
Die Vektor-Suche kann semantisch ähnliche oder verwandte Kandidaten in großen Mengen von Texten, Bildern und anderen Daten schnell lokalisieren. In realen Szenarien reicht jedoch die reine Vektor-Suche oft nicht aus.
Tatsächliche Daten enthalten in der Regel Attribute wie Zeit, Kategorie, Benutzer-ID und andere Schlüsselwörter. Durch Anwendung einer oder mehrerer Filterbedingungen auf diese Attribute kann die Präzision von Retrieval-Augmented Generation (RAG)-Systemen erheblich verbessert werden und es entsteht die Grundlage für groß angelegte Multi-Tenant-Systeme. MyScale (opens new window), entwickelt auf der ClickHouse-Datenbank, unterstützt eine breite Palette von Datenarten in SQL und erzielt hohe Präzision und Effizienz bei Suchen mit beliebigem Filterverhältnis.
Dieser Artikel behandelt die Bedeutung der gefilterten Vektorsuche sowie die Technologien, die zu ihrer Umsetzung gehören, einschließlich Vorfilterung und Nachfilterung, sowie Zeilen- und Spalten-Speicherung.
# Gefilterte Vektor-Suche ist entscheidend für die Verbesserung der Genauigkeit von RAG-Systemen
Gefilterte Suche spielt eine wichtige Rolle bei der Unterstützung von hochgenauen LLM/AI-Anwendungen. Die reine Vektor-Retrieval liefert in Szenarien mit begrenztem Dokumenteninhalt oft relativ genaue Kandidaten. Wenn jedoch das Dokumentenvolumen zunimmt, nimmt die Abrufgenauigkeit in der Regel rapide ab.
Dieses Problem tritt hauptsächlich in komplexen Dokumentenumgebungen wie der Finanzbranche auf, wo relevanter Inhalt oft reichlich vorhanden ist. In solchen Fällen kann die reine Vektor-Retrieval viele ähnliche, aber falsche Absätze zurückgeben, was sich negativ auf die Genauigkeit der endgültigen Antwort auswirkt.
Beispielsweise könnte ein Benutzer in Szenarien der Finanzanalyse fragen: "Wie ist der Führungsstil von <Unternehmen>?" Wenn <Unternehmen> ein seltener Firmenname ist, kann die reine Vektor-Retrieval oft zu einer Vielzahl ähnlicher, aber ungenauer Inhalte führen, wie Absätze über den Führungsstil ähnlicher Unternehmen, was die genaue Generierung von Antworten durch das LLM behindert.
Wenn wir jedoch im Voraus wissen, dass Dokumententitel, die mit <Unternehmen> zusammenhängen, dieses Schlüsselwort in ihren Titeln enthalten, können wir WHERE title ILIKE '%<Unternehmen>%' für die Vorfilterung verwenden und dadurch die Suchergebnisse auf relevante Dokumente beschränken. Darüber hinaus kann das <Unternehmen> automatisch vom LLM extrahiert werden - z.B. als Parameter in einem Funktionsaufruf oder durch Generierung von SQL WHERE-Klauseln aus dem Abfragetext - um sicherzustellen, dass das System flexibel und benutzerfreundlich ist.
Durch die Verwendung dieser strukturierten Attribute für die Filterung haben wir in realen Anwendungen wie der Finanzdokumentenanalyse und Unternehmenswissensdatenbanken eine Präzisionssteigerung von 60% auf 90% festgestellt. Um eine hohe Präzision bei Abfragen in RAG-Systemen zu gewährleisten, benötigen wir daher einen flexiblen und universellen Ansatz für die Modellierung und Abfrage von strukturierten + Vektor-Daten sowie eine Vektor-Retrieval, die unabhängig vom Filterverhältnis eine hohe Präzision und Effizienz garantiert.

# Gefilterte Vektor-Suche ist die Grundlage für die Implementierung von großen Multi-User-Systemen
Gefilterte Vektor-Suche ist grundlegend in Anwendungen wie groß angelegter Dokumenten-QA, virtuellem Charakter-Chat mit semantischer Speicherung und sozialen Netzwerken, wo das System Abfragen auf Daten von Millionen von Benutzern unterstützen muss, wobei jede Abfrage in der Regel Daten von einem einzelnen oder kleinen Benutzersatz umfasst.
Dies erfordert eine außergewöhnlich hohe Abfragegenauigkeit bei sehr niedrigen Filterverhältnissen in einem großen Vektordatensatz. Spezialisierte Vektordatenbanken wie Pinecone, Weaviate und Milvus, die für solche Anwendungen entwickelt wurden, haben einen Namespace-Mechanismus eingeführt, bei dem Entwickler die Daten jedes Benutzers in einem separaten Namespace platzieren können, um die Abfragegenauigkeit zu gewährleisten.
Diese Methode beschränkt jedoch die Flexibilität, da eine einzelne Abfrage nur innerhalb eines Namespaces suchen kann. Zum Beispiel müssen Benutzer in sozialen Netzwerken möglicherweise Inhalte abfragen, die sich auf ihre Freunde beziehen, was Abfragen für Hunderte bis Tausende von Freundesdaten umfasst. In der Kontextanalyse und in Empfehlungssystemen sind oft komplexe gefilterte Abfragen erforderlich - basierend auf Zeit, Autor, Schlüsselwörtern usw.
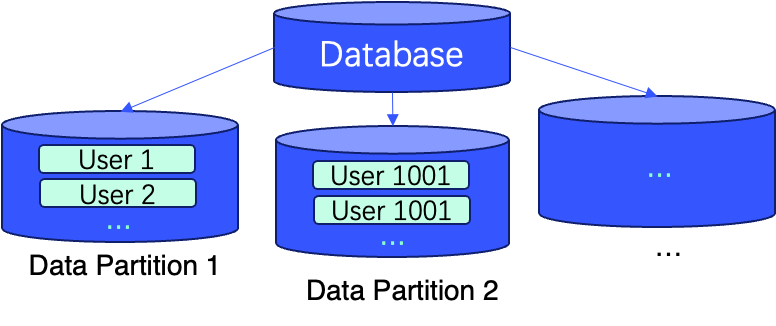
In diesen Fällen und mehr bieten gefilterte Abfragen mit WHERE-Bedingungen einen flexibleren Ansatz. Darüber hinaus kann durch Datenpartitionierung und Sortierung der Daten über Primärschlüssel die Abfrageeffizienz weiter verbessert werden, indem die Datenlokalität verbessert wird.
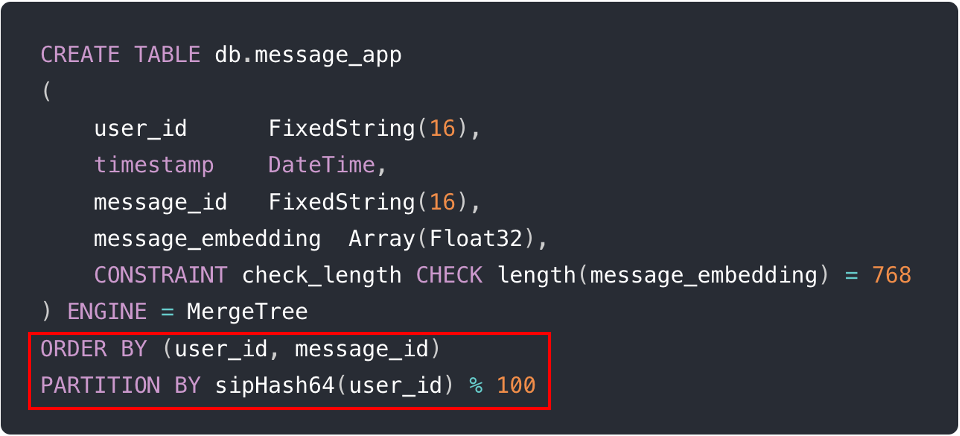
Die folgenden Abbildungen beschreiben ein reales Beispiel, das die Implementierung dieser Techniken mit zwei Zeilen SQL während der Tabellenerstellung zeigt (d.h. ORDER BY (user_id, message_id) und PARTITION BY sipHash64(user_id) % 100).
Hinweis:
Weitere Informationen finden Sie in unserer Dokumentation zur Multi-Tenancy (opens new window).
# MyScale unterstützt hochpräzise, hoch effiziente gefilterte Suche bei jedem Verhältnis
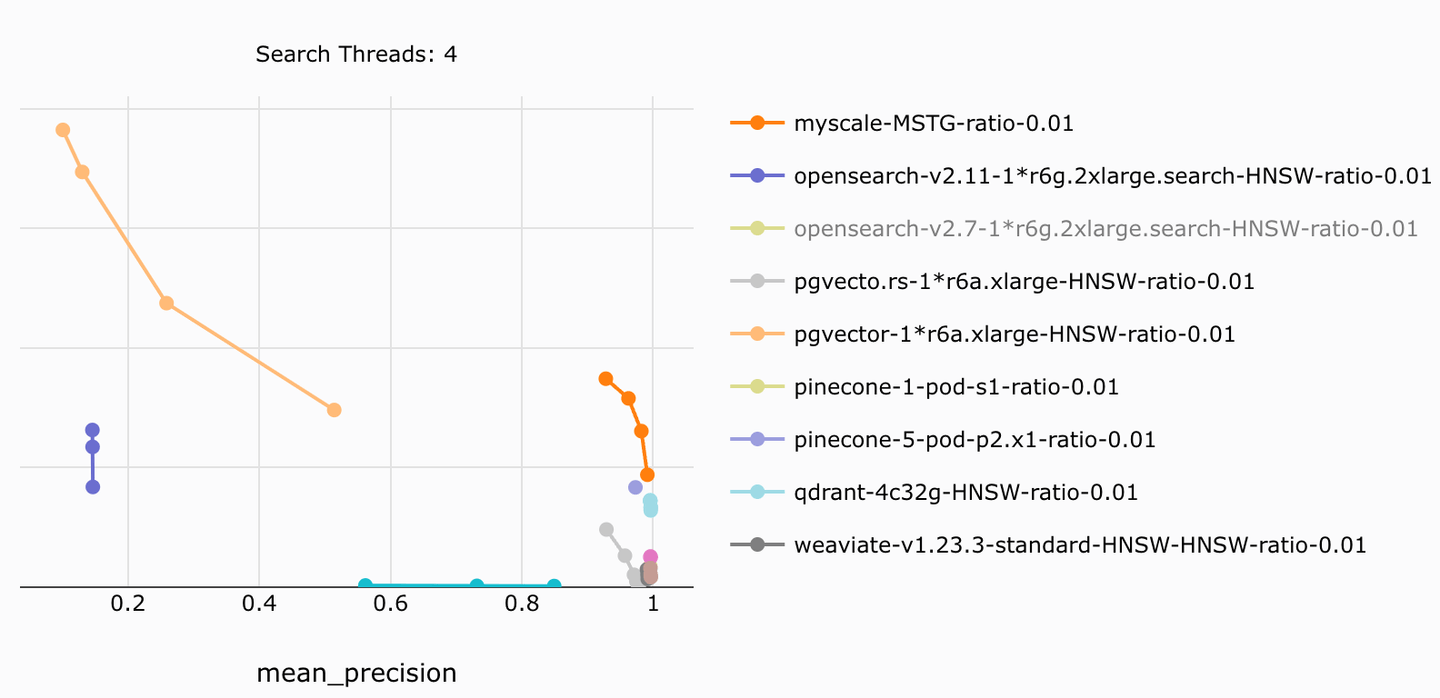
MyScale ermöglicht eine hochpräzise und hoch effiziente gefilterte Suche bei jedem Filterverhältnis, indem es Spaltenspeicherung, Vorfilterung und effiziente Suchalgorithmen kombiniert. Es bietet ein 4x-10x niedrigeres Kosten-Leistungs-Verhältnis im Vergleich zu anderen Produkten.
MyScale erreicht beispielsweise die höchste Suchgeschwindigkeit und Präzision in unserem Open-Source-Benchmark (opens new window), und übertrifft ähnliche Systeme, die in Präzision und Geschwindigkeit hinterherhinken und bis zu 5x günstiger sind. Diese präzise und effiziente gefilterte Suchfunktion ist eine wichtige Grundlage für RAG-Systeme in Produktionsqualität.
Hinweis:
Für weitere Ergebnisse siehe den Vergleichsartikel zu MyScale vs. pgvector und OpenSearch (opens new window).
Wie oben erwähnt, basiert MyScale auf der weit verbreiteten ClickHouse-SQL-Datenbank und unterstützt eine breite Palette von Datenarten und Funktionen (opens new window), wie numerisch, Datum/Uhrzeit, geografisch, JSON, Zeichenkette usw. Dies verbessert die Abfragefähigkeiten für gefilterte Abfragen im Vergleich zu spezialisierten Vektordatenbanken wie Pinecone, Weaviate und Qdrant erheblich.
Darüber hinaus können LLMs SQL sehr gut verarbeiten, sodass sie natürliche Sprache automatisch in SQL WHERE-Bedingungen umwandeln können. Dies bedeutet, dass Benutzer ohne technischen Hintergrund gefilterte Abfragen mit natürlicher Sprache ausführen können, was die Flexibilität und Präzision von RAG-Systemen weiter verbessert. Eine ähnliche Technologie haben wir in der LangChain MyScale Self-Query (opens new window) implementiert, die in Produktionsumgebungen weit verbreitet ist.

# Hinter den Kulissen
Obwohl die gefilterte Vektor-Suche in vielen Szenarien wichtig ist, erfordert die Implementierung präziser und effizienter gefilterter Vektor-Suchen zahlreiche technische Entscheidungen, wie Vorfilterung vs. Nachfilterung, zeilenbasierte vs. spaltenbasierte Speicherung und Graph- vs. Baumalgorithmen (opens new window). Durch Integration von Technologien wie Vorfilterung, spaltenbasierter Speicherung und mehrstufigen Baumgraphalgorithmen hat MyScale eine herausragende Genauigkeit und Geschwindigkeit bei der gefilterten Vektor-Suche erreicht.
# Vorfilterung vs. Nachfilterung
Es gibt zwei Ansätze zur Implementierung der Metadatenfilterung bei der gefilterten Vektor-Suche: Vorfilterung und Nachfilterung.
Bei der Vorfilterung werden zuerst Vektoren ausgewählt, die die Kriterien anhand der Metadaten erfüllen, und dann werden diese Vektoren durchsucht. Der Vorteil dieser Methode besteht darin, dass die Datenbank bei Bedarf die Garantie für k Ergebnisse geben kann, wenn Benutzer die k ähnlichsten Dokumente benötigen.
Bei der Nachfilterung hingegen wird zuerst eine Vektor-Suche durchgeführt, um m Ergebnisse zu erhalten, und dann werden auf diese Ergebnisse Metadatenfilter angewendet. Der Nachteil dieser Methode besteht darin, dass ungewiss ist, wie viele der m Ergebnisse die Kriterien des Metadatenfilters erfüllen, was möglicherweise zu weniger als k endgültigen Ergebnissen führt. Wenn die Vektoren, die die Filterkriterien erfüllen, knapp sind, nimmt die Genauigkeit der Nachfilterung erheblich ab. Das Vektor-Retrieval-Plugin pgvector von PostgreSQL verwendet diesen Ansatz und leidet unter erheblichem Genauigkeitsverlust, wenn das Verhältnis der qualifizierten Daten niedrig ist.
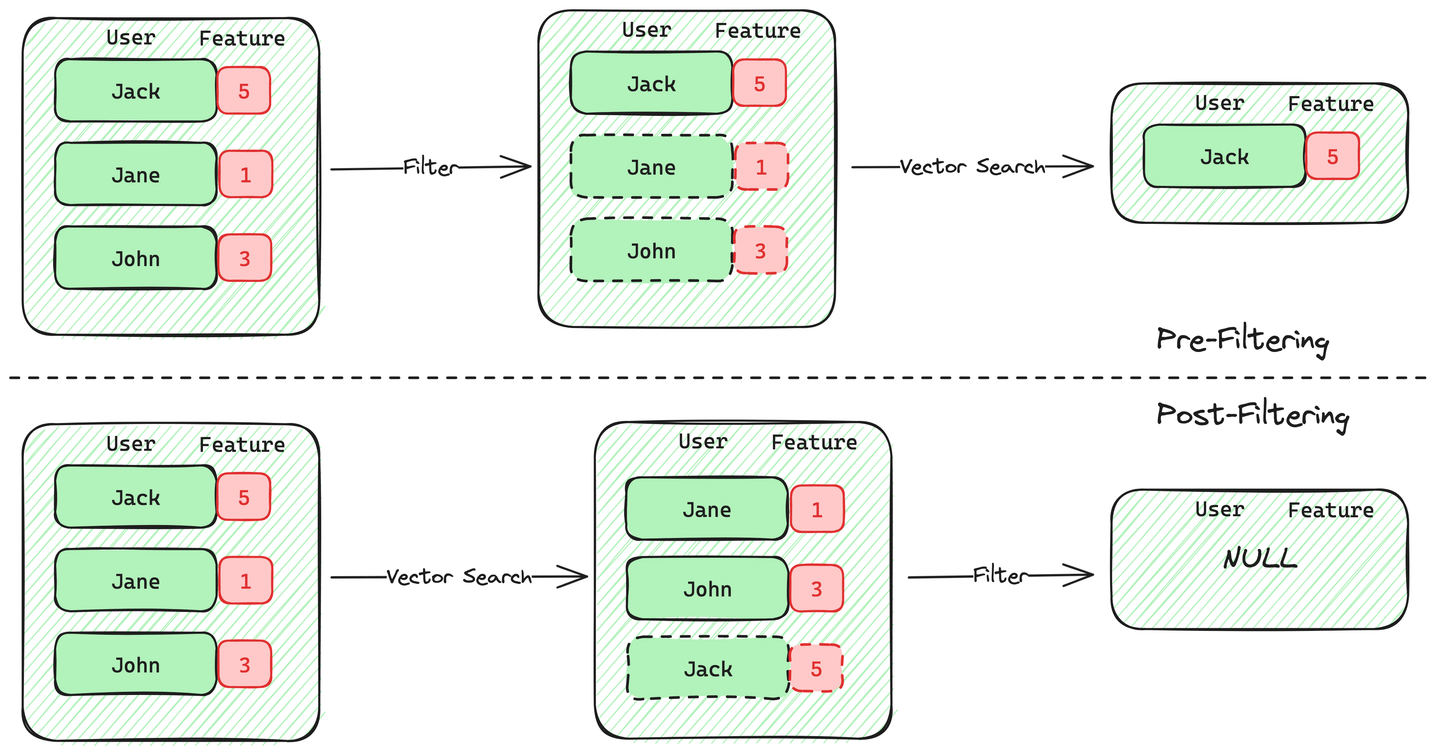
Die Herausforderung bei der Vorfilterung besteht darin, Daten effizient zu filtern und die Sucheffizienz in Vektorindizes aufrechtzuerhalten, wenn die Anzahl der qualifizierten Vektoren gering ist.
Beispielsweise erlebt der weit verbreitete HNSW (Hierarchical Navigable Small World)-Algorithmus einen erheblichen Rückgang der Sucheffektivität, wenn das Filterverhältnis niedrig ist - z.B. bleiben nach der Filterung nur 1% der Vektoren übrig. Um dieses Problem zu lösen, wird in der Branche häufig auf die Brute-Force-Suche zurückgegriffen, wenn das Filterverhältnis unter einen bestimmten Schwellenwert fällt.
Pinecone, Milvus und ElasticSearch verwenden beispielsweise alle diese Methode, aber sie kann die Leistung bei großen Datensätzen erheblich beeinträchtigen. MyScale hingegen gewährleistet bei jedem Filterverhältnis eine hohe Genauigkeit und Effizienz durch die Kombination von hoch effizienter Vorfilterung mit algorithmischen Innovationen.
# Zeilenbasierte vs. Spaltenbasierte Speicherung
Bei der Annahme einer Vorfilterungsstrategie ist die effiziente Durchsuchung von Metadaten für die Abrufleistung entscheidend. Die Speicherung in Datenbanken wird in der Regel als zeilenbasiert oder spaltenbasiert kategorisiert.
Zeilenbasierte Speicherung wird in der Regel in Transaktionsdatenbanken wie MySQL oder PostgreSQL verwendet und ist besonders für Punkt-Lese- und Schreibzugriffe geeignet, insbesondere für Transaktionsverarbeitung. Im Gegensatz dazu sind spaltenbasierte Datenbanken (wie ClickHouse) für die analytische Verarbeitung, insbesondere für das Durchsuchen mehrerer Spalten von Daten, die Stapelverarbeitung von Daten und die komprimierte Speicherung, sehr effizient.
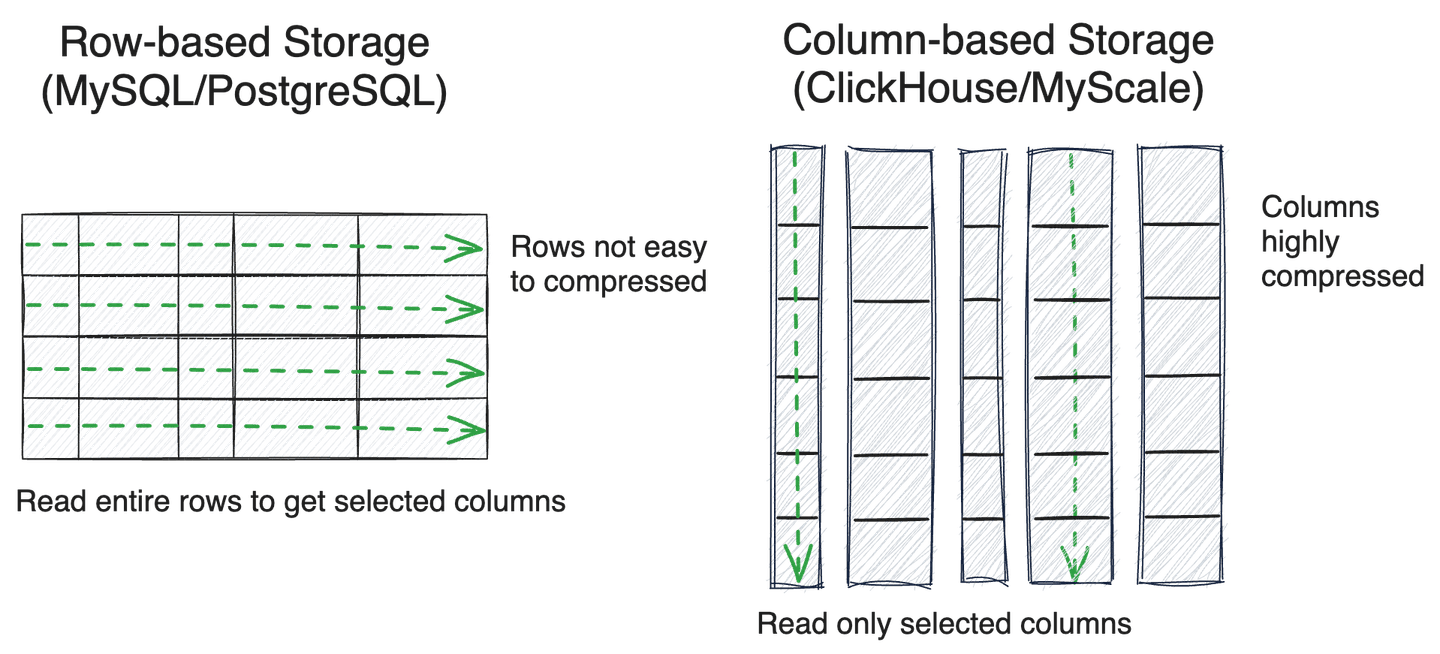
Aufgrund der Notwendigkeit einer effizienten Durchsuchung von Metadaten haben viele spezialisierte Vektordatenbanken wie Milvus und Qdrant ebenfalls die spaltenbasierte Speicherung übernommen. Nach jahrelanger Optimierung von massiven, strukturierten Datenanalyseabfragen haben sich spaltenbasierte SQL-Datenbanken wie ClickHouse - siehe ClickBench (opens new window) für weitere Informationen - noch stärker hervorgetan und verwenden Techniken wie Skip-Indizes und SIMD-Operationen, um die Effizienz der Datenabfrage in vielen praktischen Szenarien erheblich zu verbessern.
Durch umfangreiche Benutzerforschung haben wir festgestellt, dass in KI/LLM-Anwendungen wie RAG weniger Bedarf an kleinen Schreibtransaktionen besteht, aber eine effiziente Datenabfrage und -analyse unerlässlich sind. Daher ist für uns die spaltenbasierte Speicherung eine geeignetere Wahl.
Dies ist ein wesentlicher Grund, warum MyScale sich für die Entwicklung auf ClickHouse entschieden hat. Entsprechend haben Systeme wie pgvector und pgvecto.rs aufgrund der Einschränkungen der zeilenbasierten Speicherung von PostgreSQL Probleme mit der Genauigkeit oder Geschwindigkeit der gefilterten Suche.
Schließlich besteht die größte Herausforderung bei spaltenbasierten Datenbanken darin, dass ihre Mehrspalten-Punkt-Lesezugriffe ineffizient sind - aufgrund der Datenleseverstärkung und des Dekomprimierungsaufwands. Die gute Nachricht ist, dass dies mit Technologien wie dem Caching unkomprimierter Daten behoben werden kann. Es gibt auch viel Raum für Verbesserungen bei der gemeinsamen Abfrage von strukturierten und Vektordaten, wie z.B. die Optimierungen der entspannten Monotonie in vbase (opens new window).
# Zusammenfassung
Durch die Kombination von strukturierten und Vektordaten in einer Abfrage hat die gefilterte Vektor-Suche weitreichende und bedeutende Anwendungen in fortgeschrittenen RAG-Systemen, groß angelegten Multi-User-Systemen und mehr. MyScale, auf der spaltenbasierten ClickHouse-SQL-Datenbank aufgebaut, unterstützt eine breite Palette von Metadatentypen und -funktionen sowie flexible Self-Query-Fähigkeiten.
Durch die Verwendung von Vorfilterung, spaltenbasierter Speicherung und algorithmischen Optimierungen erreicht MyScale eine hohe Genauigkeit und Geschwindigkeit bei der gefilterten Suche bei jedem Filterverhältnis und legt so eine solide Datenbasis für LLM-Anwendungen.
Wenn Sie weitere Gedanken zu gefilterten Suchen haben oder Ihre Ideen teilen möchten, folgen Sie uns bitte auf Twitter (opens new window) und treten Sie unserer Discord (opens new window)-Community bei.



