
Immer wenn das Wort Datenbank erwähnt wird, waren relationale Datenbanken (opens new window) aufgrund ihrer Einfachheit und Benutzerfreundlichkeit lange Zeit die Standardwahl für die Datenspeicherung. In der heutigen datengetriebenen Welt hat jedoch die wachsende Bedeutung von unstrukturierten Daten wie Texten, Bildern und Audio dazu geführt, dass Vektordatenbanken (opens new window) als eine praktikable Alternative entstanden sind.
Im Gegensatz zu herkömmlichen Datenbanken, die auf primitive Datentypen wie Ganzzahlen und Zeichenketten beschränkt sind, speichern und verwalten Vektordatenbanken Daten als Vektoren. Dadurch können sie unstrukturierte Daten effizient verarbeiten, was sie äußerst beliebt macht. In den letzten Jahren haben viele Unternehmen Vektordatenbanken und Vektorsuchdienste bereitgestellt. Daher werden in einer Reihe von Artikeln MyScale und einige andere beliebte Vektordatenbanken mit Pinecone als erstem Vergleichspartner umfassend verglichen. Pinecone (opens new window) ist eine proprietäre Vektordatenbank, die speziell für die effiziente Verarbeitung von hochdimensionalen Vektordaten entwickelt wurde. Sie zeichnet sich durch die Speicherung, Indizierung und Abfrage von Vektoreinbettungen aus und ist daher eine ideale Lösung für Ähnlichkeitssuche und maschinelle Lernanwendungen, die Echtzeit- und hochdimensionale Vektoroperationen erfordern.
Bevor wir den Vergleich zwischen MyScale und Pinecone durchführen, möchte ich kurz einige wichtige Konzepte im Zusammenhang mit Vektordatenbanken vorstellen.
# Warum ist die Vektorsuche wichtig
Ein Vektor kann verschiedene Dinge repräsentieren: ein Array von Werten, einige Textdaten, räumliche Daten, Bilder usw. Wir alle wissen, wie einfach es ist, die grundlegenden Vektoroperationen durchzuführen oder die Skalarprodukte zu berechnen, um ihre Ausrichtung/Ähnlichkeit zu finden.
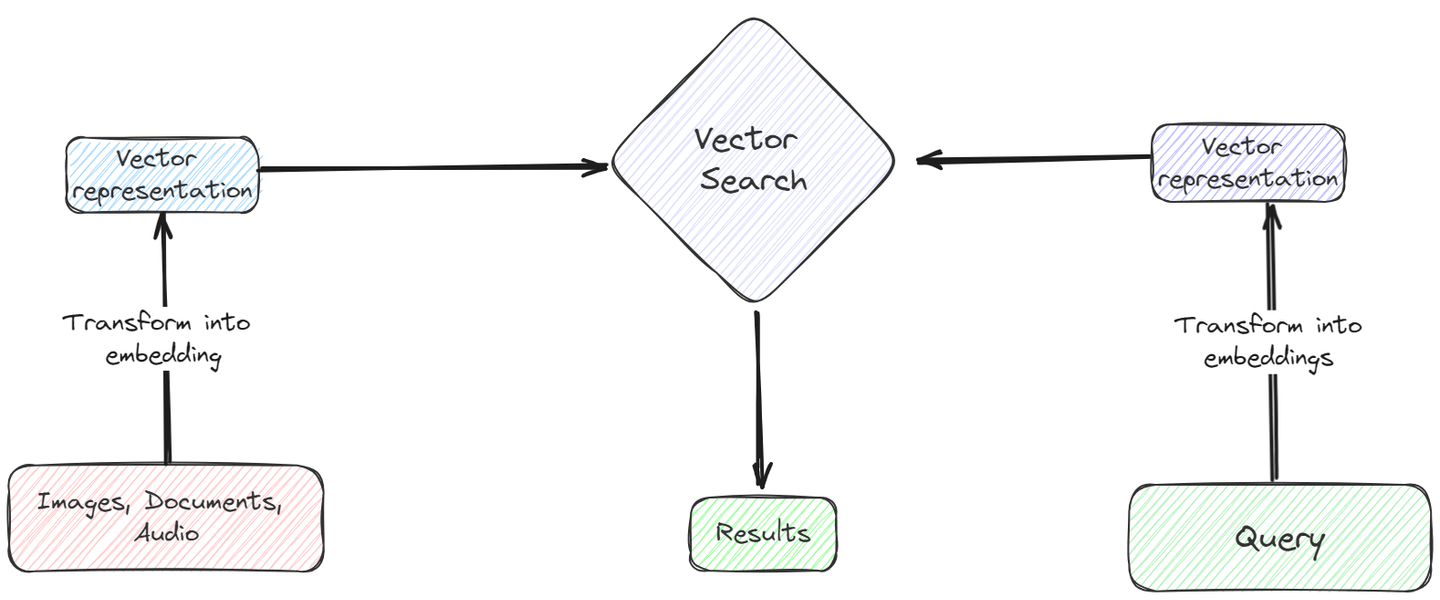
Durch die Verwendung geeigneter Einbettungen können die unstrukturierten Daten in den Vektordatenbanken in Form von Vektoren gespeichert werden. Anschließend können primitive Ähnlichkeitsmaße wie der Kosinus-Ähnlichkeitswert oder sogar der euklidische Abstand verwendet werden, um schnell und effizient Ähnlichkeitssuchen auf den Vektoren durchzuführen. Diese Vektorsuche (opens new window) ist im Vergleich zu herkömmlichen Datenbanken viel schneller und kostengünstiger und eignet sich daher hervorragend für die effektive Verarbeitung großer Mengen unstrukturierter Daten.
# Was sind SQL-Vektordatenbanken
Neben spezialisierten Vektordatenbanken haben einige SQL-Datenbanken ihre Fähigkeiten erweitert, um auch die Vektorsuche zu ermöglichen. Diese integrierten Lösungen, bekannt als SQL-Vektordatenbanken (opens new window), sollen vektorbasierte Ähnlichkeitssuchfunktionen in einer strukturierten Datenumgebung bereitstellen und die Verwaltung von Vektor- und Strukturdokumenten in einem einheitlichen Datenbank-Framework ermöglichen. [Image: testtt (1).png]
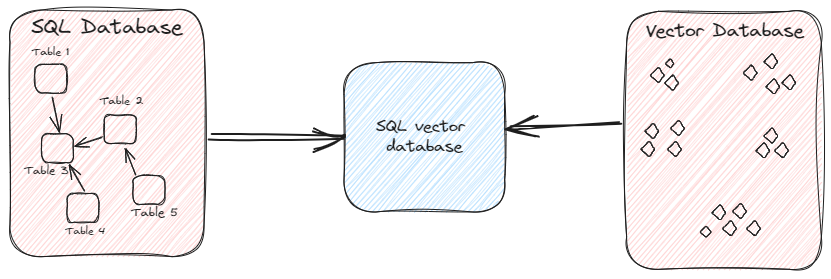
Unter den SQL-Vektordatenbanken ist MyScale eine Open-Source-Option, die die Möglichkeiten von ClickHouse erweitert. Es ist die einzige integrierte Datenbank, die in Bezug auf Geschwindigkeit und Leistung sogar spezialisierte Vektordatenbanken übertrifft.
# Bedeutung im Bereich der LLMs
Mit dem Aufkommen von LLMs breiten sich ihre Anwendungen zwangsläufig in verschiedenen Bereichen aus. Diese grundlegenden Modelle können anhand einer Reihe von Methoden an die spezifischen Anforderungen von Anwendungen angepasst werden, die grob in zwei Typen unterteilt werden können: Feinabstimmung (opens new window) und RAG (opens new window).
Bei der Feinabstimmung verwenden wir das vorhandene Modell und passen es an die neuen/relevanten Daten an. Da dies Lernen beinhaltet, ist es rechentechnisch recht aufwendig. Trotz Techniken wie LoRA usw. sind immer noch leistungsstarke GPUs erforderlich, um LLMs feinabzustimmen.
RAG (opens new window) hingegen beinhaltet keine traditionellen Lernprozesse. Stattdessen verwendet es Vektoreinbettungen für die Vektorsuche. Diese Methode verwendet primitive Ähnlichkeitsmaße und macht den Suchprozess erheblich schneller.
Bisher haben wir fast alle grundlegenden Konzepte abgedeckt. Lassen Sie uns nun mit dem Vergleich der beiden Datenbanken, MyScale und Pinecone, fortfahren.
# Hosting
Das Hosting ist ein entscheidender Aspekt bei der Auswahl einer Datenbanklösung, da es sich erheblich auf Leistung, Skalierbarkeit und Verwaltung auswirkt. Eine robuste Hosting-Option stellt sicher, dass Ihre Datenbank unterschiedliche Lasten bewältigen, zugänglich bleiben und einfach gewartet werden kann. Darüber hinaus hilft das Verständnis der Hosting-Optionen dabei, festzustellen, ob Sie die Datenbank lokal mit eigenen Ressourcen bereitstellen oder einen Cloud-basierten Service nutzen müssen.
Beide Optionen können im Cloud-Modus genutzt werden, indem Instanzen in der Cloud erstellt werden. Pinecone funktioniert ausschließlich als proprietärer Cloud-Service, während MyScale sowohl eine Cloud-Version, MyScale Cloud (opens new window), als auch eine Open-Source-Version unter https://github.com/myscale/myscaledb anbietet. Die Open-Source-Version kann mit dem folgenden Docker-Befehl gestartet werden:
docker run --name MyScale --net=host myscale/MyScale:1.6
Darüber hinaus bietet MyScale Cloud eine kostenlose Stufe, mit der Sie sich schnell anmelden und loslegen (opens new window) können. Weitere Details finden Sie in der Schnellstartanleitung (opens new window).
# Kernfunktionalitäten
# Abfragesprache und API-Unterstützung
Ein wichtiger Aspekt bei der Einführung einer neuen Datenbanktechnologie ist die Integration in bestehende Entwicklungsworkflows und die Vertrautheit mit der Abfragesprache. Glücklicherweise erspart MyScale Ihnen die Mühe, indem es SQL verwendet, das wir bereits für relationale Datenbanken verwenden.
MyScale bietet jedoch noch mehr, indem es verschiedene Entwicklertools wie Python-Client (opens new window), Node.js (opens new window), Go-Client (opens new window), ClientJDBC-Treiber (opens new window) und HTTPS-Schnittstelle (opens new window) integriert.
TL;DR:
Sowohl Pinecone als auch MyScale bieten SDKs in verschiedenen Sprachen an, aber MyScale hat einen klaren Vorteil durch seine vollständige SQL-Unterstützung.
# Unterstützte Datentypen
Pinecone ist ausschließlich auf die Speicherung von Vektoren spezialisiert. MyScale hingegen ist viel vielseitiger und ermöglicht die Speicherung verschiedener Datentypen von Text bis hin zu Bildern.
Wir können eine Tabelle erstellen, die sowohl skalare als auch Vektorattribute nahtlos enthält. Aufgrund der SQL-Schnittstelle ähnelt dies der Erstellung einer normalen relationalen DB-Tabelle. Der folgende SQL-Code erstellt eine Tabelle mit body_vector der Länge 512.
CREATE TABLE default.wiki_abstract(
id UInt64,
body String,
title String,
url String,
body_vector Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 512
)
ENGINE = MergeTree
ORDER BY id;
Da es das tabellarische Format verwendet, gibt es keine Einschränkung hinsichtlich der Zeilenlänge. Die Dokumentengröße ist daher im Gegensatz zu seinem Konkurrenten nicht begrenzt.
# Indizierung
In Vektordatenbanken werden verschiedene Indizierungsalgorithmen verwendet, wie z.B. IVF und KD-Bäume. Pinecone verwendet den Hierarchical Navigable Small Worlds (HNSW)-Algorithmus und den FreshDiskANN-Algorithmus. FreshDiskANN ist für effiziente Echtzeit-Updates konzipiert und unterstützt hohe Abrufgenauigkeit und Leistung für große Datensätze.
MyScale führt den Multi-Scale Tree Graph (MSTG) (opens new window) ein, einen Algorithmus, der hierarchisches Baumclustering und graphenbasierte Suche kombiniert. MSTG übertrifft zeitgenössische Algorithmen, indem es schnellere Suchen mit reduziertem Ressourcenverbrauch ermöglicht. Wenn es einen einzigen Grund gibt, MyScale gegenüber Pinecone zu wählen, dann ist es MSTG.
# Gefilterte Vektorsuche
Pinecone bietet die Möglichkeit zur Metadatenfilterung mit Unterstützung von bis zu 40 KB Metadaten pro Vektor. Diese Metadaten können Zeichenketten, Zahlen und Boolesche Werte enthalten, was detaillierte, attributbasierte Suchen ermöglicht. Der Einzelstufen-Filtermechanismus von Pinecone beschränkt die Suche auf Elemente, die den angegebenen Kriterien entsprechen, was den Prozess durch Vermeidung von Brute-Force-Suchen schneller und genauer macht.
MyScale optimiert die gefilterte Vektorsuche (opens new window) mit seinem MSTG-Algorithmus in Kombination mit den fortgeschrittenen Indizierungs- und parallelen Verarbeitungsfunktionen von ClickHouse. Darüber hinaus wird eine Vorfilterungsstrategie angewendet, um den Datensatz vor der eigentlichen Vektorsuche einzugrenzen und so die Leistung und Genauigkeit zu verbessern. ClickHouses spaltenorientierte Speicherung, vektorisierte Abfrageausführung, fortgeschrittene Indizierung und parallele Verarbeitung machen es zu einer idealen Grundlage für MyScale bei großen Datensätzen, wobei Geschwindigkeit und Präzision ohne die Nachteile der Nachfilterung erhalten bleiben.
TL;DR:
Pinecone glänzt bei detaillierten, attributbasierten Suchen mit umfangreicher Metadatenunterstützung. MyScale bietet jedoch eine überlegene Leistung und Skalierbarkeit für große Datensätze mit seiner Vorfilterungsstrategie und SQL-basierten Architektur.
# Volltextsuche
MyScale bietet auch erweiterte Volltextsuche (opens new window) (FTS)-Funktionen mit der Tantivy-Bibliothek, einschließlich Fuzzy- und Wildcard-Suchen sowie der Relevanzbewertungsalgorithmus BM25. Diese Einrichtung ermöglicht MyScale einen intuitiven und effizienten Zugriff auf unstrukturierte Textdaten und ermöglicht es Benutzern, basierend auf Themen oder Schlüsselideen zu suchen. MyScale bietet jetzt eine robuste und effiziente Lösung für komplexe Anforderungen an die Textsuche. Um einen grundlegenden FTS-Index zu erstellen, können Sie der folgenden Syntax folgen:
-- Volltextsuchindex erstellen
ALTER TABLE [table_name] ADD INDEX [index_name] [column_name]
TYPE fts;
-- Abfrage durchführen
SELECT
id,
title,
body,
TextSearch(body, 'non-profit institute in Washington') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;
Im Gegensatz dazu ist Pinecone nur für die Vektorsuche konzipiert und enthält keine integrierten Funktionen für die Volltextsuche.
TL;DR:
Diese Volltextsuchfunktion von MyScale macht es zu einer vielseitigeren Wahl für Anwendungen, die umfassende Datenabfragen und -analysen erfordern.
# LLM-API-Integration
Hier gibt es nicht viel zu unterscheiden, da beide gängige APIs wie LangChain und LlamaIndex unterstützen. Um eine bessere Vorstellung zu geben, werde ich hier einen grundlegenden Code bereitstellen, der LangChain mit MyScale verwendet.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
output = docsearch.similarity_search("Wie funktionieren LLMs?", 3)
# Preisgestaltung
Sowohl Pinecone als auch MyScale bieten eine kostenlose Stufe an. Dies ist sehr hilfreich, da neue Benutzer oft ein neues Tool einfach ausprobieren möchten, bevor sie sich darauf einigen, es zu implementieren (oder nicht). Für neue Benutzer bietet die kostenlose Stufe von Pinecone bis zu 2 GB Speicherplatz, der etwa 300.000 Vektoren mit je 1.536 Dimensionen verarbeiten kann.
MyScale bietet hingegen kostenlosen Speicherplatz für bis zu 5 Millionen 768-dimensionale Vektoren, was etwa 2,5 Millionen 1.536-dimensionale Vektoren entspricht. Dies ist deutlich höher als die kostenlose Stufe von Pinecone und macht MyScale zu einer attraktiveren Option für Benutzer, die größere Datensätze ohne anfängliche Kosten verwalten müssen.
Sowohl Pinecone als auch MyScale bieten Benutzern leistungs- und speicheroptimierte Pods entsprechend ihren Anforderungen. Diese Flexibilität ermöglicht es den Benutzern, die beste Lösung entsprechend ihren spezifischen Anforderungen auszuwählen. In Bezug auf die Preisgestaltung ist MyScale im Vergleich zu Pinecone deutlich günstiger.
# Preisgestaltung für speicheroptimierte Pods
Die folgende Tabelle ist ideal für Benutzer, die eine höhere Speicherkapazität für ihre Anwendungen benötigen. Sie zeigt die verfügbaren Preis- und Kapazitätsoptionen für MyScale und Pinecone in der Kategorie der speicheroptimierten Pods.
| Pod-Typ (MyScale) | Pod-Größe | MyScale Grundpreis ($/Stunde) | MyScale Geschätzte Kapazität | Pod-Typ (Pinecone) | Pinecone Grundpreis ($/Stunde) | Pinecone Geschätzte Kapazität |
|---|---|---|---|---|---|---|
| Speicheroptimierter Pod | x 1 | $0,094/Stunde | 10 Millionen Vektoren | s1 | $0,11 | 5 Millionen Vektoren |
| Speicheroptimierter Pod | x 2 | $0,189/Stunde | 20 Millionen Vektoren | s1 | $0,22 | 10 Millionen Vektoren |
| Speicheroptimierter Pod | x 4 | $0,378/Stunde | 40 Millionen Vektoren | s1 | $0,44 | 20 Millionen Vektoren |
| Speicheroptimierter Pod | x 8 | $0,756/Stunde | 80 Millionen Vektoren | s1 | $0,89 | 40 Millionen Vektoren |
| Speicheroptimierter Pod | x 16 | $1,511/Stunde | 160 Millionen Vektoren | - | - | - |
| Speicheroptimierter Pod | x 32 | $3,022/Stunde | 320 Millionen Vektoren | - | - | - |
MyScale's speicheroptimierte Pods sind preislich angemessen und bieten eine höhere Kapazität. Im Vergleich zu Pinecone bietet MyScale die Möglichkeit, mehr Vektoren zu einem niedrigeren Stundensatz zu speichern.
# Preisgestaltung für leistungsoptimierte Pods
Die folgende Tabelle ist ideal für Benutzer, die die Leistung gegenüber der Kapazität priorisieren. Sie zeigt die verfügbaren Preis- und Kapazitätsoptionen für MyScale und Pinecone in der Kategorie der leistungsoptimierten Pods.
| Pod-Typ (MyScale) | Pod-Größe | MyScale Grundpreis ($/Stunde) | MyScale Geschätzte Kapazität | Pod-Typ (Pinecone) | Pinecone Grundpreis ($/Stunde) | Pinecone Geschätzte Kapazität |
|---|---|---|---|---|---|---|
| Standard-Pod | x 1 | $0,167/Stunde | 5 Millionen Vektoren | P2 | $0,17 | 1 Million Vektoren |
| Standard-Pod | x 2 | $0,333/Stunde | 10 Millionen Vektoren | P2 | $0,33 | 2 Millionen Vektoren |
| Standard-Pod | x 4 | $0,667/Stunde | 20 Millionen Vektoren | P2 | $0,67 | 4 Millionen Vektoren |
| Standard-Pod | x 8 | $1,333/Stunde | 40 Millionen Vektoren | P2 | $1,33 | 8 Millionen Vektoren |
| Standard-Pod | x 16 | $2,667/Stunde | 80 Millionen Vektoren | - | - | - |
| Standard-Pod | x 32 | $5,333/Stunde | 160 Millionen Vektoren | - | - | - |
Im Hinblick auf speicheroptimierte Pods bietet MyScale eine kostengünstigere Lösung mit der Möglichkeit, eine größere Anzahl von Vektoren im Vergleich zu Pinecone zu speichern. Dies macht MyScale zu einer ausgezeichneten Wahl für Benutzer, die eine budgetfreundliche Option suchen, die keine Kompromisse bei der Kapazität eingeht.
TL;DR:
MyScale ist in Bezug auf speicheroptimierte Pods eine kostengünstigere Lösung und bietet die Möglichkeit, eine größere Anzahl von Vektoren zu speichern, verglichen mit Pinecone. Dies macht MyScale ideal für Benutzer, die große Datenmengen effizient verwalten müssen.
# Benchmarking
Nun werden wir die Leistung von MyScale und Pinecone anhand einiger wichtiger Kennzahlen vergleichen. Während des gesamten Vergleichs verwenden wir MyScale mit MSTG, während zwei Varianten von Pinecone (1 Knoten und 5 Pods) verwendet werden.
# Durchsatz (Anfragen pro Sekunde)
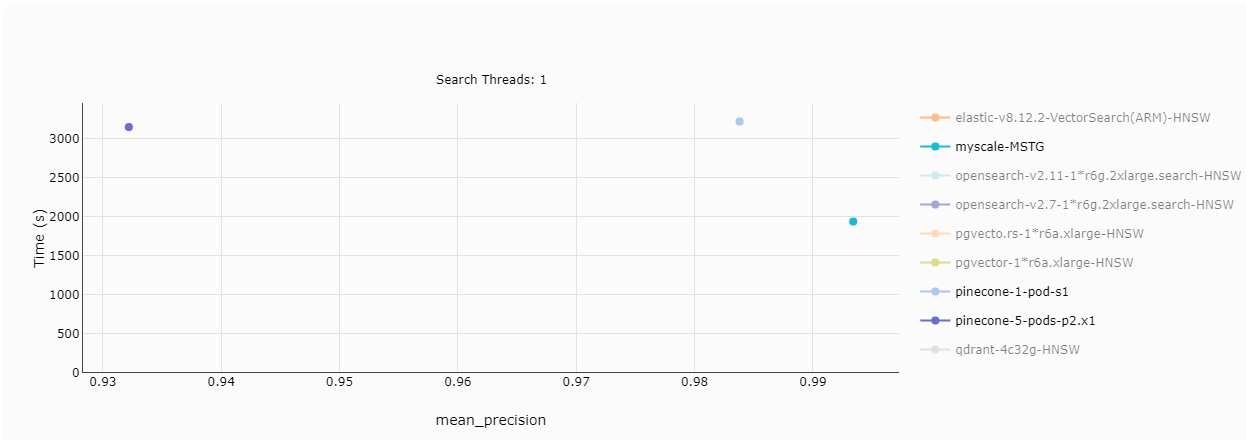
Der Durchsatz ist ein grundlegendes Maß für die Systemleistung, und Kunden sind naturgemäß an der Anzahl der pro Sekunde verarbeiteten Anfragen interessiert. Bei Einzel-Thread-Suchen liegt Pinecone’s s1 Pod deutlich hinter MyScale zurück. Allerdings können fünf p2 Pods von Pinecone eine vergleichbare Anzahl von Anfragen pro Sekunde verarbeiten. Wenn die Anzahl der Threads auf 2 erhöht wird, vergrößert sich die Leistungslücke, und bei 8 Threads beginnen selbst die fünf p2 Pods zurückzufallen.
Hinweis: In den Grafiken steht Gelb für MyScale, und die vier verschiedenen Punkte zeigen unterschiedliche Präzisionsstufen an. Höhere Präzision erfordert mehr Rechenleistung. Eine Einschränkung von Pinecone ist die Unfähigkeit, die Präzision wie MyScale anzupassen, was zu einer maximalen Abrufrate von nur 94% führt.
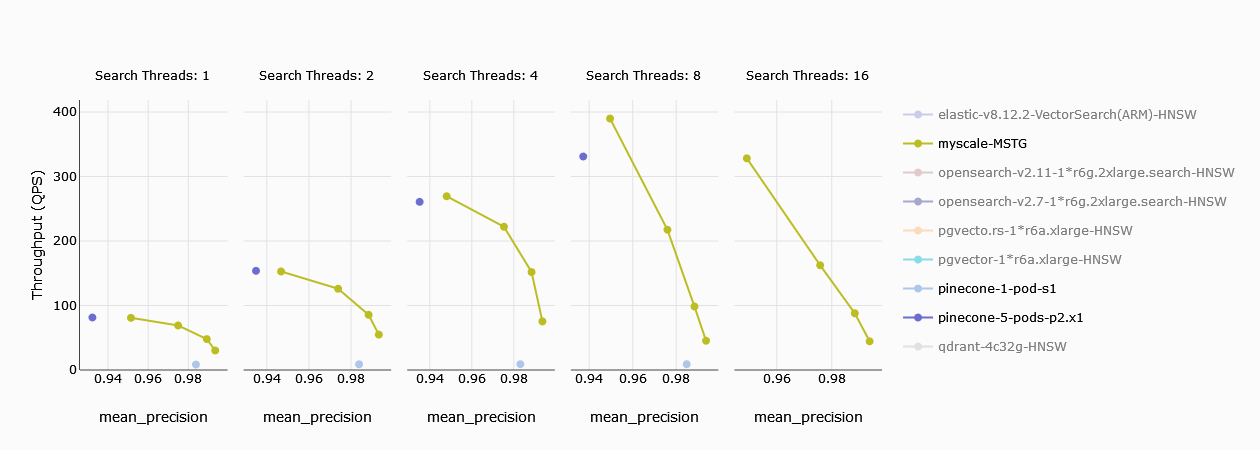
TL;DR:
Pinecone's s1 Pod kann mit MyScale nicht mithalten, aber fünf p2 Pods können dessen Leistung erreichen. Aufgrund der fehlenden Präzisionsanpassung von Pinecone kann die Abrufrate nicht 99% erreichen, im Gegensatz zu MyScale.
# Durchschnittliche Abfrageverzögerung
Die nächste interessante Kennzahl ist die durchschnittliche Abfrageverzögerung, die die durchschnittliche Zeit misst, die zur Verarbeitung einer Abfrage benötigt wird. In unserem Vergleich erreicht der s1 Pod von Pinecone nicht die Leistung von MyScale, während die fünf p2 Pods konkurrenzfähig sind.
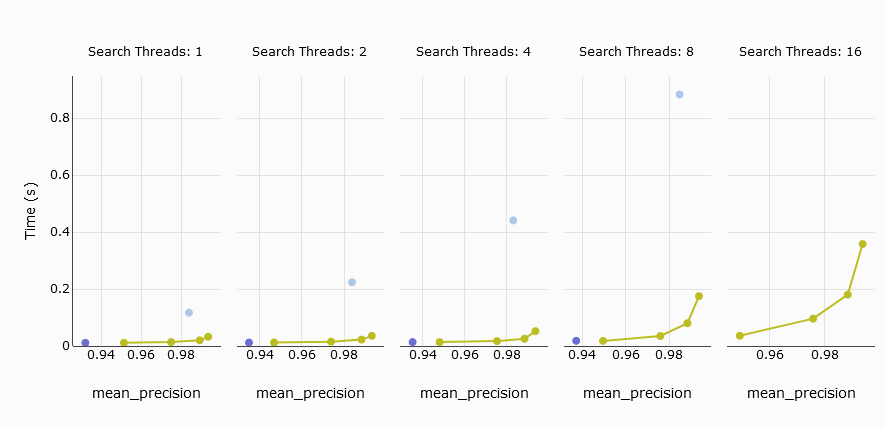
Um den Vergleich zu verbessern, schließen wir den s1 Pod aus und konzentrieren uns auf die fünf p2 Pods im Vergleich zu MyScale. Die Ergebnisse zeigen, dass MyScale und Pinecone bei bis zu 4 Threads ähnliche Verzögerungen aufweisen. Allerdings steigt die durchschnittliche Abfrageverzögerung von MyScale deutlich an, wenn die Anzahl der Threads 8 oder mehr erreicht.
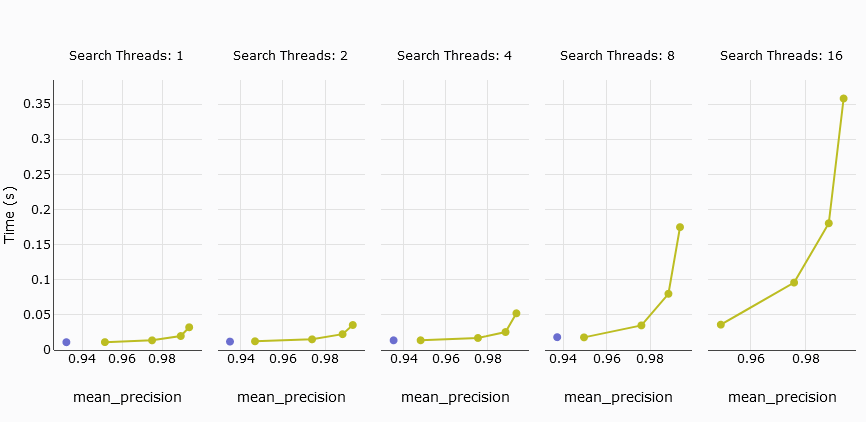
TL;DR:
Beim Vergleich von Pinecone's fünf p2 Pods mit MyScale zeigen beide bei niedriger Präzision ähnliche durchschnittliche Abfrageverzögerungen. Allerdings kann Pinecone seine Präzision nicht anpassen, um eine Abrufrate von mehr als 94% zu erreichen, im Gegensatz zu MyScale.
# Datenaufnahmedauer
Eine weitere nützliche Kennzahl ist die Datenaufnahmedauer – wie lange es dauert, die Datenbank hochzuladen und zu erstellen.
MyScale hatte die schnellste Datenaufnahmedauer für 5 Millionen Datenpunkte und schloss die Aufgabe in etwa 30 Minuten ab. Pinecone s1 benötigt etwa 53 Minuten.
# Kostenvergleich
Wir nutzten fünf p2 Pods in diesem Vergleich, die eine vergleichbare Leistung wie ein einzelner Standard-MyScale-Pod bieten. Allerdings belaufen sich die Kosten für fünf p2 Pods auf etwa 600 $ pro Monat, was sie fünfmal teurer macht als MyScale. Dieser deutliche Kostenunterschied hebt die überlegene Kosteneffizienz von MyScale hervor, da es die gleiche Leistung zu einem Bruchteil des Preises bietet.
| Datenbank | Pod-Typ | Monatliche Kosten ($) | Anmerkungen |
|---|---|---|---|
| MyScale | Standard-Pod der Größe x1 | 120 | Bietet eine vergleichbare Durchsatz- und Latenzleistung wie fünf Pinecone p2 Pods |
| MyScale | Kapazitätsoptimierter Pod | 68 | Kosteneffiziente Option zur Kapazitätsoptimierung |
| Pinecone | s1.x1 Pod | 80 | Für Speicher optimiert |
| Pinecone | 5 x p2.x1 Pods | 600 | Leistungsoptimiert durch horizontale Skalierung |
Trotz der höheren Kosten pro Pod im Vergleich zu Pinecone’s s1 Pod bietet MyScale eine vergleichbare Durchsatz- und Latenzleistung wie fünf Pinecone p2 Pods, aber zu nur einem Fünftel der Kosten.
TL;DR:
Zusammenfassung: MyScale's Standard-Pod ist weitaus kostengünstiger und bietet eine ähnliche Leistung wie fünf Pinecone p2 Pods, die fünfmal teurer sind.

# Fazit
Beim Vergleich von MyScale und Pinecone sticht MyScale durch seine SQL-basierte Integration, die Unterstützung verschiedener Datentypen und seine überlegene Leistung mit dem MSTG-Algorithmus hervor. MyScale bietet eine schnellere Abfragedurchsatz und Datenübernahmezeit, kostengünstige Speicheroptionen und Funktionen für die Volltextsuche. Dies macht es zu einer hervorragenden Wahl für die Verwaltung großer und vielfältiger Datensätze.
Pinecone ist stark bei detaillierten, attributbasierten Suchen mit umfangreicher Metadatenunterstützung. MyScale hingegen ist aufgrund seiner Open-Source-Natur, Skalierbarkeit und Leistungsvorteile eine vielseitigere und leistungsstärkere Option. MyScale übertrifft Pinecone in Bezug auf Leistung, Flexibilität und Kosten und eignet sich daher ideal für die Bewältigung verschiedener Anforderungen an das Datenmanagement im großen Maßstab.
Wenn Sie Vorschläge haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).



