
Mit dem stetigen Wachstum von Datenmengen und -komplexität werden skalierbare NoSQL-Datenbanklösungen zunehmend zu einer beliebten Alternative zu traditionellen relationalen Datenbanken. Ein Typ, der viel Interesse weckt, ist die Vektordatenbank. Mit fortschrittlichen semantischen Suchfunktionen versprechen Vektordatenbanken eine hochdimensionale Vektorsuche anstelle von herkömmlichen SQL-Abfragen, um Daten basierend auf ihrer Bedeutung und Ähnlichkeit zu organisieren und abzurufen.
Bevor Sie eine Vektordatenbank wählen, sollten Sie einige wichtige Faktoren sorgfältig berücksichtigen, um sicherzustellen, dass sie sowohl Ihren Anwendungs- als auch Ihren Analyseanforderungen sowohl jetzt als auch in Zukunft gerecht wird. Das ist es, worüber wir in diesem Blog diskutieren werden. Diese Faktoren sind in drei Hauptkategorien unterteilt: die Kernfunktionalitäten einer Vektordatenbank, die betrieblichen Überlegungen und die Benutzerfreundlichkeit und das Ökosystem. Fangen wir an!
# Kernfunktionalitäten
Die Kernfunktionalitäten einer Vektordatenbank umfassen Leistung, Indexierungsmethoden, Abfragesprache und API-Unterstützung sowie Datenmodell und Schema.
# Leistung
Bei der Auswahl einer Vektordatenbank ist die Leistung entscheidend, da sie einen reibungslosen Betrieb der Anwendung gewährleistet und effiziente Suchen nach ähnlichen Elementen, nächstgelegenen Nachbarvektoren und Datenanalysen ermöglicht. Die Leistung einer Vektordatenbank kann anhand der folgenden Faktoren gemessen werden:
- Anzahl der Abfragen pro Sekunde (QPS): Dies misst, wie viele Abfragen Ihre Datenbank pro Sekunde verarbeiten kann. Eine höhere QPS bedeutet, dass die Datenbank mehr gleichzeitige Suchvorgänge unterstützen kann, was für Anwendungen, die Echtzeit-Datenanalysen oder Benutzerinteraktionen erfordern, entscheidend ist.
- Durchschnittliche Abfrage-Latenz: Es geht darum, wie lange es dauert, bis die Datenbank nach einer Abfrage ein Ergebnis zurückgibt. Eine geringere Latenz sorgt dafür, dass Ihre Anwendung schneller und reaktionsschneller für den Benutzer ist und das gesamte Benutzererlebnis verbessert.
- Eingabezeit der Daten: Die Geschwindigkeit, mit der neue Daten zur Datenbank hinzugefügt werden können, ist besonders wichtig in dynamischen Umgebungen, in denen Daten ständig aktualisiert werden. Eine effiziente Datenübernahme stellt sicher, dass Ihre Datenbank immer auf dem neuesten Stand ist und für Abfragen bereit ist.
MyScaleDB ist eine Vektordatenbank mit herausragender Leistung im Vergleich zu anderen Vektordatenbanken. Für größere Datensätze meldet MyScaleDB nun eine verbesserte Leistung (opens new window) mit 390 QPS (Abfragen pro Sekunde) auf dem LAION 5M Datensatz, erreicht eine 95% Rückrufquote und behält eine durchschnittliche Abfrage-Latenz von 18 ms mit dem x1 Pod bei.
MyScaleDB hat auch andere Vektordatenbanken in Bezug auf die Eingabezeit der Daten übertroffen, indem es Aufgaben in nur 30 Minuten für 5M Datenpunkte abgeschlossen hat. Wenn Sie sich anmelden, können Sie den x1 Pod kostenlos nutzen, der bis zu 5 Millionen Vektoren verarbeiten kann.
Verwandter Artikel: Wie MyScale andere spezialisierte Vektordatenbanken übertrifft? (opens new window)
# Indexierungsmethode
Der Schlüssel zu einer Vektordatenbank liegt darin, wie sie die hochdimensionalen Vektordaten verarbeitet. Unterschiedliche Vektordatenbanken verwenden verschiedene Indexierungsmethoden, um sicherzustellen, dass Daten schnell und genau gefunden werden können und alles organisiert und effizient bleibt. Hier sind einige gängige Indexierungsmethoden in Vektordatenbanken:
- k-d-Bäume sind Baumstrukturen, die zum Indexieren von Punkten in einem k-dimensionalen Raum verwendet werden. Sie sind besonders nützlich für mehrdimensionale Daten wie Vektoren. k-d-Bäume partitionieren den Raum in Regionen und erleichtern so schnelle Nachbar-Suchvorgänge.
- Ballbäume sind ähnlich wie k-d-Bäume, aber effektiv für Datensätze mit variabler Dichte. Sie repräsentieren den Datensatz, indem sie Punkte in Hypersphären einschließen, was sie für Anwendungen wie Nachbar-Suchvorgänge geeignet macht.
- Lokalitätssensitive Hashing (LSH) ist eine probabilistische Methode zum Hashen von Eingabeelementen, sodass ähnliche Elemente mit hoher Wahrscheinlichkeit auf dieselben Buckets abgebildet werden. Es eignet sich für ungefähre Ähnlichkeitssuchen und ist daher für Anwendungen wie Empfehlungssysteme geeignet.
- Graphenbasierte Indizes stellen Daten als Graphen dar, wobei Knoten und Kanten als Vektoren und Beziehungen repräsentiert werden. Dieser Index eignet sich gut zur Erfassung komplexer Beziehungen und wird häufig in Anwendungen wie der Analyse sozialer Netzwerke verwendet.
- Invertierter Datei (IVF) Vektorindex ist eine Methode für effiziente Ähnlichkeitssuche in hochdimensionalen Vektorräumen. Dabei werden die Vektoren in Voronoi-Zellen partitioniert, wobei jede Zelle einem Zentroiden entspricht, und es wird ein invertierter Index erstellt, um Vektoren innerhalb einer bestimmten Zelle während Abfragen schnell zu lokalisieren.
- Produktquantisierung (PQ) teilt Vektoren in kleinere Teilvektoren auf und quantisiert sie unabhängig voneinander. Es ist effizient für hochdimensionale Daten und wird häufig in Anwendungen zur Bildsuche verwendet. PQ kann effektiv mit graphenbasierten Indizes sowie IVF kombiniert werden.
- Räumliches Hashing teilt den Vektorraum in Zellen auf und weist jedem Vektor basierend auf seiner Position eine Zelle zu. Diese Methode ist nützlich für räumliche Abfragen und wird häufig in Computergrafik und computergestütztem Design verwendet.
Viele Algorithmen stoßen auf Einschränkungen, insbesondere wenn die Indexgröße für massive Datensätze stark zunimmt, was eine Speicherung aller Vektordaten im Arbeitsspeicher erfordert. Multi-Scale Tree Graph (MSTG) (opens new window) wurde von MyScaleDB entwickelt und überwindet diese Einschränkungen, indem es hierarchisches Baumclustering mit Graphentraversierung und Speicherung mit schnellen NVMe SSDs kombiniert. MSTG reduziert den Ressourcenverbrauch von IVF/HNSW erheblich und behält gleichzeitig eine außergewöhnliche Leistung bei. Es baut schnell auf, sucht schnell und bleibt unter verschiedenen gefilterten Suchverhältnissen schnell und genau, während es ressourcen- und kosteneffizient ist.
# Abfragesprache und API-Unterstützung
Die Abfragesprache und die Unterstützung der Anwendungsprogrammierschnittstelle (API) bestimmen, wie Benutzer mit der Datenbank interagieren und Informationen abrufen können. Sie sind entscheidende Faktoren, um zu bewerten, ob eine Vektordatenbank benutzerfreundlich, anpassungsfähig und nahtlos in verschiedene technologische Ökosysteme integrierbar ist. Diese Komponenten ermöglichen es Benutzern, wertvolle Erkenntnisse zu gewinnen, indem sie mit der Datenbank interagieren und so ein reibungsloses und effektives Datenmanagementerlebnis ermöglichen.
MyScaleDB ist eine All-in-One-Vektordatenbank und vollständig kompatibel mit SQL, was nicht nur komplexe Datenoperationen, semantische Suche und strukturierte Datenabfragen über SQL vereinfacht, sondern auch ideal für fast alle Entwickler ist, um vorhandenes SQL-Wissen zur Nutzung einer Vektordatenbank und zur Durchführung von Datenaufgaben einzusetzen. Gleichzeitig erleichtert die API-Unterstützung von MyScaleDB die Automatisierung und Integration mit anderen Systemen.
# Datenmodell und Schema
Das Datenmodell und Schema einer Vektordatenbank sind ihre Baupläne, die bestimmen, wie Daten gespeichert und abgerufen werden. Dies wirkt sich auf die Speichereffizienz, die Abfrageleistung, die Skalierbarkeit und die Entwicklererfahrung aus. MyScaleDB verwendet ein hybrides Datenmodell, das die Stärken strukturierter und vektorieller Datenrepräsentationen kombiniert. Das bedeutet, dass es sowohl tabellarische Daten (wie traditionelle Datenbanken) als auch hochdimensionale Vektoren effektiv speichern kann.
# Betriebliche Überlegungen
Lassen Sie uns Skalierbarkeit, Sicherheit und Überwachung als betriebliche Überlegungen einer Vektordatenbank diskutieren.
# Skalierbarkeit
Skalierbarkeit bezieht sich auf die Fähigkeit einer Vektordatenbank, steigende Datenmengen und Benutzeranforderungen zu bewältigen, ohne die Leistung oder Funktionalität zu beeinträchtigen. Bei Vektordatenbanken gibt es zwei Arten von Skalierung: vertikale Skalierung und horizontale Skalierung. Bei der vertikalen Skalierung wird die Rechenleistung von Hardware und Software erweitert. Bei der horizontalen Skalierung erfolgt die Hinzufügung zusätzlicher Serverknoten. Dies ist entscheidend, um Ihre Vektordatenbank zukunftssicher zu machen und sicherzustellen, dass sie das Wachstum Ihrer KI-Anwendungen unterstützen kann. MyScaleDB bietet vertikale Skalierung.
# Sicherheit
Die Sicherheit in einer Vektordatenbank umfasst verschiedene Aspekte, die sowohl die Daten selbst als auch die Funktionalität des Datenbanksystems schützen. Suchen Sie nach Funktionen wie Verschlüsselung, Zugriffskontrollen, Authentifizierungsmechanismen, Netzwerksicherheit und Notfallwiederherstellung in Ihrer Vektordatenbank, da sie als digitaler Schutzschild dienen, der Ihre Daten sicher und geschützt hält.
MyScaleDB wird von Teams und Organisationen wie Ihrer aus verschiedenen Gründen vertraut.
- MyScaleDB läuft auf einem mandantenfähigen Kubernetes-Cluster auf einer vollständig verwalteten und sicheren AWS-Infrastruktur.
- Es stellt sicher, dass Kundendaten in isolierten Containern gespeichert werden.
- Der Zugriff auf Ihre Daten aus Gründen, die über API-Serviceaufrufe hinausgehen, ist strengstens untersagt.
- MyScaleDB überwacht ausschließlich operative Metriken, um die Systemgesundheit und -leistung aufrechtzuerhalten.
- MyScaleDB hat die SOC 2 Type 1-Konformität erreicht und erfüllt damit den weltweit höchsten Standard für die Sicherheit von Informationen.
# Überwachung
Die Überwachung spielt bei der Auswahl einer Vektordatenbank aus mehreren Gründen eine entscheidende Rolle. Sie liefert uns Einblicke und Fortschrittsverfolgung, um zeitnahe Entscheidungen für die Leistungsoptimierung, kontinuierliche Verbesserung und Anpassungsfähigkeit zu treffen.
MyScaleDB bietet umfassende Überwachungstools, um Leistungsmetriken, Ressourcennutzung und Sicherheitsereignisse zu verfolgen und Echtzeit-Einblicke in die Gesundheit und Aktivität Ihrer Datenbank zu erhalten.
Verwandter Artikel: Leistungssteigerung mit Retrieval Augmented Generation (opens new window)
# Benutzerfreundlichkeit und Ökosystem
Benutzerfreundlichkeit und Ökosystem umfassen Preisgestaltung, Dokumentation, Community, Support und Ökosystemintegration.
# Community und Support
Die Unterstützung der Community spielt eine wichtige Rolle bei der effektiven Nutzung von Vektordatenbanken. Sie befähigt Benutzer, fördert die Zusammenarbeit und trägt zur kontinuierlichen Verbesserung und zum Erfolg von Vektordatenbankimplementierungen in verschiedenen Anwendungen und Branchen bei. Sie hilft auch bei der Fehlerbehebung und der Klärung von Fragen. MyScaleDB bietet umfassende Unterstützung über verschiedene Kanäle wie Discord (opens new window), Twitter (opens new window), LinkedIn (opens new window) und Medium (opens new window). Und Sie können prompte Antworten von den technischen Experten von MyScaleDB über diese Kanäle erhalten.
# Preisgestaltung
Die Preisgestaltung ist ein wichtiger Faktor bei der Auswahl einer Vektordatenbank. Ein klares Verständnis der Preisgestaltung gewährleistet eine kostengünstige und nachhaltige Beziehung zur Vektordatenbank. Informieren Sie sich über die von verschiedenen Datenbanken angebotenen Preismodelle und bewerten Sie, wie sie mit Ihrem Budget und Ihren Nutzungsanforderungen übereinstimmen.
MyScaleDB bietet verschiedene Preisoptionen (opens new window), einschließlich kostenloser Dienste für Einzelpersonen für kleine Anwendungen. Es bietet auch ein Standardpaket für KI-Dienste und ein Unternehmenspaket für große Organisationen. MyScaleDB berechnet Speicherung und Berechnung getrennt, dh die Berechnungsgebühr wird nur dann berechnet, wenn Abfragen ausgeführt werden. Und kürzlich hat MyScaleDB einen neuen kapazitätsoptimierten Pod für nur 68 $/Monat eingeführt, der 10 Millionen 768D-Vektoren hosten kann, sodass Sie leistungsstarke GenAI-Apps erstellen können, ohne Ihr Budget zu sprengen.
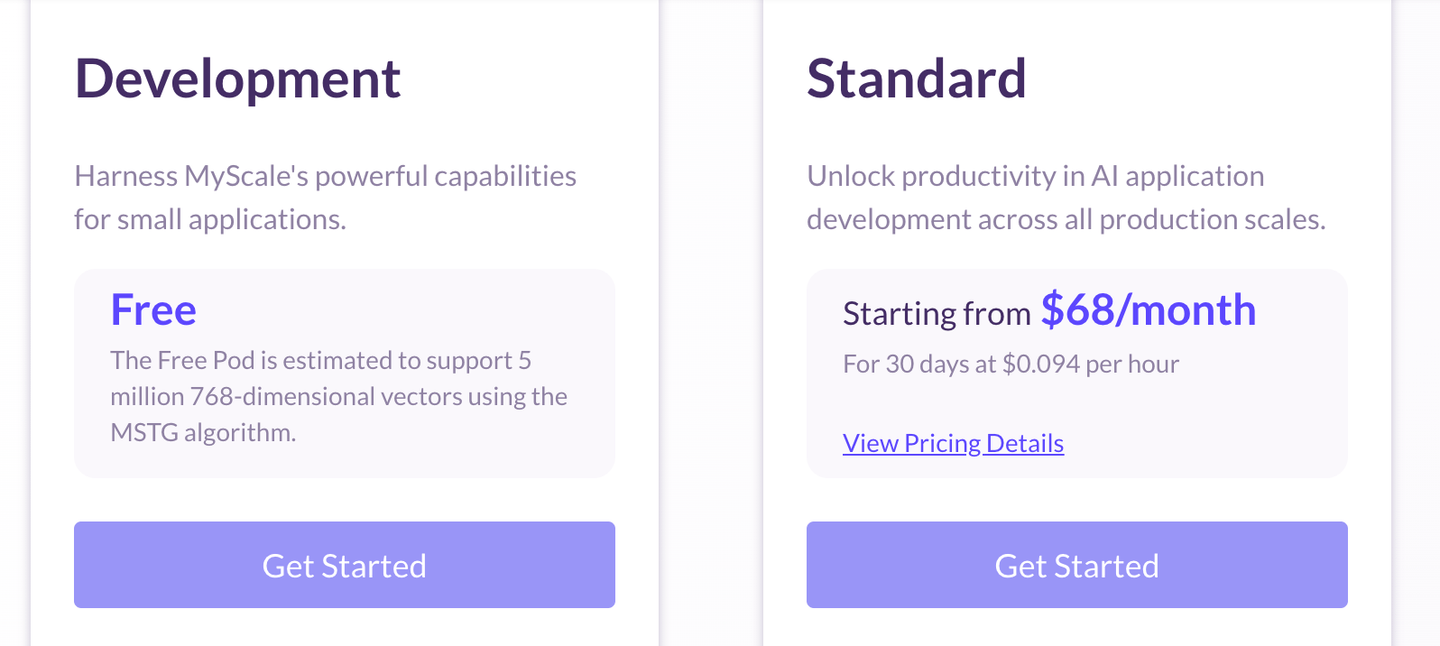
Wenn Sie eine Schätzung der Größe Ihres Datenvektors haben, können Sie den Preis auch mit dem Preisschätzer berechnen.
# Ökosystemintegrationen
Lassen Sie uns die Ökosystemintegrationen unten diskutieren:
Entwicklertools: Entwicklertools sind entscheidend bei der Auswahl der richtigen Vektordatenbank für Ihr Projekt. Sie können die Produktivität und Effizienz steigern, indem sie vorhandene Entwicklertools integrieren, mit denen Sie vertraut sind. MyScaleDB hat verschiedene Entwicklertools integriert, wie Python-Client (opens new window), Node.js (opens new window), Go-Client (opens new window), ClientJDBC-Treiber (opens new window) und HTTPS-Schnittstelle (opens new window).
Große Sprachmodelle (LLM): Die Integration von LLM erweitert die Fähigkeiten einer Vektordatenbank erheblich, indem sie erweiterte semantische Suche, Kontextualisierung von Daten, personalisierte Empfehlungen, Wissenserweiterung und konversationelle Schnittstellen ermöglicht. MyScaleDB bietet mehrere LLM-Integrationen, darunter OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window) und LlamaIndex (opens new window).
Verwandter Artikel: Erweiterte Facebook Event Data Analysis mit einer Vektordatenbank (opens new window)
# Dokumentation
Die Verfügbarkeit der ausführlichen Dokumentation ist wichtig bei der Auswahl einer Vektordatenbank. Sie hilft bei der Funktionsweise, effizienten Entwicklung, Integration, langfristigen Unterstützung und stellt einen reibungslosen Lernprozess sicher.
MyScaleDB bietet umfangreiche und detaillierte Dokumentation, die Benutzerhandbücher (opens new window), Tutorials (opens new window), Blogs (opens new window), Beispielanwendungen (opens new window) und API-Integration (opens new window) umfasst, sowie aktive Supportkanäle wie Discord und Twitter.

# Vergleich
Lassen Sie uns MyScaleDB mit einigen beliebten Vektordatenbanken vergleichen.
| Funktionen | MyScaleDB | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| Open Source | Ja | Nein | Ja | Ja | Ja |
| SQL | Ja | Nein | Nein | Nein | Nein |
| Cloud-Bereitstellung | Ja | Ja | Ja | Ja | Ja |
| Abfragesprachen | SQL & SDKs | SDKs | GraphQL | C++, Python SDKs | SDKs |
| LLM-Integration | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain | Llamalindex, LangChain |
| Kosten | Kostenlose & kostenpflichtige Stufen | Kostenpflichtige Stufen | 14 Tage kostenlos & kostenpflichtige Stufen | Kostenpflichtige Stufen | Kostenlose & kostenpflichtige Stufen |
# Fazit
Es ist nicht einfach, eine geeignete Vektordatenbank auszuwählen. Wir haben verschiedene Faktoren diskutiert, die Sie vor der Auswahl einer Vektordatenbank berücksichtigen können, einschließlich drei Hauptkategorien, die die Kernfunktionalitäten, betrieblichen Überlegungen, Benutzerfreundlichkeit und Ökosystemintegration abdecken.
Wenn Sie eine effiziente Handhabung von Datenmengen im großen Maßstab und den Umgang mit Datenkomplexität als Auswahlkriterien der obersten Kategorie betrachten, sollten Sie MyScaleDB in Betracht ziehen. Durch die Kombination der Stärken von ClickHouse und dem MSTG-Algorithmus bietet MyScaleDB kostengünstige Lösungen für komplexe und groß angelegte Vektorsuchen sowohl in Geschwindigkeit als auch in Präzision.
Sie finden auch Benchmark-Berichte zwischen MyScaleDB und anderen Wettbewerbern in den folgenden Inhalten:



