
Große Sprachmodelle (opens new window) (LLMs) haben das Gebiet der natürlichen Sprachverarbeitung (NLP) revolutioniert und eine neue Art der Interaktion mit Technologie eingeführt. Fortgeschrittene Modelle wie GPT (opens new window) und BERT (opens new window) haben eine neue Ära des semantischen Verständnisses eingeläutet. Sie ermöglichen es Computern, menschenähnlichen Text zu verarbeiten und zu generieren und überbrücken die Kluft zwischen menschlicher Kommunikation und maschineller Interpretation. LLMs werden nun in mehreren Anwendungen eingesetzt, darunter Sentimentanalyse, maschinelle Übersetzung, Frage-Antwort-Systeme, Textzusammenfassung, Chatbots, virtuelle Assistenten und mehr.
Trotz ihrer praktischen Anwendungen haben große Sprachmodelle (LLMs) ihre eigenen Herausforderungen. Sie sind darauf ausgelegt, generalisiert zu sein, was bedeutet, dass ihnen möglicherweise die Spezifität fehlt. Darüber hinaus können sie aufgrund ihrer Schulung mit vergangenen Daten nicht immer die neuesten Informationen liefern. Dies kann dazu führen, dass LLMs falsche oder veraltete Antworten generieren, was zu einem Phänomen namens "Halluzination (opens new window)" führt. Dies tritt auf, wenn die Modelle Fehler machen oder unvorhersehbare Informationen generieren aufgrund von Lücken in ihren Trainingsdaten.
Retrieval-augmentierte Generierung (opens new window) (RAG)-Systeme werden eingesetzt, um Probleme wie mangelnde Spezifität und Echtzeitaktualisierungen anzugehen und potenzielle Lösungen zur Verbesserung des verantwortungsvollen Einsatzes von LLMs anzubieten.
# Was ist RAG
Im Jahr 2020 schlugen Meta-Forscher die retrieval-augmentierte Generierung (RAG) vor, indem sie die Fähigkeit zur natürlichen Sprachgenerierung (NLG) von LLMs mit der Informationsabruf (IR)-Komponente kombinierten, um die Ausgabe zu optimieren. Es bezieht sich auf eine zuverlässige Wissensquelle außerhalb ihrer Trainingsdatenquellen, bevor sie auf die Anfrage antworten. Es erweitert die Fähigkeiten von LLMs, ohne dass eine Modellneuschulung erforderlich ist, was eine kostengünstige Möglichkeit bietet, die Relevanz, Genauigkeit und Benutzerfreundlichkeit der Ausgabe in verschiedenen Kontexten zu verbessern.
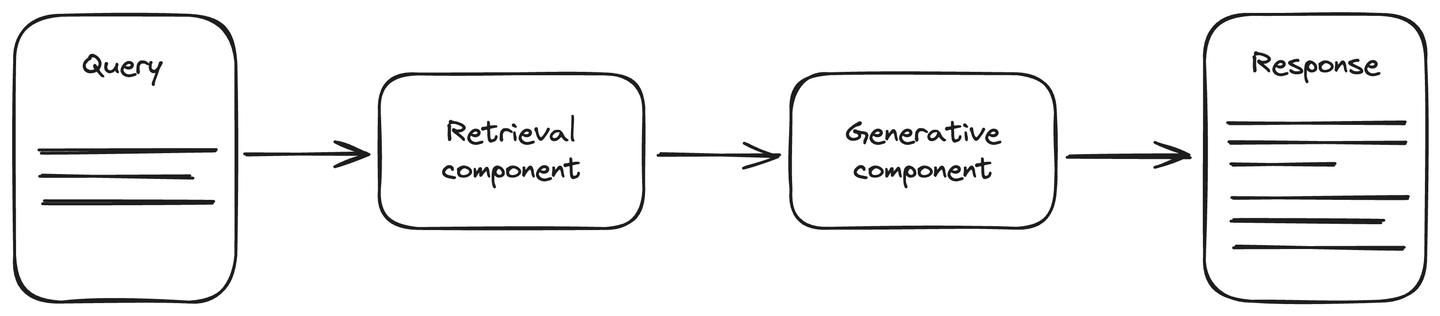
Die RAG-Architektur umfasst eine aktuelle Datenquelle, um die Genauigkeit bei generativen KI-Aufgaben zu verbessern. Sie besteht aus zwei Hauptkomponenten: der Abruf- und der Generierungskomponente. Die Abrufkomponente ist mit einer Datenquelle verbunden, meistens einer Vektordatenbank, die die aktualisierten Informationen zur Anfrage abruft. Diese Informationen werden zusammen mit der Anfrage an die Generierungskomponente weitergegeben. Die Generierungskomponente ist ein LLM-Modell, das entsprechend die Antwort generiert. RAG verbessert das Verständnis von LLMs, und die generierte Antwort ist genauer und aktueller.
Verwandter Artikel: Was man von RAG erwarten kann (opens new window)
# Einrichtung der Abrufkomponente eines RAG-Systems
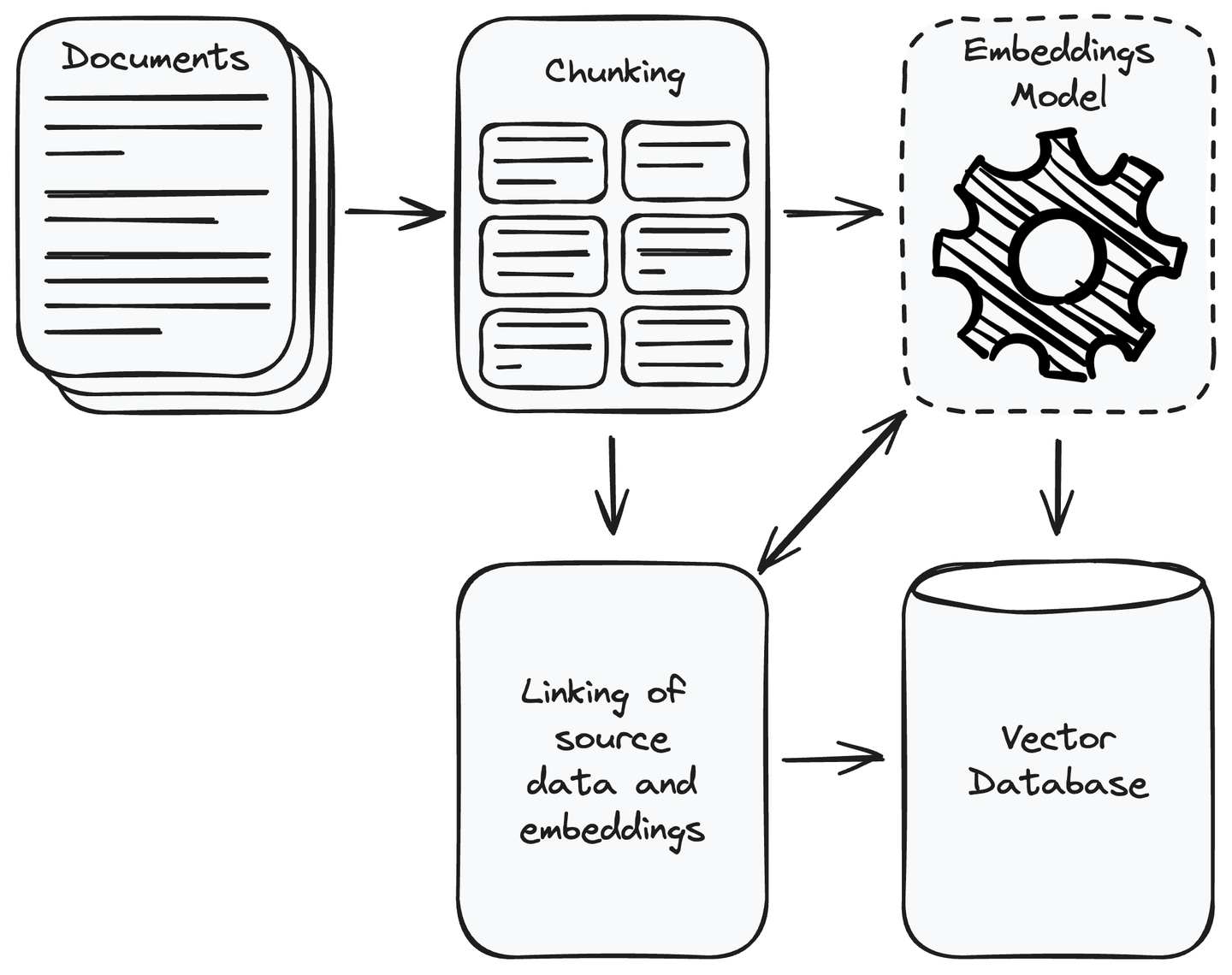
Zunächst müssen Sie alle für Ihre Anwendung erforderlichen Daten sammeln. Sobald Sie die Datensammlung abgeschlossen haben, entfernen Sie die irrelevanten Daten. Teilen Sie die gesammelten Daten in handhabbare kleinere Teile auf und wandeln Sie diese Teile in Vektorrepräsentationen um, indem Sie Einbettungsmodelle (opens new window) verwenden. Vektoren sind numerische Repräsentationen, bei denen semantisch ähnlicher Inhalt näher beieinander liegt. Dies ermöglicht es dem System, die Benutzeranfrage mit den relevanten Informationen in der Datenquelle zu verstehen und abzugleichen. Speichern Sie die Vektoren in einer Vektordatenbank und verknüpfen Sie die Teile der Quelldaten mit ihren Einbettungen. Dies hilft dabei, den Datenabschnitt eines Vektors abzurufen, der der Benutzeranfrage ähnlich ist.
MyScale (opens new window) ist eine Cloud-basierte Vektordatenbank auf Basis von ClickHouse (opens new window), die die üblichen SQL-Abfragen mit der Stärke einer Vektordatenbank kombiniert. Dadurch können Sie hochdimensionale Daten wie Bildmerkmale oder Texteinbettungen mithilfe der regulären SQL-Abfragen nach Informationen speichern und finden. MyScale ist besonders leistungsstark für KI-Anwendungen, bei denen der Vergleich von Vektoren wichtig ist. Es wurde entwickelt, um kostengünstig und praktisch für Entwickler zu sein, die mit einer großen Menge von Vektordaten in KI- und maschinellen Lernaufgaben umgehen.
Zusätzlich ist MyScale so konzipiert, dass es kostengünstiger, schneller und genauer ist als andere Optionen. Um Benutzer dazu zu ermutigen, von den Vorteilen zu profitieren, bietet MyScale 5 Millionen kostenlose Vektorspeicher auf der kostenlosen Stufe an. Dies macht es zu einer kostengünstigen und benutzerfreundlichen Lösung für Entwickler, die Vektordatenbanken in ihren KI- und maschinellen Lernvorhaben erkunden.
Verwandter Artikel: Erstellen Sie einen RAG-fähigen Chatbot (opens new window)
# Wie funktioniert ein RAG-System?
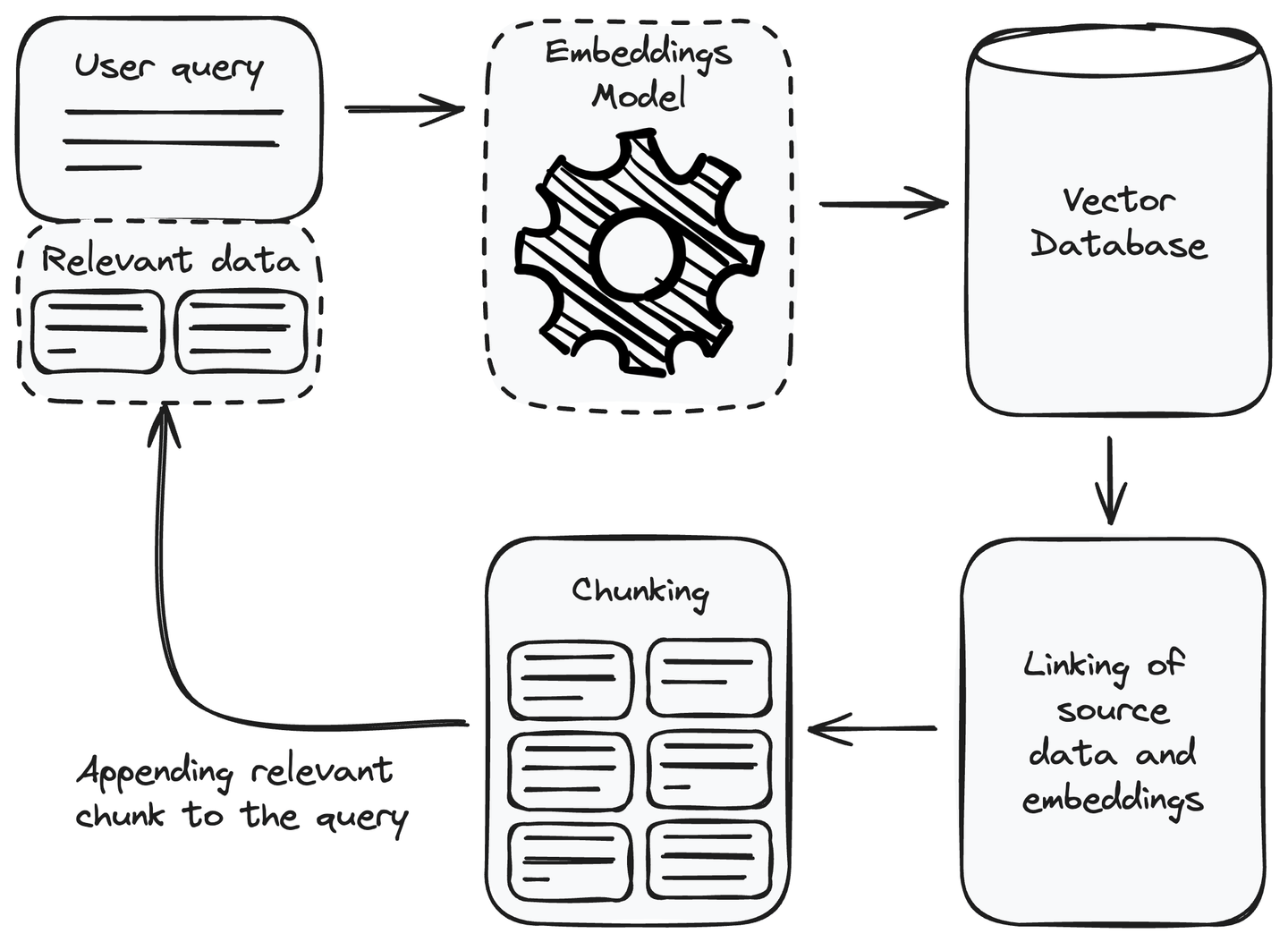
Nachdem die Abrufkomponente eingerichtet ist, können wir sie nun in unserem RAG-System nutzen. Um auf eine Benutzeranfrage zu antworten, können wir sie verwenden, um die relevanten Informationen abzurufen und sie als Kontext an die Benutzeranfrage anzuhängen, bevor sie dem Sprachmodell zur Generierung der Antwort übergeben wird. Lassen Sie uns verstehen, wie die Abrufkomponente verwendet wird, um die relevanten Informationen zu erhalten.
# Hinzufügen relevanter Informationen zur Anfrage
Immer wenn wir eine Benutzeranfrage erhalten, ist der erste Schritt, den wir durchführen müssen, die Benutzeranfrage in eine Einbettung oder Vektorrepräsentation umzuwandeln. Verwenden Sie dasselbe Einbettungsmodell, das wir verwendet haben, um die Datenquelle in Einbettungen umzuwandeln, während Sie die Abrufkomponente einrichten. Nach der Umwandlung der Benutzeranfrage in eine Vektorrepräsentation finden Sie die ähnlichen
# Generierung der Antwort mit LLM
Jetzt haben wir die Anfrage und die damit verbundenen Informationsabschnitte. Geben Sie die Benutzeranfrage zusammen mit den abgerufenen Daten an das LLM (die Generierungskomponente) weiter. Das LLM ist in der Lage, die Benutzeranfrage zu verstehen und die bereitgestellten Daten zu verarbeiten. Es generiert die Antwort auf die Benutzeranfrage entsprechend den Informationen, die es von der Abrufkomponente erhalten hat.
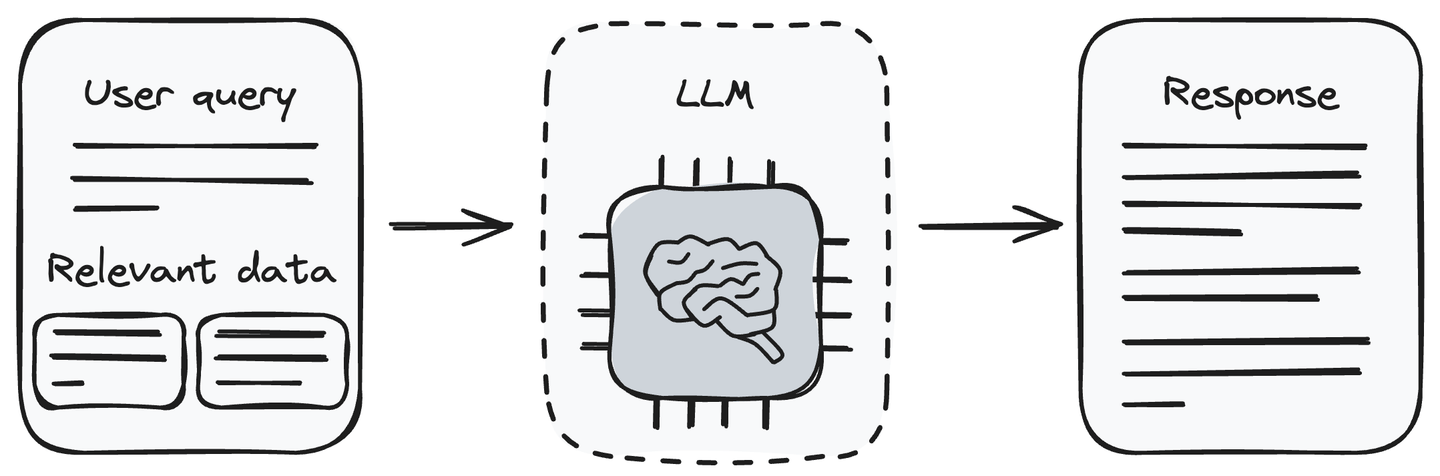
Das Übergeben der relevanten Informationen zusammen mit der Benutzeranfrage an das LLM ist eine Methode, die das Halluzinationsproblem von LLMs beseitigt. Jetzt kann das LLM Antworten auf die Benutzeranfrage generieren, indem es die Informationen verwendet, die wir ihm zusammen mit der Benutzeranfrage übergeben haben.
Hinweis: Vergessen Sie nicht, die Datenbank regelmäßig mit den neuesten Informationen zu aktualisieren, um die Genauigkeit des Modells sicherzustellen.
# Einige Anwendungen von RAG
RAG-Systeme können in verschiedenen Anwendungen eingesetzt werden, die eine präzise und kontextuell relevante Informationsabruf erfordern. Dies trägt zur Verbesserung der Genauigkeit, Aktualität und Zuverlässigkeit der generierten Antworten bei. Lassen Sie uns einige Anwendungen eines RAG-Systems besprechen.
- Domänenspezifische Fragestellungen: Wenn ein RAG-System Fragen in einer bestimmten Domäne gegenübersteht, nutzt es die Abrufkomponente, um dynamisch auf externe Wissensquellen, Datenbanken oder domänenspezifische Dokumente zuzugreifen. Dadurch kann das RAG-System Antworten generieren, die kontextuell relevant sind und die aktuellsten und genauesten Informationen innerhalb der angegebenen Domäne widerspiegeln. Dies kann in verschiedenen Bereichen wie Gesundheitswesen, rechtlicher Interpretation, historischer Forschung, technischer Fehlerbehebung usw. hilfreich sein.
- Faktentreue: Faktentreue ist entscheidend, um sicherzustellen, dass der generierte Inhalt oder die generierten Antworten mit genauen und verifizierten Daten übereinstimmen. In Situationen, in denen Ungenauigkeiten auftreten können, legt RAG den Schwerpunkt auf die Faktentreue, um Informationen bereitzustellen, die mit der Realität des betreffenden Themas übereinstimmen. Dies ist für verschiedene Anwendungen von Bedeutung, einschließlich Nachrichtenberichterstattung, Bildungsinhalten und allen Szenarien, in denen die Zuverlässigkeit und Vertrauenswürdigkeit von Informationen von größter Bedeutung sind.
- Forschungsanfragen: RAG-Systeme sind wertvoll, um Forschungsanfragen zu bearbeiten, indem sie relevante und aktuelle Informationen aus ihren Wissensquellen abrufen. Wenn beispielsweise ein Forscher eine Anfrage zu den neuesten Fortschritten in einem bestimmten wissenschaftlichen Bereich stellt, kann ein RAG-System seine Abrufkomponente nutzen, um auf aktuelle Forschungsarbeiten, Veröffentlichungen und relevante Daten zuzugreifen und sicherzustellen, dass der Forscher kontextuell genaue und aktuelle Erkenntnisse erhält.
Verwandter Artikel: Wie man ein Empfehlungssystem erstellt (opens new window)

# Herausforderungen beim Aufbau eines RAG-Systems
Obwohl RAG-Systeme verschiedene Anwendungsfälle und Vorteile haben, stehen sie auch vor einigen einzigartigen Einschränkungen. Hier sind einige davon:
- Integration: Die Integration einer Abrufkomponente mit einer generativen Komponente auf Basis von LLM kann schwierig sein. Die Komplexität nimmt zu, wenn mit mehreren Datenquellen in unterschiedlichen Formaten gearbeitet wird. Stellen Sie vor der Integration der Abrufkomponente mit der generativen Komponente die Konsistenz über alle Datenquellen hinweg mithilfe separater Module sicher.
- Datenqualität: RAG-Systeme sind von der angehängten Datenquelle abhängig. Die Qualität eines RAG-Systems kann aus verschiedenen Gründen schlecht sein, z. B. durch Verwendung von minderwertigem Inhalt, Verwendung unterschiedlicher Einbettungen bei mehreren Datenquellen oder Verwendung inkonsistenter Datenformate. Achten Sie darauf, die Datenqualität aufrechtzuerhalten.
- Skalierbarkeit: Die Leistung eines RAG-Systems wird beeinträchtigt, wenn die Menge der externen Daten zunimmt. Die Aufgaben der Umwandlung von Daten in Einbettungen, des Vergleichs der Bedeutung ähnlicher Datenabschnitte und des Abrufs in Echtzeit können rechenintensiv werden. Dadurch kann das RAG-System verlangsamt werden. Um dieses Problem zu lösen, können Sie MyScale verwenden, das das Problem durch Bereitstellung einer 390 QPS (Abfragen pro Sekunde) auf dem LAION 5M-Datensatz mit einer Rückrufquote von 95% und einer durchschnittlichen Abfrageverzögerung von 17 ms im x1-Pod gelöst hat.
# Fazit
RAG ist eine der Techniken zur Verbesserung der Fähigkeiten von LLMs durch Anbindung einer Wissensbasis. Sie können es sich als eine Suchmaschine mit Sprachgenerierungsfähigkeiten vorstellen. Diese Systeme mildern das Halluzinationsproblem von LLMs ohne zusätzliche Neuschulung oder Feinabstimmungskosten. Die Verwendung einer externen Datenquelle bei der Beantwortung der Benutzeranfrage liefert eine genauere und aktuellere Antwort, insbesondere bei der Arbeit mit faktischen, aktuellen oder regelmäßig aktualisierten Daten. Trotz dieser Vorteile von RAG-Systemen haben sie auch ihre Einschränkungen.
MyScale bietet eine leistungsstarke Lösung für groß angelegte und komplexe RAG-Anwendungen, indem es die Stärken von ClickHouse, fortschrittlichen Vektorsuchalgorithmen und gemeinsamen SQL-Vektoroptimierungen kombiniert. Es ist speziell für KI-Anwendungen konzipiert und berücksichtigt alle Faktoren, einschließlich Kosten und Skalierbarkeit. Darüber hinaus bietet es Integrationen mit bekannten KI-Frameworks wie LangChain (opens new window) und LlamaIndex (opens new window). Diese Eigenschaften und Funktionen machen MyScale zur besten Wahl für Ihre nächste KI-Anwendung.
Wenn Sie Anregungen und Feedback haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).



