
In diesem Beitrag vergleichen wir MyScale, eine integrierte Vektordatenbank mit voller SQL-Unterstützung, mit zwei traditionellen Datenbanken: PostgreSQL und OpenSearch. Beide Datenbanken haben kürzlich die Vektorsimilaritätssuche in ihre Werkzeugsammlungen aufgenommen.
Hinweis:
Wir aktualisieren kontinuierlich die Benchmark-Ergebnisse für MyScale und andere Vektordatenbank-Produkte in unserem Open-Source-Projekt, vector-db-benchmark (opens new window).
Das Aufkommen von Large Language Models (LLMs) hat das Interesse an der Integration von Konversations-Schnittstellen in verschiedene Anwendungen wie Suchmaschinen, Codegeneratoren und Datenanalysetools erhöht. Die Vektorsimilaritätssuche ist eine Schlüsseltechnologie, die dies ermöglicht und eine wichtige Rolle bei der Verbesserung der Leistung von LLMs durch Retrieval-Augmented Generation (RAG) spielt.
Auf dem Markt gibt es eine Vielzahl von Vektordatenbankprodukten. Einige sind spezialisierte Vektordatenbanken, die explizit für Vektorindizes entwickelt wurden, während andere integrierte Vektordatenbanken oder allgemeine Datenbanken sind, die um die Unterstützung der Vektorsuche erweitert wurden.
Integrierte Vektordatenbanken haben mehrere deutliche Vorteile gegenüber spezialisierten Vektordatenbanken, darunter:
- Sie speichern Vektoren und strukturierte Daten in derselben Datenbank, was komplexere gefilterte Suchen sowie SQL- und Vektorverbundabfragen ermöglicht.
- Sie nutzen leistungsstarke und weit verbreitete Abfragesprachen wie SQL für die Analyse strukturierter und vektorieller Daten.
- Sie nutzen die ausgereiften Tools und Integrationen von allgemeinen Datenbanken.
- Sie reduzieren zusätzliche Arbeitskosten für spezialisierte Fähigkeiten und Lizenzkosten für spezialisierte Datenbanken.
Die drei integrierten Vektordatenbanken, die wir vergleichen, sind wie folgt aufgestellt:
- MyScale ist eine integrierte Vektordatenbank, die auf ClickHouse entwickelt wurde und die Möglichkeit der Vektorsimilaritätssuche mit voller SQL-Unterstützung kombiniert.
- PostgreSQL bietet Unterstützung für die Vektorsuche durch seine Erweiterung pgvector (opens new window).
- OpenSearch integriert die neuronale (Vektor-)Suche in Version 2.9.0 (opens new window).
Wie unten beschrieben, zeigt unsere umfassende Benchmark-Evaluation, dass MyScale in Bezug auf gefilterte Vektorsuchgenauigkeit, Leistung, Kosteneffizienz und Indexaufbauzeit bei weitem die anderen Produkte übertrifft. Wichtig ist, dass MyScale das einzige getestete Produkt ist, das eine hohe Suchgenauigkeit und QPS bei verschiedenen Filterverhältnissen bietet.
Darüber hinaus übertrifft MyScale auch spezialisierte Vektordatenbanken, siehe diesen Beitrag (opens new window) und unseren Open-Source-Benchmark (opens new window) für weitere Details. Wie in der folgenden Abbildung gezeigt, macht die Kombination aus voller SQL-Unterstützung und hoher Vektorsuchleistung MyScale zu einer überzeugenden Wahl für die Verwaltung Ihrer KI-/LLM-bezogenen Daten, sowohl strukturiert als auch vektorisiert:
# Benchmark-Setup
Wir haben Benchmarks für MyScale, OpenSearch und zwei Postgres-Vektorsuch-Erweiterungen durchgeführt. Die Details werden unten angegeben.
| Datenbank | Pod-Typ | Monatliche Kosten (USD) | Anmerkungen |
|---|---|---|---|
| MyScale (opens new window) | Pod-Größe: x1 | 120 | Derzeit kostenlos für die Entwicklungsstufe (opens new window). |
| Postgres mit pgvector (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS für PostgreSQL |
| Postgres mit pgvecto.rs (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS für PostgreSQL |
| AWS OpenSearch Service (opens new window) | r6g.2xlarge.search (opens new window) (8C 64GB) | 488 | Amazon OpenSearch Service-Domäne |
Wir haben 5 Millionen 768-dimensionale Vektoren verwendet, die aus dem LAION 2B Images (opens new window)-Datensatz generiert wurden, sowohl für Vektorsuchen als auch für gefilterte Vektorsuchtests.
Hinweis:
Der vollständige Code, die Datensätze und die Ergebnisse finden Sie auf unserer Benchmark-Seite (opens new window).
Wir haben den kleinsten Pod-Typ für jede Datenbank ausgewählt, der alle Vektoren hosten kann.
Da die neuesten Versionen von pgvector und pgvecto.rs noch nicht von PostgreSQL-Cloud-Diensten weit verbreitet übernommen wurden, haben wir uns für das Self-Hosting entschieden, als wir unsere Benchmarks durchgeführt haben. In der obigen Tabelle haben wir jedoch die Preise für Amazon RDS für PostgreSQL zum Vergleich aufgenommen.
Hinweis:
PostgresSQL-Cloud-Dienste wie Supabase (opens new window) und TimeScaleDB (opens new window) können für ähnliche Hardware-Konfigurationen mehr kosten.
Für OpenSearch haben wir uns für r6g.2xlarge.search (64 GB Speicher) entschieden, da wir beim Versuch, den Vektorindex auf einer r6g.xlarge.search (32 GB Speicher) Instanz zu erstellen, auf Probleme gestoßen sind. Wie die Zusammenfassung zeigt, bleibt MyScale die kostengünstigste integrierte Vektordatenbank.
# Benchmark-Ergebnisse
Wir haben unsere Ergebnisse wie folgt zusammengefasst:
# Vektorsuche
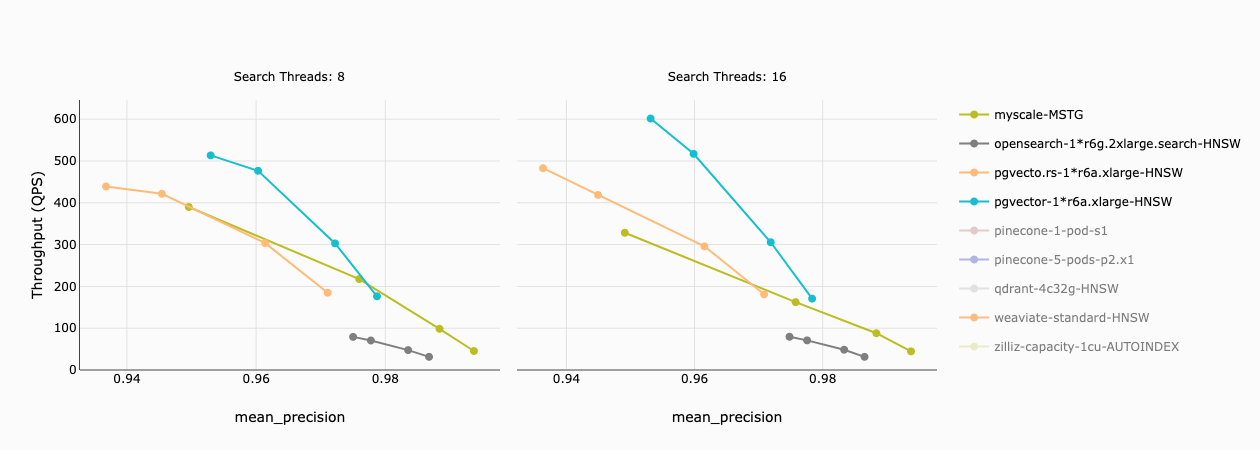
Im folgenden Diagramm stellt die x-Achse die Genauigkeit und die y-Achse die Durchsatzrate (QPS) für jede Vektordatenbank dar. Wir haben folgendes festgestellt:
- MyScale und die beiden Postgres-Erweiterungen haben bei einer Genauigkeit von 97% einen ähnlichen Durchsatz.
- pgvector und pgvecto.rs können bei niedrigeren Genauigkeiten einen höheren Durchsatz erzielen, verursachen jedoch deutlich höhere Kosten als MyScale.
- OpenSearch war in Bezug auf Geschwindigkeit für alle Genauigkeiten langsamer als die anderen.
# Gefilterte Vektorsuche
In realen Szenarien reicht die reine Vektorsuche selten aus. Vektoren werden normalerweise mit Metadaten geliefert, und Benutzer müssen häufig einen oder mehrere Filter auf diese Metadaten anwenden.
Das folgende Diagramm beschreibt den Durchsatz von MyScale (und anderen integrierten Vektordatenbanken) auf einem Datensatz mit einem Filterverhältnis von 1%. Ein Filterverhältnis von 1% bedeutet, dass nach Anwendung der Filterbedingung 50.000 Vektoren (1% x 5 Millionen Vektoren) verbleiben.
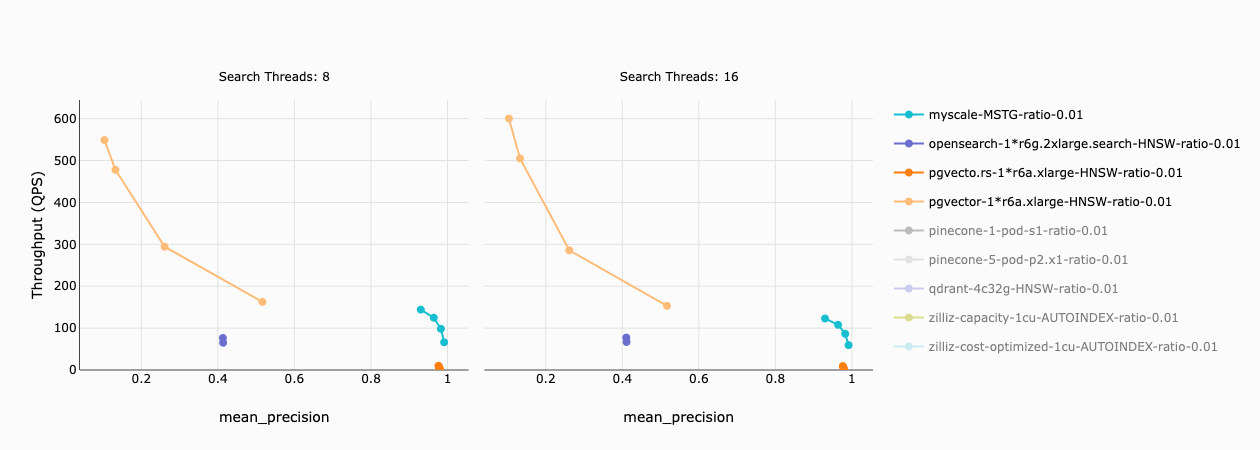
Unsere Ergebnisse ergaben folgende Informationen:
- Die Genauigkeit von pgvector und OpenSearch ist gering (weniger als 50%) und in der Praxis kaum verwendbar.
- Der Durchsatz von pgvecto.rs ist relativ gering (weniger als 10 QPS).
- Nur MyScale bietet einen gesunden Durchsatz (66 - 144 QPS) und eine Genauigkeit (93% - 99%).
Es gibt zwei Hauptansätze bei der Implementierung von gefilterten Vektorsuchen in diesen Datenbanken.
# Nachfilterung
Bei dieser Methode wird zuerst eine Vektorsuche durchgeführt und anschließend werden die Ergebnisse entfernt, die nicht mit dem Filter übereinstimmen. Leider gibt es zwei wesentliche Nachteile bei der Verwendung dieser Methode:
- Erstens ist die Anzahl der Elemente in der Suche unvorhersehbar, da der Filter auf eine bereits reduzierte Liste von Kandidaten angewendet wird.
- Zweitens, wenn der Filter sehr restriktiv ist, d.h. er passt nur auf einen kleinen Prozentsatz der Datenpunkte im Verhältnis zur Größe des Datensatzes, besteht die Möglichkeit, dass die ursprüngliche Vektorsuche überhaupt keine Übereinstimmungen enthält.
# Vorfilterung
Die niedrigen Genauigkeiten von pgvector und OpenSearch sind auf ihren Einsatz von Nachfilterung zurückzuführen. Im Gegensatz dazu verwenden MyScale und pgvecto.rs einen anderen Ansatz, der als Vorfilterung bekannt ist. Der Filter wird zuerst angewendet und ein Bitmap wird an den Vektorindex übergeben, um die Vektorsuche durchzuführen.
Während unseres Benchmarks hat der von pgvecto.rs verwendete HNSW-Algorithmus bei niedrigem Filterverhältnis schlecht abgeschnitten. Darüber hinaus ist die zeilenbasierte Speicherung von PostgreSQL für die groß angelegte Scan-Operation, die bei der Vorfilterung erforderlich ist, nicht geeignet, was die suboptimale Leistung weiter verschlechtert. MyScale hingegen löst dieses Problem durch die Kombination aus ClickHouses schneller spaltenbasierter SQL-Ausführungsmaschine (opens new window) und unserem proprietären MSTG-Vektorindexalgorithmus (opens new window).
# Bewertung der Kosteneffizienz: Reine Vektorsuche vs. Gefilterte Vektorsuche
Bei der Auswahl einer Datenbank muss man nicht nur die Rohleistung, sondern auch den Wert der Investition berücksichtigen. Die Kosteneffizienz, insbesondere bei höheren Genauigkeitsniveaus wie 95%, wird zu einem entscheidenden Kriterium für Unternehmen, die umfangreiche Vektorsuchen durchführen.
# Reine Vektorsuche
Um einen klaren Einblick in die Kosteneffizienz zu erhalten, haben wir das Kosten-Leistungs-Verhältnis jeder Datenbank untersucht, indem wir die monatlichen Kosten in Bezug auf die Queries per Second (QPS) betrachtet haben, die sie bei einer Genauigkeit von etwa 95% erreichen können. Dies gibt einen Hinweis auf die Kosten pro 100 QPS für jede Datenbank.
Wie die folgenden Ergebnisse zeigen, bietet MyScale eine außergewöhnliche Kosteneffizienz und übertrifft seinen nächsten Konkurrenten um den Faktor mindestens 1,8x.
| Datenbank | Monatliche Kosten (USD) pro 100 QPS |
|---|---|
| MyScale | 30 |
| pgvector | 54 |
| pgvecto.rs | 79 |
| OpenSearch | 613 |
# Gefilterte Vektorsuche mit 1% Filterverhältnis
Jedoch erfordern viele reale Szenarien mehr als reine Vektorsuchen. Es werden häufig Filter auf Datensätze angewendet, um die Ergebnisse einzugrenzen. Wenn wir die Kosteneffizienz für eine gefilterte Vektorsuche mit einem Filterverhältnis von 1% bewerten, ändert sich das Bild. Insbesondere konnten pgvector und OpenSearch keine Genauigkeit von mehr als 50% erreichen. Diese geringe Genauigkeit ist in den meisten Fällen unbrauchbar und markiert sie in dieser Analyse als N/A.
| Datenbank | Monatliche Kosten (USD) pro 100 QPS |
|---|---|
| MyScale | 96 |
| pgvector | N/A |
| pgvecto.rs | 3290 |
| OpenSearch | N/A |
Zusammenfassend lässt sich sagen, dass MyScale bei reinen Vektorsuchen die Nase vorn hat, aber seine Dominanz bei gefilterten Vektorsuchen noch deutlicher wird. Mit erstklassiger Leistung zu einem Bruchteil der Kosten garantiert MyScale Unternehmen optimale Renditen für ihre Investitionen. Diese Kombination aus hoher Genauigkeit, Kosteneffizienz und Leistung macht MyScale zu einer herausragenden Wahl für Organisationen, die integrierte Vektordatenbanken effektiv nutzen möchten.
# Indexaufbauzeit
Nach dem Einfügen von Vektoren in eine Vektordatenbank müssen Benutzer einen Vektorindex erstellen, bevor sie Vektorsuchen durchführen können. Die Zeit, die für den Aufbau des Index benötigt wird, ist entscheidend für schnelle Suchergebnisse. Die Aufbauzeiten für die vier verschiedenen Vektordatenbanken sind in der folgenden Tabelle beschrieben:
| Datenbank | Hochladen & Aufbauzeit |
|---|---|
| MyScale | 32 min |
| Pgvector | 10,9 Stunden |
| Pgvecto.rs | 80 min |
| OpenSearch | 45 min |
Diese Ergebnisse zeigen, dass MyScale mit der schnellsten Aufbauzeit klar führend ist, während pgvector aufgrund des Mangels an paralleler Aufbauunterstützung extrem langsam beim Aufbau des HNSW-Vektorindex war. Ein schneller Indexaufbau ist entscheidend, wenn die Anwendung das Einfügen und Aktualisieren vieler Vektoren erfordert (wie z.B. Online-Chats im großen Maßstab, Dokumentenbearbeitung usw.) und reduziert auch die Ressourcenkonflikte zwischen Indexaufbau und Vektorsuche.
# Fazit
Nach einer umfangreichen Analyse übertrifft MyScale konsequent seine Konkurrenten und zeigt eine überlegene Leistung bei gefilterter Vektorsuche und schneller Indexaufbauzeit. Unter allen getesteten Produkten ist MyScale die einzige integrierte Vektordatenbank, die eine hohe Suchgenauigkeit und QPS bei verschiedenen Filterverhältnissen bietet. Was MyScale auch von anderen Produkten unterscheidet, ist seine herausragende Kosteneffizienz, die es zu einer robusten Option für integrierte Vektordatenbanken und einer finanziell klugen Wahl macht. Für Organisationen, die die Möglichkeiten integrierter Vektordatenbanken nutzen möchten, ist MyScale aufgrund seiner unschlagbaren Kombination aus Leistung, Präzision und Preis-Leistungs-Verhältnis ein herausragender Kandidat.

# Weitere Erkundungen
Für ein tieferes Verständnis, wie sich MyScale in Bezug auf spezialisierte Vektordatenbanken in Bezug auf Leistung schlägt, empfehlen wir das Lesen dieses Beitrags (opens new window).
Und für diejenigen, die erwägen, ihre Vektordaten von PostgreSQL zu MyScale zu migrieren, bietet dieser Leitfaden (opens new window) wertvolle Einblicke und Schritt-für-Schritt-Anleitungen.



