
Retrieval-augmented generation (RAG) (opens new window) hat einen großen Durchbruch im Bereich der natürlichen Sprachverarbeitung (NLP) erreicht. Es hat die meisten NLP-Aufgaben durch seine Einfachheit und Effizienz optimiert. Durch die Kombination der Stärken von Retrieval-Systemen (Vektordatenbanken) und generativen Modellen (LLMs) verbessert RAG signifikant die Leistung von KI-Systemen in Bereichen wie Textgenerierung, Übersetzung und Beantwortung von Fragen.
Die Integration von Vektordatenbanken hat eine Schlüsselrolle bei der Revolutionierung der Leistung von RAG-Systemen gespielt. Lassen Sie uns die Beziehung zwischen RAG und Vektordatenbanken erkunden und wie sie zusammenarbeiten, um solch bemerkenswerte Ergebnisse zu erzielen.
# Ein kurzer Überblick über das RAG-Modell
RAG ist eine Technik, die speziell entwickelt wurde, um die Leistung großer Sprachmodelle (LLMs) zu verbessern. Es ruft Informationen, die mit der Benutzeranfrage zusammenhängen, aus Vektordatenbanken ab und stellt sie dem LLM als Referenz zur Verfügung. Dieser Prozess verbessert signifikant die Qualität der Antworten von LLMs, indem sie genauer und relevanter werden. Das folgende Bild zeigt kurz, wie ein RAG-Modell funktioniert (opens new window).
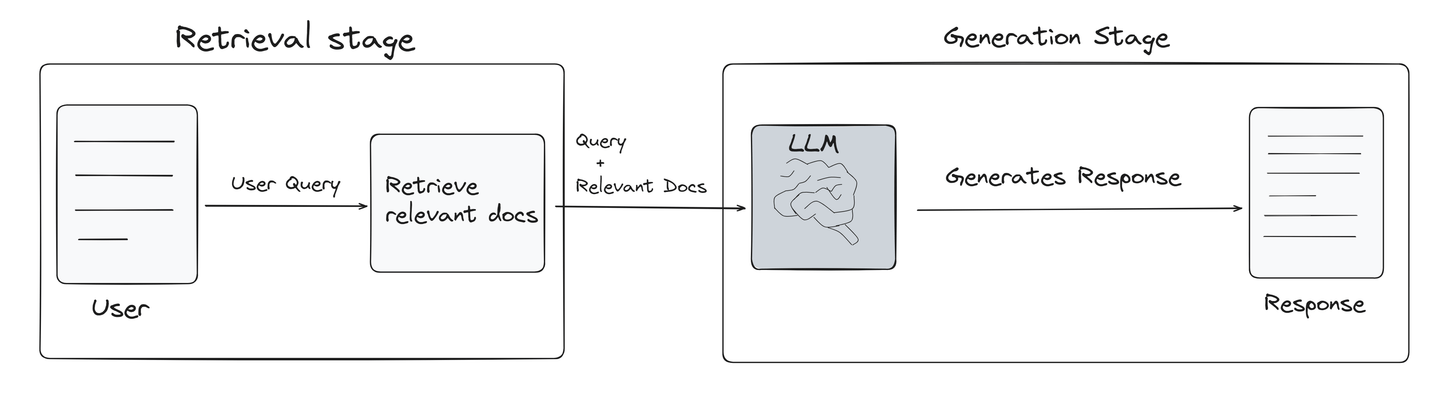
Retrieval-Stufe: RAG identifiziert zunächst die relevantesten Informationen aus der Vektordatenbank mithilfe der Kraft der Ähnlichkeitssuche. Diese Stufe ist der wichtigste Teil eines RAG-Systems, da sie die Grundlage für die Qualität der endgültigen Ausgabe bildet.
Generierungsstufe: Sobald die relevanten Informationen abgerufen wurden, werden die Benutzeranfrage und die abgerufenen Dokumente an das LLM-Modell weitergegeben, um neuen Inhalt zu generieren, der kohärent, relevant und informativ ist.
Die Implementierung von RAG verbessert die Leistung von LLMs signifikant, indem sie wichtige Einschränkungen wie faktische Ungenauigkeiten, veraltete Informationen und Halluzinationen angeht. Die Abrufung relevanter, aktueller Informationen aus Vektordatenbanken verbessert die Genauigkeit und Zuverlässigkeit der Antworten von LLMs, insbesondere bei wissensintensiven Aufgaben.
Darüber hinaus führt sie eine Ebene der Transparenz und Rückverfolgbarkeit ein, die es Benutzern ermöglicht, die Herkunft der bereitgestellten Informationen zu überprüfen. Dieser hybride Ansatz, der die generativen Fähigkeiten von LLMs mit der informativen Kraft von Retrieval-Systemen kombiniert, führt zu robusten und vertrauenswürdigen KI-Anwendungen, die sich dynamisch an eine Vielzahl komplexer Anfragen und Aufgaben anpassen können.
# Die Rolle von Vektordatenbanken
Eine Vektordatenbank ist ein spezialisiertes Datenbanksystem, das Daten in Form von numerischen Vektoren, sogenannten Embeddings, speichert und verwaltet. Diese Embeddings codieren die semantische Bedeutung und den Kontext von Daten jeglicher Art. Die Daten können Texte, Bilder oder sogar Audio sein. Vektordatenbanken speichern diese Embeddings effizient und ermöglichen eine schnelle Abrufung von Embeddings durch eine Ähnlichkeitssuche. Diese Funktionen spielen eine wichtige Rolle bei Aufgaben wie Information Retrieval, Empfehlungssystemen und semantischer Suche. Diese Datenbanken sind besonders nützlich in maschinellem Lernen (ML) und künstlicher Intelligenz (KI) Anwendungen, bei denen Daten oft in Vektorräume transformiert werden, um komplexe Muster und Beziehungen zu erfassen.
Wichtige Merkmale von Vektordatenbanken sind:
- Unterstützung für hochdimensionale Daten: Diese Datenbanken sind darauf ausgelegt, hochdimensionale Vektordaten zu verarbeiten, die in Machine-Learning-Modellen häufig verwendet werden.
- Effiziente Suche: Diese Datenbanken bieten optimierte Suchalgorithmen, um die ähnlichsten Vektoren aus einem großen Datensatz schnell zu finden. Die Kernsuchfunktion ist die Suche nach dem nächsten Nachbarn, und alle Algorithmen sind darauf ausgelegt, diesen Ansatz zu optimieren.
- Skalierbarkeit: Vektordatenbanken sind darauf ausgelegt, große Datenmengen und Benutzeranfragen zu verarbeiten. Dadurch eignen sie sich für wachsende Datensätze und steigende Anforderungen.
- Indexierung: Diese Datenbanken verwenden oft fortschrittliche Indexierungstechniken, um den Prozess des Suchens und Vergleichens von Vektoren zu beschleunigen.
- Integration: Sie können problemlos in Machine-Learning-Pipelines integriert werden, um Echtzeit-Datenabrufmöglichkeiten bereitzustellen.
Vektordatenbanken sind eine entscheidende Komponente in Systemen, die maschinelles Lernen für Aufgaben wie Bilderkennung, Textanalyse und Empfehlungsalgorithmen nutzen, bei denen die Fähigkeit, große Mengen vektorisierter Daten schnell abzurufen und zu vergleichen, von entscheidender Bedeutung ist.
# Wie Vektordatenbanken die Leistung von RAG verbessern
Vektordatenbanken verbessern die Leistung von RAG-Systemen signifikant, indem sie verschiedene Stufen des Workflows optimieren. Zunächst wird der Text in Vektoren umgewandelt, indem ein Embedding-Modell verwendet wird. Diese Umwandlung ist wichtig, da sie Textdaten in ein Format transformiert, das basierend auf semantischer Bedeutung effizient gespeichert und abgerufen werden kann.
Die Stärke einer Vektordatenbank liegt in ihren fortgeschrittenen Indexierungsmethoden. Sobald die Daten in Vektoren umgewandelt wurden, werden sie mithilfe von fortgeschrittenen Indexierungsmethoden wie HNSW (Hierarchical Navigable Small World) oder IVF (Inverted File Index) (opens new window) in der Vektordatenbank gespeichert. Diese Indexierungsmethoden organisieren die Vektoren so, dass eine schnelle und effiziente Abrufung möglich ist. Der Indexierungsprozess stellt sicher, dass das System bei einer Abfrage schnell die relevanten Vektoren aus dem umfangreichen Datensatz finden kann.
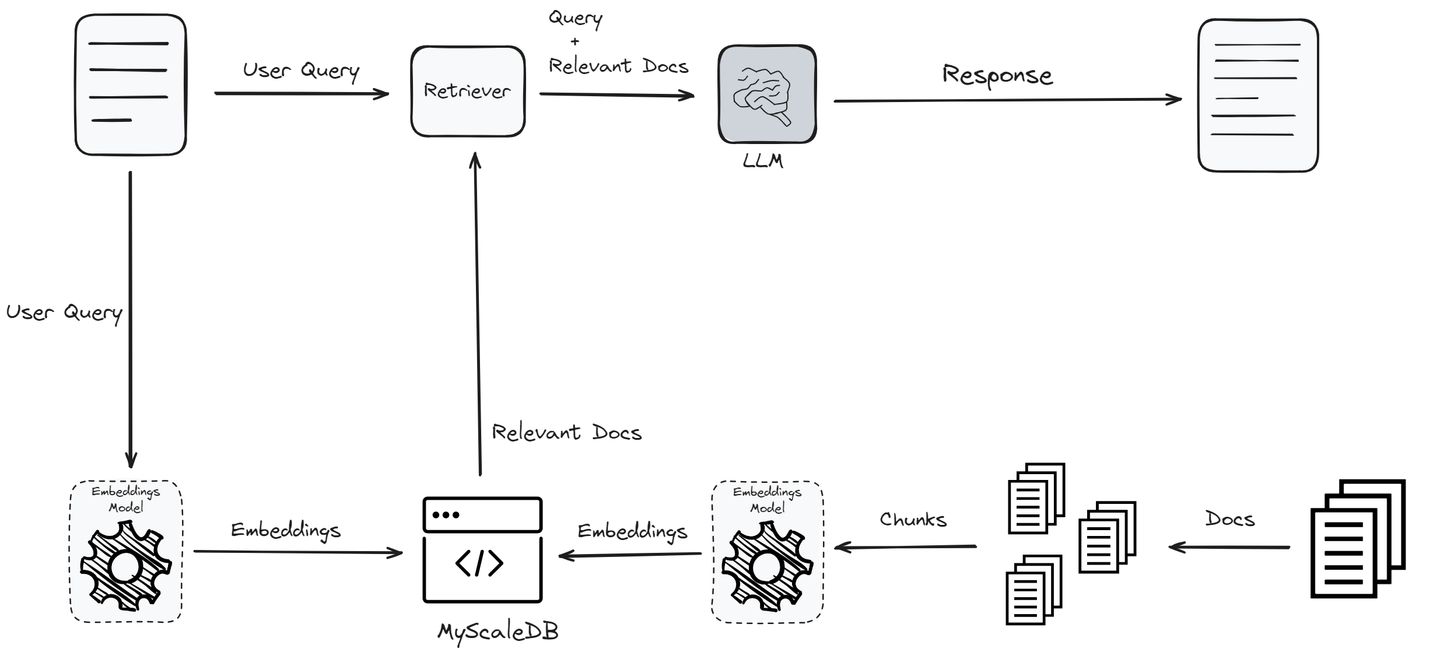
Wenn ein Benutzer eine Anfrage stellt, wird diese ebenfalls mithilfe desselben Embedding-Modells in einen Vektor umgewandelt. Die Vektordatenbank sucht nach dem nächsten Cluster mit ähnlichen Vektoren. Die Vektordatenbank sucht nach Clustern von Vektoren, die semantisch am nächsten zum Anfragevektor sind. Diese Ähnlichkeitssuche bildet die Grundlage für jedes RAG-System und ermöglicht es Vektordatenbanken, semantisch ähnliche Vektoren schnell und präzise zu identifizieren.
Die ähnlichen Dokumente werden dann an den Retriever weitergegeben, der die Anfrage mit den relevanten Dokumenten kombiniert und sie an das LLM zur Generierung der Antwort sendet. Die Verwendung von Vektordatenbanken stellt sicher, dass der Retriever mit den relevantesten Informationen arbeitet. Dies verbessert die Genauigkeit und Relevanz der generierten Antwort.
Vektordatenbanken verbessern nicht nur die Abrufgeschwindigkeit, sondern verarbeiten auch große Datenmengen effizient. Diese Skalierbarkeit ist für Anwendungen mit umfangreichen Datensätzen von entscheidender Bedeutung. Durch schnelle und präzise Abrufung ermöglichen Vektordatenbanken Echtzeit-Abfragen und liefern Benutzern sofortige und relevante Antworten.

# Die ideale Lösung: Spezialisierte Vektordatenbank vs. SQL-Vektordatenbank
In realen RAG-Systemen erfordert die Überwindung der Abrufgenauigkeit (und der damit verbundenen Leistungsengpässe) eine effiziente Möglichkeit, Abfragen von strukturierten, Vektor- und Schlüsselwortdaten zu kombinieren.
Einige Vektordatenbanken (wie Pinecone, Weaviate und Milvus) sind von Anfang an speziell für die Vektorsuche konzipiert. Sie zeigen gute Leistung in diesem Bereich, haben jedoch etwas eingeschränkte allgemeine Datenverwaltungsfähigkeiten.
- Eingeschränkte Abfragefähigkeiten: Sie bieten nur begrenzte Unterstützung für komplexe Abfragen, einschließlich solcher mit mehreren Bedingungen, Joins und Aggregationen, aufgrund eingeschränkter Metadatenspeicherung.
- Einschränkungen bei Datentypen: Da sie hauptsächlich für die Speicherung von Vektoren und minimalen Metadaten konzipiert sind, fehlt ihnen die Flexibilität, verschiedene Datentypen wie Ganzzahlen, Zeichenketten und Datumsangaben zu verarbeiten.
SQL-Vektordatenbanken (opens new window) stellen eine fortschrittliche Fusion von traditionellen SQL-Datenbankfunktionen mit den spezialisierten Fähigkeiten von Vektordatenbanken dar. Diese Systeme integrieren Vektorsuchalgorithmen direkt in die strukturierte Datenumgebung und ermöglichen die Verwaltung von Vektor- und strukturierten Daten innerhalb eines einheitlichen Datenbank-Frameworks.
Diese Integration bietet mehrere Vorteile:
- Vereinfachte Kommunikation zwischen Datentypen.
- Flexible Filterung basierend auf Metadaten.
- Unterstützung für die Ausführung von SQL- und Vektorabfragen.
- Kompatibilität mit vorhandenen Tools, die für Datenbanken mit allgemeinem Zweck entwickelt wurden.
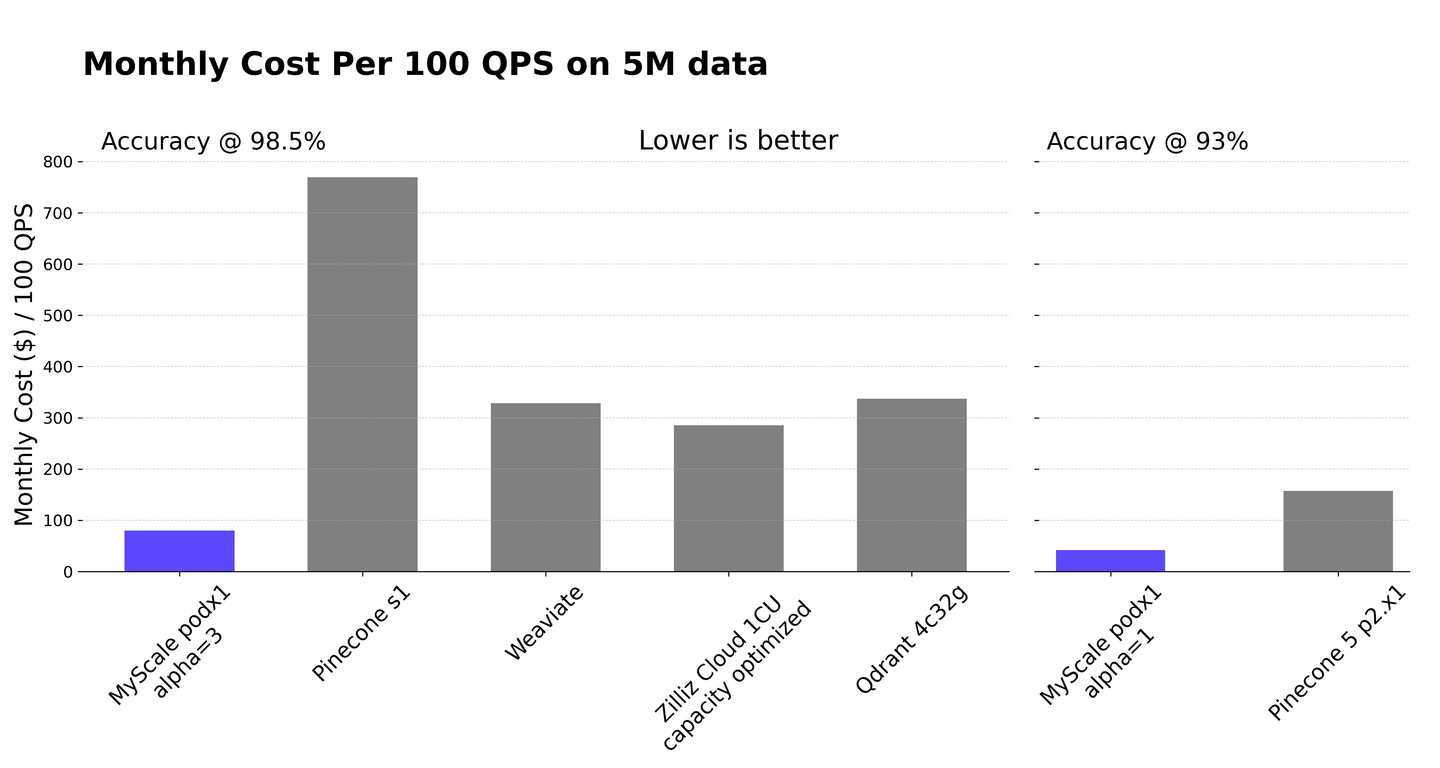
Unter den SQL-Vektordatenbanken ist MyScaleDB (opens new window) eine Open-Source-Option, die die Fähigkeiten von ClickHouse erweitert. Sie kombiniert nahtlos die Verwaltung strukturierter Daten mit Vektoroperationen, optimiert die Leistung für komplexe Dateninteraktionen und verbessert die Effizienz von RAG-Systemen. Mit gefilterten Suchen (opens new window) filtert MyScaleDB effizient Daten in großen Datensätzen basierend auf bestimmten Attributen, bevor Vektorsuchen durchgeführt werden. Dadurch wird eine schnelle und präzise Abrufung für RAG-Systeme sichergestellt.
# Fazit
Vektordatenbanken haben RAG-Systeme erheblich verbessert, indem sie die Datenabrufung und -verarbeitung optimieren. Diese Datenbanken ermöglichen eine effiziente Speicherung und schnelle Abrufung basierend auf semantischer Bedeutung. Fortgeschrittene Indexierungsmethoden wie HNSW und IVF stellen sicher, dass relevante Daten schnell gefunden werden, was die Genauigkeit der Antworten verbessert. Darüber hinaus verarbeiten Vektordatenbanken große Datenmengen und bieten die erforderliche Skalierbarkeit für Echtzeit-Abfragen und sofortige Benutzerantworten.
Eine SQL-Vektordatenbank geht noch einen Schritt weiter, indem sie die Vektorsuche mit SQL integriert. Dadurch sind komplexe und präzise Dateninteraktionen möglich. Diese Integration vereinfacht die Entwicklung und reduziert die Lernkurve für den Aufbau robuster RAG-Anwendungen.
Sie sind herzlich eingeladen, das Open-Source-MyScaleDB-Repository auf GitHub (opens new window) zu erkunden und SQL und Vektoren zu nutzen, um innovative RAG-Anwendungen auf Produktionsniveau zu entwickeln.
Dieser Artikel wurde ursprünglich auf The New Stack veröffentlicht. (opens new window)



