
Traditionelle Bildklassifikationsmodelle wie Convolutional Neural Networks (CNNs) (opens new window) sind seit Jahren die Grundlage für Aufgaben der Computer Vision (opens new window). Diese Modelle werden durch das Training mit großen, gelabelten Datensätzen betrieben, bei denen jedes Bild mit einem bestimmten Klassenlabel verknüpft ist. In der Regel basieren diese Modelle auf N-Shot-Learning, was bedeutet, dass sie eine große Anzahl von gelabelten Bildern (N Beispiele) für jede Klasse benötigen, um eine hohe Genauigkeit zu erreichen.
Diese traditionellen Modelle haben jedoch mehrere signifikante Herausforderungen. Erstens erfordern sie eine erhebliche Menge an gelabelten Daten, die zeitaufwändig und kostspielig in der Produktion sind. Darüber hinaus haben traditionelle Modelle Schwierigkeiten, effektiv zu generalisieren, insbesondere wenn die Anzahl der Beispiele (N) gering ist.
Darüber hinaus sind diese Modelle in ihrer Fähigkeit, unbekannte Daten zu klassifizieren, begrenzt. Wenn ein Modell nicht auf eine bestimmte Klasse trainiert wurde, ist es unwahrscheinlich, dass es Bilder aus dieser Klasse genau klassifizieren kann. Diese Begrenzung wird besonders problematisch, wenn neue Kategorien häufig auftauchen oder wenn gelabelte Daten knapp sind.
Diese Herausforderungen machen deutlich, dass wir intelligentere Modelle benötigen, die mit weniger mehr leisten können. Hier kommt CLIP ins Spiel. Im Gegensatz zu traditionellen Modellen muss CLIP nicht speziell in jeder Klasse trainiert werden, um sie zu erkennen. Es verwendet einen riesigen Datensatz von Bild-Text-Paaren und kontrastives Lernen, um herauszufinden, was sich auf einem Bild befindet, auch wenn es noch nie zuvor einen solchen Bildtyp gesehen hat. Dies macht CLIP unglaublich nützlich, insbesondere in Situationen, in denen traditionelle Modelle an ihre Grenzen stoßen.
# CLIP
OpenAI hat 2021 CLIP (opens new window) eingeführt, ein Modell, das die Lücke zwischen Bildern und Texten schließt, indem es sie in einem gemeinsamen Vektorraum platziert. Durch den Einsatz von kontrastivem Lernen lernt CLIP, welche Bild-Text-Paare zusammengehören und welche nicht. Diese Fähigkeit ermöglicht es ihm, über verschiedene Klassen hinweg zu generalisieren, auch solche, die es zuvor noch nicht gesehen hat. Dadurch ist CLIP äußerst effektiv bei der Zero-Shot-Klassifikation, bei der es neue Kategorien basierend ausschließlich auf Textbeschreibungen genau identifizieren kann.
- Zero-Shot-Klassifikation (opens new window): Bei diesem Ansatz kann das Modell neue Kategorien klassifizieren, ohne während des Trainings gelabelte Beispiele zu benötigen. Es wird "Zero-Shot" genannt, weil es keine Trainingsdaten benötigt und sich ausschließlich auf Textbeschreibungen zur Vorhersage stützt.
- N-Shot-Klassifikation (opens new window): In diesem Fall benötigt das Modell N gelabelte Beispiele pro Kategorie, um zu lernen, wie sie korrekt klassifiziert werden. Das "N" repräsentiert die Anzahl der Beispiele, die das Modell sehen muss, um jede Kategorie zu verstehen.
# Wie CLIP für Zero-Shot-Klassifikation verwendet wird
Die Architektur von CLIP ist so konzipiert, dass sie die Zero-Shot-Klassifikation auf einfache, aber leistungsstarke Weise bewältigt. Im Kern von CLIP befinden sich zwei Encoder: einer für Bilder und einer für Texte. Diese Encoder wandeln Eingangsbilder und Textbeschreibungen in hochdimensionale Vektoren oder Embeddings in einem gemeinsamen Vektorraum um.
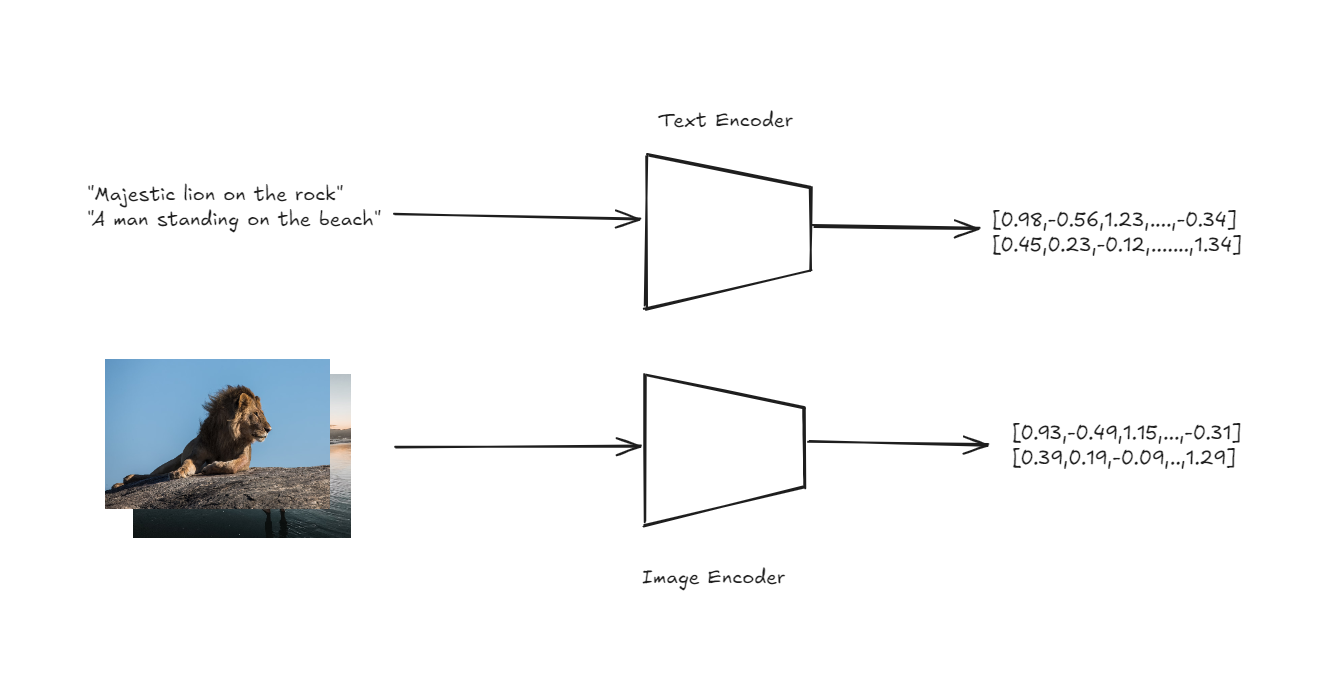
Text- und Bild-Encoder zur Gewinnung von Embeddings
Die entscheidende Innovation besteht darin, dass sowohl Bilder als auch Texte im selben Raum repräsentiert werden, was einen direkten Vergleich zwischen den beiden Modalitäten ermöglicht.
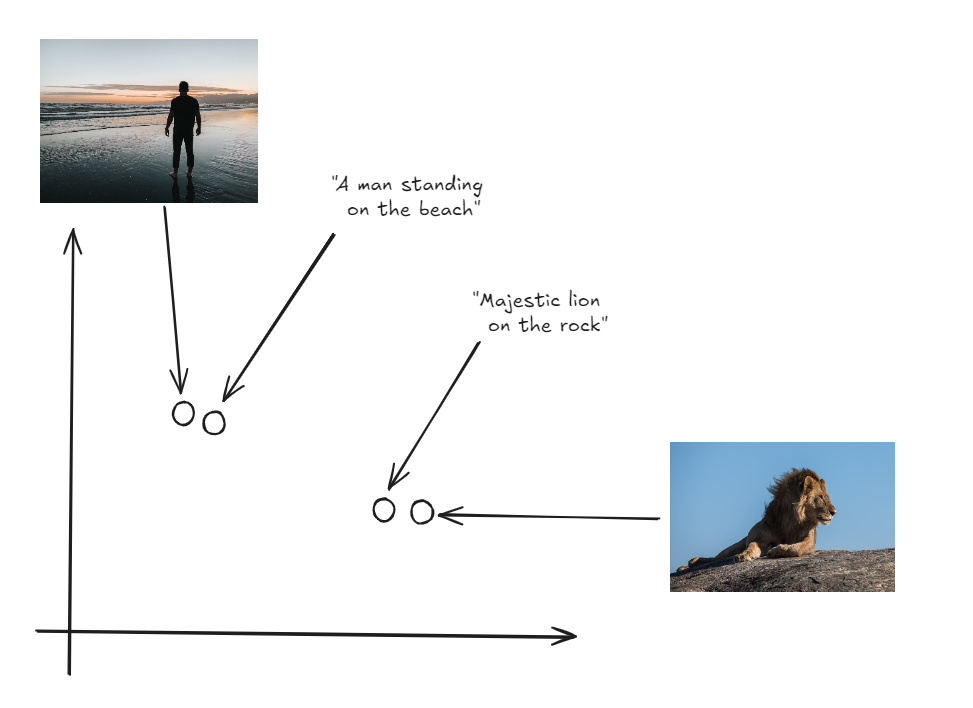
Sowohl Bilder als auch Labels im selben Vektorraum
Um die Zero-Shot-Klassifikation durchzuführen, generiert CLIP zunächst Embeddings für eine Reihe von Textbeschreibungen, die verschiedenen Klassen entsprechen (z.B. "ein Foto einer Katze", "ein Foto eines Hundes"). Anschließend wird ein Embedding für das Eingangsbild generiert. Das Modell berechnet die Kosinus-Ähnlichkeit zwischen dem Bild-Embedding und jedem der Text-Embeddings. Die Kosinus-Ähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren und gibt an, wie eng sie ausgerichtet sind. Die Textbeschreibung mit der höchsten Kosinus-Ähnlichkeit zum Bild-Embedding wird als vorhergesagtes Label ausgewählt. Dieser Prozess ermöglicht es CLIP, Bilder in Kategorien einzuteilen, die es während des Trainings nie explizit gesehen hat, und sich ausschließlich auf die in den Textbeschreibungen erfassten semantischen Informationen zu verlassen.
Hinweis: Der gleiche Ansatz kann verwendet werden, um eine Bildsuchanwendung mit CLIP (opens new window) zu erstellen.
# Praktisches Beispiel
Als wir das CLIP-Modell auf den Imagenette-Datensatz für die Zero-Shot-Klassifikation getestet haben, hat es außergewöhnlich gut abgeschnitten und eine Genauigkeit von über 99% erreicht. Dieses Ergebnis zeigt, dass CLIP die Leistung traditioneller Bildklassifikationsmodelle erreichen oder sogar übertreffen kann.
Mit solch beeindruckenden Ergebnissen ist klar, dass CLIP eine leistungsstarke Alternative für Bildklassifikationsaufgaben bietet. Nun wollen wir genauer untersuchen, wie wir dieses Modell in einer praktischen Situation implementieren können.
Hinweis: Sie können das vollständige Notebook auf Github (opens new window) finden.
# Installation der erforderlichen Bibliotheken
Zunächst müssen wir die erforderlichen Bibliotheken installieren. Verwenden Sie den folgenden Befehl, um die erforderlichen Pakete zu installieren:
pip install datasets transformers
Die Bibliothek datasets von Hugging Face bietet Zugriff auf eine Vielzahl von sofort einsatzbereiten Datensätzen, die für maschinelles Lernen sehr hilfreich sind.
Die Bibliothek transformers, ebenfalls von Hugging Face, ist Ihre Anlaufstelle für die Verwendung leistungsstarker vortrainierter Modelle. In unserem Fall verwenden wir sie, um das CLIP-Modell zu laden und damit zu arbeiten.
# Importieren der Abhängigkeiten
Nachdem die Bibliotheken installiert sind, können wir die erforderlichen Abhängigkeiten importieren. Dazu gehören wesentliche Module zum Umgang mit Daten, zur Arbeit mit dem CLIP-Modell und zur Visualisierung von Ergebnissen.
import torch
import numpy as np
from datasets import load_dataset
from tqdm.auto import tqdm
from transformers import AutoProcessor, CLIPModel, AutoTokenizer
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
Wir werden matplotlib und seaborn verwenden, um Visualisierungen zu erstellen und anzuzeigen, die uns helfen, unsere Daten in diesem Projekt besser zu interpretieren und zu präsentieren.
# Laden des CLIP-Modells
Für die Zero-Shot-Klassifikation laden wir das CLIP-Modell. Das Modell wird auf die GPU geladen, sofern verfügbar, andernfalls wird es auf die CPU zurückfallen. Wir laden auch den zugehörigen Prozessor und den Tokenizer.
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14")
Der AutoProcessor ist dafür verantwortlich, sowohl Bild- als auch Textdaten so zu verarbeiten, dass sie mit dem CLIP-Modell kompatibel sind. Der AutoTokenizer wandelt Text in ein Format um, das vom Modell verstanden werden kann, und generiert die erforderlichen Tokens für die weitere Verarbeitung.
Hinweis: Für diesen Blog nutzen wir die kostenlose GPU, die in Google Colab verfügbar ist, was die Verarbeitungszeit erheblich verkürzt.
# Laden des Imagenette-Datensatzes
Wir laden den Imagenette-Datensatz, der ein kleinerer Teil des größeren ImageNet-Datensatzes ist. Dieser Teil enthält 10 Klassen, was ihn für schnelle Experimente besser handhabbar macht:
imagenette = load_dataset(
'frgfm/imagenette',
'320px',
split='validation',
revision="4d512db"
)
Die Funktion load_dataset aus der datasets-Bibliothek von Hugging Face wird verwendet, um den Imagenette-Datensatz herunterzuladen und vorzubereiten. Diese Version des Datensatzes besteht aus Bildern, die auf 320 Pixel verkleinert wurden, und ist in einen Validierungssatz aufgeteilt, um die Leistung des Modells zu bewerten.
# Analyse des Datensatzes
Wir beginnen damit, die im Datensatz vorhandenen Klassenlabels auszugeben, um zu verstehen, mit welchen Kategorien wir arbeiten:
labels = imagenette.features["label"].names
print(f"Klassenlabels im Datensatz: {labels}")
Der obige Code gibt das folgende Ergebnis aus:
Klassenlabels im Datensatz: ['tench', 'English springer', 'cassette player', 'chain saw', 'church', 'French horn', 'garbage truck', 'gas pump', 'golf ball', 'parachute']
# Visualisierung der Klassenverteilung
Um die Verteilung der Bilder auf verschiedene Klassen besser zu verstehen, erstellen wir ein Balkendiagramm.
plt.figure(figsize=(10, 6))
sns.barplot(x=labels, y=class_counts, palette='viridis')
plt.xticks(rotation=45, ha='right')
plt.title('Klassenverteilung im Imagenette-Datensatz')
plt.xlabel('Klassenlabels')
plt.ylabel('Anzahl der Bilder')
plt.show()
Der obige Code erzeugt ein Balkendiagramm wie dieses: Das Diagramm zeigt, dass die Klassenverteilung im Imagenette-Datensatz ungleichmäßig ist. Diese Ungleichgewicht ist für uns jedoch kein Problem, da wir den Datensatz nicht zum Training verwenden, sondern für die Zero-Shot-Klassifikation.
# Auswahl und Verarbeitung von Bildern
Anschließend durchlaufen wir den Datensatz, um Bilder und die entsprechenden Labels auszuwählen. Dieser Schritt bereitet die Daten für die anschließende Generierung der Embeddings vor.
selected_images = []
selected_labels = []
for example in tqdm(imagenette):
label = example["label"]
selected_images.append(example["image"])
selected_labels.append(label)
# Vorbereitung der Texteingaben
Für die Zero-Shot-Klassifikation wandeln wir die Klassenlabels mit dem Tokenizer in Texteingaben um. Diese Eingaben werden dem Modell zugeführt, um Text-Embeddings zu generieren.
text_inputs = tokenizer([f"ein Foto von {c}" for c in labels], return_tensors="pt", padding=True).to(device)
Der Grund für die Formatierung der Zeichenketten als "ein Foto von {label}" besteht darin, dass das CLIP-Modell auf ähnlichen Text-Bild-Paaren trainiert wurde. Diese Formulierung hilft dem Modell, den Text besser mit den entsprechenden Bildern abzugleichen.
# Generierung der Text-Embeddings
Mit dem CLIP-Modell generieren wir Text-Embeddings für jedes Klassenlabel. Diese Embeddings werden später mit den Bild-Embeddings verglichen, um die Bilder zu klassifizieren.
with torch.no_grad():
label_emb = model.get_text_features(input_ids=text_inputs['input_ids'], attention_mask=text_inputs['attention_mask'])
label_emb = label_emb.cpu().numpy()
# Stapelverarbeitung und Generierung von Bild-Embeddings
Wir verarbeiten die ausgewählten Bilder stapelweise, um Bild-Embeddings zu generieren. Diese Embeddings werden dann mit den Text-Embeddings verglichen, um Ähnlichkeitswerte zu berechnen.
preds = []
batch_size = 50
for i in tqdm(range(0, len(selected_images), batch_size)):
i_end = min(i + batch_size, len(selected_images))
images = processor(
images=selected_images[i:i_end],
return_tensors='pt'
)['pixel_values'].to(device)
with torch.no_grad():
img_emb = model.get_image_features(images)
img_emb = img_emb.cpu().numpy()
# Berechnung der Ähnlichkeitswerte zwischen Bild-Embeddings und Text-Embeddings
scores = np.dot(img_emb, label_emb.T)
preds.extend(np.argmax(scores, axis=1))
Nun haben wir eine Reihe von vorhergesagten Labels für unsere ausgewählten Bilder. Als nächstes werden wir untersuchen, wie gut das Modell abgeschnitten hat und welche Erkenntnisse diese Vorhersagen bieten.
# Berechnung und Anzeige der Genauigkeit
Schließlich berechnen wir die Genauigkeit der Zero-Shot-Klassifikation, indem wir die vorhergesagten Labels mit den tatsächlichen Labels vergleichen.
accuracy = accuracy_score(selected_labels, preds)
print(f"Zero-Shot-Klassifikationsgenauigkeit auf Imagenette: {accuracy * 100:.2f}%")
Der obige Code gibt folgende Ausgabe aus:

Wie wir sehen können, hat das CLIP-Modell auf dem Imagenette-Datensatz sehr gut abgeschnitten und eine hohe Genauigkeit erreicht. Diese starke Leistung ist auf die hochwertigen Bilder und die vergleichsweise geringe Anzahl von Klassen im Datensatz zurückzuführen, was es dem Modell erleichtert, die Bilder mit ihren entsprechenden Textbeschreibungen in Einklang zu bringen. CLIP wurde auf einem riesigen Datensatz von 400 Millionen Bild-Text-Paaren trainiert, in der Regel mit Bildern, die auf etwa 224x224 Pixel verkleinert wurden, was ihm geholfen hat, über eine breite Palette von visuellen und textuellen Daten zu generalisieren.
Wenn jedoch Bilder mit niedrigerer Auflösung oder Datensätze mit mehr Klassen verwendet werden, variiert die Leistung des Modells. Wenn wir zum Beispiel das Modell auf den CIFAR-10-Datensatz mit 32x32 Pixel Bildern getestet haben, sank die Genauigkeit auf 94,76%. Ebenso zeigte der Test auf dem SaulLu/Caltech-101-Datensatz mit 102 Klassen eine geringere Genauigkeit von 81,21% aufgrund der höheren Anzahl von Klassen und der unterschiedlichen Bildqualität.
Hinweis: Hier finden Sie die vollständigen Notebooks mit Ergebnissen für SaulLu/Caltech-101 (opens new window) und CIFAR-10 (opens new window).

Trotz dieser Herausforderungen bleibt CLIP eine ausgezeichnete Wahl, insbesondere wenn Sie über begrenzte oder keine gelabelten Trainingsdaten verfügen. Seine Fähigkeit zur Zero-Shot-Klassifikation und zur Bewältigung verschiedener Aufgaben ohne umfangreiches Neutraining macht es zu einem wertvollen Werkzeug in Situationen, in denen traditionelle Modelle an ihre Grenzen stoßen.



