
In den frühen Phasen der Datenbankentwicklung wurden Daten in einfachen Tabellen gespeichert. Diese Methode war unkompliziert, aber mit zunehmender Datenmenge wurde es schwieriger und langsamer, Informationen zu verwalten und abzurufen. Dann wurden relationale Datenbanken eingeführt, die bessere Möglichkeiten zur Speicherung und Verarbeitung von Daten bieten.
Eine wichtige Technik in relationalen Datenbanken ist die Indizierung, die sehr ähnlich funktioniert wie die Art und Weise, wie Bücher in einer Bibliothek aufbewahrt werden. Anstatt die gesamte Bibliothek durchzusuchen, gehen Sie direkt zu einem bestimmten Abschnitt, in dem das benötigte Buch platziert ist. Die Indizierung in Datenbanken funktioniert ähnlich und beschleunigt den Prozess des Auffindens der benötigten Daten.
In diesem Blog behandeln wir die Grundlagen der Vektorindizierung und wie sie mit verschiedenen Techniken implementiert wird.
# Was sind Vektoreinbettungen
Vektoreinbettungen sind einfach die numerische Darstellung, die aus Bildern, Texten und Audio konvertiert wird. In einfacheren Worten wird ein einzelner mathematischer Vektor gegen jedes Element erstellt, der die Semantik oder Eigenschaften dieses Elements erfasst. Diese Vektoreinbettungen werden von Rechensystemen leichter verstanden und sind mit maschinellen Lernmodellen kompatibel, um Beziehungen und Ähnlichkeiten zwischen verschiedenen Elementen zu verstehen.
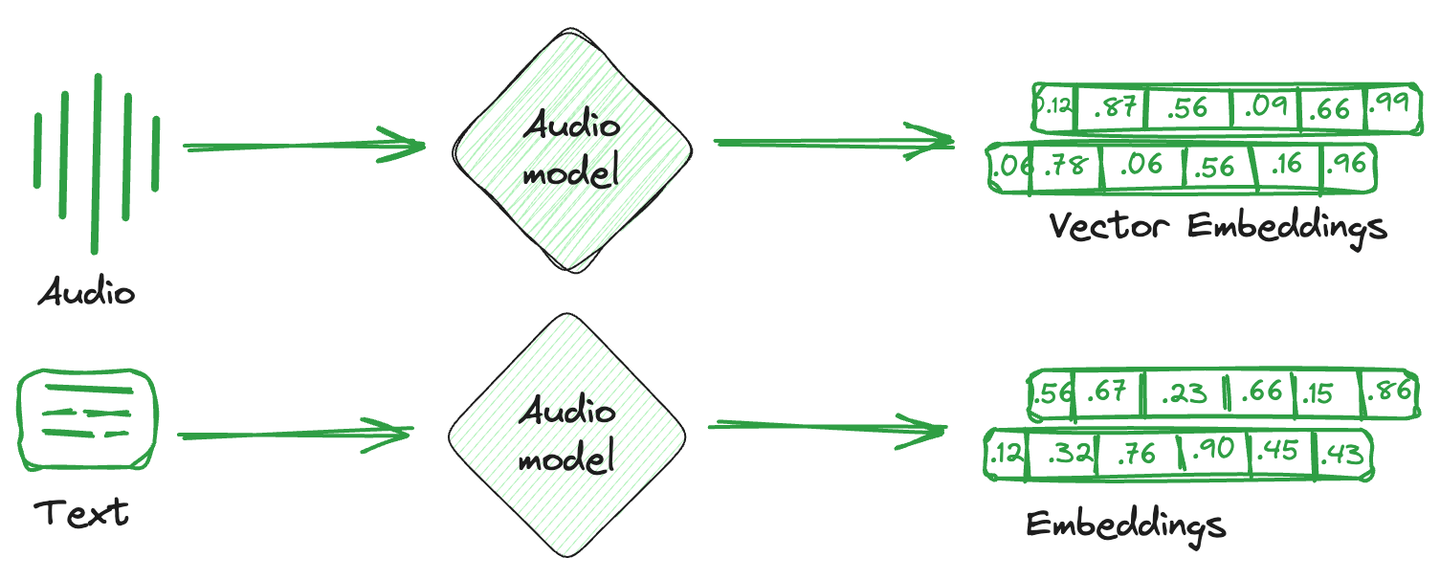
Spezialisierte Datenbanken, die diese Einbettungsvektoren speichern, werden als Vektordatenbanken bezeichnet. Diese Datenbanken nutzen die mathematischen Eigenschaften von Einbettungen, die es ermöglichen, ähnliche Elemente zusammen zu speichern. Unterschiedliche Techniken werden verwendet, um ähnliche Vektoren zusammen und unähnliche Vektoren auseinander zu speichern. Dies sind Vektorindizierungstechniken.
# Was ist ein Vektorindex
Vektorindizierung geht nicht nur darum, Daten zu speichern, sondern auch darum, die Vektoreinbettungen intelligent zu organisieren, um den Abrufprozess zu optimieren. Diese Technik umfasst fortschrittliche Algorithmen, um die hochdimensionalen Vektoren auf eine durchsuchbare und effiziente Weise ordentlich anzuordnen. Diese Anordnung ist nicht zufällig; sie erfolgt so, dass ähnliche Vektoren zusammen gruppiert werden. Durch die Vektorindizierung ermöglicht dies schnelle und genaue Ähnlichkeitssuchen und Mustererkennung, insbesondere bei der Suche in großen und komplexen Datensätzen.
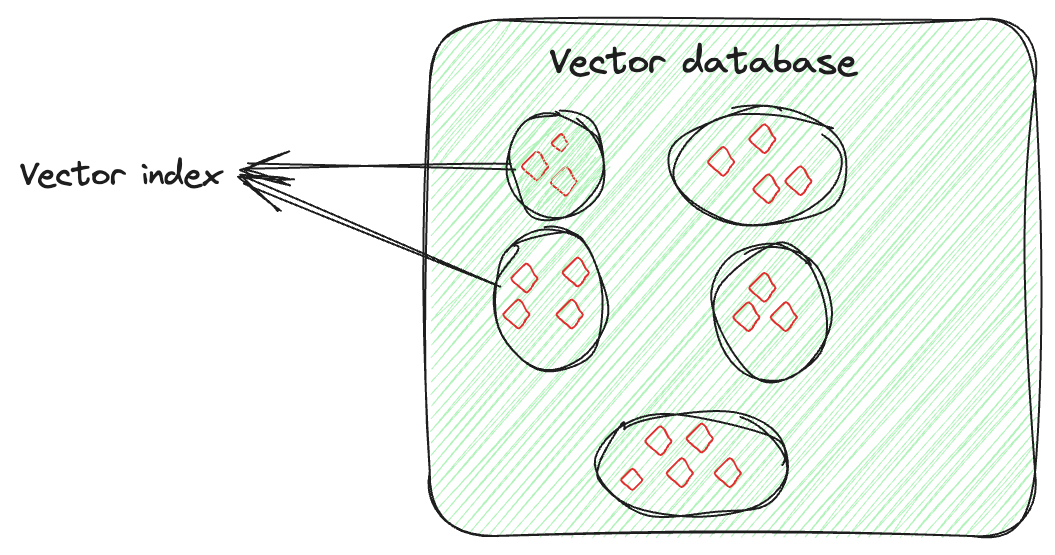
Angenommen, Sie haben einen Vektor für jedes Bild, der seine Merkmale erfasst. Der Vektorindex organisiert diese Vektoren so, dass es einfacher ist, ähnliche Bilder zu finden (hier). Sie können sich vorstellen, dass Sie die Bilder jeder Person separat organisieren. Wenn Sie also ein bestimmtes Bild einer bestimmten Person von einer bestimmten Veranstaltung benötigen, würden Sie nicht alle Bilder durchsuchen, sondern nur die Sammlung dieser Person durchgehen und das Bild leicht finden.
# Häufige Vektorindizierungstechniken
Je nach spezifischen Anforderungen werden verschiedene Indizierungstechniken verwendet. Lassen Sie uns einige davon besprechen.
# Inverted File (IVF)
Dies ist die grundlegendste Indizierungstechnik. Sie teilt die gesamten Daten in mehrere Cluster auf, indem Techniken wie K-Means-Clustering verwendet werden. Jeder Vektor der Datenbank wird einem bestimmten Cluster zugeordnet. Diese strukturierte Anordnung von Vektoren ermöglicht es dem Benutzer, die Suchanfragen viel schneller zu machen. Wenn eine neue Anfrage eingeht, durchsucht das System nicht die gesamte Datenmenge. Stattdessen identifiziert es die nächstgelegenen oder ähnlichsten Cluster und sucht nach dem spezifischen Dokument innerhalb dieser Cluster.
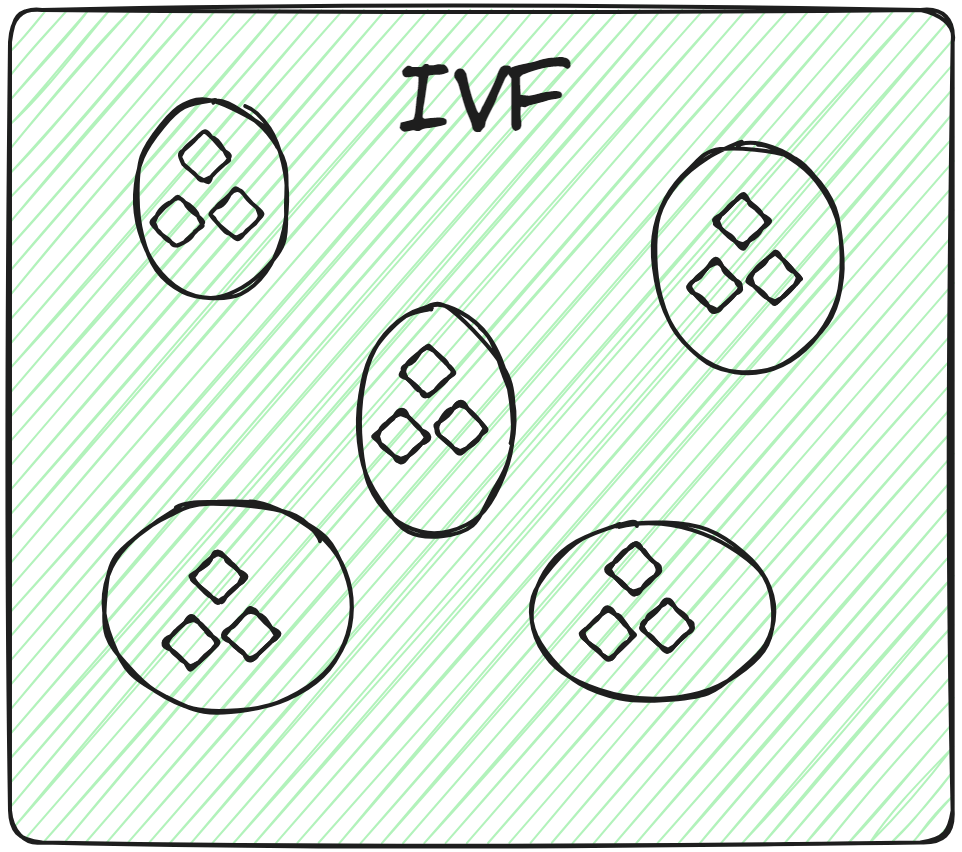
Durch die ausschließliche Anwendung der Brute-Force-Suche innerhalb des relevanten Clusters anstelle der gesamten Datenbank wird nicht nur die Suchgeschwindigkeit verbessert, sondern auch die Abfragezeit erheblich reduziert.
# Varianten von IVF: IVFFLAT, IVFPQ und IVFSQ
Es gibt verschiedene Varianten von IVF, abhängig von den spezifischen Anforderungen der Anwendung. Schauen wir sie uns genauer an.
# IVFFLAT
IVFFLAT (opens new window) ist eine einfachere Form von IVF. Sie teilt den Datensatz in Cluster auf. Innerhalb jedes Clusters verwendet sie jedoch eine flache Struktur (daher der Name "FLAT") zur Speicherung der Vektoren. IVFFLAT ist darauf ausgelegt, das Gleichgewicht zwischen Suchgeschwindigkeit und Genauigkeit zu optimieren.
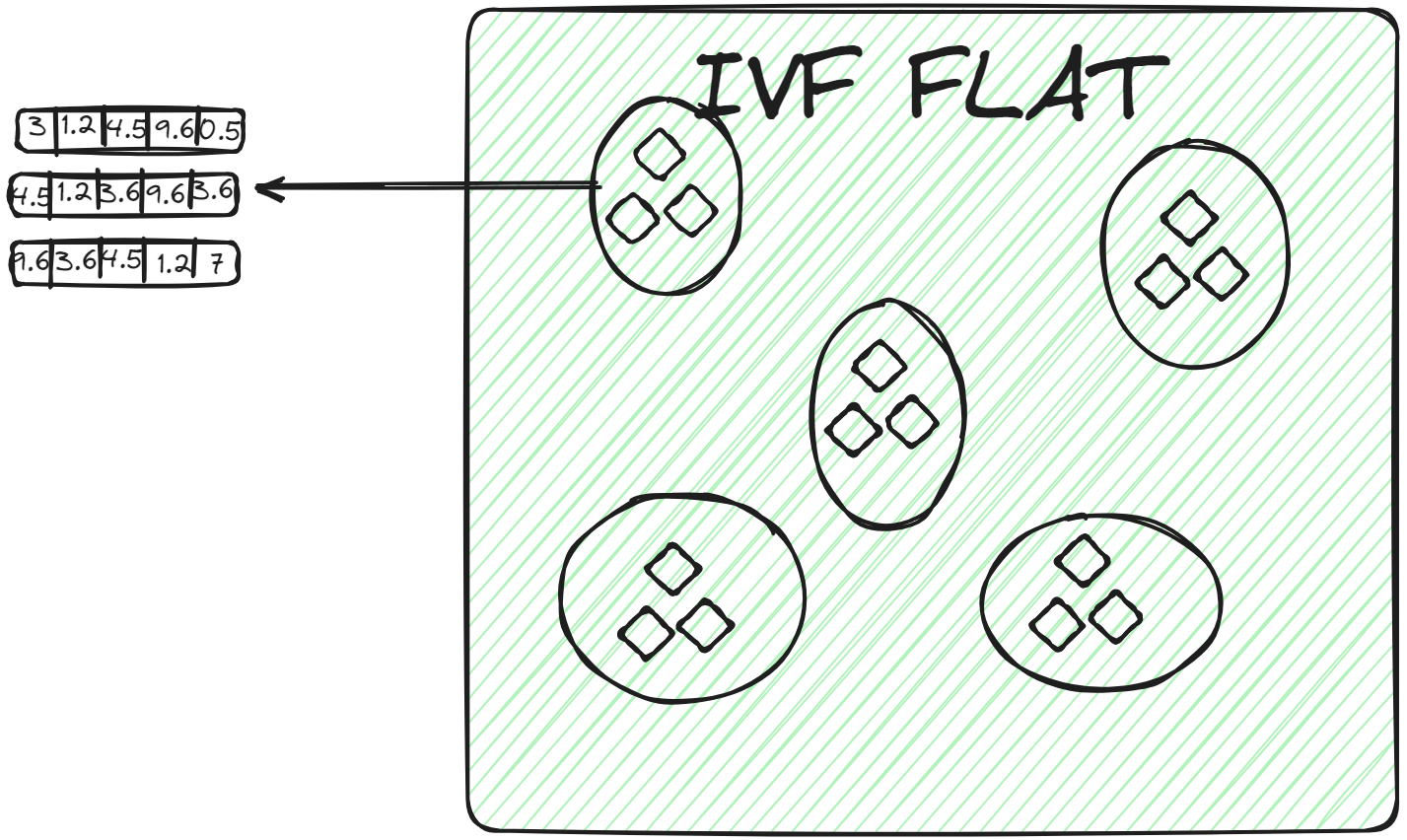
In jedem Cluster werden die Vektoren in einer einfachen Liste oder einem Array ohne zusätzliche Unterteilung oder hierarchische Strukturen gespeichert. Wenn ein Abfragevektor einem Cluster zugeordnet wird, wird der nächstgelegene Nachbar durch eine Brute-Force-Suche gefunden, bei der jeder Vektor in der Liste des Clusters untersucht und sein Abstand zum Abfragevektor berechnet wird. IVFFLAT wird in Szenarien eingesetzt, in denen der Datensatz nicht besonders groß ist und das Ziel darin besteht, eine hohe Genauigkeit im Suchprozess zu erreichen.
# IVFPQ
IVFPQ (opens new window) ist eine fortgeschrittene Variante von IVF, die für Inverted File with Product Quantization steht. Sie teilt die Daten ebenfalls in Cluster auf, aber jeder Vektor in einem Cluster wird in kleinere Vektoren aufgeteilt, und jeder Teil wird mit Hilfe der Produktquantisierung in eine begrenzte Anzahl von Bits codiert oder komprimiert.
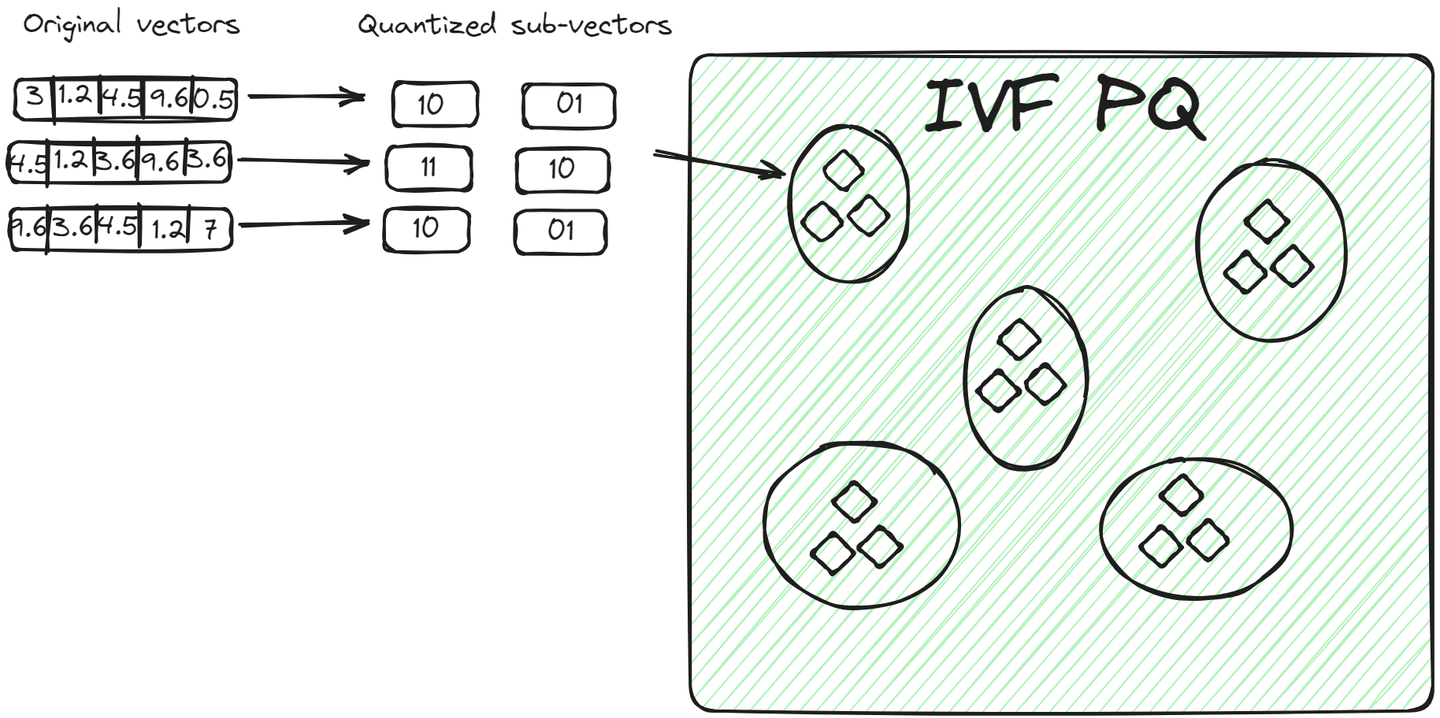
Für einen Abfragevektor vergleicht der Algorithmus nach Identifizierung des relevanten Clusters die quantisierte Darstellung der Abfrage mit den quantisierten Darstellungen der Vektoren innerhalb des Clusters. Dieser Vergleich ist schneller als der Vergleich von Rohvektoren aufgrund der reduzierten Dimensionalität und Größe durch Quantisierung. Diese Methode hat zwei Vorteile gegenüber der vorherigen Methode:
- Die Vektoren werden auf kompakte Weise gespeichert und nehmen weniger Platz ein als die Rohvektoren.
- Der Abfrageprozess ist noch schneller, da nicht alle Rohvektoren, sondern codierte Vektoren verglichen werden.
# IVFSQ
File System with Scalar Quantization (IVFSQ) (opens new window) teilt wie andere IVF-Varianten die Daten in Cluster auf. Der wesentliche Unterschied besteht jedoch in der Quantisierungstechnik. Bei IVFSQ wird jeder Vektor in einem Cluster einer skalaren Quantisierung unterzogen. Das bedeutet, dass jede Dimension des Vektors separat behandelt wird.
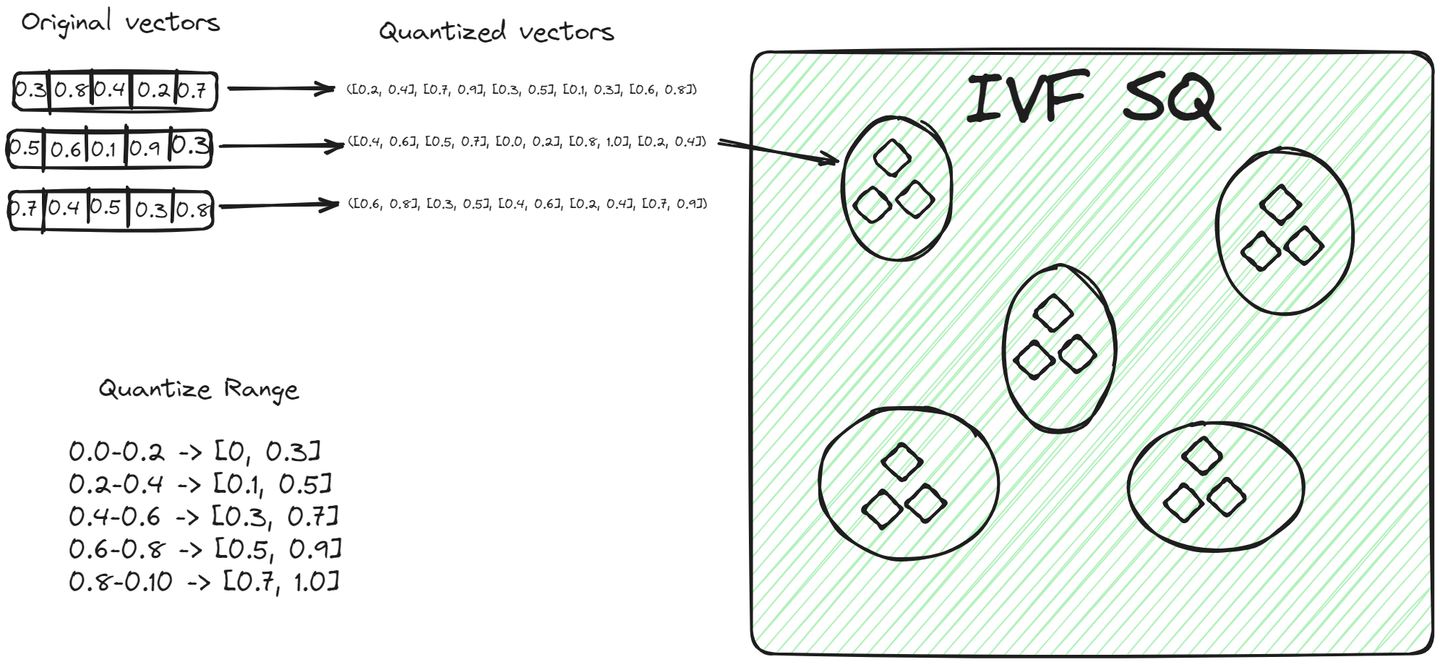
Einfach ausgedrückt legen wir für jede Dimension eines Vektors einen vordefinierten Wert oder Bereich fest. Diese Werte oder Bereiche helfen dabei, zu entscheiden, welchem Cluster ein Vektor angehört. Jede Komponente des Vektors wird dann mit diesen vordefinierten Werten abgeglichen, um ihren Platz in einem Cluster zu finden. Diese Methode des Zerlegens und Quantisierens jeder Dimension macht den Prozess einfacher. Sie ist besonders nützlich für niedrigdimensionale Daten, da sie die Codierung vereinfacht und den für die Speicherung benötigten Platz reduziert.
# Hierarchical Navigable Small World (HNSW) Algorithmus
Der Hierarchical Navigable Small World (opens new window) (HNSW) Algorithmus ist eine ausgefeilte Methode zur effizienten Speicherung und Abfrage von Daten. Seine graphenähnliche Struktur ist von zwei verschiedenen Techniken inspiriert: der Wahrscheinlichkeits-Skip-Liste und dem Navigable Small World (NSW).
Um HNSW besser zu verstehen, wollen wir zuerst die grundlegenden Konzepte dieses Algorithmus betrachten.
# Skip-Liste
Eine Skip-Liste ist eine fortgeschrittene Datenstruktur, die die Vorteile von zwei traditionellen Strukturen kombiniert: die schnelle Einfügefähigkeit einer verketteten Liste und die schnelle Abruffähigkeit eines Arrays. Dies wird durch ihre mehrschichtige Architektur erreicht, bei der die Daten über mehrere Ebenen organisiert sind, wobei jede Ebene eine Teilmenge der Datenpunkte enthält.
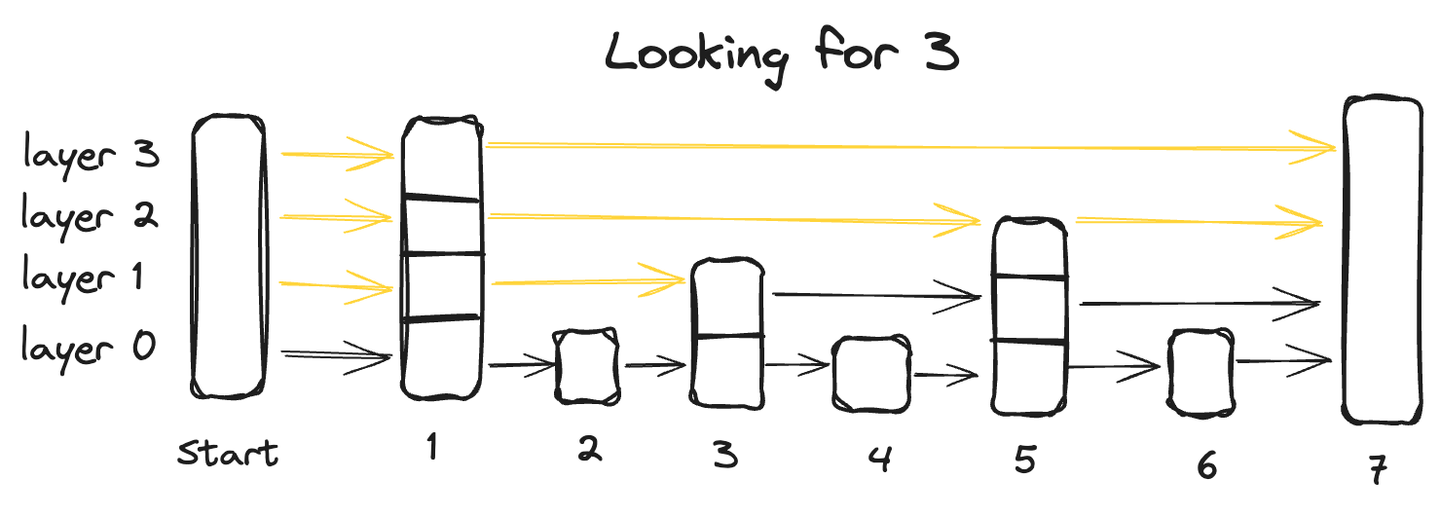
Ausgehend von der untersten Ebene, die alle Datenpunkte enthält, überspringt jede nachfolgende Ebene einige Punkte und hat daher weniger Datenpunkte, wobei die oberste Ebene die geringste Anzahl von Datenpunkten aufweist.
Um einen Datenpunkt in einer Skip-Liste zu suchen, beginnen wir in der obersten Ebene und gehen von links nach rechts und erkunden jeden Datenpunkt. An jedem Punkt, wenn der abgefragte Wert größer als der aktuelle Datenpunkt ist, gehen wir zurück zum vorherigen Datenpunkt in der darunterliegenden Ebene und setzen die Suche von links nach rechts fort, bis wir den genauen Punkt finden.
# Navigable Small World (NSW)
Navigable Small World (NSW) ähnelt einem proximaten Graphen, bei dem Knoten basierend auf ihrer Ähnlichkeit miteinander verbunden sind. Die gierige Methode wird verwendet, um den nächstgelegenen Nachbarpunkt zu suchen.
Wir beginnen immer mit einem vordefinierten Einstiegspunkt, der mit mehreren nahegelegenen Knoten verbunden ist. Wir identifizieren, welche dieser Knoten dem Abfragevektor am nächsten sind, und bewegen uns dorthin. Dieser Prozess wiederholt sich, bis es keinen Knoten gibt, der dem Abfragevektor näher ist als der aktuelle Knoten, was als Abbruchbedingung für den Algorithmus dient.
Nun kommen wir zum Hauptthema zurück und sehen, wie es funktioniert.
# Wie HNSW entwickelt wird
Bei HNSW nehmen wir die Motivation aus der Skip-Liste und erstellen Schichten wie bei der Skip-Liste. Aber für die Verbindung zwischen den Datenpunkten erstellen wir eine graphenähnliche Verbindung zwischen den Knoten. Die Knoten in jeder Schicht sind nicht nur mit den Knoten der aktuellen Schicht verbunden, sondern auch mit den Knoten der darunterliegenden Schichten. Die Knoten oben sind sehr wenige und die Intensität nimmt zu, wenn wir zu den unteren Schichten gehen. Die letzte Schicht enthält alle Datenpunkte der Datenbank. So sieht die HNSW-Architektur aus.
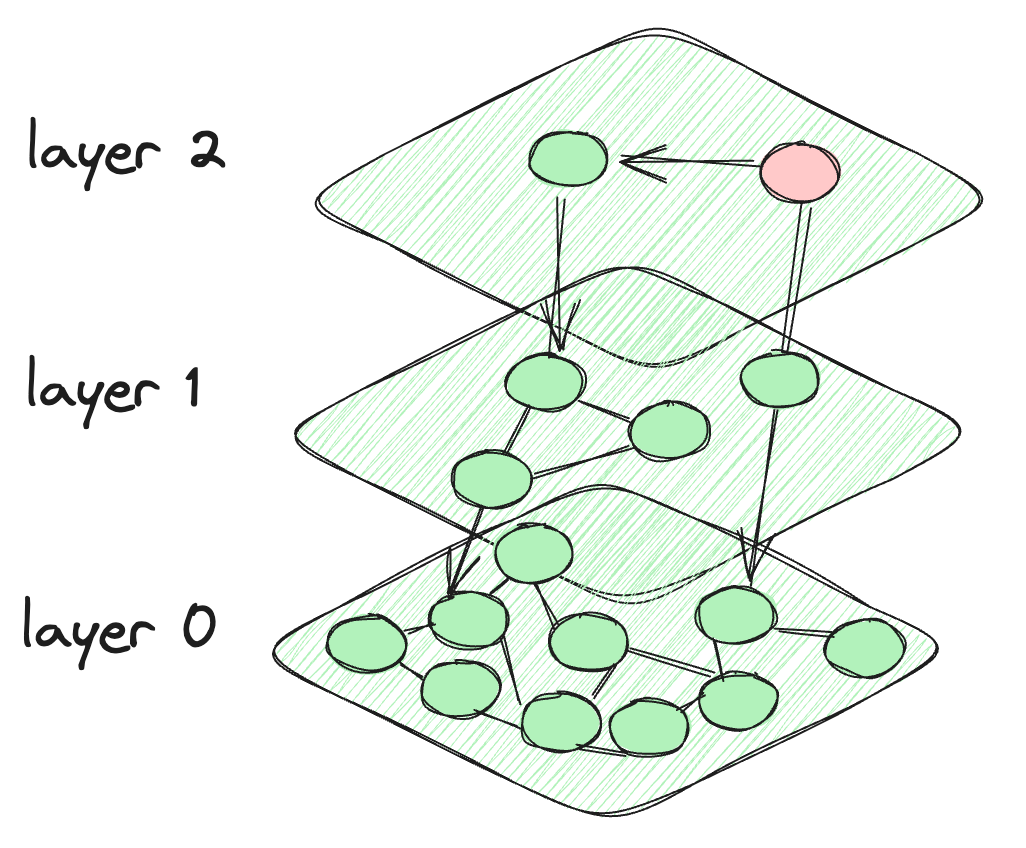
Die Architektur des HNSW-Algorithmus
# Wie funktioniert eine Suchanfrage in HNSW
Der Algorithmus startet beim vordefinierten Knoten der obersten Schicht. Er berechnet dann den Abstand zwischen den verbundenen Knoten der aktuellen Schicht und denen in der darunterliegenden Schicht. Der Algorithmus wechselt zu einer niedrigeren Schicht, wenn der Abstand zu einem Knoten in dieser Schicht kleiner ist als der Abstand zu Knoten in der aktuellen Schicht. Dieser Prozess wird fortgesetzt, bis die letzte Schicht erreicht ist oder ein Knoten erreicht wird, der den minimalen Abstand zu allen anderen verbundenen Knoten hat. Die letzte Schicht, Layer 0, enthält alle Datenpunkte und bietet eine umfassende und detaillierte Darstellung des Datensatzes. Diese Schicht ist entscheidend, um sicherzustellen, dass die Suche alle potenziellen nächsten Nachbarn einschließt.
# Verschiedene Varianten von HNSW: HNSWFLAT und HNSWSQ
Wie bei IVFFLAT und IVFSQ, bei denen einer Rohvektoren speichert und der andere quantisierte Bereiche speichert, gilt dasselbe für HNSWFLAT und HNSWSQ. Bei HNSWFLAT werden die Rohvektoren so gespeichert, wie sie sind, während bei HNSWSQ die Vektoren in quantisierter Form gespeichert werden. Abgesehen von diesem wesentlichen Unterschied in der Datenspeicherung sind der gesamte Prozess und die Methodik der Indizierung und Suche in HNSWFLAT und HNSWSQ gleich.

# Multi-Scale Tree Graph (MSTG) Algorithmus
Die Standard Inverted File Indexing (IVF) partitioniert einen Vektordatensatz in zahlreiche Cluster, während Hierarchical Navigable Small World (HNSW) einen hierarchischen Graphen für die Vektordaten erstellt. Eine bemerkenswerte Einschränkung dieser Methoden ist jedoch das erhebliche Wachstum der Indexgröße bei massiven Datensätzen, was die Speicherung aller Vektordaten im Arbeitsspeicher erfordert. Während Methoden wie DiskANN den Vektorspeicher auf SSD auslagern können, baut es den Index langsam auf und weist eine sehr geringe Leistung bei gefilterten Suchen auf.
Multi-Scale Tree Graph (MSTG) wurde von MyScale (opens new window) entwickelt und überwindet diese Einschränkungen, indem es hierarchisches Baumclustering mit Graphtraversierung, Speicher mit schnellen NVMe SSDs kombiniert. MSTG reduziert signifikant den Ressourcenverbrauch von IVF/HNSW und behält dabei eine außergewöhnliche Leistung bei. Es baut schnell auf, sucht schnell und bleibt schnell und genau bei verschiedenen gefilterten Suchverhältnissen, dabei ist es ressourcen- und kosteneffizient.
# Fazit
Vektordatenbanken haben die Art und Weise, wie Daten gespeichert werden, revolutioniert und bieten nicht nur eine verbesserte Geschwindigkeit, sondern auch immense Nützlichkeit in verschiedenen Bereichen wie künstlicher Intelligenz und Big Data-Analyse. In einer Ära exponentiellen Datenwachstums, insbesondere in unstrukturierter Form, sind die Anwendungen von Vektordatenbanken grenzenlos. Maßgeschneiderte Indizierungstechniken verstärken die Leistung und Effektivität dieser Datenbanken, beispielsweise durch die Verbesserung der gefilterten Vektorsuche. MyScale optimiert die gefilterte Vektorsuche (opens new window) mit dem einzigartigen MSTG-Algorithmus und bietet eine leistungsstarke Lösung für komplexe, groß angelegte Vektorsuchen. Probieren Sie MyScale noch heute aus (opens new window), um die fortschrittliche Vektorsuche zu erleben.



