
Daten sind heute das Herzstück nahezu jeder Organisation. Da die Datenmengen weiterhin explodieren, müssen Unternehmen Möglichkeiten finden, ihre Daten effektiv zu speichern, zu verarbeiten und zu analysieren. Dies hat zu einem Boom auf dem Datenbankmarkt geführt, wobei Unternehmen sowohl traditionelle SQL-Datenbanken als auch neuere Vektordatenbanken nutzen, um unterschiedliche Aufgaben zu erledigen.
Jede Art von Datenbank hat jedoch ihre Vor- und Nachteile. Traditionelle SQL-Datenbanken bieten Konsistenz, Genauigkeit und Benutzerfreundlichkeit für strukturierte Daten, während Vektordatenbanken auf Geschwindigkeit und Skalierbarkeit optimiert sind, insbesondere bei großen Mengen unstrukturierter Daten. Aber was ist, wenn Sie nicht wählen müssen? Was ist, wenn es eine Datenbank gibt, die Ihnen das Beste aus beiden Welten bietet?
In diesem Blog werfen wir einen Blick auf MyScale, von den Grundlagen wie Tabellenerstellung und Definition von Indizes bis zur fortgeschrittenen SQL-Vektorsuche. Am Ende vergleichen wir MyScale auch mit anderen Datenbanken auf dem Markt und sehen, warum MyScale besser ist. Also, lasst uns anfangen.
# Was ist MyScale
MyScale (opens new window) ist eine cloudbasierte SQL-Vektordatenbank, die speziell für die Verwaltung großer Datenmengen für KI-Anwendungen entwickelt und optimiert wurde. Sie basiert auf ClickHouse (opens new window) (einer SQL-Datenbank) und kombiniert die Möglichkeit der Vektorähnlichkeitssuche mit vollständiger SQL-Unterstützung. Mit einer einzigen Schnittstelle kann eine SQL-Abfrage gleichzeitig und schnell verschiedene Datenmodalitäten nutzen, um komplexe KI-Anforderungen zu bewältigen, die sonst mehr Schritte und Zeit erfordern würden.
Im Gegensatz zu spezialisierten Vektordatenbanken kombiniert MyScale Vektorsuchalgorithmen harmonisch mit strukturierten Datenbanken und ermöglicht so die Verwaltung von Vektoren und strukturierten Daten in derselben Datenbank. Diese Integration bietet Vorteile wie vereinfachte Kommunikation, anpassbare Metadatenfilterung, Unterstützung für SQL- und Vektorverbundabfragen sowie Kompatibilität mit ausgereiften Tools, die häufig mit vielseitigen Datenbanken für allgemeine Zwecke verbunden sind. MyScale bietet im Wesentlichen eine einheitliche Lösung, die einen ganzheitlichen, effizienten und leicht zu erlernenden Ansatz zur Bewältigung der Komplexität des KI-Datenmanagements bietet.
# Wie man einen Cluster in MyScale startet
Bevor Sie MyScale in Ihrem Projekt verwenden können, müssen Sie zunächst ein Konto erstellen und einen Cluster erstellen, der Ihre Daten speichert. Hier zeigen wir Ihnen die Schritte:
- Melden Sie sich für ein MyScale-Konto unter myscale.com (opens new window) an oder registrieren Sie sich.
- Sobald das Konto erstellt ist, klicken Sie auf die Schaltfläche "+ Neuer Cluster" auf der rechten Seite der Seite.
- Geben Sie den Namen des Clusters ein und klicken Sie auf die Schaltfläche "Weiter".
- Warten Sie, bis der Cluster erstellt ist. Dies dauert einige Sekunden.
Sobald der Cluster erstellt ist, sehen Sie den Text "Cluster erfolgreich gestartet" auf der Popup-Schaltfläche.
Hinweis:
Nachdem der Cluster erstellt wurde, haben Sie auch die Möglichkeit, vorgefertigte Beispieldaten in Ihren Cluster zu importieren, wenn Sie keine eigenen Daten haben. In diesem Tutorial laden wir jedoch unsere eigenen Daten.
Nun ist der nächste Schritt, die Arbeitsumgebung einzurichten und auf den laufenden Cluster zuzugreifen. Machen wir das.
# Einrichten der Umgebung
Um MyScale in Ihrer Umgebung zu verwenden, benötigen Sie:
- Python: MyScale bietet eine Python-Client-Bibliothek zum Interagieren mit der Datenbank, daher benötigen Sie Python auf Ihrem System installiert. Wenn Sie Python nicht auf Ihrem PC installiert haben, können Sie es von der offiziellen Python-Website (opens new window) herunterladen.
- MyScale Python-Client: Installieren Sie das ClickHouse-Client (opens new window) Paket mit
pip:
pip install clickhouse-connect
Sobald die Ausführung abgeschlossen ist, können Sie die Installation bestätigen, indem Sie den folgenden Befehl eingeben:
pip show clickhouse-connect
Wenn die Bibliothek installiert ist, sehen Sie Informationen über das Paket, andernfalls sehen Sie einen Fehler.
# Verbindung mit dem Cluster
Der nächste Schritt besteht darin, die Python-App mit dem Cluster zu verbinden. Für die Verbindung benötigen wir die folgenden Details:
- Cluster-Host
- Benutzername
- Passwort
Um die Details zu erhalten, können Sie zu Ihrem MyScale-Profil zurückkehren, über die drei vertikal ausgerichteten Punkte unter dem Text "Aktionen" schweben und auf "Verbindungsdetails" klicken.
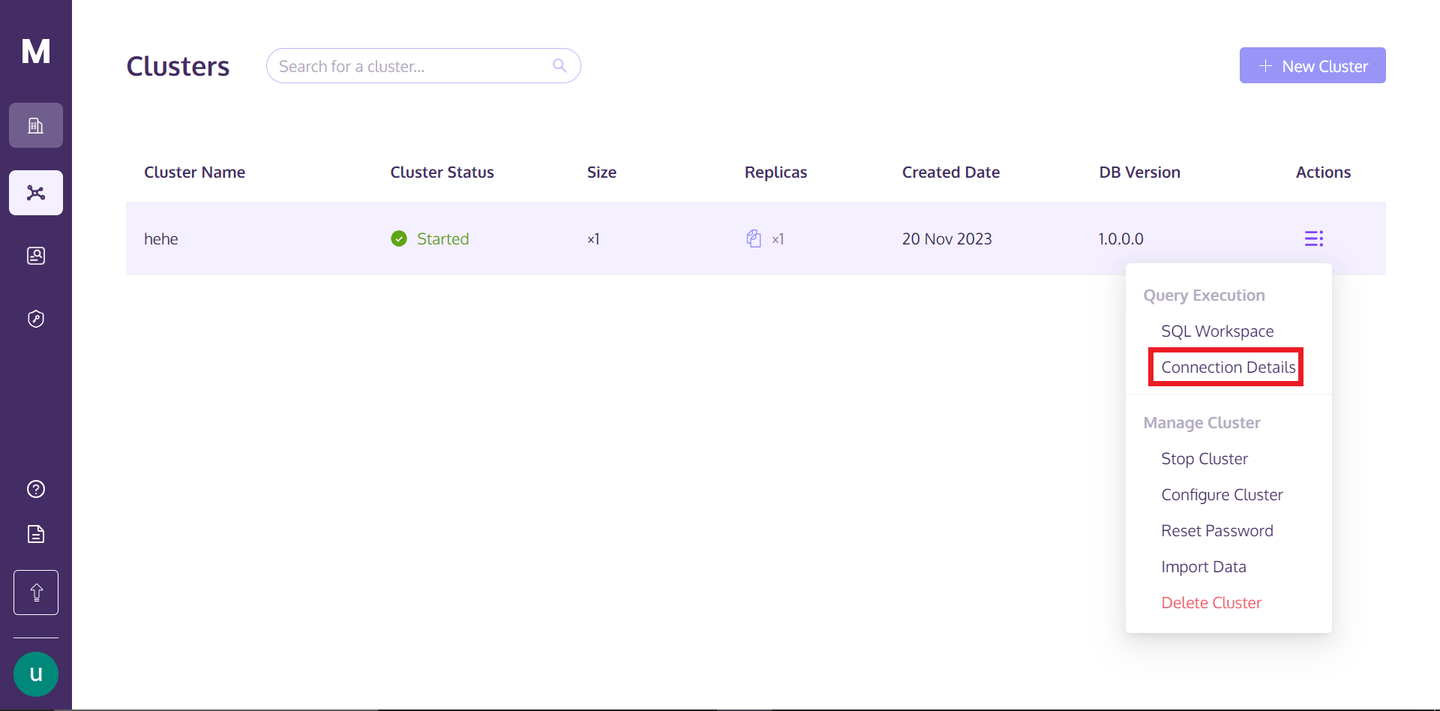
Sobald Sie auf "Verbindungsdetails" klicken, sehen Sie folgendes Feld:
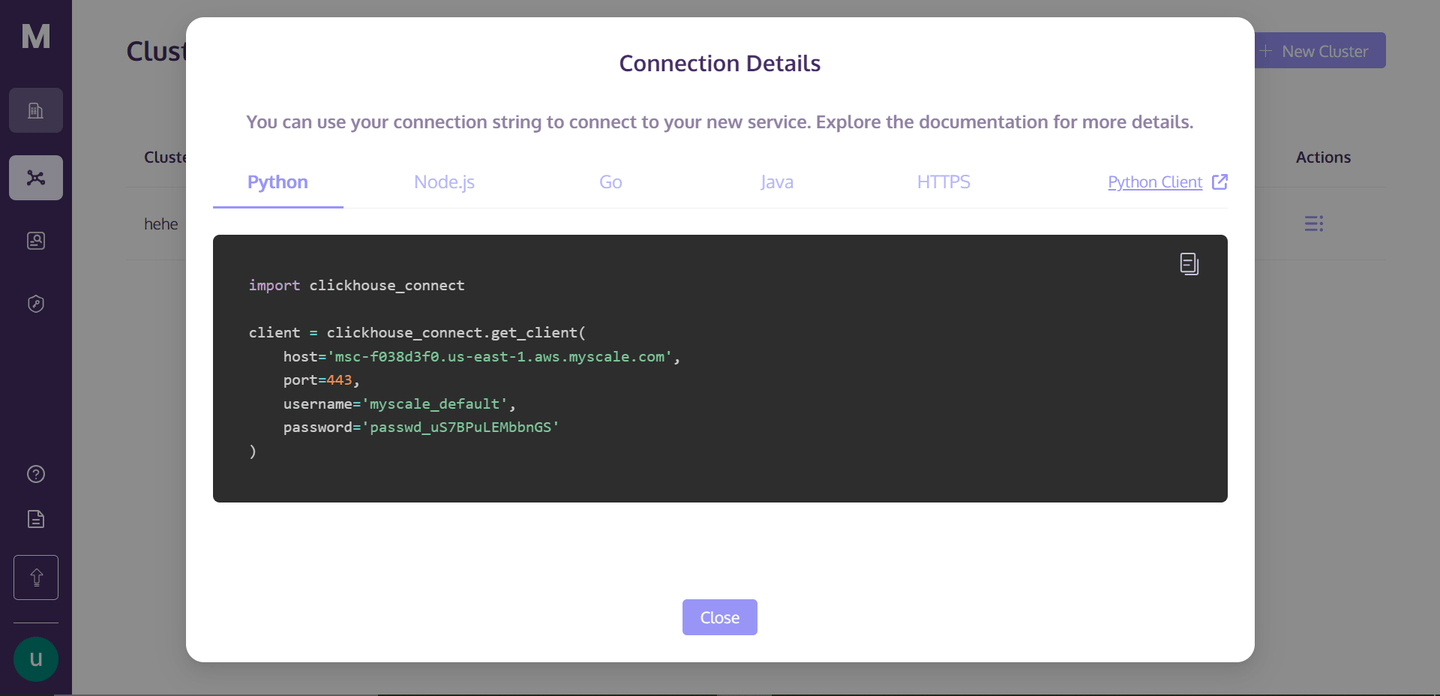
Dies sind die Verbindungsdetails, die Sie benötigen, um eine Verbindung mit dem Cluster herzustellen. Erstellen Sie einfach eine Python-Notebook-Datei in Ihrem Verzeichnis, kopieren Sie den folgenden Code in Ihre Notebook-Zelle und führen Sie die Zelle aus. Es wird eine Verbindung mit Ihrem Cluster herstellen.
# Erstellen einer Datenbank
Der nächste Schritt besteht darin, eine Datenbank auf dem Cluster zu erstellen. Sehen wir uns an, wie Sie dies tun können:
client.command("""
CREATE DATABASE IF NOT EXISTS getStart;
""")
Dieser Befehl überprüft zunächst, ob die Datenbank mit demselben Namen vorhanden ist. Wenn nicht, wird eine Datenbank mit dem Namen getStart erstellt.
# Erstellen Sie eine Tabelle mit MyScale
Die grundlegende Syntax zum Erstellen einer Tabelle in MyScale lautet wie folgt:
CREATE TABLE [IF NOT EXISTS] db_name.table_name
(
column_name1 data_type [options],
column_name2 data_type [options],
...
)
ENGINE = engine_type
[ORDER BY expression]
[PRIMARY KEY expression];
In der obigen Syntax können Sie db_name und table_name entsprechend Ihrer Wahl ersetzen. Innerhalb der Klammern definieren Sie die Spalten Ihrer Tabelle. Jede Spalte (column_name1, column_name2, usw.) wird mit ihrem jeweiligen Datentyp (data_type) definiert, und Sie können optional zusätzliche Spaltenoptionen ([options]) wie Standardwerte oder Einschränkungen angeben.
Hinweis:
Wir schauen uns nur an, wie Tabellen in MyScale erstellt werden. In einem späteren Schritt werden wir eine tatsächliche Tabelle gemäß unseren Daten erstellen.
Die Klausel ENGINE = engine_type ist entscheidend für die Bestimmung der Datenspeicherung und -verarbeitung. Sie können die ORDER BY expression angeben, die bestimmt, wie die Daten physisch in der Tabelle gespeichert werden. Der PRIMARY KEY expression wird verwendet, um die Effizienz der Datenabfrage zu verbessern. Im Gegensatz zu traditionellen SQL-Datenbanken erzwingt der Primärschlüssel in ClickHouse keine Eindeutigkeit, sondern wird als Werkzeug zur Leistungsoptimierung verwendet, um die Abfrageverarbeitung zu beschleunigen.
# Importieren Sie Daten für eine Tabelle und erstellen Sie einen Index
Machen Sie sich mit dem Importieren eines Datensatzes vertraut und lernen Sie dann, eine Spalte gegen den Datensatz zu erstellen.
import pandas as pd
# URL of the data
url = 'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv'
# Reading the data directly into a pandas DataFrame
data = pd.read_csv(url)
Dadurch wird der Datensatz von der angegebenen URL heruntergeladen und als DataFrame gespeichert. Die Daten sollten wie folgt aussehen:
| id | data | date | label |
|-------|---------------------------------------------------|------------|----------|
| 0 | [0,0,1,8,7,3,2,5,0,0,3,5,7,11,31,13,0,0,0,... | 2030-09-26 | person |
| 1 | [65,35,8,0,0,0,1,63,48,27,31,19,16,34,96,114,3... | 1996-06-22 | building |
| 2 | [0,0,0,0,0,0,0,4,1,15,0,0,0,0,49,27,0,0,0,... | 1975-10-07 | animal |
| 3 | [3,9,45,22,28,11,4,3,77,10,4,1,1,4,3,11,23,0,... | 2024-08-11 | animal |
| 4 | [6,4,3,7,80,122,62,19,2,0,0,0,32,60,10,19,4,0,... | 1970-01-31 | animal |
| ... | ... | ... | ... |
| 99995 | [9,69,14,0,0,0,1,24,109,33,2,0,1,6,13,12,41,... | 1990-06-24 | animal |
| 99996 | [29,31,1,1,0,0,2,8,8,3,2,19,19,41,20,8,5,0,0,6... | 1987-04-11 | person |
| 99997 | [0,1,116,99,2,0,0,0,0,2,97,117,6,0,5,2,101,86,... | 2012-12-15 | person |
| 99998 | [0,20,120,67,76,12,0,0,8,63,120,55,12,0,0,0,... | 1999-03-05 | building |
| 99999 | [48,124,18,0,0,1,6,13,14,70,78,3,0,0,9,15,49,4... | 1972-04-20 | building |
Der nächste Schritt besteht darin, eine tatsächliche Tabelle im MyScale-Cluster zu erstellen und diese Daten zu speichern. Lassen Sie uns das tun.
client.command("""
CREATE TABLE getStart.First_Table (
id UInt32,
data Array(Float32),
date Date,
label String,
CONSTRAINT check_data_length CHECK length(data) = 128
) ENGINE = MergeTree()
ORDER BY id
""")
Der obige Befehl erstellt eine Tabelle mit dem Namen First_Table. Hier werden auch die Spaltennamen mit den Datentypen angegeben. Der Grund für die Wahl der Einschränkung besteht darin, dass wir möchten, dass die Vektoren der Daten in der Spalte data genau gleich sind, da wir später eine Vektorsuche auf dieser Spalte anwenden werden.
# Daten in die definierte Tabelle einfügen
Nach dem Erstellungsprozess der Tabelle ist der nächste Schritt, die Daten in die Tabelle einzufügen. Wir werden also die Daten einfügen, die wir zuvor heruntergeladen haben.
# Convert the data vectors to float, so that it can meet the defined datatype of the column
data['data'] = data['data'].apply(lambda x: [float(i) for i in ast.literal_eval(x)])
# Convert the 'date' column to the 'YYYY-MM-DD' string format
data['date'] = pd.to_datetime(data['date']).dt.date
# Define batch size and insert data in batches
batch_size = 1000 # Adjust based on your needs
num_batches = len(data) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = data[start_idx:end_idx]
client.insert("getStart.First_Table", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
Der obige Code ändert die Datentypen einiger Spalten entsprechend der definierten Tabelle. Wir fügen die Daten in Form von Batches aufgrund des großen Datenvolumens ein. Daher erstellen wir Batches von 1000.
# Erstellen Sie einen Vektorindex
Der nächste Schritt besteht darin, einen Vektorindex zu erstellen. Schauen wir uns an, wie das gemacht wird.
client.command("""
ALTER TABLE getStart.First_Table
ADD VECTOR INDEX vector_index data
TYPE MSTG
""")
Hinweis:
Die Zeit für die Erstellung des Vektorindex hängt von den Daten in Ihrer Tabelle ab.
Der MSTG-Vektorindex wurde von MyScale intern erstellt und hat seine Konkurrenten in Bezug auf Geschwindigkeit, Genauigkeit und Kosteneffizienz bei weitem übertroffen.
Um zu überprüfen, ob der Vektorindex erfolgreich erstellt wurde, verwenden wir den folgenden Befehl:
get_index_status="SELECT status FROM system.vector_indices WHERE table='First_Table'"
print(f"Der Status des Index ist {client.command(get_index_status)}")
Die Ausgabe des Codes sollte "Der Status des Index ist Built" sein. Das Wort "Built" bedeutet, dass der Index aktiv und erfolgreich erstellt wurde.
Hinweis:
Derzeit erlaubt MyScale nur die Erstellung eines Index pro Tabelle. In Zukunft wird es jedoch möglich sein, mehrere Indizes in einer Tabelle zu erstellen.
# Schreiben Sie verschiedene Arten von SQL-Abfragen mit MyScale
Mit MyScale können Sie verschiedene Arten von Abfragen von den Grundlagen bis zu komplexen Abfragen schreiben. Beginnen wir mit einer sehr einfachen Abfrage.
result=client.query("SELECT * FROM getStart.First_Table ORDER BY date DESC LIMIT 1")
for row in result.named_results():
print(row["id"], row["date"], row["label"],row["data"])
Sie können auch die nächsten Nachbarn einer Entität anhand von Ähnlichkeitswerten aus Vektoren finden. Nehmen wir das extrahierte Ergebnis und ermitteln seine nächsten Nachbarn:
results = client.query(f"""
SELECT id, date, label,
distance(data, {result.first_item["data"]}) as dist FROM getStart.First_Table ORDER BY dist LIMIT 10
""")
for row in results.named_results():
print(row["id"], row["date"], row["label"])
Hinweis:
Die Methode first_item gibt uns das erste Element aus dem Ergebnisarray.
Dies sollte die 10 nächsten Nachbarn des angegebenen Eintrags ausgeben.
# Schreiben Sie natürlichsprachliche Abfragen mit MyScale
Sie können MyScale auch mit natürlichsprachlichen Abfragen abfragen, aber dafür werden wir eine andere Tabelle mit neuen Daten und Merkmalen aus neuronalen Netzwerken erstellen.
Bevor wir die Tabelle erstellen, laden wir die Daten. Die Originaldatei kann hier (opens new window) heruntergeladen werden.
with open('/`../../modules/state_of_the_union.txt`', 'r', encoding='utf-8') as f:
texts = [line.strip() for line in f if line.strip()]
Dieser Befehl lädt die Textdatei und teilt sie in separate Dokumente auf. Um diese Textdokumente in Vektor-Embeddings zu transformieren, verwenden wir die OpenAI API. Um dies zu installieren, öffnen Sie Ihr Terminal und geben Sie den folgenden Befehl ein:
pip install openai
Sobald die Installation abgeschlossen ist, können Sie Ihr Embeddings-Modell einrichten und die Embeddings abrufen:
import os
# Import OPENAI
import openai
# Import pandas
import pandas as pd
# Set the environment variable for OPENAI API Key
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
# Get the embedding vectors of the documents
response = openai.embeddings.create(
input = texts,
model = 'text-embedding-ada-002')
# The code below creates a dataframe. We will insert this dataframe directly to the table
embeddings_data = []
for i in range(len(response.data)):
embeddings_data.append({'id': i, 'data': response.data[i].embedding, 'content': texts[i]})
# Convert to Pandas DataFrame
df_embeddings = pd.DataFrame(embeddings_data)
Der obige Code wandelt die Textdokumente in Embeddings um und erstellt dann ein DataFrame, das in eine Tabelle eingefügt wird. Nun gehen wir zur Erstellung der Tabelle über.
client.command("""
CREATE TABLE getStart.natural_language (
id UInt32,
content String,
data Array(Float32),
CONSTRAINT check_data_length CHECK length(data) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
Der nächste Schritt besteht darin, die Daten in die Tabelle einzufügen.
# Set the batch size to 20
batch_size = 20
# Find the number of batches
num_batches = len(df_embeddings) // batch_size
# Insert the data in the form of batches
for i in range(num_batches + 1):
# Define the starting point for each batch
start_idx = i * batch_size
# Define the last index for each batch
end_idx = min(start_idx + batch_size, len(df_embeddings))
# Get the batch from the main DataFrame
batch_data = df_embeddings[start_idx:end_idx]
# Insert the data
if not batch_data.empty:
client.insert("getStart.natural_language",
batch_data.to_records(index=False).tolist(),
column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches + 1} inserted.")
Der Daten-Einfügeprozess kann je nach Größe der Daten einige Zeit in Anspruch nehmen, aber Sie können den Fortschritt wie folgt überwachen. Nun gehen wir zur Erstellung des Index für unsere Tabelle über.
client.command("""
ALTER TABLE getStart.natural_language
ADD VECTOR INDEX vector_index_new data
TYPE MSTG
""")
Sobald der Index erstellt wurde, können Sie mit Abfragen beginnen.
# Convert the query to vector embeddigs
response = openai.embeddings.create(
# Write your query in the input parameter
input = 'What did the president say about Ketanji Brown Jackson?',
model = 'text-embedding-ada-002'
)
# Get the results
results = client.query(f"""
SELECT id,content,
distance(data, {list(response.data[0].embedding)}) as dist FROM getStart.natural_language ORDER BY dist LIMIT 5
""")
for row in results.named_results():
print(row["id"] ,row["content"], row["dist"])
Es sollte die folgenden Ergebnisse ausgeben:
| ID | Text | Score |
| --- | ---------------------------------------------------------------------------------------------------------------- | ------------------- |
| 269 | And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson... | 0.33893799781799316 |
| 331 | The Cancer Moonshot that President Obama asked me to lead six years ago. | 0.4131550192832947 |
| 80 | Vice President Harris and I ran for office with a new economic vision for America. | 0.4235861897468567 |
| 328 | This is personal to me and Jill, to Kamala, and to so many of you. | 0.42732131481170654 |
| 0 | Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet... | 0.427462637424469 |
Dies sind nur einige Beispiele für Abfragen. Sie können so viele komplexe Abfragen schreiben, wie Sie möchten, je nach Ihren eigenen Bedürfnissen und Projekten.

# MyScale führt den Weg bei SQL-Vektor-Datenbanken an
MyScale sticht auf dem Markt für SQL-Vektor-Datenbanken durch unübertroffene Genauigkeit, Leistung und Kosteneffizienz hervor. Es übertrifft andere integrierte Vektor-Datenbanken wie pgvector und spezialisierte Vektor-Datenbanken wie Pinecone und erzielt eine viel bessere Suchgenauigkeit und schnellere Abfrageverarbeitung zu geringeren Kosten. Neben der Leistungsfähigkeit ist die SQL-Schnittstelle für Entwickler äußerst benutzerfreundlich und bietet maximalen Wert bei minimalem Lernaufwand.
MyScale hebt das Spiel wirklich auf eine neue Ebene. Es geht nicht nur um eine bessere Suche über Vektoren hinaus; es liefert hohe Genauigkeit und Abfragen pro Sekunde (QPS) in Szenarien mit komplexen Metadatenfiltern. Und hier ist das Wichtigste: Wenn Sie sich anmelden, können Sie den S1-Pod kostenlos nutzen, der bis zu 5 Millionen Vektoren verarbeiten kann. Es ist die erste Wahl für jeden, der eine leistungsstarke und gleichzeitig kostengünstige Lösung für eine Vektordatenbank benötigt.
# MyScale stärkt Anwendungen mit KI-Integrationen
MyScale erweitert seine Möglichkeiten und ermöglicht es Ihnen, robustere Anwendungen durch Integration mit KI-Technologien zu erstellen. Schauen wir uns einige dieser Integrationen an, mit denen Sie Ihre MyScale-Anwendung verbessern können.
Integration mit LangChain: In der heutigen Welt, in der die Anwendungsfälle von KI-Anwendungen von Tag zu Tag zunehmen, können Sie keine robuste KI-Anwendung erstellen, indem Sie nur LLMs mit Datenbanken kombinieren. Sie müssen verschiedene Frameworks und Tools verwenden, um bessere Anwendungen zu entwickeln. In diesem Zusammenhang bietet MyScale eine vollständige Integration mit LangChain (opens new window), mit der Sie effektivere und zuverlässigere KI-Anwendungen mit fortschrittlicher Abrufstrategie erstellen können. Insbesondere implementiert der Self-Query-Retriever für MyScale (opens new window) eine flexible und leistungsstarke Methode zur Umwandlung von Text in metadatengefilterte Vektorabfragen und erzielt hohe Genauigkeit in vielen realen Szenarien.
Integration mit OpenAI: Durch die Integration von MyScale mit OpenAI können Sie die Genauigkeit und Robustheit Ihrer KI-Anwendung erheblich verbessern. OpenAI ermöglicht es Ihnen, die besten Einbettungsvektoren zu erhalten und dabei den Kontext und die Semantik beizubehalten. Dies ist besonders wichtig, wenn Sie die Vektorsuche mit natürlichsprachlichen Abfragen anwenden oder Einbettungen aus Ihren Daten extrahieren. So können Sie die Präzision und Genauigkeit Ihrer Anwendungen verbessern. Für ein detaillierteres Verständnis können Sie unsere Integration mit OpenAI (opens new window) Dokumentation lesen.
Kürzlich hat OpenAI GPTs veröffentlicht, die Entwicklern ermöglichen, GPTs und Chatbots mühelos anzupassen. MyScale passt sich diesem Wandel an und transformiert die Entwicklung des RAG-Systems, indem es serverseitige Kontexte nahtlos in GPT-Modelle einfügt. MyScale optimiert die Kontextinjektion mit strukturierten Datenfiltern und semantischer Suche über SQL WHERE-Klauseln, optimiert die Speicherkosten für Wissensbasis und ermöglicht das Teilen über GPTs hinweg. Probieren Sie MyScaleGPT (opens new window) im GPT Store aus oder binden Sie Ihre Wissensbasis in GPTs mit MyScale ein (opens new window).
# Fazit
Mit dem Wachstum von KI- und maschinellen Lernanwendungen besteht ein steigender Bedarf an Datenbanken wie MyScale, die speziell für moderne KI-Anwendungen entwickelt wurden. MyScale ist eine hochmoderne SQL-Vektor-Datenbank, die die Geschwindigkeit und Funktionalität herkömmlicher Datenbanken mit modernsten Vektorsuchfunktionen kombiniert. Diese Kombination ist perfekt, um KI-Anwendungen zu verbessern.
Am wichtigsten ist, dass aufgrund der vollständigen Kompatibilität von MyScale mit der SQL-Syntax jeder Entwickler, der mit SQL vertraut ist, schnell mit MyScale beginnen kann. Darüber hinaus sind die Kosten bei MyScale deutlich niedriger als bei anderen Arten von Vektordatenbanken. (opens new window) Dies macht MyScale zu einer überzeugenden Wahl für Unternehmen, die erhebliche Datenmengen verwalten, da es einen klaren Vorteil beim Aufbau von GenAI-Anwendungen mit der Vertrautheit und Leistungsfähigkeit von SQL bietet. Wenn Sie über MyScale auf dem Laufenden bleiben möchten, treten Sie uns noch heute bei auf Discord (opens new window) oder Twitter (opens new window) bei.



