
# Über Cowarobot

Cowarobot wurde 2015 gegründet und ist ein Unternehmen, das sich auf die Bereitstellung schlüsselfertiger Lösungen für autonomes Fahren in komplexen städtischen Umgebungen spezialisiert hat. Mitte 2022 waren sie in über 10 Städten in China präsent und verfügten über eine Flotte von über 1.000 autonomen Fahrzeugen. Sie haben auch mit chinesischen Automobilherstellern wie Cherry, BAIC, Shaanxi Automobile und Zoomlion zusammengearbeitet, um in diesen Städten Lösungen für die urbane Logistiklieferung und den Transport zu entwickeln.
# Vor der Verwendung von MyScale
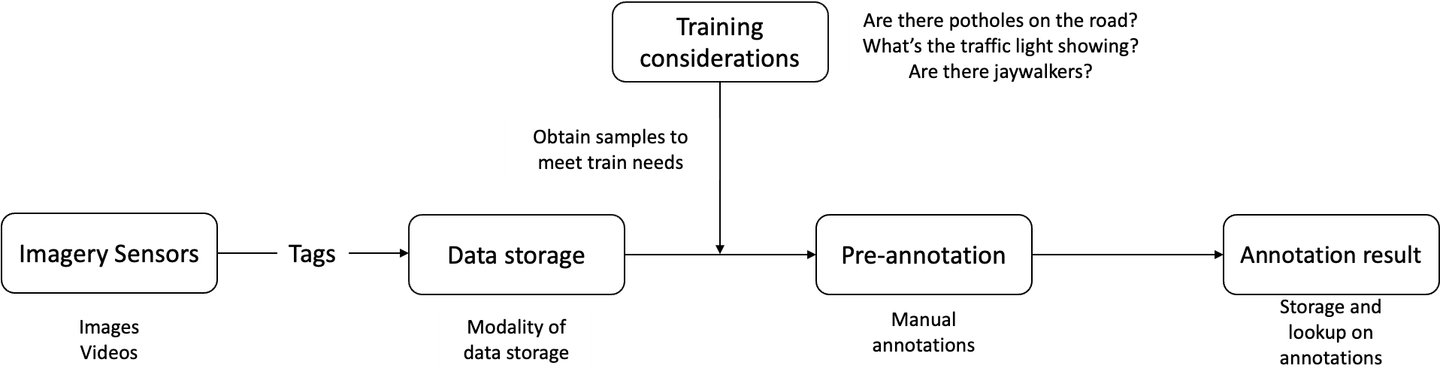
Der Hauptworkflow von Cowarobot für das Training ihrer autonomen Fahrzeugflotte ist in fünf Abschnitte unterteilt:
- Speicherung von Rohdaten und Labels in einem zentralen Speicher
Cowarobot ist darauf spezialisiert, Rohvideo- und Raumdaten zu sammeln und zu verarbeiten, die für autonome Fahrzeuge entscheidend sind, wie z.B. dynamische Informationen wie nahegelegene Fahrzeuge, Straßensperren und Verkehrssignale, zusätzlich zu traditionellen Daten wie Straßenoberflächen, Gehwegen, Karten und Geschwindigkeitsbegrenzungen. Die Daten werden gelabelt und in Ordner mit mehreren Ebenen organisiert, die dann auf lokalen Laufwerken gespeichert werden. Cowarobot steht jedoch vor einer erheblichen Herausforderung in Bezug auf die Datenspeicherung aufgrund der großen Menge an produzierten Daten. Das Unternehmen steht vor der Herausforderung, eine große Anzahl von Festplatten zu beschaffen und in nachhaltiger Weise Daten zentral zu speichern. Darüber hinaus sind mindestens eine Million Datensamples erforderlich, um eine genaue Echtzeitobjekterkennung, Segmentierung und Labelerkennung zu ermöglichen.
- Ausführung von Schulungsaufgaben
Cowarobot verwendet die gesammelten Rohdaten, um seine Modelle zu trainieren, damit seine autonomen Fahrzeuge von Punkt A nach Punkt B navigieren, eine sichere Geschwindigkeit im Verhältnis zu anderen Autos halten, Hindernissen ausweichen und Verkehrssignale beachten können. Um sicherzustellen, dass die Fahrzeuge sich an sich ändernde Straßenbedingungen anpassen können, müssen die Schulungsdaten ständig aktualisiert werden. Wenn zum Beispiel Straßenmarkierungen geändert werden, müssen die bisherigen Datenlabels entsprechend angepasst werden. Ebenso müssen die Fahrzeuge trainiert werden, angemessen auf neue oder unerwartete Situationen zu reagieren, wie z.B. Fußgänger, die unerlaubt die Straße überqueren, oder ein Polizist, der das Fahrzeug zum Anhalten auffordert. Diese Aktualisierungen erfordern von Cowarobot, wiederholt neue Daten zu beschaffen und zu labeln sowie vorhandene Daten neu zu labeln, was erhebliche Schulungskosten verursacht. Diese Kosten und häufigen Aktualisierungen begrenzen die Arten, Häufigkeit und Qualität der Schulungsaufgaben, die Cowarobot durchführen kann.
- Beschaffung neuer Samples
Cowarobot hat keine Möglichkeit, auf einfache Weise auf die Labels zuzugreifen und abzurufen, die sie ihren Daten zuvor zugewiesen haben, und kann frühere Labels nicht abrufen. Diese Einschränkung bedeutet, dass das Unternehmen nur Schulungsaufgaben mit seinen vorhandenen Daten unterstützen kann. Cowarobot muss alle Daten manuell von ihren lokalen Laufwerken exportieren, um sie verwenden zu können, was ein zeitaufwändiger Prozess ist. Darüber hinaus reichen die vorhandenen Daten nicht aus, um das Training der Cowarobot-Modelle zu unterstützen, sodass das Unternehmen weiterhin neue Daten sammeln und Trainingssamples generieren muss. Der aktuelle Workflow erfordert jedoch, dass Cowarobot nach jeder Aktualisierung alle Daten manuell von den lokalen Laufwerken exportiert, was ein mühsamer und zeitaufwändiger Prozess ist.
- Datenlabels
Die manuelle Natur des aktuellen Labeling-Prozesses von Cowarobot beeinträchtigt die Effizienz bei der Erstellung von Datensätzen zur Aktualisierung ihrer Modelle und zur Bereitstellung neuer Updates für ihre autonome Flotte. Dieses arbeitsintensive und zeitaufwändige Verfahren hindert das Unternehmen daran, seine Modelle mit den aktuellsten Daten auf dem neuesten Stand zu halten.
- Modelltraining
Derzeit verwendet Cowarobot für das Modelltraining eine verteilte Architektur, bei der mehrere Supercomputer genutzt werden, um deren Rechenleistung für verschiedene Phasen des Schulungsprozesses zu nutzen. Diese Strategie ist wirtschaftlicher als die Verwendung eines einzelnen, leistungsstärkeren Supercomputers. Ein Nachteil dieser Methode besteht jedoch darin, dass die Schulungssamples zwischen den Computern übertragen werden müssen, entweder über das Netzwerk oder offline, was umständlich und zeitaufwändig sein kann.
Darüber hinaus wird die Ausgabe der trainierten Modelle nicht ausreichend genutzt. Abgeschlossene Schulungsaufgaben würden es Cowarobot ermöglichen, diese Modelle direkt online zu nutzen, aber die außerhalb der Modellschulungssamples gespeicherten Daten wurden nicht aktualisiert, um das neue Modell widerzuspiegeln.
# Einführung von MyScale als Datenlagerlösung für ihre autonomen Fahrzeuge
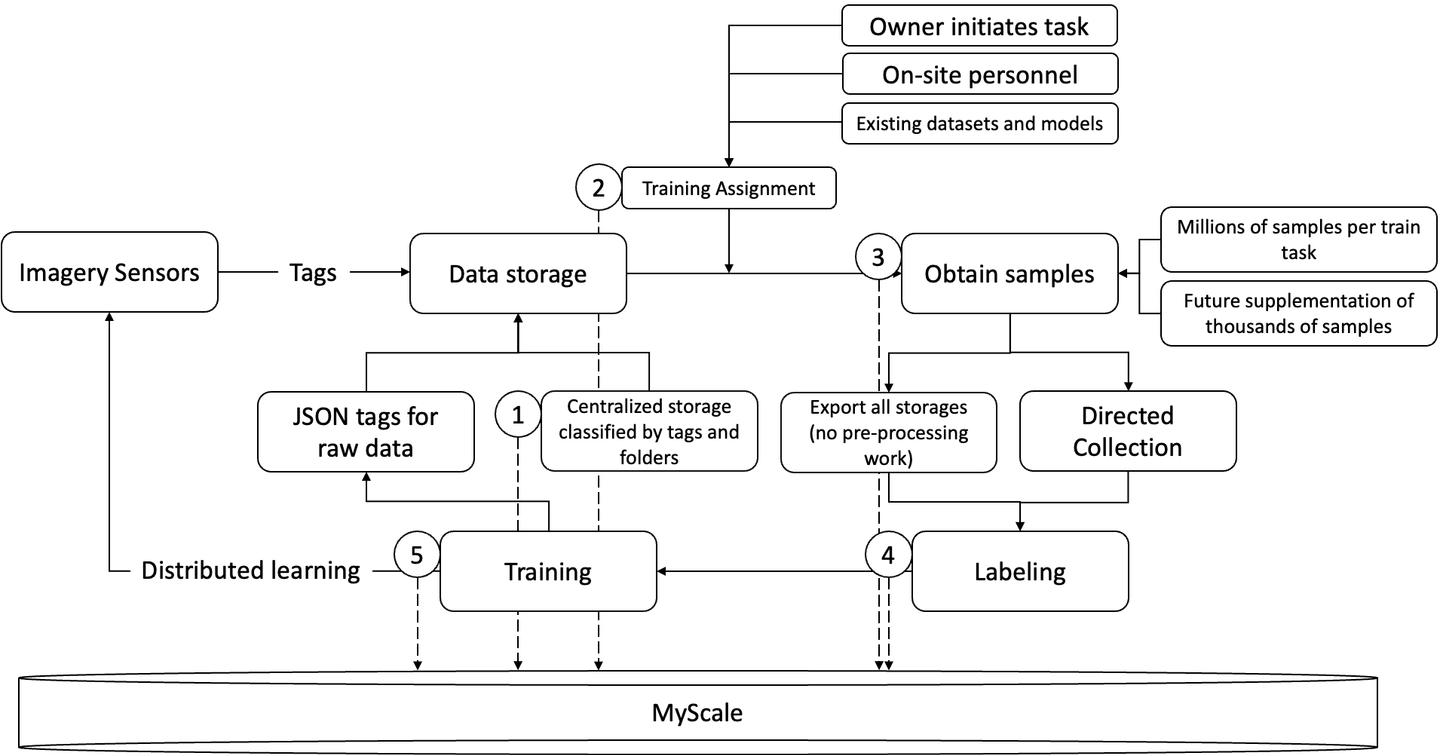
Cowarobot hat MyScale verwendet, um ihre Modellschulungsworkflows für ihre autonomen Fahrzeuge in Bereichen von der Speicherung über die Datenlabels bis hin zum Modelltraining zu verbessern.
- Speicherung von Rohdaten und Labels in einem zentralen Speicher
MyScale bietet einen einheitlichen Speicher für Abfragen und Datenverwaltung mit Datentypen wie ID, Vektordaten, Tag-Daten, URL usw., was die Verwaltung und Nutzung von Datensätzen für verschiedene Zwecke erleichtert. Dies ermöglicht es verschiedenen Abteilungen in einem Unternehmen, ihre maschinellen Lernprozesse besser zu verfolgen, ihre Datenverwendung zu verbessern und den Umfang ihrer Schulungsaufgaben zu erweitern.
- Ausführung von Schulungsaufgaben
MyScale unterstützt die schnelle Generierung von Schulungssamples aus Bestandsdaten, indem es Benutzern ermöglicht, gemeinsame SQL-Abfragen (Attributfilterung) durchzuführen. Dadurch können neue Schulungsaufgaben eine kleinere Stichprobengröße erfordern oder überhaupt keine neuen Datenakquisitionen erfordern. Dies reduziert die Schulungskosten und ermöglicht es den Benutzern, die Häufigkeit und Arten von Schulungsaufgaben mit kleineren Datensätzen zu erhöhen.
- Beschaffung neuer Samples
Der wesentliche Vorteil von MyScale besteht darin, dass nur eine geringe Anzahl von Datensamples erforderlich ist. Mit weniger erforderlichen Samples wird die Arbeitsbelastung für die Beschaffung neuer Samples zur Modellschulung reduziert. MyScale ermöglicht dies, indem es Benutzern ermöglicht, gemeinsame SQL-Abfragen auszuführen, um Schulungssamples aus gespeicherten Daten schnell zu generieren. Dies ist auch dann nützlich, wenn eine vorhandene Datenbank mit einer großen Anzahl von Samples vorhanden ist, da MyScale nach Schulungssamples suchen und nach qualitativ hochwertigeren Schulungssamples suchen kann. Dadurch wird die Präzision der positiven Samples in den gelabelten Daten erhöht.
- Datenlabels
MyScale erfordert eine kleine Stichprobe von Daten, die bereits gelabelt wurden, um den Prozess des Modelltrainings zu starten. Das Labeling von Daten dauert weniger Zeit und kostet weniger Geld, wenn weniger Datensamples manuell geändert werden müssen.
- Modelltraining
MyScale kann Schulungsdaten verwalten und vollständige SQL-Unterstützung bieten. MyScale ermöglicht es Benutzern, einfache SQL-Anweisungen zu schreiben, um Schulungssamples direkt zu erstellen. Das Modelltraining kann dann direkt auf die Originaldaten zugreifen, um den Prozess des Modelltrainings zu starten. Dadurch werden die Modelltraining-Aufgaben und die Art und Weise, wie Daten von verschiedenen Quellen übertragen werden, erheblich vereinfacht.

# Wie MyScale Ihnen dabei helfen kann, neuen Geschäftswert aus Ihren Videodaten zu erschließen

MyScale hat mit dem Robo-Taxi-Unternehmen Cowarobot zusammengearbeitet, um ihren maschinellen Lernprozess zu verwalten, der Datenbeschaffung, -speicherung, -labeling und Modelltraining für ihre autonome Flotte umfasst. Eine Vielzahl von Datenquellen, einschließlich Vektordaten und Datenannotationen, werden in einer einheitlichen Plattform verwaltet. Die MyScale-Plattform bietet auch volle SQL-Unterstützung, was das Modelltraining durch die Verwendung einer einzigen Abfragesprache vereinfacht.
MyScale bietet auch Suchfunktionen, um Schulungssamples schnell aus gespeicherten Daten zu lokalisieren. Dadurch werden die Kosten für das Training von Modellen gesenkt und die Häufigkeit und Art des Trainings verbessert. Cowarobot nutzte MyScale und das Few-Shot-Learning, um Datenscreening, Datenklassifizierung und Datenmarkierung durchzuführen. Diese Strategie reduzierte den Bedarf an Datenannotation und Datensammlung.
Wenn Ihr Unternehmen auch mit Bildern und Videos in Ihrer aktuellen Anwendung arbeitet und mehr darüber erfahren möchte, wie MyScale Ihnen helfen kann, mehr Wert aus Ihren Anwendungen und Unternehmen zu extrahieren, zögern Sie bitte nicht, uns unter contact@myscale.com zu kontaktieren.



