
Vektordatenbanken (opens new window) und Vektorsuchen (opens new window) gewinnen aufgrund ihrer beeindruckenden Geschwindigkeit und Skalierbarkeit schnell an Popularität. Im Gegensatz zu traditionellen Machine-Learning-Modellen nutzen diese Datenbanken effiziente Ähnlichkeitsmaße wie Euklidische Distanz (opens new window), Kosinus-Ähnlichkeit (opens new window) usw., um schnelle Suchergebnisse zu liefern, ohne umfangreiches Training zu erfordern. Diese Effizienz, gepaart mit ihrer kostengünstigen Natur im Vergleich zu ML-basierten Alternativen, macht sie zu einer attraktiven Lösung für verschiedene Anwendungen.
Angesichts der wachsenden Landschaft von Vektordatenbanken kann es schwierig sein, die richtige für Ihre spezifischen Anforderungen auszuwählen. Faktoren wie Durchsatz, Kosten und Funktionalität spielen eine entscheidende Rolle bei der Bestimmung der idealen Lösung.
Dieser Artikel, der dritte in unserer Serie, geht detailliert auf den Vergleich von zwei prominenten Konkurrenten ein: MyScaleDB (opens new window) und Qdrant (opens new window). Beide Datenbanken bieten einzigartige Vorteile, so dass eine umfassende Analyse für fundierte Entscheidungen unerlässlich ist.
Hinweis: Wenn Sie neu im Bereich der Vektordatenbanken sind, empfehlen wir Ihnen, mit dem ersten Artikel (opens new window) in dieser Serie zu beginnen, um ein grundlegendes Verständnis dieser leistungsstarken Technologie zu erlangen.
# Einführung in MyScaleDB und Qdrant
# MyScaleDB
MyScaleDB zeichnet sich als cloud-native Datenbank aus, die für KI-Anwendungen und -Lösungen optimiert ist. Aufbauend auf dem robusten Fundament der Open-Source- und hochskalierbaren ClickHouse-Datenbank (opens new window) bietet MyScaleDB mehrere überzeugende Vorteile:
- Vereinheitlichte Plattform für KI: MyScaleDB optimiert KI-Workflows, indem es sowohl strukturierte als auch vektorisierte Daten nahtlos in einer einzigen, vereinheitlichten Plattform verwaltet und verarbeitet. Dadurch entfällt die Notwendigkeit komplexer Datenpipelines und vereinfacht die Entwicklung.
- Kompromisslose Leistung: Durch den Einsatz einer modernen OLAP-Datenbankarchitektur bietet MyScaleDB eine außergewöhnliche Leistung für Operationen mit vektorisierten Daten. Diese Architektur ermöglicht eine blitzschnelle Abfrageausführung und eignet sich daher ideal für anspruchsvolle KI-Workloads.
- SQL-basierte Einfachheit: MyScaleDB nutzt die Universalität von SQL und ermöglicht Entwicklern die Interaktion mit der Datenbank über eine vertraute und weit verbreitete Sprache. Dadurch entfällt die Notwendigkeit, spezialisierte Abfragesprachen zu erlernen, was die Entwicklung beschleunigt und die Produktivität steigert.
- MSTG-Indexierung für verbesserte Suche: MyScaleDB verwendet den Multi-Scale Tree Graph Algorithmus (MSTG) (opens new window), einen fortschrittlichen Indexierungsalgorithmus (opens new window), der für hohe Datendichte und optimierte Suchleistung entwickelt wurde. MSTG eignet sich sowohl für grundlegende als auch für gefilterte Vektorsuchen (opens new window) und gewährleistet eine schnelle und präzise Wiederherstellung relevanter Informationen.
# Qdrant
Qdrant ist eine weitere zeitgemäße Vektordatenbank. Sie ist ebenfalls Open Source und sowohl in Docker als auch in der Cloud verfügbar. Einige der Funktionen von Qdrant sind:
- Erweiterte Komprimierung: Qdrant verwendet binäre Quantisierung (opens new window), um jede numerische Vektoreinbettung in einen Vektor von booleschen Werten umzuwandeln. Dadurch wird eine bis zu 40-fach bessere Suchleistung erzielt.
- Multitenancy-Unterstützung: Das Vorhandensein einer einzigen Sammlung mit partitionierter Nutzlast wird als Multitenancy (opens new window) bezeichnet. Qdrant unterstützt dies für die gemeinsame Nutzung von Instanzen durch mehrere Benutzer.
- I/O Uring (opens new window): Qdrant bietet Unterstützung für
io_uring, um die Durchsatzleistung zu verbessern und den Overhead von Betriebssystemaufrufen zu reduzieren.
Nachdem wir nun wissen, was MyScaleDB und Qdrant bieten, wollen wir uns auf die wesentlichen Unterschiede konzentrieren. Diese Unterscheidungen helfen Ihnen dabei, festzustellen, welche Datenbank am besten zu Ihren spezifischen Anforderungen und Prioritäten passt, sei es in Bezug auf Leistung, einzigartige Funktionen oder andere Aspekte.
# Hosting-Flexibilität: Ein wichtiger Aspekt für Vektordatenbanken
Bei der Bewertung von Datenbanklösungen spielt das Hosting eine entscheidende Rolle für die Leistung, Skalierbarkeit und Verwaltbarkeit. Die richtige Hosting-Option gewährleistet, dass Ihre Datenbank schwankende Arbeitslasten problemlos bewältigen, eine hohe Verfügbarkeit aufrechterhalten und den administrativen Aufwand minimieren kann.
In Bezug auf das Hosting bieten sowohl MyScaleDB als auch Qdrant Open-Source-Versionen, Cloud-basierte Lösungen und On-Premise-Lösungen an. Das Cloud-Hosting bietet sowohl kostenlose als auch kostenpflichtige Ebenen, wie wir gleich im Detail sehen werden.
# Cloud-Hosting
Für MyScaleDB Cloud (opens new window) können Sie mit einem kostenlosen Pod beginnen, der 5 Millionen 768-dimensionale Vektoren unterstützt. Melden Sie sich hier (opens new window) an und werfen Sie einen Blick auf MyScaleDB QuickStart (opens new window) für weitere Anweisungen.
Qdrant bietet Ihnen einen dauerhaft kostenlosen Cluster mit 1 GB Speicherkapazität ohne Vorabkosten. Um Qdrant zu nutzen, besuchen Sie den Cloud-Quickstart (opens new window).
# On-Premise
Für die On-Premise-Lösung ist das Docker-Image eine allgemeine Option. Wir können das MyScaleDB Docker-Image wie folgt starten:
docker run --name MyScaleDB --net=host MyScaleDB/MyScaleDB:1.6
Verbinden Sie sich dann mit der Datenbank über den ClickHouse-Client:
docker exec -it MyScaleDBdb clickhouse-client
Ebenso kann Qdrant lokal mit Docker ausgeführt werden:
docker run -p 6333:6333 qdrant/qdrant
# Kernfunktionalitäten
Während Hosting-Optionen die Grundlage für die Zugänglichkeit und Skalierbarkeit einer Datenbank bilden, sind es die Kernfunktionalitäten, die MyScaleDB und Qdrant wirklich voneinander unterscheiden. Dieser Abschnitt untersucht die wesentlichen Funktionen jeder Plattform und gibt Einblicke in die Art und Weise, wie sie die Feinheiten der vektorbasierten Datenverarbeitung handhaben.
Das Verständnis dieser Funktionen hilft Ihnen dabei zu sehen, wie jede Datenbank wichtige Aufgaben in der vektorbasierten Datenverarbeitung bewältigt und welche am besten Ihren spezifischen Anforderungen entspricht.
# Abfragesprache und API-Unterstützung
Die Wahl der Abfragesprache und die verfügbare API-Unterstützung spielen eine entscheidende Rolle für die Produktivität der Entwickler und die Integration. Schauen wir uns an, wie MyScaleDB und Qdrant diese Aspekte behandeln:
# Unterstützung mehrerer Sprachen:
- Qdrant: Qdrant bietet umfangreiche Unterstützung für mehrere Sprachen und richtet sich an eine Vielzahl von Entwicklern mit SDKs für Python (opens new window), Java (opens new window), Go (opens new window), .Net (opens new window), Rust (opens new window) und TypeScript/JavaScript (opens new window). Diese breite Sprachunterstützung gewährleistet eine nahtlose Integration mit verschiedenen Technologiestacks.
- MyScaleDB: MyScaleDB bietet SDKs für Python, Java, Go und Node.JS (opens new window) und bietet solide Unterstützung für beliebte Programmiersprachen.
Obwohl beide Datenbanken eine respektable Unterstützung für mehrere Sprachen bieten, unterscheidet sich MyScaleDB durch seine einzigartige Verwendung von SQL. Sie können herkömmliche SQL-Abfragen mit MyScaleDB verwenden, und es funktioniert nahtlos mit Vektordatenbanken oder sogar einer Kombination aus herkömmlichen und Vektordatenbanken wie folgt:
SELECT id, date, label,
distance(data, {target_row_data}) AS dist
FROM default.myscale_search
ORDER BY dist LIMIT 10
Die Methode distance in MyScaleDB berechnet die Ähnlichkeit zwischen Vektoren, indem sie den Abstand zwischen einem bestimmten Vektor und allen in einer bestimmten Spalte gespeicherten Vektoren misst.
Hinweis: Wenn Sie gerne mit SQL arbeiten, ist MyScaleDB definitiv die richtige Wahl.
# Unterstützte Datentypen
Die Fähigkeit, verschiedene Datentypen zu verarbeiten, ist für jede Datenbank von entscheidender Bedeutung, und Vektordatenbanken bilden da keine Ausnahme. Schauen wir uns MyScaleDB und Qdrant in Bezug auf ihre unterstützten Datentypen an:
# Qdrants flexible JSON-Ansatz
Qdrant nutzt die Flexibilität von JSON-Payloads und ermöglicht so die Speicherung und Abfrage einer Vielzahl von Datentypen, einschließlich:
- Schlüsselwörter: Für textbasierte Suchen und Filterungen.
- Ganzzahlen und Fließkommazahlen: Für numerische Daten und Bereichsabfragen.
- Verschachtelte Objekte und Arrays: Zur Darstellung komplexer Datenstrukturen.
Dieser JSON-zentrierte Ansatz bietet Flexibilität bei der Datenmodellierung und ermöglicht verschiedene Anwendungsfälle.
# MyScaleDBs SQL-basierte Vielseitigkeit:
MyScaleDB geht noch einen Schritt weiter bei der Unterstützung von Datentypen, indem es seine volle SQL-Kompatibilität nutzt. Dadurch kann es nicht nur Vektordaten, sondern auch eine Vielzahl von herkömmlichen Datentypen verwalten, darunter:
- Strukturierte Daten: Herkömmliche relationale Datentypen wie Ganzzahlen, Fließkommazahlen, Zeichenketten, Datumsangaben usw.
- JSON: Zur Verarbeitung von halbstrukturierten Daten und verschachtelten Objekten.
- Geodaten: Für standortbasierte Abfragen und räumliche Analysen.
- Zeitreihendaten: Zur Speicherung und Analyse von zeitgestempelten Daten.
Die Fähigkeit von MyScaleDB, sowohl Vektordaten als auch verschiedene herkömmliche Datentypen innerhalb einer einzigen Plattform zu verarbeiten, bietet einen erheblichen Vorteil. Dieser einheitliche Ansatz vereinfacht das Datenmanagement, beseitigt Datensilos und ermöglicht leistungsstarke Abfragen, die verschiedene Datentypen umfassen.
Hier ist ein Beispiel für eine Tabelle, die die Vielfalt der von MyScaleDB verwalteten Spalten zeigt, einschließlich Vektordaten.
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 768
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Dieser SQL-Befehl erstellt eine Tabelle mit strukturierten und vektorisierten Daten, erzwingt eine Vektorgröße von 768 und optimiert Abfragen durch die Sortierung nach id.
TL;DR: Beide Datenbanken unterstützen effektiv eine Vielzahl von numerischen und Textdatentypen, aber MyScaleDB geht mit seiner fortgeschrittenen SQL-Kompatibilität, seinen leistungsstarken OLAP-Funktionen und der umfassenden Unterstützung komplexer Datenstrukturen wie geografischen und zeitgestempelten Daten noch einen Schritt weiter.
# Indexierung
Für die Indexierung verwendet Qdrant den Hierarchical Navigable Small World (HNSW) (opens new window)-Algorithmus, der zwar für Standard-Vektorsuchen effektiv ist, aber bei gefilterten Suchoperationen Schwierigkeiten hat.
MyScaleDB behebt diese Einschränkung, indem es den Multi-Scale Tree Graph (MSTG)-Algorithmus einführt. MSTG kombiniert hierarchisches Baumclustering mit graphenbasierter Suche und verbessert so die Abrufgeschwindigkeit und -leistung erheblich. Dadurch ist er sowohl für Standard- als auch für komplexe gefilterte Vektorsuchoperationen äußerst effizient.
Übrigens unterstützen sowohl MyScaleDB als auch Qdrant Multi-Vektor-Suche.
Hinweis: MSTG übertrifft zeitgenössische Indexierungsalgorithmen und verleiht MyScaleDB einen erheblichen Vorteil sowohl bei Standard- als auch bei gefilterten Vektorsuchen.
# Volltextsuche
Die Volltextsuche (opens new window) ist sowohl in Qdrant (ab Version 0.10.0) als auch in MyScaleDB verfügbar. Qdrant implementiert die Volltextsuche, indem es die Tokenisierung und Indexierung von Textfeldern unterstützt, was es ermöglicht, nach bestimmten Wörtern oder Phrasen zu suchen und zu filtern.

MyScaleDB verwendet hingegen die Tantivy-Bibliothek, die den BM25-Algorithmus zur genauen und effizienten Dokumentenwiederherstellung nutzt.
# Beispiel für Qdrant
Hier ist ein Beispiel für die Erstellung eines Volltextindexes (in ihrer Terminologie normalerweise als Payload-Index bezeichnet) in Qdrant:
from qdrant_client import QdrantClient, models
client = QdrantClient(url="<http://localhost:6333>")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=15,
lowercase=True,
),
)
Dieser Code-Schnipsel in Qdrant richtet einen Textindex ein, indem er ein Textfeld basierend auf Parametern wie Wortlänge und Groß-/Kleinschreibung tokenisiert.
# Beispiel für MyScaleDB
Im Beispiel für MyScaleDB verwenden wir den stem-Tokenizer mit englischen Stoppwörtern, der die Suchgenauigkeit verbessern kann, indem er sich auf die Grundform von Wörtern konzentriert. In diesem Fall verwenden wir die Tabelle en_wiki_abstract (sie wurde im gesamten Beispiel (opens new window) verwendet, wenn Sie mehr Details sehen möchten).
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
Hinweis: Es gibt nicht viel Unterschiede zwischen den beiden in Bezug auf die Volltextsuche, da beide effektive Lösungen bieten.
# Gefilterte Suche
MyScaleDB optimiert die gefilterte Vektorsuche durch seinen MSTG-Algorithmus in Kombination mit Bitmasking-Techniken. Diese Kombination, zusammen mit den fortschrittlichen Indexierungs- und parallelen Verarbeitungsfähigkeiten von ClickHouse, ermöglicht es MyScaleDB, große Datensätze effizient zu verarbeiten. Durch die Verwendung einer Vorfilterungsstrategie schränkt MyScaleDB den Datensatz vor der eigentlichen Vektorsuche ein, so dass nur die relevantesten Daten verarbeitet werden. Dies steigert sowohl die Leistung als auch die Genauigkeit erheblich.
Qdrant verwendet einen filterbaren HNSW-Algorithmus (opens new window), der Filter während des Suchvorgangs anwendet, um sicherzustellen, dass nur relevante Knoten im Suchgraphen berücksichtigt werden.
# Geo-Suche
Sowohl MyScaleDB als auch Qdrant unterstützen die Geo-Suche. MyScaleDB verfügt über eine Reihe von geospatialen Funktionen (opens new window), um die Geo-Suche zu unterstützen. Zum Beispiel findet diese Funktion den Abstand zwischen zwei Punkten auf der Erde (angenommen als Mannigfaltigkeit):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# Integration von LLM-APIs
Die größte Anwendung von Vektorsuchen sind wahrscheinlich LLMs und RAGs. Sowohl Qdrant als auch MyScaleDB werden durch die Unterstützung mehrerer LLM-API-Integrationen wie LlamaIndex (opens new window), LangChain (opens new window) und Hugging Face (opens new window) unterstützt.
# Preisgestaltung
Sowohl Qdrant als auch MyScaleDB verwenden ein Freemium-Preismodell und bieten kostenlose Ebenen für Experimente und kleinere Projekte sowie leistungsstärkere kostenpflichtige Ebenen für anspruchsvolle Workloads an. Beide Plattformen ermöglichen es den Benutzern, ihre kostenlosen Angebote zu erkunden, ohne Kreditkarteninformationen anzugeben.
# Kostenlose Ebene
- Qdrant: Bietet 1 GB Speicherkapazität in seiner kostenlosen Ebene.
- MyScaleDB: Bietet eine deutlich großzügigere kostenlose Ebene, die die Speicherung von bis zu 5 Millionen 768-dimensionalen Vektoren ermöglicht. Um dies in Perspektive zu setzen: Um diese Speicherkapazität auf der Plattform von Qdrant zu erreichen, wäre ein kostenpflichtiger Plan erforderlich, der etwa 275 US-Dollar pro Monat kosten würde.
# Kostenpflichtige Ebene
Für die kostenpflichtige Ebene bieten sowohl Qdrant als auch MyScaleDB alle 3 Arten von Cloud-Hostings an: GCP, Azure und AWS. Normalerweise sind Azure und AWS teurer, während GCP die wirtschaftlichste verfügbare Option ist.
Für die kostenpflichtige Ebene vergleichen wir Qdrants GCP-Hosting mit MyScaleDB. Bei MyScaleDB werden sowohl kapazitäts- als auch leistungsoptimierte Optionen betrachtet, wobei eine konsistente Vektorgröße von 768 Dimensionen für alle Vergleiche verwendet wird.
| Kapazität | Qdrant ($)/Stunde | Knoten | MyScaleDB kapazitätsoptimiert ($)/Stunde | Pods | MyScaleDB leistungsoptimiert ($)/Stunde | Pods |
|---|---|---|---|---|---|---|
| 10 Millionen | 0,75 | 1 | 0,09 | 1 | 0,33 | 2 |
| --- | --- | --- | --- | --- | --- | --- |
| 20 Millionen | 1,5 | 1 | 0,19 | 2 | 0,67 | 4 |
| 40 Millionen | 3,02 | 2 | 0,38 | 4 | 1,33 | 8 |
| 80 Millionen | 4,52 | 3 | 0,76 | 8 | 2,67 | 16 |
| 160 Millionen | 9,05 | 6 | 1,51 | 16 | 5,33 | 32 |
| 320 Millionen | 16,58 | 11 | 3,02 | 32 | 10,66 | 64 |
In den kapazitätsoptimierten Pods von MyScaleDB erhalten wir 10 Millionen Vektoren pro Pod, während die leistungsoptimierte Einstellung eine geringere Latenz bietet und daher mehr Pods für die Speicherung erfordert. Wir können sehen, dass selbst die leistungsoptimierten Pods von MyScaleDB deutlich günstiger sind als die wirtschaftlichste Einstellung von Qdrant.
Eine weitere Beobachtung ist, dass MyScaleDB einen linearen Skalierungsfaktor aufweist, während Qdrant ein asymmetrisches Muster aufweist, wie wir in diesem Diagramm sehen können.
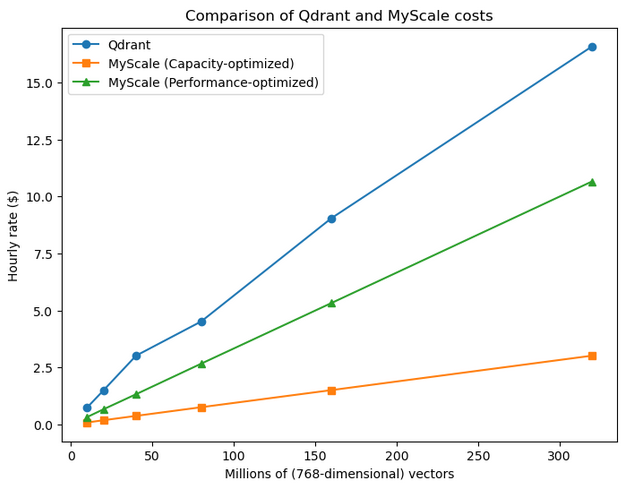
Hinweis: Wenn es um die Preisgestaltung - kostenlose oder kostenpflichtige Ebene geht, gibt es keinen Vergleich zu MyScaleDB.
# Benchmarking
Während die vorherigen Funktionsvergleiche wertvolle Einblicke bieten, bietet objektives Benchmarking ein konkreteres Verständnis der Leistungsfähigkeit von MyScaleDB und Qdrant.
# Durchsatz (Abfragen pro Sekunde)
Der Durchsatz, der in der Regel in Abfragen pro Sekunde (QPS) gemessen wird, spiegelt direkt die Fähigkeit einer Datenbank wider, gleichzeitige Anfragen effizient zu verarbeiten. Die Benchmark-Ergebnisse zeigen eindeutig den überlegenen Durchsatz von MyScaleDB im Vergleich zu Qdrant. Darüber hinaus wird der Leistungsunterschied mit zunehmender Anzahl gleichzeitiger Threads deutlich größer, was die außergewöhnliche Skalierbarkeit von MyScaleDB unter hoher Arbeitsbelastung zeigt.
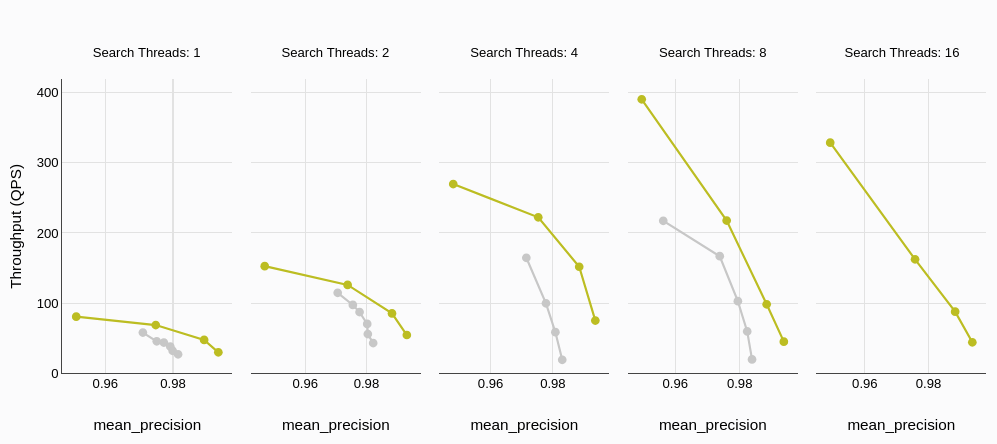
# Durchschnittliche Abfrage-Latenz
Die durchschnittliche Abfrage-Latenz, gemessen in Millisekunden oder Sekunden, stellt die durchschnittliche Zeit dar, die eine Datenbank benötigt, um eine Abfrage zu verarbeiten und Ergebnisse zurückzugeben. Eine niedrigere Latenz bedeutet schnellere Reaktionszeiten, was ein entscheidender Faktor für Echtzeit-Anwendungen und Benutzererfahrung ist.
Die Benchmark-Ergebnisse zeigen konsistent eine deutlich niedrigere durchschnittliche Abfrage-Latenz von MyScaleDB im Vergleich zu Qdrant. Dieser Trend hält bei unterschiedlichen Thread-Zahlen konstant an und zeigt die Fähigkeit von MyScaleDB, auch bei hoher Auslastung eine niedrige Latenz aufrechtzuerhalten.
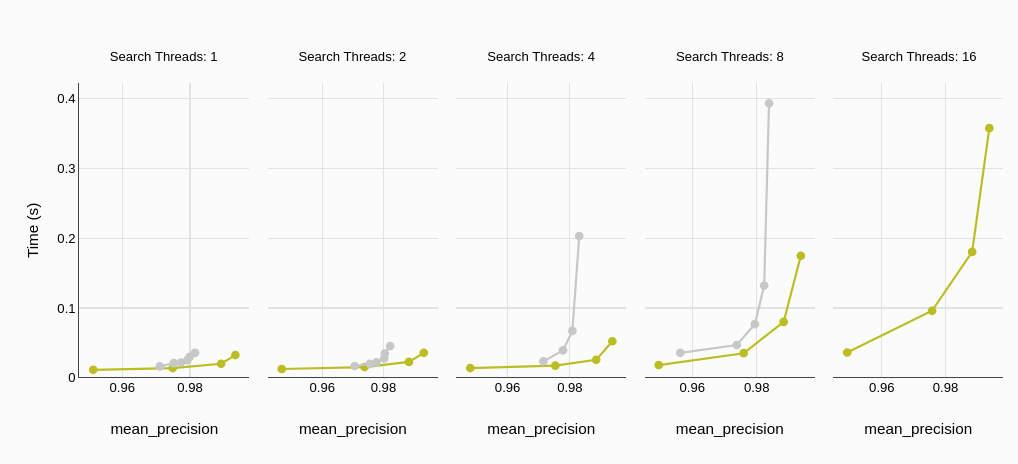
Wir sehen ähnliche Trends auch bei der P95 (95. Perzentil)-Latenz, was die niedrige Latenz von MyScaleDB für praktische Anwendungen weiter unterstreicht.
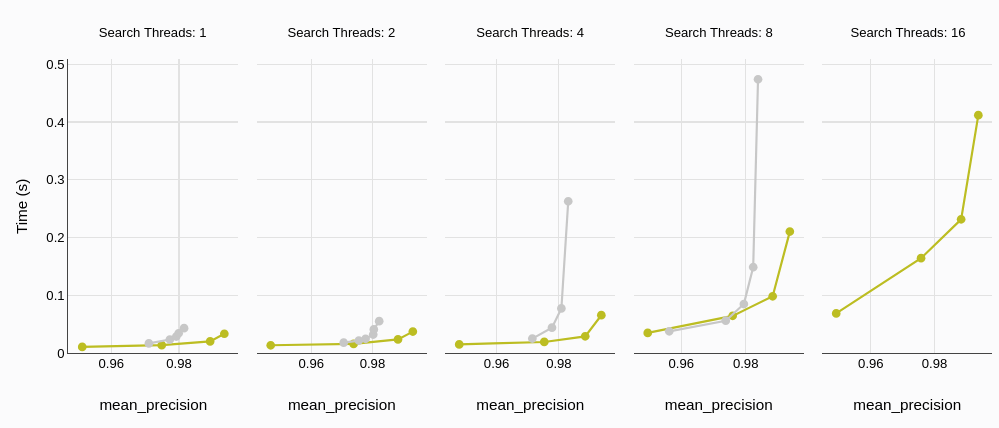
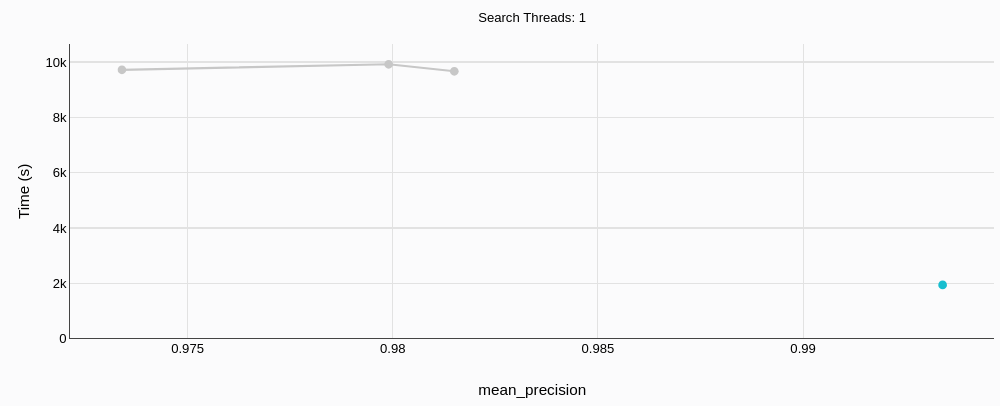
# Build-Zeit
MyScaleDB (grün; dieser kleine Punkt in der rechten unteren Ecke) hat nicht nur eine bessere Präzision, sondern ist auch fast 5x schneller.
# Monatliche Kosten
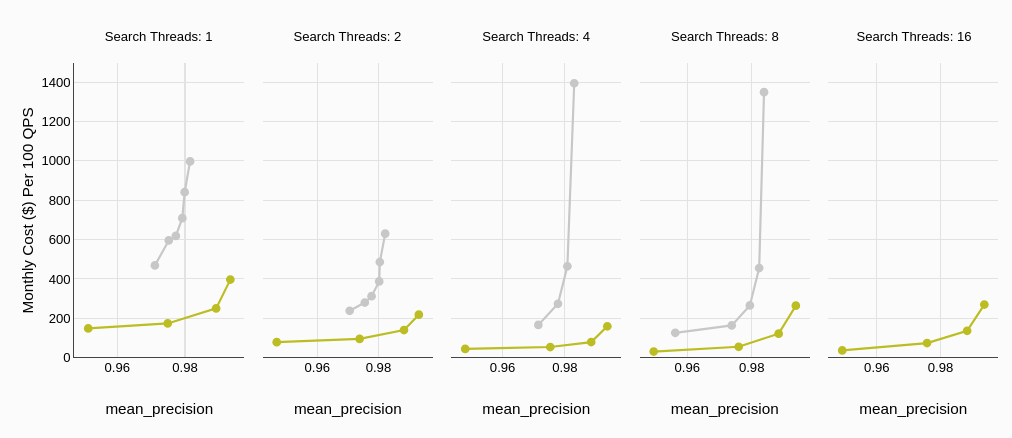
Die Kostenwirksamkeit spielt eine entscheidende Rolle bei der Auswahl der richtigen Datenbanklösung. Wie im Abschnitt zur Preisgestaltung hervorgehoben, bietet MyScaleDB im Allgemeinen eine kostengünstigere Option im Vergleich zu Qdrant, insbesondere wenn man seine großzügige kostenlose Ebene berücksichtigt.
Dieses Diagramm erklärt es weiter in Bezug auf die Suchthreads. Wir können sehen, dass die Kosten von Qdrant (grau) mit zunehmender Anzahl von Suchthreads stark ansteigen. Im Gegensatz dazu behält MyScaleDB ein deutlich niedrigeres Kostenprofil bei und bleibt auch bei höheren Thread-Zahlen relativ stabil.

# Fazit
Sowohl Qdrant als auch MyScaleDB zeichnen sich als prominente Konkurrenten in der sich schnell entwickelnden Landschaft der Vektordatenbanken aus. Qdrant profitiert aufgrund seiner längeren Präsenz auf dem Markt von einer breiteren Akzeptanz und bietet überzeugende Funktionen wie die Unterstützung von dünnen Vektoren und effiziente Quantisierungstechniken.
MyScaleDB hingegen erweist sich als leistungsstarke Alternative und bietet bedeutende Vorteile in wichtigen Bereichen:
- Leistung und Skalierbarkeit: MyScaleDB übertrifft Qdrant in Benchmarks kontinuierlich und zeigt eine überlegene Durchsatzrate, niedrigere Latenz und beeindruckende Skalierbarkeit für anspruchsvolle Workloads.
- Kostenwirksamkeit: MyScaleDB bietet mit seiner großzügigen kostenlosen Ebene und deutlich niedrigeren Kosten für kostenpflichtige Pläne, insbesondere für hohe Parallelitätsszenarien, ein überzeugendes Preis-Leistungs-Verhältnis.
- Vereinheitlichtes Datenmanagement: Die Fähigkeit von MyScaleDB, sowohl Vektordaten als auch verschiedene herkömmliche Datentypen innerhalb einer einzigen Plattform zu verwalten, vereinfacht Datenpipelines und ermöglicht leistungsstarke Cross-Data-Abfragen.
- SQL-basierte Einfachheit: Durch die Nutzung der Vertrautheit und Ausdruckskraft von SQL rationalisiert MyScaleDB die Entwicklung und ermöglicht es Benutzern, mit Vektordaten in einer weit verbreiteten Sprache zu interagieren.
Letztendlich hängt die optimale Wahl von Ihren spezifischen Anforderungen und Prioritäten ab. Wenn eine breite Sprachunterstützung und spezialisierte Funktionen wie die Handhabung von dünnen Vektoren im Vordergrund stehen, könnte Qdrant eine geeignete Option sein. Wenn jedoch Leistung, Skalierbarkeit, Kostenwirksamkeit und vereinheitlichtes Datenmanagement entscheidende Faktoren sind, erweist sich MyScaleDB als klarer Favorit.
Wir ermutigen Sie, Ihre Anforderungen sorgfältig zu bewerten und die Erkenntnisse aus diesem Vergleich zu nutzen, um eine fundierte Entscheidung zu treffen, die Ihren einzigartigen Anforderungen an die Datenverarbeitung und Anwendungen entspricht.



