
Die Entwicklung skalierbarer und optimierter KI-Anwendungen mit Large Language Models (LLMs) steckt noch in den Anfängen. Der Aufbau von Anwendungen auf Basis von LLMs ist aufgrund der umfangreichen manuellen Arbeit, wie dem Schreiben von Prompts, komplex und zeitaufwändig. Das Schreiben von Prompts ist der wichtigste Teil jeder LLM-Anwendung, da es uns hilft, die bestmöglichen Ergebnisse aus dem Modell zu extrahieren. Das Erstellen eines optimierten Prompts erfordert jedoch, dass Entwickler sich stark auf Versuchs- und Irrtumsmethoden verlassen, was zu erheblichem Zeitaufwand führt, bis das gewünschte Ergebnis erreicht ist.
Die herkömmliche Methode des manuellen Erstellens von Prompts ist zeitaufwändig und fehleranfällig. Entwickler verbringen oft viel Zeit damit, Prompts anzupassen, um das gewünschte Ergebnis zu erzielen, und stehen dabei vor Problemen wie:
- Zerbrechlichkeit: Prompts können bei geringfügigen Änderungen brechen oder inkonsistent funktionieren.
- Manuelle Anpassungen: Es ist umfangreicher manueller Aufwand erforderlich, um Prompts zu verfeinern.
- Inkonsistente Handhabung: Unterschiedliche Prompts für ähnliche Aufgaben führen zu inkonsistenten Ergebnissen.
# Was ist DSPy?
DSPy (Declarative Self-improving Language Programs), ausgesprochen "dee-s-pie", ist ein Framework, das von Omer Khattab und seinem Team an der Stanford NL entwickelt wurde. Es zielt darauf ab, die Konsistenz- und Zuverlässigkeitsprobleme beim Schreiben von Prompts durch Priorisierung der Programmierung gegenüber dem manuellen Schreiben von Prompts zu lösen. Es bietet einen deklarativen, systematischen und programmatischen Ansatz zum Aufbau von Datenpipelines, der es Entwicklern ermöglicht, hochrangige Workflows zu erstellen, ohne sich auf Details auf niedriger Ebene konzentrieren zu müssen.
DSPy-Logo
Es ermöglicht Ihnen, zu definieren, was erreicht werden soll, anstatt wie es erreicht werden soll. Um dies zu erreichen, hat DSPy Fortschritte gemacht:
- Abstraktion über Prompts: DSPy hat das Konzept der Signaturen eingeführt. Signaturen sollen das manuelle Formulieren von Prompts durch eine strukturierte Vorlagenstruktur ersetzen. In dieser Struktur müssen wir nur die Eingaben und Ausgaben für eine bestimmte Aufgabe definieren. Dadurch werden unsere Pipelines widerstandsfähiger und flexibler gegenüber Änderungen im Modell oder den Daten.
- Modulare Bausteine: DSPy bietet Module, die gängige Prompting-Techniken (wie Chain of Thought oder ReAct) kapseln. Dadurch entfällt die Notwendigkeit, komplexe Prompts für diese Techniken manuell zu erstellen.
- Automatisierte Optimierung: DSPy unterstützt integrierte Optimierer, auch "Teleprompter" genannt, die automatisch die besten Prompts für Ihre spezifische Aufgabe und Ihr Modell auswählen. Diese Funktion eliminiert die Notwendigkeit einer manuellen Prompt-Abstimmung und vereinfacht den Prozess.
- Compiler-gesteuerte Anpassung: Der DSPy-Compiler optimiert die gesamte Pipeline, passt Prompts an oder feinabstimmt Modelle basierend auf Ihren Daten und Validierungslogiken. Dadurch bleibt die Pipeline auch bei Änderungen an den Komponenten effektiv.
# Bausteine eines DSPy-Programms
Lassen Sie uns die wesentlichen Komponenten erkunden, die das Fundament eines DSPy-Programms bilden, und verstehen, wie sie interagieren, um leistungsstarke und effiziente NLP-Pipelines zu erstellen.
# Signaturen
Signaturen dienen als Blaupause zur Definition dessen, was Ihr LLM tun soll. Anstatt den genauen Prompt zu schreiben, beschreiben Sie die Aufgabe in Bezug auf ihre Eingaben und Ausgaben.
Beispielsweise könnte eine Signatur für die Zusammenfassung von Text wie folgt aussehen: text -> zusammenfassung. Dies teilt DSPy mit, dass Sie einen Text eingeben möchten und eine prägnante Zusammenfassung als Ausgabe erhalten möchten. Komplexere Aufgaben können mehrere Eingaben umfassen, wie z.B. eine Frage-Antwort-Signatur: kontext, frage -> antwort. Signaturen sind flexibel und können mit zusätzlichen Informationen wie Beschreibungen der Eingabe- und Ausgabefelder angepasst werden.
class GenerateAnswer(dspy.Signature):
"""Beantworten Sie Fragen mit kurzen faktoiden Antworten."""
context = dspy.InputField(desc="kann relevante Fakten enthalten")
question = dspy.InputField()
answer = dspy.OutputField(desc="oft zwischen 1 und 5 Wörtern")
# Module: Bausteine für das Verhalten von LLMs
Module sind vorgefertigte Komponenten, die spezifisches Verhalten oder Techniken von LLMs kapseln. Sie sind die Bausteine, die Sie verwenden, um Ihre LLM-Anwendung zusammenzustellen. Zum Beispiel ermutigt das Modul ChainOfThought das LLM, schrittweise zu denken und verbessert so seine Fähigkeiten bei komplexen Denkaufgaben. Das Modul ReAct ermöglicht es Ihrem LLM, mit externen Tools wie Taschenrechnern oder Datenbanken zu interagieren. Sie können mehrere Module miteinander verketten, um komplexe Pipelines zu erstellen.
# Methode 1: Geben Sie die Klasse an das ChainOfThought-Modul weiter
chain_of_thought = ChainOfThought(TranslateText)
Jedes Modul nimmt eine Signatur entgegen und erstellt mit der Methode defined wie ChainOfThought den erforderlichen Prompt basierend auf den definierten Eingaben und Ausgaben. Diese Methode stellt sicher, dass die Prompts systematisch generiert werden, was die Konsistenz erhöht und die Notwendigkeit des manuellen Prompt-Schreibens reduziert.
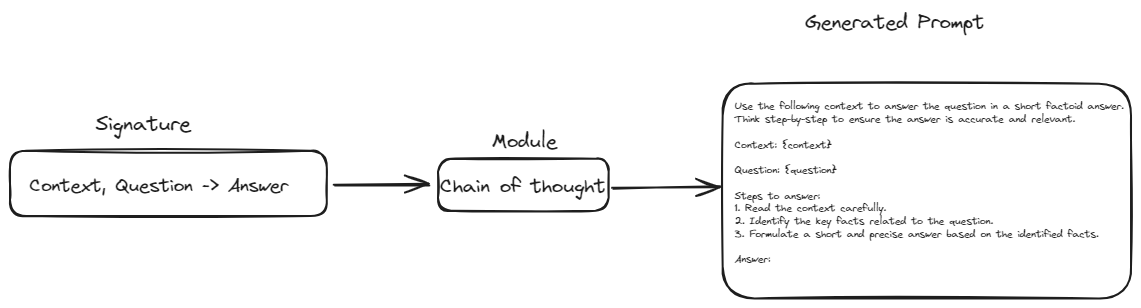
Auf diese Weise nimmt das Modul die Signatur, wendet sein spezifisches Verhalten oder seine Technik an und generiert einen Prompt, der den Anforderungen der Aufgabe entspricht. Diese Integration von Signaturen und Modulen ermöglicht den Aufbau komplexer und flexibler LLM-Anwendungen mit minimalem manuellen Eingriff.
# Teleprompter (Optimierer): Die Prompt-Flüsterer
Teleprompter sind wie Trainer für Ihr LLM. Sie verwenden fortschrittliche Techniken, um die besten Prompts für Ihre spezifische Aufgabe und Ihr Modell zu finden. Dies geschieht, indem sie automatisch verschiedene Variationen von Prompts ausprobieren und deren Leistung anhand einer von Ihnen definierten Metrik bewerten. Ein Teleprompter könnte beispielsweise eine Metrik wie Genauigkeit für Frage-Antwort-Aufgaben oder ROUGE-Score für Textzusammenfassungen verwenden.
from dspy.teleprompt import BootstrapFewShot
# Einfaches Beispiel für einen Teleprompter
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# DSPy Compiler: Der Master-Orchestrator
Der DSPy-Compiler ist das Gehirn hinter der Operation. Er nimmt Ihr gesamtes Programm - einschließlich Ihrer Signaturen, Module, Trainingsdaten und Validierungslogik - und optimiert es für maximale Leistung. Die Fähigkeit des Compilers, Änderungen in Ihrer Anwendung automatisch zu verarbeiten, macht DSPy unglaublich robust und anpassungsfähig.
from dspy.teleprompt import BootstrapFewShot
# Kleiner Trainingssatz mit Frage- und Antwortpaaren
trainset = [dspy.Example(question="Wofür ist Albert Einstein am besten bekannt?",
answer="Die Relativitätstheorie").with_inputs('question'),
dspy.Example(question="Welche berühmte Gleichung hat Albert Einsteins Relativitätstheorie hervorgebracht?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="Welche renommierte Auszeichnung erhielt Albert Einstein 1921?",
answer="Der Nobelpreis für Physik").with_inputs('question'),
dspy.Example(question="In welchem Jahr zog Albert Einstein in die Vereinigten Staaten?",
answer="1933").with_inputs('question'),
dspy.Example(question="Welche bedeutende wissenschaftliche Arbeit veröffentlichte Einstein 1905, manchmal als sein annus mirabilis (Wunderjahr) bezeichnet?",
answer="Vier bahnbrechende Arbeiten, darunter Theorien zum photoelektrischen Effekt, zur Brownschen Bewegung, zur speziellen Relativitätstheorie und zur Massen-Energie-Äquivalenz").with_inputs('question'),]
# Richten Sie einen grundlegenden Teleprompter ein, der unser RAG-Programm kompiliert.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
Der DSPy-Compiler nimmt den grundlegenden Prompt, Trainingsbeispiele und das DSPy-Programm, um einen optimierten und bestmöglichen Prompt zu generieren. Dieser Prozess beinhaltet das Simulieren verschiedener Versionen des Programms auf den Eingaben und das Bootstrapping von Beispieltraces jedes Moduls, um die Pipeline für Ihre Aufgabe zu optimieren.
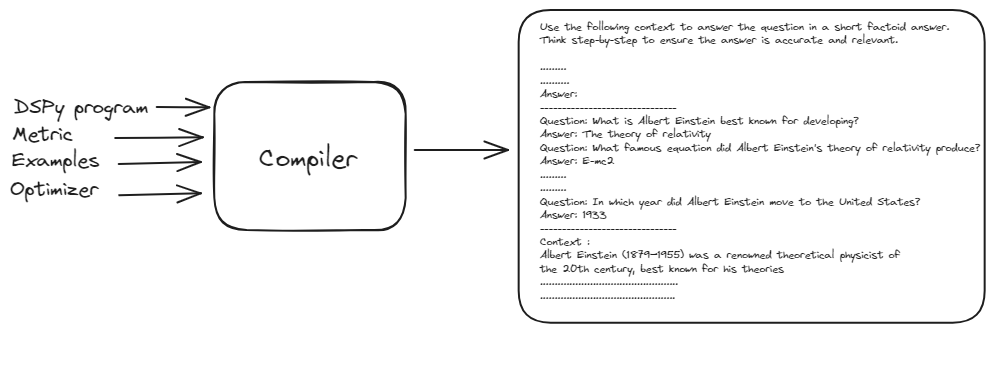
Dieser automatisierte Optimierungsprozess eliminiert die Notwendigkeit einer manuellen Prompt-Abstimmung, macht DSPy robust und anpassungsfähig gegenüber Änderungen und liefert letztendlich eine hochwirksame und effiziente NLP-Pipeline.
# Praktisches Beispiel: Erstellen eines RAG-Modells mit DSPy und MyScaleDB
Nachdem wir die Grundlagen von DSPy behandelt haben, erstellen wir eine praktische Anwendung. Wir werden eine Frage-Antwort-RAG-Pipeline erstellen und MyScaleDB als Vektordatenbank verwenden.
# 1. Laden von Dokumenten aus Wikipedia
Wir beginnen damit, Dokumente über "Albert Einstein" aus Wikipedia zu laden. Dies geschieht mithilfe des WikipediaLoader aus dem Modul langchain_community.document_loaders.
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# Laden der Dokumente
docs = loader.load()
# 2. Umwandlung der Dokumente in Klartext
Als nächstes wandeln wir die geladenen Dokumente mithilfe des Html2TextTransformer in Klartext um.
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# Bereinigten Text abrufen
cleaned_text = docs_transformed[0].page_content
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs_transformed])
# 3. Aufteilen des Textes in Abschnitte
Der Text wird mithilfe des CharacterTextSplitter in handhabbare Abschnitte aufgeteilt. Dies hilft bei der Verarbeitung großer Dokumente und stellt sicher, dass das Modell sie effizient verarbeitet.
import os
from langchain_text_splitters import CharacterTextSplitter
# API-Schlüssel als Umgebungsvariable festlegen
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
# Text in Abschnitte aufteilen
text = ' '.join([page.page_content.replace('\\\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=300,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
# 8. Definition des Embeddings-Modells
Wir verwenden die Bibliothek transformers, um ein Embedding-Modell zu definieren. Wir verwenden das Modell all-MiniLM-L6-v2, um den Text in Vektor-Embeddings zu transformieren.
import torch
from transformers import AutoTokenizer, AutoModel
# Initialisieren des Tokenizers und Modells für Embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
# 7. Abrufen der Embeddings
Wir generieren Embeddings für die Textabschnitte mithilfe des oben definierten Embedding-Modells.
import pandas as pd
all_embeddings = []
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
embeddings_batch = get_embeddings(batch)
all_embeddings.extend(embeddings_batch)
# DataFrame mit den Textabschnitten und ihren Embeddings erstellen
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
# 8. Verbindung zur Vektordatenbank herstellen
Wir verwenden MyScaleDB (opens new window) als Vektordatenbank, um diese Beispielanwendung zu entwickeln. Sie können ein kostenloses Konto auf MyScaleDB erstellen, indem Sie die MyScale Anmelden (opens new window)Seite (opens new window) besuchen. Anschließend können Sie das Schnellstart-Tutorial (opens new window) befolgen, um einen neuen Cluster zu starten und die Verbindungsdetails zu erhalten.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-cloud-host',
port=443,
username='your-user-name',
password='your-password'
)
Kopieren Sie die Verbindungsdetails in Ihr Python-Notebook und führen Sie den Codeblock aus. Er stellt eine Verbindung mit Ihrem MyScaleDB-Cluster in der Cloud her.
# 9. Erstellen einer Tabelle und Übertragen von Daten
Lassen Sie uns den Vorgang des Erstellens einer Tabelle auf dem MyScaleDB-Cluster aufschlüsseln. Zunächst erstellen wir eine Tabelle mit dem Namen RAG. Diese Tabelle hat drei Spalten: id, page_content und embeddings. Die Spalte id enthält die eindeutige id jeder Zeile, die Spalte page_content speichert den Textinhalt und die Spalte embeddings speichert die Embeddings des entsprechenden Textinhalts.
# Tabelle erstellen
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# Daten in die Tabelle einfügen
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} eingefügt.")
Nachdem die Tabelle erstellt wurde, speichern wir die Daten in der neu erstellten RAG-Tabelle in Form von Batches.
# 10. Konfiguration von DSPy mit MyScaleDB
Wir verbinden DSPy und MyScaleDB und konfigurieren DSPy so, dass es standardmäßig unsere Sprach- und Retrieval-Modelle verwendet.
import dspy
import openai
from dspy.retrieve.MyScaleRM import MyScaleRM
# OpenAI API-Schlüssel festlegen
openai.api_key = "your_openai_api_key"
# LLM konfigurieren
lm = dspy.OpenAI(model="gpt-3.5-turbo")
# Retrieval-Modell konfigurieren
rm = MyScaleRM(client=client,
table="RAG",
local_embed_model="sentence-transformers/all-MiniLM-L6-v2",
vector_column="embeddings",
metadata_columns=["page_content"],
k=6)
# DSPy so konfigurieren, dass es standardmäßig das folgende Sprachmodell und Retrieval-Modell verwendet
dspy.settings.configure(lm=lm, rm=rm)
Hinweis: Das hier verwendete Embedding-Modell sollte dasselbe sein, das oben definiert wurde.
# 11. Definition der Signatur
Wir definieren die Signatur GenerateAnswer, um die Eingaben und Ausgaben für unsere Frage-Antwort-Aufgabe anzugeben.
class GenerateAnswer(dspy.Signature):
"""Beantworten Sie Fragen mit kurzen faktoiden Antworten."""
context = dspy.InputField(desc="kann relevante Fakten enthalten")
question = dspy.InputField()
answer = dspy.OutputField(desc="oft zwischen 1 und 5 Wörtern")
# 12. Definition des RAG-Moduls
Das RAG-Modul integriert die Schritte des Retrievals und der Generierung. Es ruft relevante Abschnitte ab und generiert Antworten basierend auf dem Kontext.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
Die forward-Methode akzeptiert die Frage als Eingabe und verwendet den Retriever, um relevante Abschnitte aus der integrierten Datenbank zu finden. Diese abgerufenen Abschnitte werden dann an das ChainOfThought-Modul übergeben, um einen grundlegenden Prompt zu generieren.
# 13. Einrichten von Telepromptern
Als nächstes verwenden wir den Teleprompter/Optimierer BootstrapFewShot, um unseren grundlegenden Prompt zu kompilieren und zu optimieren.
from dspy.teleprompt import BootstrapFewShot
# Kleiner Trainingssatz mit Frage- und Antwortpaaren
trainset = [dspy.Example(question="Wofür ist Albert Einstein am besten bekannt?",
answer="Die Relativitätstheorie").with_inputs('question'),
dspy.Example(question="Welche berühmte Gleichung hat Albert Einsteins Relativitätstheorie hervorgebracht?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="Welche renommierte Auszeichnung erhielt Albert Einstein 1921?",
answer="Der Nobelpreis für Physik").with_inputs('question'),
dspy.Example(question="In welchem Jahr zog Albert Einstein in die Vereinigten Staaten?",
answer="1933").with_inputs('question'),
dspy.Example(question="Welche bedeutende wissenschaftliche Arbeit veröffentlichte Einstein 1905, manchmal als sein annus mirabilis (Wunderjahr) bezeichnet?",
answer="Vier bahnbrechende Arbeiten, darunter Theorien zum photoelektrischen Effekt, zur Brownschen Bewegung, zur speziellen Relativitätstheorie und zur Massen-Energie-Äquivalenz").with_inputs('question'),]
# Einen grundlegenden Teleprompter einrichten, der unser RAG-Programm kompiliert.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# Kompilieren der RAG-Pipeline mit dem Teleprompter
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
Dieser Code verwendet die oben definierte Klasse RAG und verwendet die Beispiele zusammen mit dem Optimierer, um den bestmöglichen Prompt für unser LLM zu generieren.
# 14. Ausführen der Pipeline
Schließlich führen wir unsere kompilierte RAG-Pipeline aus, um Fragen basierend auf dem in MyScaleDB gespeicherten Kontext zu beantworten.
# Relevante Dokumente abrufen
retrieve_relevant_docs = dspy.Retrieve(k=5)
context = retrieve_relevant_docs("Wer ist Albert Einstein?").passages
# Die Abfrage stellen
pred = compiled_rag(question="Wer war Albert Einstein?")
Dies erzeugt eine Ausgabe wie diese:
['Albert Einstein (1879–1955) war ein renommierter theoretischer Physiker des 20. Jahrhunderts,
am besten bekannt für seine Theorien der speziellen Relativität ........
.......
Originalität haben das Wort "Einstein" zum Synonym für "Genie" gemacht.']

# Fazit
Das DSPy-Framework hat unsere Interaktion mit LLMs revolutioniert, indem es fest codierte Prompts durch eine programmierbare Schnittstelle ersetzt und den Entwicklungsprozess erheblich vereinfacht. Diese Umstellung vom manuellen Schreiben von Prompts zu einer strukturierten, programmierorientierten Methodik hat die Effizienz, Konsistenz und Skalierbarkeit von KI-Anwendungen verbessert. Durch die Abstraktion der Komplexität des Prompt-Engineerings ermöglicht DSPy Entwicklern, sich auf die Definition von Hochleistungslogik und -workflows zu konzentrieren und so die Bereitstellung anspruchsvoller KI-gesteuerter Lösungen zu beschleunigen.
MyScaleDB, eine speziell für KI-Anwendungen entwickelte Vektordatenbank, spielt eine wichtige Rolle bei der Verbesserung der Leistung solcher Systeme. Ihre fortschrittlichen, proprietären Algorithmen steigern die Geschwindigkeit und Genauigkeit von KI-Anwendungen. Darüber hinaus ist MyScaleDB kostengünstig und bietet neuen Benutzern kostenlosen Speicherplatz für bis zu 5 Millionen Vektoren. Dies macht es zu einer attraktiven Option für Startups und Forscher, die robuste Datenbanklösungen nutzen möchten, ohne anfängliche Investitionen tätigen zu müssen.



