
Update (2023-10-17): Schauen Sie sich unseren neuen Blog-Beitrag Vergleich von MyScale mit Postgres und OpenSearch: Eine Erkundung der integrierten Vektor-Datenbanken (opens new window) für einen umfassenden Vergleich zwischen MyScale und PostgreSQL an.
Das rasante Wachstum von KI- und ML-Anwendungen, insbesondere solche, die eine Datenanalyse im großen Maßstab erfordern, hat die Nachfrage nach Vektordatenbanken erhöht, die Vektor-Embeddings effizient speichern, indizieren und abfragen können. Aus diesem Grund werden Vektordatenbanken wie MyScale, Pinecone und Qdrant kontinuierlich weiterentwickelt und erweitert, um diese Anforderungen zu erfüllen.
Gleichzeitig verbessern herkömmliche Datenbanken kontinuierlich ihre Fähigkeiten zur Speicherung und Abfrage von Vektordaten. Zum Beispiel bieten die bekannte relationale Datenbank PostgreSQL und ihre Erweiterung pgvector ähnliche Funktionen, wenn auch weniger effektiv als eine gut optimierte Vektordatenbank.
Es gibt signifikante Unterschiede in Leistung, Genauigkeit und anderen Aspekten bei der Verwendung einer allgemeinen Datenbank wie PostgreSQL. Diese Unterschiede können zu Engpässen bei der Leistung und beim Datenmaßstab führen. Um diese Probleme zu lösen, wird ein Upgrade auf eine effizientere Vektordatenbank wie MyScale empfohlen.
Was MyScale von anderen spezialisierten Vektordatenbanken unterscheidet, ist die Fähigkeit, volle SQL-Unterstützung zu bieten, ohne dabei die hohe Leistung einzuschränken. Dadurch wird der Migrationsprozess von PostgreSQL zu MyScale wesentlich reibungsloser und einfacher.
Um diesen Aussage Wert zu verleihen, betrachten wir einen Anwendungsfall, bei dem wir Vektordaten in einer PostgreSQL-Datenbank gespeichert haben, aber mit Leistungs- und Datenmaßstabsengpässen konfrontiert sind. Daher haben wir uns als Lösung entschieden, auf MyScale zu aktualisieren.
# Daten von PostgreSQL nach MyScale migrieren
Ein wesentlicher Teil des Upgrades von PostgreSQL zu MyScale besteht darin, die Daten von der alten zur neuen Datenbank zu migrieren. Schauen wir uns an, wie das gemacht wird.
Hinweis:
Um zu demonstrieren, wie Daten von PostgreSQL nach MyScale migriert werden, müssen wir beide Datenbanken einrichten, obwohl unser Anwendungsfall besagt, dass wir bereits Vektordaten in einer PostgreSQL-Datenbank haben.
Bevor wir beginnen, ist es wichtig zu beachten, dass wir die folgenden Umgebungen und Datensätze verwenden werden:
# Umgebungen
| Datenbank | Tier | DB-Version | Erweiterungsversion |
|---|---|---|---|
| PostgreSQL auf Supabase (opens new window) | Kostenlos (bis zu 500 MB Datenbankspeicherplatz) | 15.1 | pgvector 4.0 |
| MyScale (opens new window) | Entwicklung (bis zu 5 Millionen 768-dimensionale Vektoren) | 0.10.0.0 |
# Datensatz
Wir haben die ersten 1 Million Zeilen (genau 1.000.448 Zeilen) aus dem LAION-400-MILLION OPEN DATASET (opens new window) für diese Übung verwendet, um ein Szenario zu demonstrieren, in dem der Datenmaßstab nach der Migration weiter zunimmt.
Hinweis:
Dieser Datensatz enthält 400 Millionen Einträge, von denen jeder aus einem 512-dimensionalen Vektor besteht.
# Daten in PostgreSQL laden
Wenn Sie bereits mit PostgreSQL und pgvector vertraut sind, können Sie zum Migrationsprozess springen, indem Sie hier klicken.
Der erste Schritt besteht darin, die Daten in eine PostgreSQL-Datenbank zu laden, indem Sie die folgende schrittweise Anleitung befolgen:
# PostgreSQL-Datenbank erstellen und Umgebungsvariablen festlegen
Erstellen Sie eine PostgreSQL-Instanz mit pgvector in Supabase wie folgt:
- Gehen Sie zur Supabase-Website (opens new window) und melden Sie sich an.
- Erstellen Sie eine Organisation und benennen Sie sie.
- Warten Sie, bis die Organisation und ihre Datenbank erstellt wurden.
- Aktivieren Sie die
pgvector-Erweiterung.
Der folgende GIF erklärt diesen Vorgang genauer.

Sobald die PostgreSQL-Datenbank erstellt und pgvector aktiviert wurde, ist der nächste Schritt, die folgenden drei Umgebungsvariablen zu konfigurieren, um die Verbindung zu PostgreSQL mit psql herzustellen:
export PGHOST=db.qwbcctzfbpmzmvdnqfmj.supabase.co
export PGUSER=postgres
export PGPASSWORD='********'
Führen Sie außerdem das folgende Skript aus, um die Speicher- und Anforderungsdauerlimits zu erhöhen und sicherzustellen, dass keine SQL-Abfragen unterbrochen werden:
$ psql -c "SET maintenance_work_mem='300MB';"
SET
$ psql -c "SET work_mem='350MB';"
SET
$ psql -c "SET statement_timeout=4800000;"
SET
$ psql -c "ALTER ROLE postgres SET statement_timeout=4800000;";
ALTER ROLE
# PostgreSQL-Datentabelle erstellen
Führen Sie die folgende SQL-Anweisung aus, um eine PostgreSQL-Datentabelle zu erstellen. Stellen Sie sicher, dass die Vektorspalten (text_embedding und image_embedding) vom Typ vector(512) sind.
Hinweis:
Die Vektorspalten müssen mit den Vektordimensionen unserer Daten übereinstimmen.
$ psql -c "CREATE TABLE laion_dataset (
id serial,
url character varying(2048) null,
caption character varying(2048) null,
similarity float null,
image_embedding vector(512) not null,
text_embedding vector(512) not null,
constraint laion_dataset_not_null_pkey primary key (id)
);"
# Daten in die PostgreSQL-Tabelle einfügen
Fügen Sie die Daten in Stapeln von 500.000 Zeilen ein.
Hinweis:
Wir haben nur den ersten Satz von 500.000 Zeilen eingefügt, um zu testen, wie erfolgreich die Daten eingefügt wurden, bevor wir den Rest hinzufügen.
$ wget https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion_dataset.sql.tar.gz
$ tar -zxvf laion_dataset.sql.tar.gz
$ cd laion_dataset
$ psql < laion_dataset_id_lt500K.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
# Einen ANN-Index erstellen
Der nächste Schritt besteht darin, einen Index zu erstellen, der die Approximate Nearest Neighbor-Suche (ANN) verwendet.
Hinweis:
Setzen Sie den Parameter lists auf 1000, da die erwartete Anzahl von Zeilen in der Datentabelle 1 Million beträgt. (https://github.com/pgvector/pgvector#indexing (opens new window))
$ psql -c "CREATE INDEX ON laion_dataset
USING ivfflat (image_embedding vector_cosine_ops)
WITH (lists = 1000);";
CREATE INDEX
# Eine SQL-Abfrage ausführen
Der letzte Schritt besteht darin, zu überprüfen, ob alles funktioniert, indem Sie die folgende SQL-Anweisung ausführen:
$ psql -c "SET ivfflat.probes = 100;
SELECT id, url, caption, image_embedding <=> (SELECT image_embedding FROM laion_dataset WHERE id=14358) AS dist
FROM laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;"
Wenn Ihr Ergebnis wie unseres aussieht, können wir fortfahren.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background Stock Photo | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white Norwegian Forest Cat, on white background royalty free stock image | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |
# Den Rest der Daten einfügen
Fügen Sie den Rest der Daten in die PostgreSQL-Tabelle ein. Dies ist wichtig, um die Leistung von pgvector im großen Maßstab zu validieren.
$ psql < laion_dataset_id_ge500K_lt1m.sql
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
INSERT 0 1000
...
ERROR: cannot execute INSERT in a read-only transaction
ERROR: cannot execute INSERT in a read-only transaction
Wie Sie aus der Ausgabe dieses Skripts (und dem folgenden Bild) sehen können, treten beim Einfügen des Rests der Daten Fehler auf. Supabase setzt die PostgreSQL-Instanz in den Nur-Lese-Modus, um eine Speichernutzung über die Grenzen des kostenlosen Tiers hinaus zu verhindern.
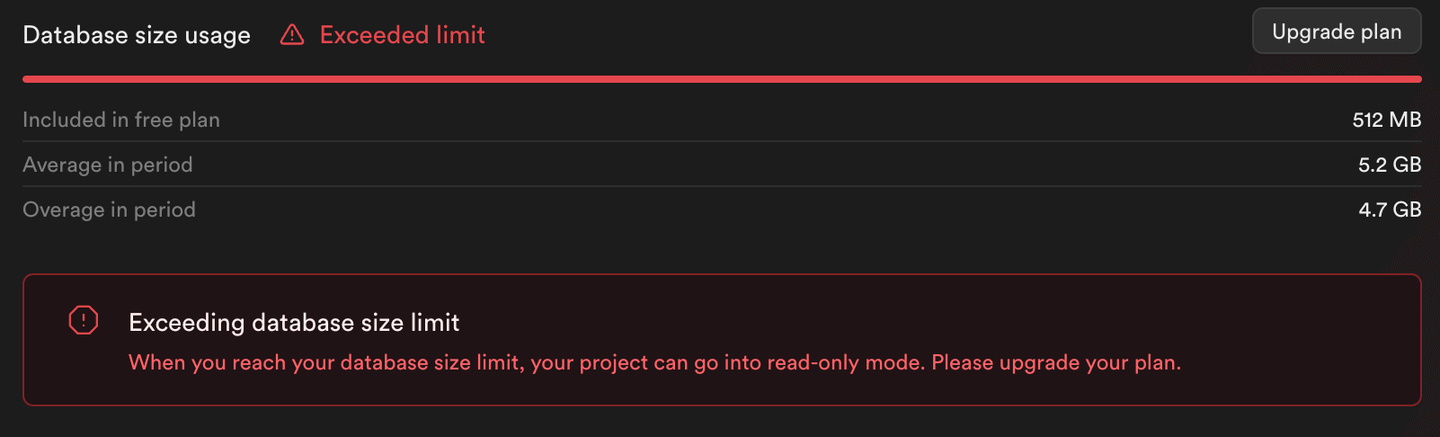
Hinweis:
Es wurden nur 500.000 Zeilen in die PostgreSQL-Tabelle eingefügt und nicht 1 Million Zeilen.
# Zu MyScale migrieren
Lassen Sie uns nun die Daten zu MyScale migrieren, indem Sie der folgenden schrittweisen Anleitung folgen:
Hinweis:
MyScale ist nicht nur eine leistungsstarke integrierte Vektordatenbank, sondern Benchmark-Berichte zeigen, dass MyScale im Vergleich zu anderen spezialisierten Vektordatenbanken hinsichtlich Suchleistung, Genauigkeit und Ressourcennutzung überlegen ist. MyScale's proprietärer Vektorindexierungsalgorithmus, Multi-Scale Tree Graph (MSTG), nutzt lokale NVMe SSD als Cache-Disk, was die unterstützte Indexskala im Vergleich zu In-Memory-Situationen erheblich erhöht.
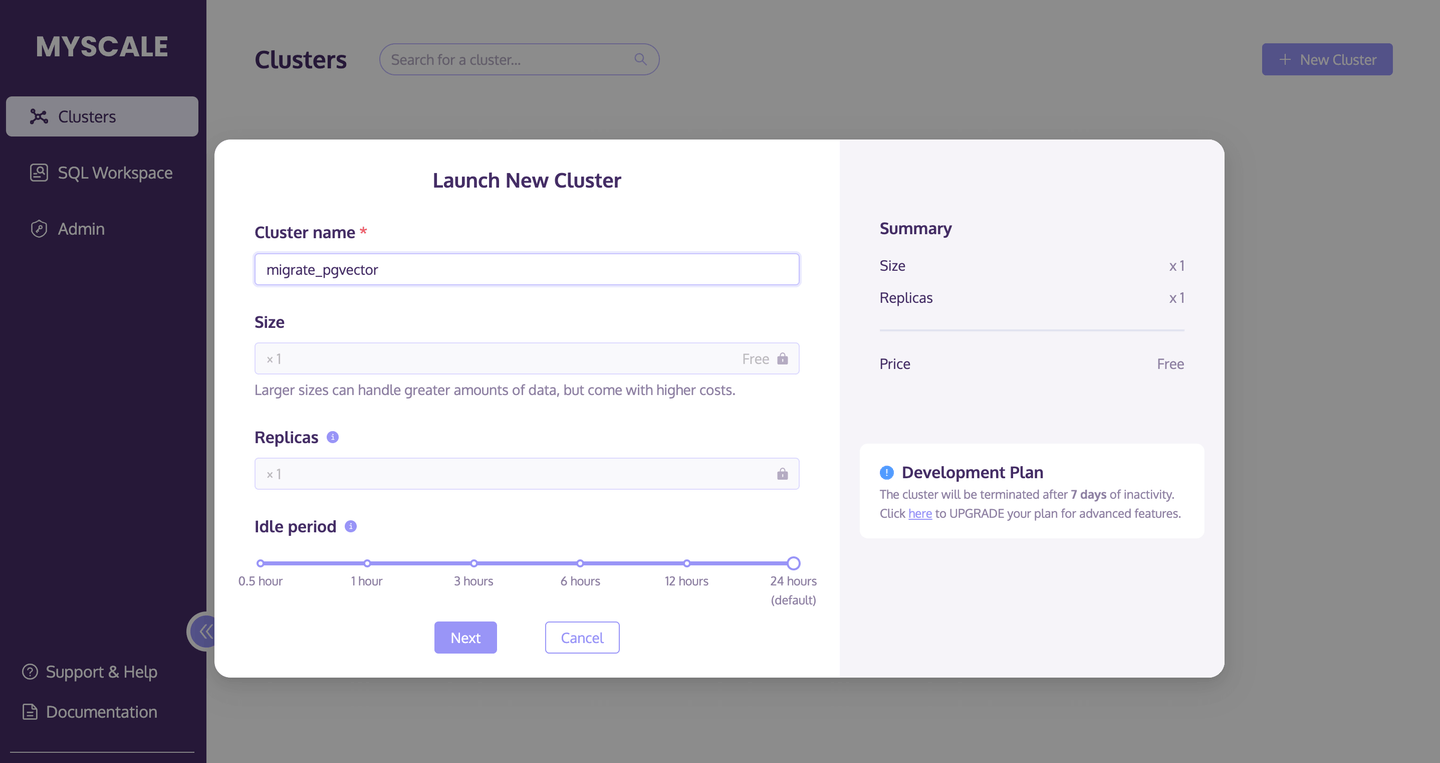
# Einen MyScale-Cluster erstellen
Der erste Schritt besteht darin, einen neuen MyScale-Cluster zu erstellen und zu starten.
- Gehen Sie zur Clusters-Seite (opens new window) und klicken Sie auf die Schaltfläche +Neuer Cluster, um einen neuen Cluster zu starten.
- Benennen Sie Ihren Cluster.
- Klicken Sie auf Start, um den Cluster auszuführen.
Das folgende Bild beschreibt diesen Vorgang genauer:
# Eine Datentabelle erstellen
Sobald der Cluster ausgeführt wird, führen Sie das folgende SQL-Skript aus, um eine neue Datenbanktabelle zu erstellen:
CREATE TABLE laion_dataset
(
`id` Int64,
`url` String,
`caption` String,
`similarity` Nullable(Float32),
`image_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(image_embedding) = 512,
`text_embedding` Array(Float32),
CONSTRAINT check_length CHECK length(text_embedding) = 512
)
ENGINE = MergeTree
ORDER BY id;
# Daten von PostgreSQL migrieren
Wenn Sie die Datenbanktabelle erstellt haben, verwenden Sie den PostgreSQL()-Tabellen-Engine (opens new window), um die Daten von PostgreSQL einfach zu migrieren.
INSERT INTO default.laion_dataset
SELECT id, url, caption, similarity, image_embedding, text_embedding
FROM PostgreSQL('db.qwbcctzfbpmzmvdnqfmj.supabase.co:5432',
'postgres', 'laion_dataset',
'postgres', '************')
SETTINGS min_insert_block_size_rows=65505;
Hinweis:
Die Einstellung min_insert_block_size_rows wird hinzugefügt, um die Anzahl der pro Batch eingefügten Zeilen zu begrenzen und einen übermäßigen Speicherbedarf zu verhindern.
# Die Gesamtzahl der eingefügten Zeilen bestätigen
Verwenden Sie die SELECT count(*)-Anweisung, um zu bestätigen, ob alle Daten von der PostgreSQL-Tabelle erfolgreich nach MyScale migriert wurden.
SELECT count(*) FROM default.laion_dataset;
Die folgende Ergebnismenge zeigt an, dass die Migration erfolgreich war, da diese Abfrage 500.000 (500000) Zeilen zurückgibt.
| count() |
|---|
| 500000 |
# Eine Datenbanktabellen-Index erstellen
Der nächste Schritt besteht darin, einen Index mit dem Indextyp MSTG und metric_type (Berechnungsmethode für die Distanz) als cosine zu erstellen.
ALTER TABLE default.laion_dataset
ADD VECTOR INDEX laion_dataset_vector_idx image_embedding
TYPE MSTG('metric_type=cosine');
Sobald diese ALTER TABLE-Anweisung abgeschlossen ist, ist der nächste Schritt, den Status des Index zu überprüfen. Führen Sie das folgende Skript aus, und wenn der status als Built zurückgegeben wird, wurde der Index erfolgreich erstellt.
SELECT database, table, type, status FROM system.vector_indices;
| database | table | type | status |
|---|---|---|---|
| default | laion_dataset | MSTG | Built |
# Eine ANN-Abfrage ausführen
Führen Sie das folgende Skript aus, um eine ANN-Abfrage mit dem gerade erstellten MSTG-Index auszuführen.
SELECT id, url, caption,
distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)
) AS dist
FROM default.laion_dataset where id!=14358 ORDER BY dist ASC LIMIT 10;
Wenn die folgende Ergebnistabelle mit den Ergebnissen der PostgreSQL-Abfrage übereinstimmt, war unsere Datenmigration erfolgreich.
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Pretty Ragdoll cat on white background Royalty Free Stock Image | 0.0749262628626345 | |
| 195973 | cat sitting in front and looking at camera isolated on white background | 0.0929287358264965 | |
| 83158 | Abyssinian Cat Pictures | 0.105731256045087 | |
| 432425 | Russian blue kitten Stock Images | 0.108455925228164 | |
| 99628 | Norwegian Forest Cat on white background. Show champion black and white... | 0.111603095925331 | |
| 478216 | himalayan cat: Cat isolated over white background | 0.115501832572401 | |
| 281881 | Sealpoint Ragdoll lying on white background Stock Images | 0.121348724151614 | |
| 497148 | Frightened black kitten standing in front of white background | 0.127657010206311 | |
| 490374 | Lying russian blue cat Stock Photo | 0.129595023570348 | |
| 401134 | Maine coon cat on pastel pink Stock Image | 0.130214431419139 |

# Den Rest der Daten in die MyScale-Tabelle einfügen
Fügen Sie den Rest der Daten in die MyScale-Tabelle ein.
# Daten aus CSV/Parquet importieren
Die gute Nachricht ist, dass wir die Daten direkt aus dem Amazon S3-Bucket importieren können, indem wir die folgende Methode von MyScale verwenden:
INSERT INTO laion_dataset
SELECT * FROM s3(
'https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/laion-1m-pic-vector.csv',
'CSV',
'id Int64, url String, caption String, similarity Nullable(Float32), image_embedding Array(Float32), text_embedding Array(Float32)')
WHERE id >= 500000 SETTINGS min_insert_block_size_rows=65505;
Dies automatisiert den Daten-Einfügeprozess und reduziert die Zeit, die manuell zum Hinzufügen der Zeilen in Stapeln von 500.000 benötigt wird.
# Die Gesamtzahl der eingefügten Zeilen bestätigen
Führen Sie erneut die SELECT count(*)-Anweisung aus, um zu bestätigen, ob alle Daten aus dem S3-Bucket in MyScale importiert wurden.
SELECT count(*) FROM default.laion_dataset;
Die folgende Ergebnismenge zeigt an, dass die richtige Anzahl von Zeilen importiert wurde.
| count() |
|---|
| 1000448 |
Hinweis:
Der kostenlose Pod von MyScale kann insgesamt 5 Millionen 768-dimensionale Vektoren speichern.
# Eine ANN-Abfrage ausführen
Wir können dieselbe SQL-Abfrage wie oben verwenden, um Abfragen auf einem Datensatz von 1 Million Zeilen durchzuführen.
Um Ihr Gedächtnis aufzufrischen, hier ist die SQL-Anweisung erneut:
SELECT id, url, caption, distance('alpha=4')(image_embedding,
(SELECT image_embedding FROM laion_dataset WHERE id=14358)) AS dist
FROM default.laion_dataset WHERE id!=14358 ORDER BY dist ASC LIMIT 10;
Hier ist die Ergebnistabelle der Abfrage, einschließlich der neu hinzugefügten Daten:
| id | url | caption | dist |
|---|---|---|---|
| 134746 | Hübsche Ragdoll-Katze auf weißem Hintergrund, lizenzfreies Stockbild | 0.07492614 | |
| 195973 | Katze sitzt vorne und schaut in die Kamera, isoliert auf weißem Hintergrund, Stockfoto | 0.09292877 | |
| 693487 | Russische Blaukatze, geheimnisvolle Katze, freundliche Katze, Frances Simpson, Katzenrassen, Katzenzucht | 0.09316337 | |
| 574275 | Mischlingskatze, Felis catus, 6 Monate alt, lizenzfreies Stockfoto | 0.09820753 | |
| 83158 | Abbildungen von Abessinierkatzen | 0.10573125 | |
| 797777 | Männliche Katzennamen für orangefarbene Katzen | 0.10775411 | |
| 432425 | Bilder von russischen Blaukätzchen | 0.10845572 | |
| 99628 | Norwegische Waldkatze auf weißem Hintergrund. Ausstellungschampion schwarz und weiß... | 0.1116029 | |
| 864554 | Rückansicht eines Maine Coon Kätzchens, das sitzt und nach oben schaut, 4 Monate alt, isoliert auf weißem Hintergrund | 0.11200631 | |
| 478216 | Himalaya-Katze: Katze isoliert auf weißem Hintergrund | 0.11550176 |
# Zusammenfassung
Diese Diskussion beschreibt, wie die Migration von Vektordaten von PostgreSQL zu MyScale unkompliziert ist. Selbst wenn wir die Datenmenge in MyScale erhöhen, indem wir Daten von PostgreSQL migrieren und neue Daten importieren, zeigt MyScale eine zuverlässige Leistung, unabhängig von der Größe des Datensatzes. Der umgangssprachliche Ausdruck "Je größer, desto besser" trifft in dieser Hinsicht zu. Die Leistung von MyScale bleibt auch bei Abfragen von sehr großen Datensätzen zuverlässig.
Daher empfehlen wir dringend, Ihre Daten gemäß den in diesem Artikel beschriebenen Schritten nach MyScale zu migrieren, wenn Ihr Unternehmen mit Datenmengen oder Leistungsengpässen zu kämpfen hat.



