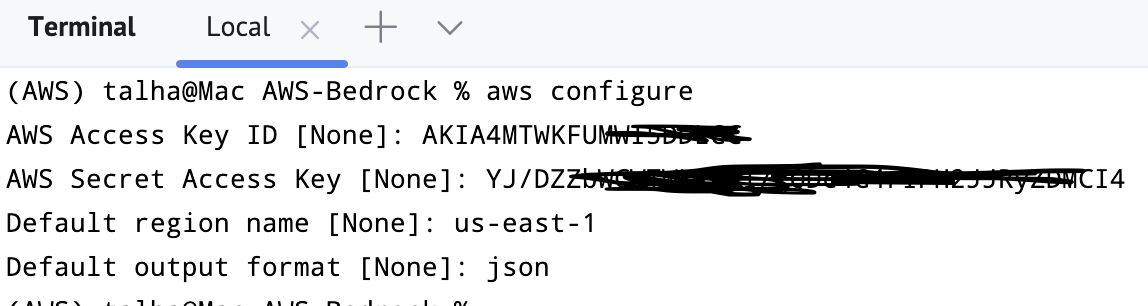
Sie können dies überprüfen, indem Sie in das Terminal gehen und aws configure eingeben. Es wird nach den Anmeldeinformationen, dem Standardausgabeformat und der Region fragen.
# Python-API
Sie können Bedrock mit dem Dienst importieren und eine Verbindung herstellen. Normalerweise bevorzugen wir es, uns mit der Region us-east-1 zu verbinden.
import boto3
bedrockInterface = boto3.client(service_name="bedrock-runtime", region_name='us-east-1')
Es läuft erfolgreich, was bedeutet, dass der Bedrock-Client/Interface installiert und konfiguriert wurde. Bisher sind einige Vorbereitungen abgeschlossen:
- MyScale einrichten und verbinden
- Bedrock einrichten und verbinden
# Modelle auswählen
Bevor Sie die semantische Suche auf dem Roman mit einem Einbettungsmodell implementieren, ist eine geeignete Modellauswahl erforderlich. Im Gegensatz zu den üblichen Datenanfragen, die Zeit in Anspruch nehmen und in der Regel sofort gewährt werden, gehen Sie zur unteren Leiste der Seitenleiste und Sie finden die entsprechende Option.
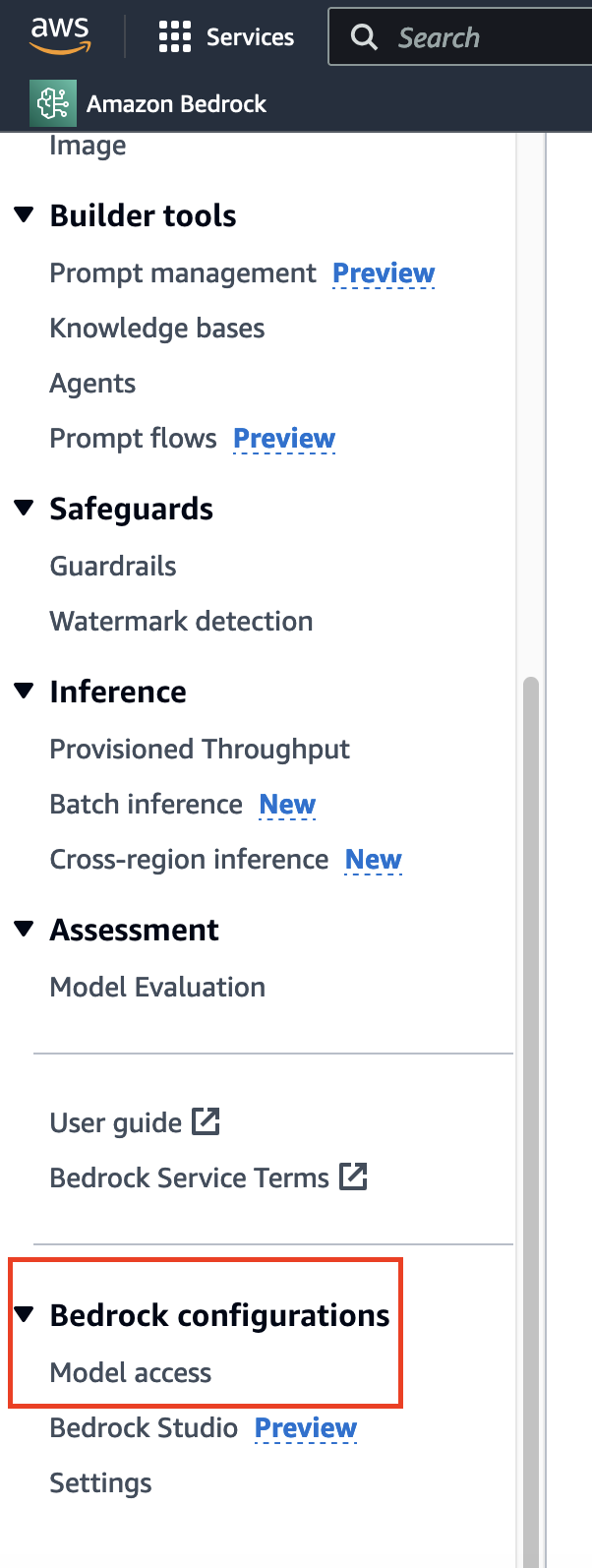
Hier hatte ich bereits Zugriff, daher sehen Sie für die meisten Modelle "Zugriff gewährt". Wenn Sie es zum ersten Mal verwenden, können Sie auf "Modelzugriff ändern" klicken und den Zugriff auf die entsprechenden Modelle aktivieren.

Hinweis:
Die Verfügbarkeit einiger Modelle hängt von der Region ab, die Sie wählen (opens new window).
# Titan-Einbettungen
Für dieses Tutorial verwenden wir das Titan-Einbettungsmodell (opens new window). Zunächst wird die Methode invoke_model() des gerade erstellten Clients/Interfaces angewendet, um das Modell zu verwenden. Da wir JSON als Modus operandi angegeben haben, müssen wir sicherstellen, dass sowohl die Eingaben als auch die Ausgaben in diesem Format vorliegen.
import json
query = "Warum ist die Zahl 42 in der Literatur so bedeutend?"
query_json = json.dumps({
"inputText": query,
})
Nun können Sie invoke_model() aufrufen. Wie wir sehen können, ist die Ausgabe ein Wörterbuch.
output = bedrockInterface.invoke_model(modelId="amazon.titan-embed-text-v1", body=query_json)
#Ausgabe
{'ResponseMetadata': {'RequestId': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Wed, 18 Sep 2024 03:05:53 GMT',
'content-type': 'application/json',
'content-length': '17180',
'connection': 'keep-alive',
'x-amzn-requestid': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'x-amzn-bedrock-invocation-latency': '68',
'x-amzn-bedrock-input-token-count': '12'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': <botocore.response.StreamingBody at 0x151b1c880>}
Um den body zu decodieren, verwenden wir erneut den JSON-Loader.
response_body = json.loads(output.get('body').read())
#Ausgabe
{'embedding': [-0.35351562,
-0.3203125,
-0.083496094,
0.04711914,
0.0034332275,
0.24902344,
-0.13183594,
-4.798174e-06,
-0.28320312,
.
.
.
0.7890625,
...],
'inputTextTokenCount': 12}
Das ist gut, aber LangChain bietet eine viel einfachere Klasse, BedrockEmbeddings. Sie verwendet die oben bereits deklarierte bedrockInterface.
from langchain_aws import BedrockEmbeddings
embeddingOutput = BedrockEmbeddings(client=bedrockInterface)
BedrockEmbeddings enthält eine Reihe von Methoden. Eine davon ist embed_query(), die einen Textstring entgegennimmt und die Einbettung zurückgibt. Da wir das Titan-Modell verwenden, sollten wir einen Einbettungsvektor der Länge 1536 erwarten.
x = embeddingGenerator.embed_query("Wie geht es dir?")
len(x)
# 1536
# Einbettungen in MyScale speichern
Jetzt erhalten wir auch die Einbettungen aus dem entsprechenden Modell, was bedeutet, dass wir uns in einer perfekten Position befinden, um die Vektordatenbank zu nutzen. Wir werden zuerst die Tabelle zur Speicherung des Texts und der entsprechenden Einbettungen erstellen und sie dann für die Inferenz weiter verwenden.
client.command("""
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
# MyScale-Einbettungsfunktionen
MyScale bietet integrierte Funktionen für verschiedene Zwecke, einschließlich des Zugriffs auf ML-Modelle. Eine dieser Funktionen ist EmbedText(), die aus verschiedenen Gründen sehr wertvoll ist:
- Direkte Schnittstelle zur Berechnung von Einbettungen für Texteingaben.
- Die Möglichkeit, eine Vielzahl verschiedener APIs wie Bedrock, Hugging Face, Open AI usw. aufzurufen.
EmbedText() (opens new window) nimmt eine Reihe von Argumenten entgegen. Wenn wir speziell über Bedrock sprechen, benötigen wir Folgendes:
- Eingabetext: Der Text, dessen Einbettung wir erhalten möchten.
- Provider: In unserem Fall wird es 'Bedrock' sein.
- API-URL: Einige APIs verwenden möglicherweise eine URL, aber in unserem Fall ist dies nicht erforderlich und wird als leerer String belassen.
api_key: Der (AWS) Secret Access Key, über den wir zuvor gesprochen haben.access_key_id: Der entsprechende Schlüssel-ID.model: Modell-ID (eines auf Bedrock).region_name: AWS-Region.
Beispielsweise verwenden wir diese Funktion wie folgt:
SELECT EmbedText('Nenn mich Ishmael. Vor einigen Jahren - es spielt keine Rolle, wie lange genau - hatte ich wenig oder kein Geld in meiner Brieftasche und nichts Besonderes, das mich an Land interessierte. Ich dachte, ich würde ein wenig segeln und den wässrigen Teil der Welt sehen.', 'Bedrock', '', 'xxxxxxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxxx"}')
Da es sich um eine skalare Funktion handelt, erhalten wir diese direkte Ausgabe.

Jetzt, jedes Mal, wenn wir diese Funktion aufrufen, sind alle Argumente außer dem Eingabetext gleich. Daher können wir sie anpassen:
CREATE FUNCTION EmbedTest AS (x) -> EmbedText(x, 'Bedrock', '', 'xxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxx"}')
SELECT EmbedTest('Nenn mich Ishmael. Vor einigen Jahren - es spielt keine Rolle, wie lange genau - hatte ich wenig oder kein Geld in meiner Brieftasche und nichts Besonderes, das mich an Land interessierte. Ich dachte, ich würde ein wenig segeln und den wässrigen Teil der Welt sehen.')
Diese angepasste Funktion kann problemlos von überall aus aufgerufen werden. Nachdem wir diese einfache Einbettungsfunktion (die mit anderen APIs erweitert werden kann) gesehen haben, gehen wir zurück zur Front-End-Anwendung, um etwas Text abzurufen, den wir im Rest des Blogs verwenden werden.
# Generieren von Bucheinbettungen
Nun wählen wir ein Buch aus und generieren seine Einbettungen. Verwenden wir zum Beispiel Gutenberg (opens new window), um Tolstois Klassiker (opens new window) zu nehmen:
import requests
url = "<https://www.gutenberg.org/files/1399/1399-0.txt>"
response = requests.get(url)
if response.status_code == 200:
bookText = response.content.decode('utf-8-sig')
start = bookText.find("CHAPTER I")
end = bookText.find("End of the Project Gutenberg EBook")
bookText = bookText[start:end]
chapters = re.split(r'(Chapter \\d+)', book_text)
splitChapters = ["".join(x) for x in zip(chapters[1::2], chapters[2::2])]
Jetzt haben wir Anna Karenina im Kapitel-für-Kapitel-Format. Sie können alle Kapitel durch das Titan-Modell geben, um die Einbettungen zu erhalten.
embeddingsMatrix = [embeddingGenerator.embed_query(chapter) for chapter in splitChapters]
Anschließend wird es in ein DataFrame konvertiert und in die Tabelle eingefügt.
import pandas as pd
df = pd.DataFrame({
'Text': splitChapters,
'Embedding': embeddingsMatrix
})
df_records = df.to_records(index=True)
client.insert("BookEmbeddings", df_records.tolist(), column_names=["id", "sentences", "embeddings"])
Die Daten werden erfolgreich eingefügt, wie wir im SQL-Arbeitsbereich (opens new window) (auf der MyScale-Konsole) bestätigen können.
# Indizierung
Die Indizierung ist nützlich, um die Distanz zwischen den Einbettungen schnell zu berechnen.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX dist_idx embeddings
TYPE MSTG
""")
Es kann einige Momente dauern, bis dieser Index angewendet wird (abhängig von den Daten).
# Verwendung von MyScale zur Suche nach dem Roman Anna Karenina
Nachdem der gesamte Roman in der Datenbank gespeichert und die Indizierung aktiviert ist, kehren wir zur Vektordatenbank zurück, um einige Abfragen auszuführen. Suchen wir zum Beispiel die relevantesten Kapitel (d.h. Dokumentenabruf).
query = "Was ist mit Levins Bruder passiert?"
queryEmbeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {queryEmbeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
Im folgenden Ergebnis sehen Sie, dass diese 3 Kapitel am relevantesten für die Beantwortung der Abfrage sind.

query = "Als Dolly Anna in ihrem Haus besuchen ging?"
query_embeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {query_embeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
Auch hier ist das Ergebnis bemerkenswert, da die Vektorsuche ziemlich gut funktioniert.

Ich habe herumgespielt und eine andere Maßeinheit ausprobiert (Kosinusähnlichkeit). Während die Entfernungen unterschiedlich waren, habe ich immer noch die gleichen Antworten wie oben erhalten. Wenn Sie es ausprobieren möchten, können Sie gerne den vorhandenen Index löschen und den Index für die Kosinusähnlichkeit hinzufügen.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX cosine_idx embeddings
TYPE MSTG
('metric_type=Cosine')
""")

# Fazit
Die Verwendung von Amazon Bedrock und MyScale für die Vektorsuche bietet eine klare Verbesserung gegenüber den herkömmlichen suchbasierten Suchen, die in den meisten E-Readern zu finden sind. Mit der semantischen Suche können Benutzer relevante Inhalte finden, auch wenn sie sich nicht an die genauen Begriffe erinnern, was das Leseerlebnis viel reibungsloser macht. Obwohl sich dieses Beispiel auf einen einzelnen Roman konzentriert, kann dieser Ansatz auf eine Vielzahl von Texten angewendet werden, von anderen Büchern über juristische Dokumente bis hin zu offiziellen Papieren.
Der Prozess ist auch recht zugänglich. Alles, was hier gezeigt wurde, wurde mit der kostenlosen Stufe von MyScale durchgeführt, die ausreichend Ressourcen für Tests und die Reproduktion von Ergebnissen bietet. Durch die Kombination der Stärken der KI-Modelle von Bedrock und der effizienten Speicherung und Suchfunktion von MyScale können Sie Textsuchen in einer Vielzahl von Anwendungen effektiver handhaben.



