
ChatGPT (opens new window) und andere große Sprachmodelle (LLMs) (opens new window) haben große Fortschritte bei der Verarbeitung und Generierung von textähnlichen menschlichen Texten gemacht. Sie haben jedoch oft Schwierigkeiten, genau und relevant zu bleiben, insbesondere in schnelllebigen oder spezialisierten Bereichen. Dies liegt daran, dass sie auf großen, aber festen Datensätzen beruhen, die schnell veraltet sein können. Hier können Vektordatenbanken (opens new window) helfen, indem sie eine Möglichkeit bieten, diese Modelle auf dem neuesten Stand zu halten und kontextbewusst zu machen.
Vektordatenbanken bieten eine Lösung für diese Herausforderung, indem sie LLMs wie ChatGPT Zugriff auf relevante und aktuelle Informationen ermöglichen, die über ihr ursprüngliches Training hinausgehen. Durch die Integration von Vektordatenbanken können diese Modelle spezifische, auf den Bereich bezogene Daten abrufen und nutzen, was zu einer verbesserten Antwortgenauigkeit und kontextuellen Bewusstsein führt.
Dieser Artikel untersucht, wie die Nutzung von Vektordatenbanken die Leistung von ChatGPT verbessern kann. Wir werden untersuchen, wie die leistungsstarken Abruffähigkeiten von Vektordatenbanken es ChatGPT ermöglichen, spezialisierte Aufgaben und detaillierte Fragen effektiver zu bearbeiten und es zu einem zuverlässigeren und vielseitigeren Werkzeug für Benutzer zu machen.
# Verständnis von Vektordatenbanken
Bevor wir ihre Integration diskutieren, ist es wichtig zu verstehen, was Vektordatenbanken sind und wie sie die KI revolutionieren.
# Was ist eine Vektordatenbank?
Eine Vektordatenbank ist eine spezielle Art von Datenbank, die dazu entwickelt wurde, komplexe Datenpunkte, sogenannte Vektoren (opens new window), zu verarbeiten. Vektoren sind wie Listen von Zahlen, die Daten auf eine Weise darstellen, die den Vergleich und das Finden von Ähnlichkeiten erleichtert. Anstatt Informationen in Zeilen und Spalten wie herkömmliche Datenbanken zu organisieren, speichern Vektordatenbanken Daten als diese numerischen Listen. Dadurch sind sie sehr gut geeignet für Aufgaben, bei denen es darum geht, Muster und Ähnlichkeiten zu finden, wie z.B. Produktempfehlungen oder die Identifizierung ähnlicher Bilder.
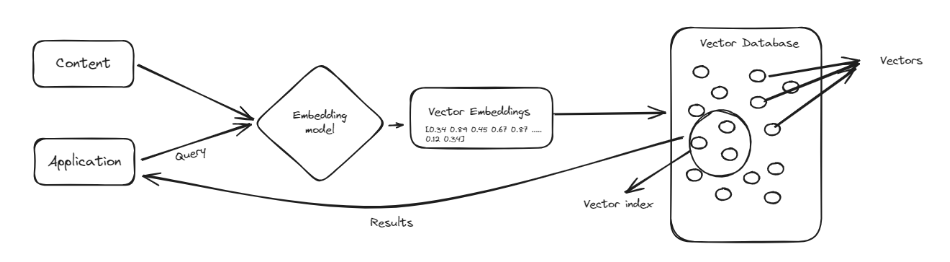
Einer der Hauptvorteile von Vektordatenbanken ist ihre Fähigkeit, schnell durch große Datenmengen zu suchen, um relevante Informationen zu finden. Sie sind besonders nützlich in Bereichen wie maschinellem Lernen und künstlicher Intelligenz, wo das Verständnis von Beziehungen zwischen Datenpunkten entscheidend ist. Durch die Verwendung von Vektordatenbanken können wir Tools wie ChatGPT verbessern, indem wir sie intelligenter und effizienter bei der Verarbeitung und Abruf von Informationen machen, was zu besseren und genaueren Antworten führt.
# Vektordatenbanken vs. traditionelle Datenbanken
Wenn es darum geht, strukturierte Datensätze zu verwalten und die Integrität der gespeicherten Daten sicherzustellen, haben traditionelle relationale Datenbanken keine Konkurrenz; jedoch im Vergleich zu ihnen:
- Vektordatenbanken sind flexibler im Umgang mit mehrdimensionalen Datenpunkten.
- Vektordatenbanken verarbeiten große Mengen an Informationen schneller.
- Ähnlichkeitsbasierte Abrufmethoden funktionieren auf Vektordatenbanken aufgrund ihrer Effizienz bei der schnellen Verarbeitung von Operationen während der Mustererkennung oder Ähnlichkeitsabgleichung, die für KI-Anwendungen wichtig sind, besser.
# Warum Vektordatenbanken für ChatGPT wichtig sind
LLMs wie ChatGPT haben bemerkenswerte Fortschritte in der natürlichen Sprachverarbeitung und -generierung gezeigt. Diese Modelle haben jedoch auch mehrere Einschränkungen, die durch die Integration von Vektordatenbanken behoben werden können.
- Wissenshalluzinationen: Eine Vektordatenbank würde als zuverlässige Wissensbasis dienen und falsche Informationen reduzieren.
- Keine Speicherfähigkeit für Langzeitgedächtnis: Durch die effiziente Speicherung relevanter Daten kann man sie als ein weiteres Gedächtnis für das jeweilige Modell betrachten.
- Problem des kontextuellen Verständnisses: Vektorrepräsentationen ermöglichen ein nuanciertes Verständnis von Kontext und Beziehungen zwischen Konzepten.
# Integration von ChatGPT mit MyScale für einen KI-Personalassistenten
In diesem Tutorial werden wir den Prozess der Integration von ChatGPT mit MyScale (opens new window), einer leistungsstarken Vektordatenbank, durchgehen, um einen KI-Personalassistenten zu erstellen, der in der Lage ist, Mitarbeiteranfragen rund um die Uhr zu beantworten. Dieses praktische Beispiel zeigt, wie Vektordatenbanken ChatGPT durch Bereitstellung von aktuellen, domänenspezifischen Informationen verbessern können.
# Schritt 1: Umgebung einrichten
Zunächst müssen wir unsere Umgebung einrichten, indem wir die erforderlichen Bibliotheken installieren. Diese Bibliotheken umfassen langchain zur Verwaltung von Sprachmodellen und Textverarbeitung, sentence-transformers zur Erstellung von Einbettungen und openai für das ChatGPT-Modell.
pip install langchain sentence-transformers openai
# Schritt 2: Umgebungsvariablen konfigurieren
Wir müssen die Umgebungsvariablen konfigurieren, um eine Verbindung zu MyScale und der OpenAI API herzustellen. Diese Variablen umfassen den Host, den Port, den Benutzernamen und das Passwort für MyScale sowie den API-Schlüssel für OpenAI.
import os
# Einrichtung der Verbindungen zur Vektordatenbank
os.environ["MYSCALE_HOST"] = "Ihr_Host_Name_hier"
os.environ["MYSCALE_PORT"] = "Port_Nummer"
os.environ["MYSCALE_USERNAME"] = "Ihr_Benutzername_hier"
os.environ["MYSCALE_PASSWORD"] = "Ihr_Passwort_hier"
# Einrichtung des API-Schlüssels für OpenAI
os.environ["OPENAI_API_KEY"] = "Ihr_API-Schlüssel_hier"
Hinweis: Wenn Sie kein MyScaleDB (opens new window) Konto haben, besuchen Sie die MyScale-Website, um sich für ein kostenloses Konto anzumelden, und folgen Sie der Schnellstartanleitung (opens new window). Um die OpenAI API zu verwenden, erstellen Sie ein Konto auf der OpenAI-Website (opens new window) und erhalten Sie den API-Schlüssel.
# Schritt 3: Daten laden
Wir laden das Mitarbeiterhandbuch im PDF-Format und teilen es in Seiten zur weiteren Verarbeitung auf. Hierzu verwenden wir einen Dokumentenlader.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Mitarbeiterhandbuch.pdf")
pages = loader.load_and_split()
# Falls erforderlich, die ersten Seiten überspringen
pages = pages[4:]
Die Klasse PyPDFLoader wird verwendet, um PDF-Dokumente effizient zu laden und den Ladevorgang nahtlos zu handhaben. Die Methode load_and_split() liest das Dokument und teilt es in einzelne Seiten auf, um den Text für die weitere Verarbeitung handlicher zu machen. Mit pages = pages[4:] entfernen wir die ersten vier Seiten, um irrelevante Informationen wie den Umschlag oder das Inhaltsverzeichnis auszuschließen.
# Schritt 4: Daten bereinigen
Nun bereinigen wir den aus dem PDF extrahierten Text, um unerwünschte Zeichen, Leerzeichen und Formatierungen zu entfernen.
import re
def clean_text(text):
# Entfernen aller Zeilenumbrüche und Ersetzen mehrerer Zeilenumbrüche durch ein einzelnes Leerzeichen
text = re.sub(r'\\s*\\n\\s*', ' ', text)
# Entfernen aller mehrfachen Leerzeichen und Ersetzen durch ein einzelnes Leerzeichen
text = re.sub(r'\\s+', ' ', text)
# Entfernen aller Zahlen am Anfang von Zeilen (wie '1 ', '2 ', usw.)
text = re.sub(r'^\\d+\\s*', '', text)
# Entfernen aller verbleibenden unerwünschten Leerzeichen oder Sonderzeichen
text = re.sub(r'[^A-Za-z0-9\\s,.-]', '', text)
# Führende und abschließende Leerzeichen entfernen
text = text.strip()
return text
text = "\\n".join([doc.page_content for doc in pages])
cleaned_text = clean_text(text)
Die Funktion clean_text verarbeitet und bereinigt den Text. Sie entfernt Zeilenumbrüche, mehrfache Leerzeichen, Zahlen am Anfang von Zeilen und alle verbleibenden unerwünschten Zeichen, sodass sauberer und standardisierter Text entsteht.
# Schritt 5: Daten aufteilen
Der nächste Schritt besteht darin, den Text in kleinere, handhabbare Abschnitte für die Verarbeitung für unsere KI-Anwendung aufzuteilen.
from langchain.text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Maximale Größe jedes Abschnitts
chunk_overlap=300, # Überlappung zwischen den Abschnitten
length_function=len, # Funktion zur Berechnung der Länge
is_separator_regex=False,
)
docs = text_splitter.create_documents([cleaned_text])
Die Klasse RecursiveCharacterTextSplitter teilt den Text in Abschnitte einer bestimmten Größe mit Überlappung auf, um die Kontinuität zu gewährleisten. Dadurch wird sichergestellt, dass der Text in handhabbare Stücke zerlegt wird, ohne den Kontext zu verlieren.
# Schritt 6: Das Einbettungsmodell definieren
Wir definieren das Einbettungsmodell mit Hilfe von OpenAIEmbeddings, um Textabschnitte in Vektorrepräsentationen umzuwandeln.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
Die Klasse OpenAIEmbeddings initialisiert ein vortrainiertes Transformer-Modell, um Einbettungen (Vektorrepräsentationen) für die Textabschnitte zu erstellen, die die semantische Bedeutung des Textes erfassen.
# Schritt 7: Daten zur MyScale-Vektorspeicher hinzufügen
Nun fügen wir die vektorisierten Textabschnitte zur MyScale-Vektorspeicher (opens new window) für eine effiziente Suche hinzu.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
Die Methode MyScale.from_documents(docs, embeddings) speichert die Vektorrepräsentationen der Textabschnitte in der MyScale-Vektordatenbank, was effiziente Ähnlichkeitssuchen ermöglicht.
# Schritt 8: Eine Ähnlichkeitssuche durchführen
Führen wir eine Ähnlichkeitssuche auf den gespeicherten Vektoren durch, um die Funktionsweise unseres Vektorspeichers zu testen.
output = docsearch.similarity_search("Wie viel Benzin bekommen die Mitarbeiter?", 3)
Die Methode similarity_search sucht in der Vektordatenbank nach Vektoren, die der Abfrage ähnlich sind, und ruft die besten sechs Übereinstimmungen ab. Nachdem Sie die Abfrage gestellt haben, erhalten Sie Ergebnisse wie diese:
[Document(page_content='Der Mitarbeiter kann sich für einen zusätzlichen Beitrag zum Pensionsfonds über den freiwilligen Pensionsfonds VPF Arbeitgeberbeitrag 12 des Grundgehalts des Mitarbeiters 9.2Gratifikation Gratifikation wird gemäß dem Gratifikationsgesetz von 1972 an alle berechtigten Mitarbeiter von Adino Telecom Ltd. gezahlt. Der Arbeitgeber zahlt dem berechtigten Mitarbeiter für jedes abgeschlossene Dienstjahr von mehr als 5 Jahren eine Gratifikation in Höhe von 15 Tagen Gehalt pro abgeschlossenem Dienstjahr. Die Gehaltsrate entspricht dem letzten Gehalt. 9.3Mediclaim Krankenversicherung Alle berechtigten Mitarbeiter sind gemäß dem Star Healthc laim Medical Policy für sich selbst, den Ehepartner und das Kind bis zu Rs.1 lakh versichert. 9.4ESIC Alle berechtigten Mitarbeiter sind gemäß dem ESI Act von 1948 versichert. Alle Mitarbeiter, die ein monatliches Gehalt von bis zu Rs. 10.000 erhalten, sind in das ESI-System aufnehmbar. Mitarbeiterbeitrag In Höhe von 1,75 des Gehalts Arbeitgeberbeitrag In Höhe von 4,75 des Gehalts.', metadata={'_dummy': 0}),
Document(page_content='ZUGEWIESEN PRO MONATin Rs M5 M4 1500 M3 M2 1250 M1 M0 800 O1 O2 420 A1, A2 A3 300 Bitte beachten Sie, dass außer für Business Manager, die internationale Anrufe tätigen müssen, keine Sondergenehmigung erteilt wird. Bitte beachten Sie, dass die oben genannten Werte Änderungen unterliegen 437.3Fahrtkostenzuschuss Bis DM-Ebene maximal Rs. 1875 pro Monat, das tatsächlich geltend gemacht werden kann Manager-Ebene maximal Rs. 2.200 pro Monat, das tatsächlich geltend gemacht werden kann Sr. Manager DGM-Ebene maximal Rs. 2.575 pro Monat, das tatsächlich geltend gemacht werden kann GM mit Auto maximal Rs. 6.000 pro Monat, das tatsächlich geltend gemacht werden kann. Autowartung maximal Rs. 2.000 pro Monat und Rs. 8000 pro Jahr. Die Fahrtkosten müssen auf den oben genannten Beträgen gehalten werden und es wird keine Erstattung über den genannten Betrag hinaus gewährt. Bei bezahlten Umfragen beträgt die Fahrtkostenpauschale Rs. 5.000 pro Monat. Bitte beachten Sie, dass die oben genannten Werte Änderungen unterliegen 447.4Internetgebühren Rs. 300 pro Monat für Internetgebühren gelten nur für Mitarbeiter der Stufe M5. 7.5Schulungspolitik', metadata={'_dummy': 0}),
Document(page_content='wird nach Abschluss jedes Jahres während Diwali ausgezahlt. 4.Leistungsanreiz Die Mitarbeiter haben Anspruch auf Leistungsanreize, die auf ihrer Leistung im Laufe des Jahres basieren. Der Anreiz wird einmal im Jahr ausgezahlt. 5.Medizinische Leistungen Berechtigte Mitarbeiter sind durch die Star Health Insurance Policy Scheme versichert. 6.Alle Mitarbeiter, die unter die Einkommensteuer fallen, sollten ihre Anlagepläne bis September jedes Finanzjahres einreichen. 7.Alle Anlageplan-Nachweise müssen bis Ende Januar eingereicht werden. 499.Vorteile 509.1Pensionsfonds Alle Mitarbeiter sind gemäß dem Pensionsfondsgesetz von 1952 versichert, wonach der Arbeitnehmerbeitrag 12 des Grundgehalts beträgt. Der Mitarbeiter kann sich für einen zusätzlichen Beitrag zum Pensionsfonds über den freiwilligen Pensionsfonds VPF Arbeitgeberbeitrag 12 des Grundgehalts des Mitarbeiters 9.2Gratifikation Gratifikation wird gemäß dem Gratifikationsgesetz von 1972 an alle berechtigten Mitarbeiter von Adino Telecom', metadata={'_dummy': 0})]
# Schritt 9: Den Retriever festlegen
Nun wandeln wir diesen Vektorspeicher von einer Dokumentsuchmaschine in einen Retriever um. Dieser wird von der LLM-Kette verwendet, um relevante Informationen abzurufen.
retriever = docsearch.as_retriever()
Die Methode as_retriever konvertiert den Vektorspeicher in ein Retriever-Objekt, das relevante Dokumente basierend auf ihrer Ähnlichkeit zur Abfrage abruft.
# Schritt 10: Das LLM und die Kette definieren
Der letzte Schritt besteht darin, das LLM (ChatGPT) zu definieren und eine retrievalbasierte QA-Kette einzurichten.
from langchain_openai import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=False,
)
Die Klasse OpenAI initialisiert das ChatGPT-Modell, während RetrievalQA.from_chain_type eine QA-Kette einrichtet, die den Retriever verwendet, um relevante Dokumente abzurufen, und das Sprachmodell verwendet, um Antworten zu generieren.
# Schritt 11: Die Kette abfragen
Wir stellen eine Anfrage an die QA-Kette, um Antworten von dem KI-Personalassistenten zu erhalten.
# Die Kette abfragen
response1 = qa.run("Wie hoch ist die Fahrtkostenzulage?")
print(response1)
Die Methode qa.run(query) sendet eine Anfrage an die QA-Kette, die relevante Dokumente abruft und eine Antwort mit Hilfe von ChatGPT generiert. Die Antworten auf die Anfragen werden dann ausgegeben.
Nachdem Sie die Anfrage gestellt haben, erhalten Sie eine Antwort wie diese:
"Die Fahrtkostenzulage variiert je nach Gehaltsgruppe und -stufe des Mitarbeiters und reicht von Rs. 1.875 pro Monat für Mitarbeiter der DM-Stufe bis zu maximal Rs. 6.000 pro Monat für Mitarbeiter der GM-Stufe mit einem Auto. Die Beträge können sich ändern."
Stellen wir eine weitere Anfrage:
response2 = qa.run("Wie sind die Büroarbeitszeiten?")
print(response2)
Diese Anfrage liefert Ergebnisse ähnlich wie diese:
'Die Büroarbeitszeiten sind von 9:00 Uhr bis 17:45 Uhr oder von 9:30 Uhr bis 18:15 Uhr, wobei bestimmte Mitarbeiter möglicherweise unterschiedliche Zeitpläne oder Schichten haben.'
So können wir die Leistung von ChatGPT durch Integration mit Vektordatenbanken verbessern. Dadurch stellen wir sicher, dass das Modell auf aktuelle, domänenspezifische Informationen zugreifen kann, was zu genaueren und relevanteren Antworten führt.

# Warum MyScale als Vektordatenbank wählen
MyScale zeichnet sich als Vektordatenbank durch seine volle Kompatibilität mit SQL (opens new window) aus, was komplexe Datenoperationen und semantische Suchen vereinfacht. Entwickler können vertraute SQL-Abfragen verwenden, um Vektoren zu verarbeiten, ohne neue Tools erlernen zu müssen. MyScale's fortschrittliche Vektorindexierungs-Algorithmen und OLAP-Architektur gewährleisten eine hohe Leistung und Skalierbarkeit, was es für die effiziente Verwaltung von Daten großer KI-Anwendungen geeignet macht.
Sicherheit und einfache Integration sind weitere Stärken von MyScale. Es läuft auf einer sicheren AWS-Infrastruktur und bietet Funktionen wie Verschlüsselung und Zugriffskontrollen zum Schutz von Daten. MyScale unterstützt auch umfangreiche Überwachungstools (opens new window), die Echtzeiteinblicke in die Leistung und Sicherheit von LLM-Anwendungen bieten. Als Open-Source-Plattform fördert MyScale Innovation und Anpassungsfähigkeit, was es zu einer vielseitigen Wahl für verschiedene KI-Projekte macht.
# Fazit
Die Kombination von LLMs wie ChatGPT mit Vektordatenbanken ermöglicht es Entwicklern, leistungsstarke Anwendungen zu erstellen, ohne die Modelle auf neue Daten neu trainieren zu müssen. Diese Konfiguration ermöglicht es ChatGPT, auf Echtzeit- und spezifische Informationen zuzugreifen, was zu genaueren und relevanteren Antworten führt.
Vektordatenbanken spielen eine wichtige Rolle bei der Verbesserung der Antwortqualität und Leistung von LLMs. Sie stellen sicher, dass Modelle Zugriff auf die neuesten und relevantesten Daten haben. MyScale zeichnet sich in diesem Bereich aus und bietet effiziente und skalierbare Lösungen, die eine einfache und effektive Integration ermöglichen. MyScale hat auch spezialisierte Vektordatenbanken übertroffen (opens new window) in Bezug auf Geschwindigkeit und Leistung. Darüber hinaus können neue Benutzer 5 Millionen kostenlose Vektorspeicher in ihrem Entwicklungs-Pod nutzen, um MyScale-Funktionen zu testen und die Vorteile aus erster Hand zu erleben.
Wenn Sie weitere Fragen haben, sind Sie herzlich eingeladen, unserem MyScale Discord (opens new window) beizutreten, um Ihre Gedanken und Feedbacks zu teilen.



