
Die Vektorsuche sucht in einem Datensatz nach ähnlichen Vektoren oder Datenpunkten basierend auf ihren Vektorrepräsentationen. Jedoch ist die reine Vektorsuche in realen Szenarien selten ausreichend. Vektoren sind in der Regel mit Metadaten versehen, und Benutzer müssen häufig einen oder mehrere Filter auf diese Metadaten anwenden. Dadurch wird die gefilterte Vektor-Suche relevant.
Die gefilterte Vektor-Suche wird für komplexe Abruf-Szenarien immer wichtiger. Sie können einen Filtermechanismus anwenden, um unerwünschte Vektoren jenseits der Top-k/Range der mehrdimensionalen Einbettungen herauszufiltern.
In diesem Blog diskutieren wir zunächst die technischen Herausforderungen bei der Implementierung der gefilterten Vektor-Suche. Anschließend stellen wir eine Lösung vor, indem wir erläutern, wie MyScale die gefilterte Vektor-Suche mithilfe unseres proprietären Algorithmus MSTG optimiert, zusammen mit ClickHouse für schnelle Filterung von strukturierten Daten.
# Technische Herausforderungen bei der Implementierung der gefilterten Vektor-Suche
Mit der zunehmenden Vielfalt der Datentypen in großen Datensätzen in modernen Anwendungen ist die Auswahl des geeigneten Ansatzes für die gefilterte Vektor-Suche und des Vektor-Indexierungsalgorithmus entscheidend, um die Qualität der Suchergebnisse zu verbessern und präzisere Suchergebnisse zu liefern. Nun gehen wir auf jede dieser Herausforderungen ein.
# Vor-Filterung vs. Nach-Filterung
Basierend auf dem Zeitpunkt, zu dem die Filterung im Vektor-Suchprozess erfolgt, kann die gefilterte Suche entweder als Vor- oder Nach-Filterung kategorisiert werden, wie in der folgenden Abbildung dargestellt.
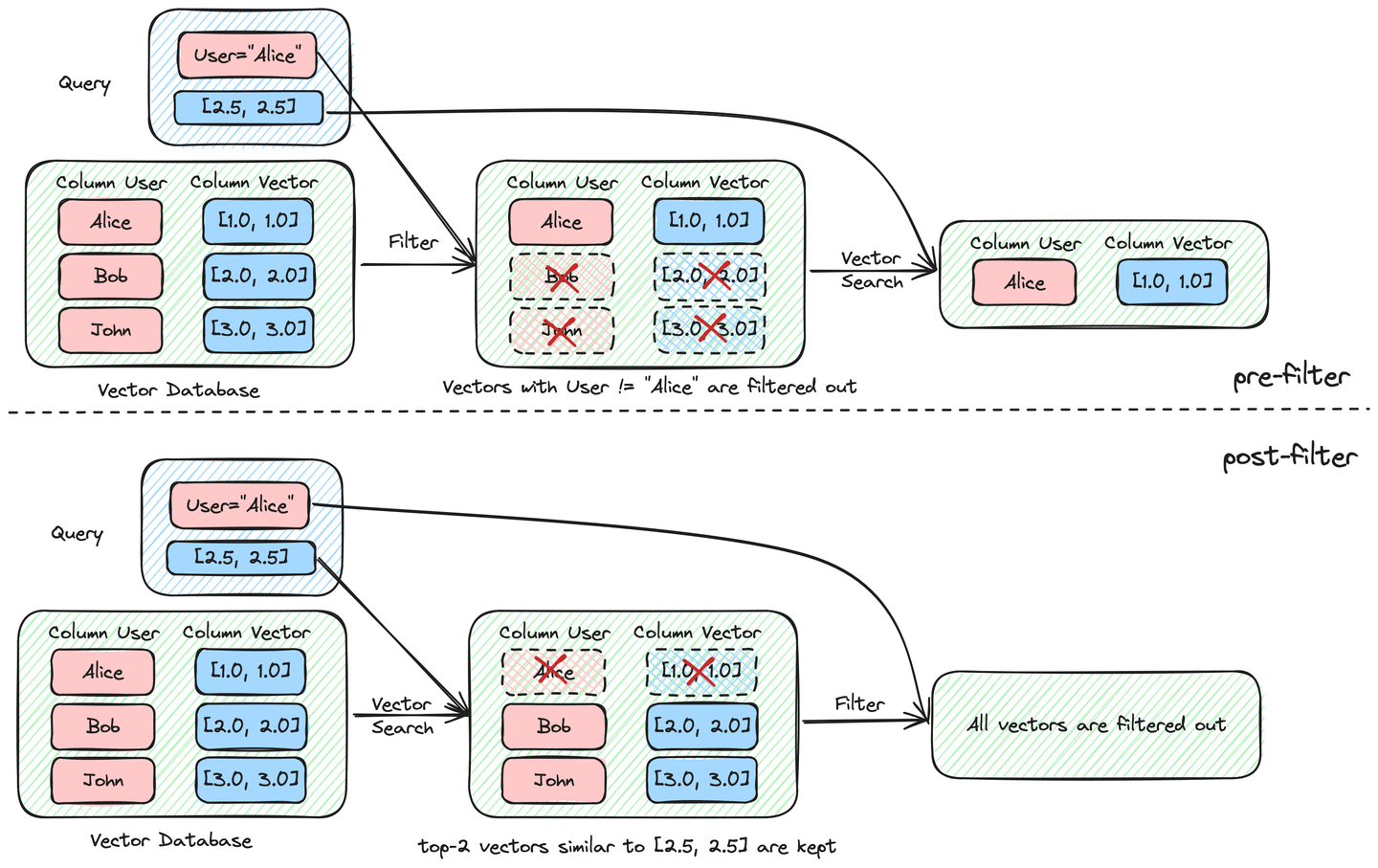 Bei Verwendung der Vor-Filterung erhalten wir die erwartete Ausgabe
Bei Verwendung der Vor-Filterung erhalten wir die erwartete Ausgabe ("Alice", [1.0, 1.0]). Die Nach-Filterung liefert jedoch keine Ergebnisse.
# Vor-Filterung
Die Vor-Filterung der Vektor-Suche ist eine Technik, bei der potenzielle Übereinstimmungen vor der eigentlichen Vektor-Suche in einem Datensatz initial überprüft werden. Das Ziel besteht darin, den Suchraum einzugrenzen und ungeeignete oder unnötige Ergebnisse frühzeitig zu eliminieren, um die Effizienz und Genauigkeit der anschließenden Vektor-Suche zu verbessern. Diese Methode ist besonders vorteilhaft in Szenarien, in denen der Datensatz groß ist und die Rechenressourcen sorgfältig genutzt werden müssen.
Stellen Sie sich ein Szenario vor, in dem Sie eine umfangreiche Datenbank von Bildern haben und Bilder abrufen möchten, die einem bestimmten Suchbild nahe kommen. Anstatt eine detaillierte Vektor-Suche auf der gesamten Bild-Datenbank durchzuführen, können Sie potenzielle Kandidaten anhand einfacher Merkmale wie Farbhistogramme, Seitenverhältnisse oder Low-Level-Deskriptoren vorfiltern. Sie könnten beispielsweise Bilder vorfiltern, die ähnliche Farbverteilungen oder Formen wie das Suchbild aufweisen.
Zusammenfassend ist die Vor-Filterung ein strategischer Ansatz, um die Gesamtleistung von Ähnlichkeitssuchen durch intelligentes Eingrenzen des Suchbereichs zu verbessern.
Hinweis:
Die Vor-Filterung wird immer in der gefilterten Suchimplementierung von MyScale verwendet.
# Nach-Filterung
Im Gegensatz zur Vor-Filterung, die vor der eigentlichen Vektor-Suche erfolgt, handelt es sich bei der Nach-Filterung um eine Technik, bei der die reine Vektor-Suche auf einem Datensatz ausgeführt wird und anschließend nach Erhalt der anfänglichen Ergebnisse zusätzliche Filter- oder Verfeinerungsschritte angewendet werden. Diese Methode hat jedoch bestimmte Einschränkungen und Nachteile, die sich auf die Effizienz und Genauigkeit der Suchergebnisse auswirken können. Diese Ergebnisse können aufgrund des angewendeten Filters auf eine reduzierte Menge von Ergebnissen unvorhersehbar sein. In Fällen, in denen der Filter sehr restriktiv ist und nur einen kleinen Prozentsatz der Datenpunkte im Verhältnis zur Größe des Datensatzes betrifft, besteht die Möglichkeit, dass in der anfänglichen Vektor-Suche keine Übereinstimmungen gefunden werden.
Beliebte Vektor-Datenbanken wie PostgreSQL/pgvector und OpenSearch haben diesen Ansatz übernommen, was zu einer geringen Genauigkeit bei der gefilterten Suche führt, wie in unserem vorherigen Blog (opens new window) gezeigt.
# Warum HNSW bei der gefilterten Suche schlechte Leistung erbringt
Obwohl beliebte Graphalgorithmen wie HNSW für die ungefilterte Vektor-Suche gut geeignet sind, kann ihre Leistung bei gefilterten Vektor-Suchen erheblich abnehmen.
Definieren wir zunächst das Filterverhältnis einer gefilterten Vektor-Suche wie folgt:
Wenn das Filterverhältnis niedrig ist, wird die Filterung sehr restriktiv. Wie in der folgenden Abbildung gezeigt, erzielt der HNSW-Algorithmus in diesem Fall eine schlechte Leistung und benötigt mehrere Sekunden, wenn das Filterverhältnis unter 1% liegt:
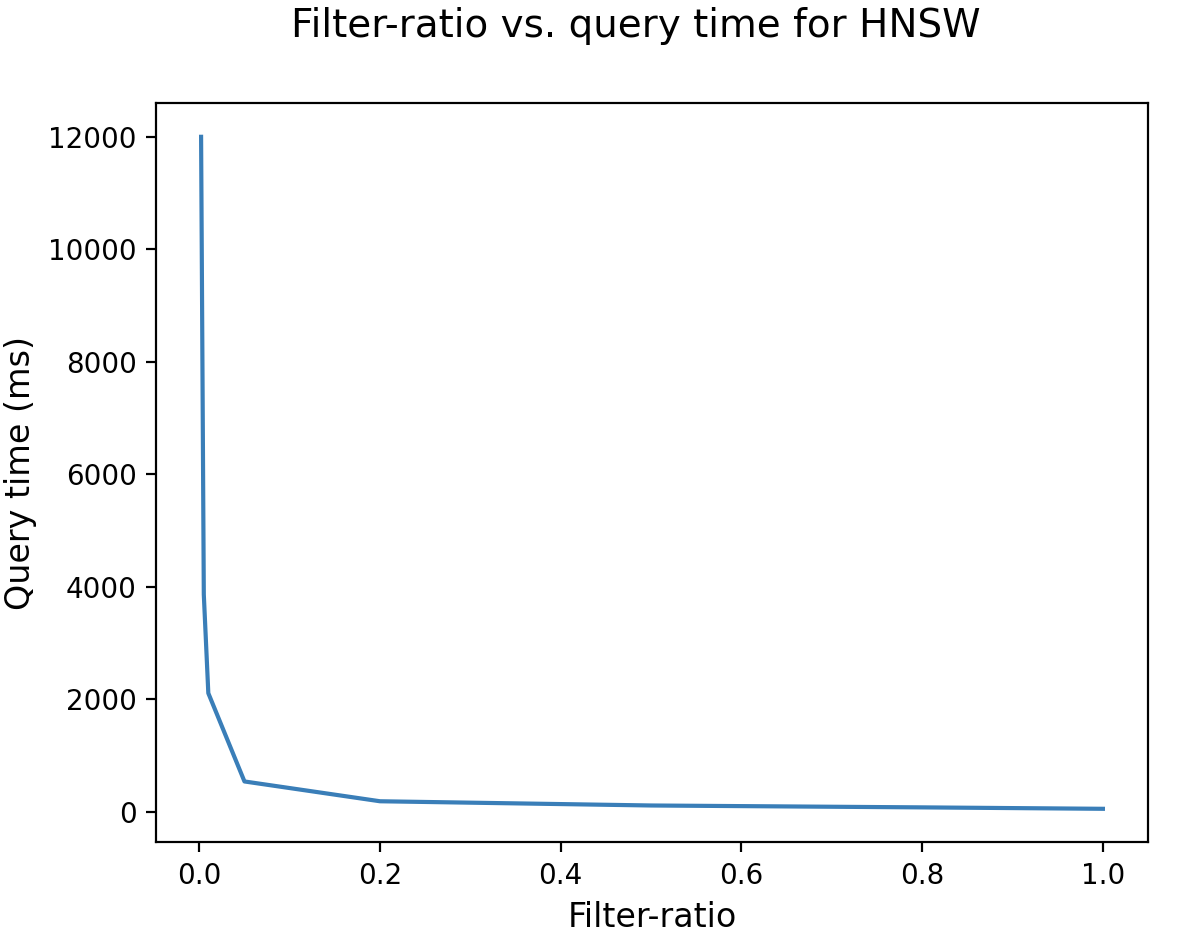
Lassen Sie uns analysieren, warum HNSW bei niedrigem Filterverhältnis schlechte Leistung erbringt, indem wir uns zuerst den Suchprozess ansehen. Während dieser Vektor-Suche ist die Suche auf der Basisebene der zeitaufwändigste Prozess. Wie die Knotensuche in den meisten Graphalgorithmen verwendet HNSW einen Kandidatensatz, um die zu besuchenden Knoten und einen Top-Kandidatensatz zu speichern, um potenzielle Top-Knoten zu speichern. Die Bedingungen für das Beenden der Suche sind:
- Die Anzahl der Top-Kandidaten erfüllt bereits die Anforderungen des Algorithmus, und
- Wenn der maximale Abstand zwischen den Top-Kandidaten und dem Suchvektor kleiner ist als der minimale Abstand zwischen dem Kandidatensatz und dem Suchvektor.
Im Gegensatz zum gewöhnlichen Vektor-Suchprozess überprüft HNSW-mit-gefilterter-Suche, ob der Knoten in der ausgewählten Menge enthalten ist, bevor er ihn zur Liste der potenziellen Top-Kandidaten hinzufügt.
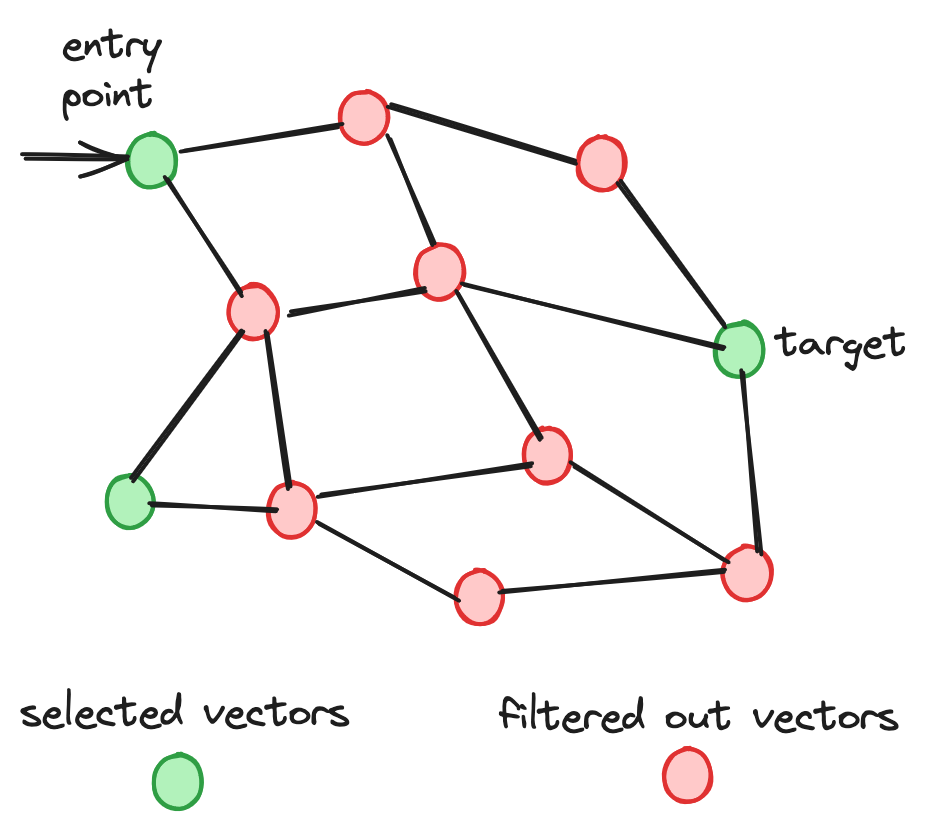
Das niedrige Filterverhältnis stellt eine erhebliche Herausforderung für den Index dar, eine ausreichende Anzahl von Top-Kandidaten zu identifizieren. Diese Einschränkung führt zu umfangreichen Knotentraversierungen. Hinzu kommt die Schwierigkeit, den Graphen effizient zu durchqueren, um die gefilterten nächsten Nachbarn zu finden.
Eine gängige Optimierungstechnik für die gefilterte Vektor-Suche mit HNSW besteht darin, bei einem Filterverhältnis unter einem bestimmten Schwellenwert auf eine Brute-Force-Suche umzuschalten. Wir empfehlen jedoch nicht, diesen Ansatz zu verwenden, da er für groß angelegte Vektoren, wie Datenbanken mit Hunderten von Millionen oder sogar Milliarden von Vektoren, unpraktisch ist. In solchen Fällen erfordert selbst ein Filterverhältnis von 1% das Berechnen der Abstände zwischen dem Suchvektor und Millionen von Vektoren in der Datenbank.
# Fortgeschrittene gefilterte Vektor-Suche in MyScale
Da wir das Problem identifiziert haben, arbeiten wir an einer Lösung. MyScale ist eine SQL-Vektor-Datenbank, die eine schnelle SQL-Ausführungsmaschine (basierend auf ClickHouse) mit dem proprietären Multi-Scale Tree Graph (MSTG)-Algorithmus für schnelle gefilterte Suche kombiniert. In diesem Abschnitt erläutern wir unsere Überlegungen zur Verwendung von ClickHouse als Grundlage für MyScale, das als schnellste Open-Source-Analyse-Datenbank bekannt ist, und erklären unsere Verbesserungen am Vektoralgorithmus für eine effiziente gefilterte Suche. Diese Optimierungen haben zu einer leistungsstarken, flexiblen und robusten gefilterten Vektor-Suche in MyScale beigetragen.
Hinweis:
MyScale ist eine integrierte Vektor-Datenbank mit voller SQL-Unterstützung.
# Nutzung von ClickHouse für die gefilterte Vektor-Suche
Die Entscheidung, ClickHouse als Grundlage für MyScale zu wählen, wurde durch seine nachgewiesene Effizienz bei der Verarbeitung von Daten in großem Maßstab beeinflusst. Die überlegene Geschwindigkeit beim Scannen von Daten in ClickHouse war entscheidend für diese Entscheidung - besonders wichtig für leistungsfähige gefilterte Vektor-Suchen. Die folgenden Designs haben seine Effizienz erheblich verbessert:
- Spaltenorientierter Speicher: Im Gegensatz zu herkömmlichen zeilenorientierten Datenbanken speichert ClickHouse Daten spaltenweise, was das Lesen und Verarbeiten von Daten schneller macht. Dieses Design ist vor allem für Aggregatfunktionen und Filter vorteilhaft, da es nur die erforderlichen Spalten von der Festplatte effizient liest und I/O-Operationen reduziert.
- Vektorisierte Abfrageausführung: ClickHouse verarbeitet Daten in Stapeln, nicht zeilenweise. Dieser vektorisierte Ansatz ermöglicht es, Operationen auf mehreren Datenpunkten gleichzeitig durchzuführen und die Abfrageausführung erheblich zu beschleunigen. Dies ist besonders vorteilhaft für gefilterte Vektor-Suchen in umfangreichen Datensätzen.
- Erweiterte Indexierung: ClickHouse verwendet anspruchsvolle Indexierungstechniken wie Skip-Indizes. Die Datenbank überspringt während einer Abfrage schnell irrelevante Datenblöcke, was zu einer schnelleren Filterung führt, da die Datenbank weniger Zeit mit dem Scannen nicht zusammenhängender Daten verbringt.
- Parallele Verarbeitung: Die Architektur von ClickHouse unterstützt parallele Verarbeitung, sodass die Arbeitslast auf mehrere Kerne und Knoten verteilt werden kann. Diese Parallelisierung ist entscheidend für die effiziente Verarbeitung von umfangreichen Abfragen und Filtern und gewährleistet eine hohe Leistung auch bei großen und komplexen Datensätzen.
Diese Funktionen machen ClickHouse zu einer idealen Plattform für die Implementierung schneller und effizienter gefilterter Vektor-Suchen. Diese Integration bietet das Beste aus beiden Welten: die leistungsstarken analytischen Fähigkeiten von ClickHouse und die nuancierten Funktionen einer Vektor-Datenbank, die für die Verarbeitung komplexer, metadatenreicher Vektordaten unerlässlich sind.
# Multi-Scale Tree Graph Algorithmus
Multi-Scale Tree Graph (MSTG) ist ein neuer Vektor-Index, der von MyScale entwickelt wurde. Im Gegensatz zu beliebten Algorithmen wie HNSW, die ausschließlich auf hierarchischen Graphen basieren, und IVF (Inverted File Index), das als zweistufiger Baum betrachtet werden kann, kombiniert MSTG die besten Teile beider hierarchischer Graphen und Baumstrukturen in seinem Design.
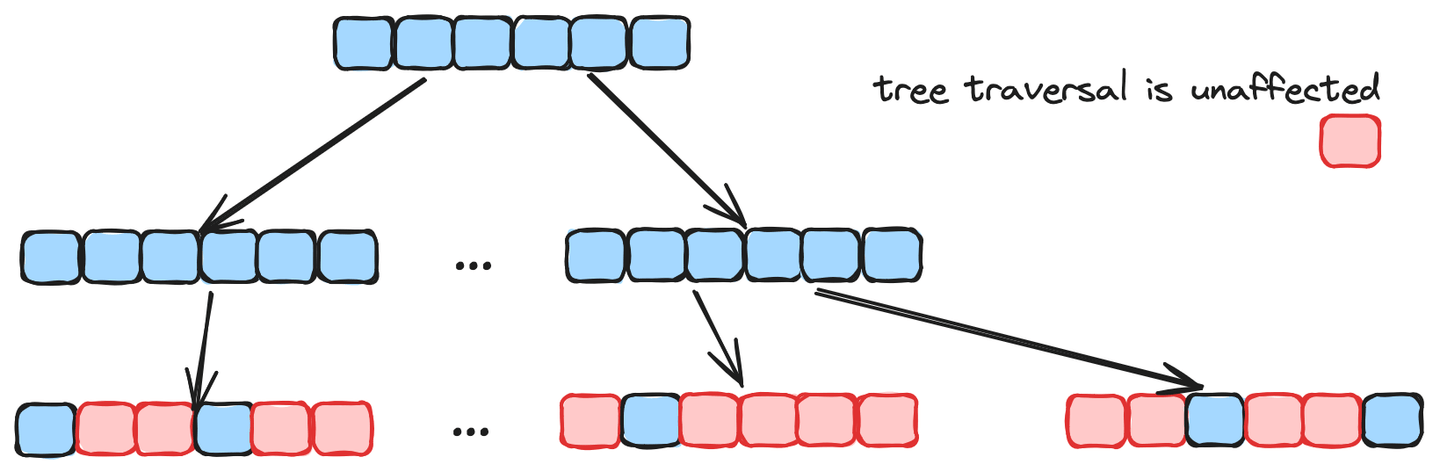
Ein Graphalgorithmus zeichnet sich durch eine schnelle Konvergenz aus und ist in der Regel schneller bei ungefilterten Suchen. Bei gefilterten Suchen ist seine Effizienz jedoch stark eingeschränkt. Auf der anderen Seite sind Baumalgorithmen langsamer und haben eine geringere Genauigkeit bei ungefilterten Suchen, aber die Baumtraversierung wird von gefilterten Elementen nicht beeinflusst und behält die Leistungsfähigkeit bei gefilterten Suchen bei, wie in der folgenden Abbildung dargestellt. Durch die Kombination dieser beiden Algorithmen in MSTG wird eine hohe Leistung und Genauigkeit für beide Fälle erzielt und eine schnelle Indexerstellung ermöglicht. Darüber hinaus hat MSTG sowohl die Vor-Filterung als auch die Berechnung der Vektorentfernung mit SIMD (Single Instruction, Multiple Data) beschleunigt und die Berechnungsdurchsatz auf modernen CPUs erheblich verbessert.

# Fazit
Die Vektorsuche sucht ähnliche Datenpunkte basierend auf Vektorrepräsentationen, aber in realen Szenarien ist mehr als eine reine Vektorsuche erforderlich. Vektoren mit Metadaten erfordern oft eine gefilterte Vektor-Suche, die für komplexe Abruf-Szenarien entscheidend ist.
Der innovative Ansatz von MyScale für die gefilterte Vektor-Suche, der die Stärken von ClickHouse und des proprietären MSTG-Algorithmus kombiniert, bietet eine leistungsstarke Lösung für komplexe Vektor-Suchen im großen Maßstab. Diese Integration bietet sowohl Geschwindigkeit als auch Präzision und macht MyScale zu einem führenden Unternehmen in der Vektor-Datenbank-Technologie.
Sie finden Benchmark-Berichte zwischen MyScale und anderen Wettbewerbern in folgenden Inhalten:



