
Seit der Veröffentlichung von Large Language Models (LLMs) und fortschrittlichen Chat-Modellen werden verschiedene Techniken verwendet, um die gewünschten Ausgaben aus diesen KI-Systemen zu extrahieren. Einige dieser Methoden beinhalten die Änderung des Verhaltens des Modells, um es besser mit unseren Erwartungen in Einklang zu bringen, während andere sich darauf konzentrieren, wie wir die LLMs abfragen, um präzisere und relevantere Informationen zu extrahieren.
Techniken wie Retrieval Augmented Generation (RAG) (opens new window), Prompting (opens new window) und Fine-Tuning (opens new window) sind die am häufigsten verwendeten. Auf MyScale haben wir bereits Techniken wie RAG (opens new window) und Fine-Tuning im Detail besprochen. Beim Fine-Tuning haben wir zwei Techniken besprochen, Fine-Tuning mit OpenAI (opens new window) und Fine-Tuning mit Hugging Face (opens new window).
Hinweis:
Wenn Sie unsere RAG- und Fine-Tuning-Blogs noch nicht gelesen haben, empfehlen wir Ihnen dringend, diese zuerst zu lesen, bevor Sie hier beginnen.
Die heutige Diskussion ist etwas anders. Wir gehen von der Exploration zur Vergleichung über. Wir werden uns die Vor- und Nachteile jeder Technik ansehen. Dies ist wichtig, um zu verstehen, wann und wie man diese Techniken effektiv einsetzen kann. Beginnen wir also unseren Vergleich und sehen, was jede Methode einzigartig macht.
# Prompt Engineering
Prompting ist der einfachste Weg, mit einem Large Language Model zu interagieren. Es ist wie Anweisungen geben. Wenn Sie einen Prompt (opens new window) verwenden, sagen Sie dem Modell, welche Art von Informationen Sie erhalten möchten. Dies wird auch als Prompt Engineering bezeichnet. Es ist ein bisschen wie das Erlernen, wie man die richtigen Fragen stellt, um die besten Antworten zu erhalten. Aber es gibt Grenzen, wie viel Sie daraus bekommen können. Das liegt daran, dass das Modell nur das zurückgeben kann, was es bereits aus seinem Training (opens new window) weiß.
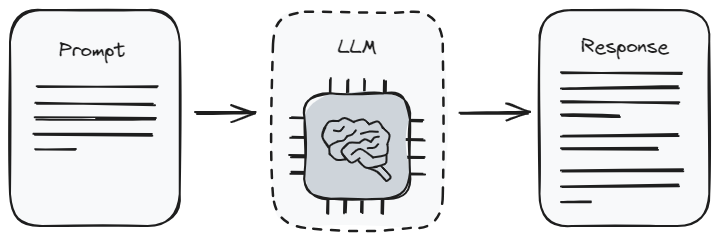
Das Besondere am Prompt Engineering ist, dass es ziemlich einfach ist. Sie müssen kein Technikexperte sein, um es zu tun, was für die meisten Menschen großartig ist. Aber da es stark von dem ursprünglichen Lernen des Modells abhängt, gibt es Ihnen möglicherweise nicht immer die neuesten oder spezifischsten Informationen, die Sie benötigen. Es ist am besten, wenn Sie mit allgemeinen Themen arbeiten oder wenn Sie nur eine schnelle Antwort benötigen, ohne zu viele Details zu berücksichtigen.
# Vorteile:
- Benutzerfreundlichkeit: Prompting ist benutzerfreundlich und erfordert keine fortgeschrittenen technischen Fähigkeiten, was es für ein breites Publikum zugänglich macht.
- Kosteneffizienz: Da es vortrainierte Modelle (opens new window) verwendet, sind die Rechenkosten im Vergleich zum Fine-Tuning minimal.
- Flexibilität: Prompts können schnell angepasst werden, um verschiedene Ausgaben zu erkunden, ohne das Modell neu trainieren zu müssen.
# Nachteile:
- Inkonsistenz: Die Qualität und Relevanz der Antworten des Modells können je nach Formulierung des Prompts erheblich variieren.
- Begrenzte Anpassungsmöglichkeiten: Die Möglichkeit, die Antworten des Modells anzupassen, ist auf die Kreativität und Fähigkeit zur Formulierung effektiver Prompts beschränkt.
- Abhängigkeit vom Wissen des Modells: Die Ausgaben sind auf das beschränkt, was das Modell während seines anfänglichen Trainings gelernt hat, was es weniger effektiv für hochspezialisierte oder aktuelle Informationen macht.
# Fine-Tuning
Fine-Tuning bedeutet, dass Sie das Sprachmodell nehmen und ihm etwas Neues oder Besonderes beibringen. Denken Sie daran, dass es ist, als würden Sie eine App auf Ihrem Telefon aktualisieren, um bessere Funktionen zu erhalten. Aber in diesem Fall benötigt die App (das Modell) viele neue Informationen und Zeit, um alles richtig zu lernen. Es ist ein bisschen wie wieder zur Schule gehen für das Modell.
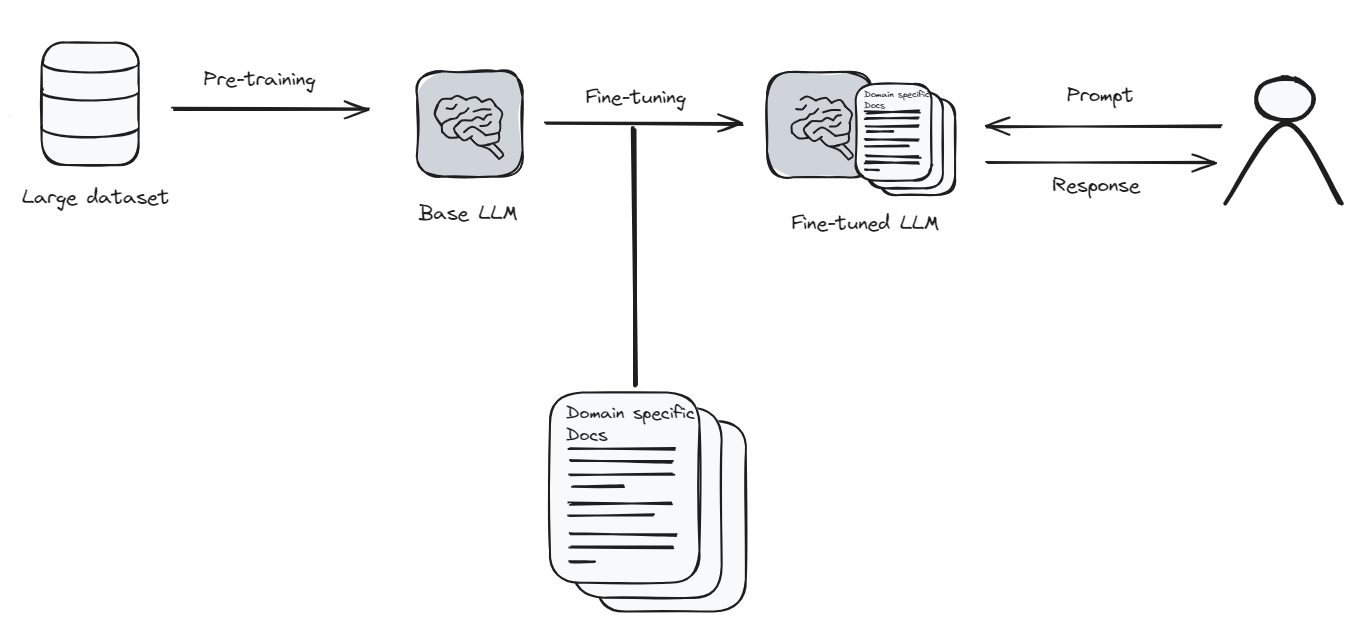
Da Fine-Tuning viel Rechenleistung und Zeit benötigt, kann es teuer sein. Aber wenn Sie möchten, dass Ihr Sprachmodell ein bestimmtes Thema sehr gut versteht, dann lohnt sich das Fine-Tuning. Es ist wie das Unterrichten des Modells, ein Experte in dem zu werden, woran Sie interessiert sind. Nach dem Fine-Tuning kann das Modell Ihnen Antworten geben, die genauer und näher an dem liegen, wonach Sie suchen.
# Vorteile:
- Anpassungsmöglichkeiten: Ermöglicht umfangreiche Anpassungsmöglichkeiten, sodass das Modell Antworten generieren kann, die auf spezifische Domänen oder Stile zugeschnitten sind.
- Verbesserte Genauigkeit: Durch das Training mit einem spezialisierten Datensatz kann das Modell genauere und relevantere Antworten liefern.
- Anpassungsfähigkeit: Feinabgestimmte Modelle können besser mit Nischenthemen oder aktuellen Informationen umgehen, die im ursprünglichen Training nicht abgedeckt wurden.
# Nachteile:
- Kosten: Fine-Tuning erfordert erhebliche Rechenressourcen, was es teurer macht als Prompting.
- Technische Fähigkeiten: Diese Methode erfordert ein tieferes Verständnis von Maschinellem Lernen (opens new window) und Sprachmodellarchitekturen (opens new window).
- Datenanforderungen: Für ein effektives Fine-Tuning ist ein umfangreicher und gut kuratierter Datensatz erforderlich, was eine Herausforderung sein kann.
Verwandte Artikel: Wie man ein Empfehlungssystem aufbaut (opens new window)
# Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation, oder RAG, kombiniert die üblichen Sprachmodellfunktionen mit etwas Ähnlichem wie einer Wissensbasis (opens new window). Wenn das Modell eine Frage beantworten muss, sucht es zuerst relevante Informationen in einer Wissensbasis und beantwortet dann die Frage auf der Grundlage dieser Informationen. Es ist, als würde das Modell eine schnelle Überprüfung einer Bibliothek von Informationen durchführen, um sicherzustellen, dass es Ihnen die beste Antwort gibt.
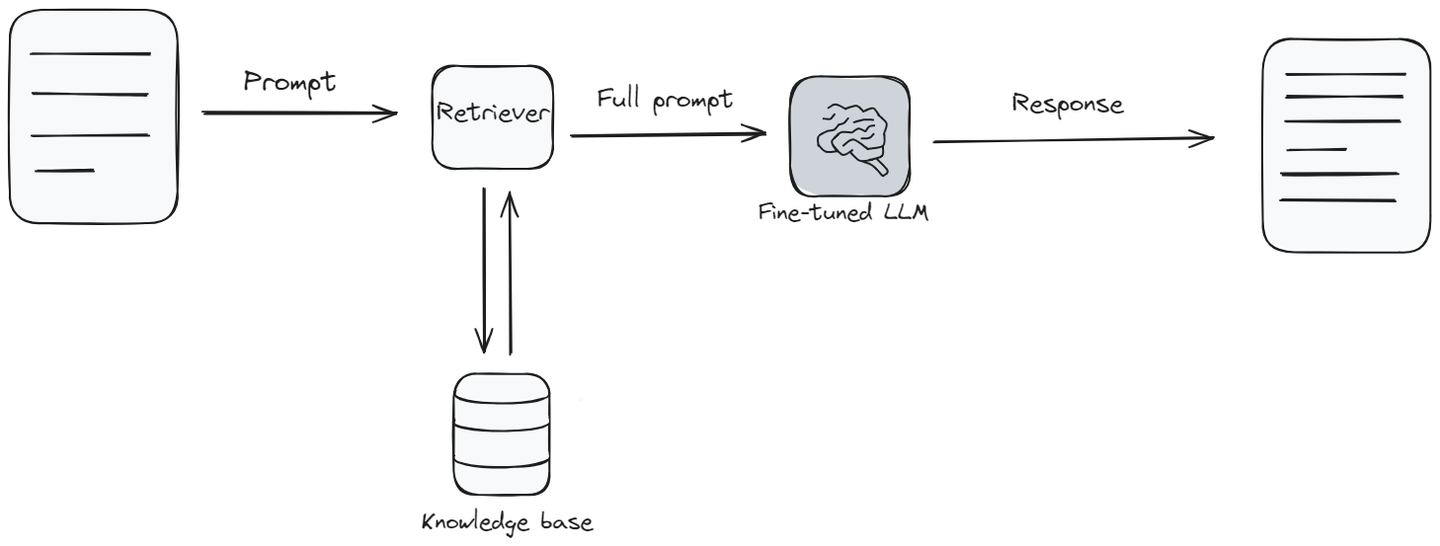
RAG ist besonders nützlich in Situationen, in denen Sie die neuesten Informationen oder Antworten benötigen, die einen breiteren Themenbereich abdecken als das Modell ursprünglich gelernt hat. Es liegt sozusagen in der Mitte, wenn es darum geht, wie schwer es einzurichten ist und wie viel es kostet. Es ist großartig, weil es dem Sprachmodell Antworten liefert, die frisch sind und mehr Details enthalten. Aber wie beim Fine-Tuning benötigt es zusätzliche Werkzeuge und Informationen, um gut zu funktionieren.
Die Kosten, Geschwindigkeit und Qualität der Antworten Ihres RAG-Systems hängen stark von der Vektordatenbank ab, wodurch sie zu einem sehr wichtigen Bestandteil des RAG-Systems wird. MyScale (opens new window) ist eine solche Vektordatenbank, die nicht nur fast die Hälfte im Vergleich zu anderen Vektordatenbanken kostet, sondern auch eine 3-fach bessere Leistung bietet. Sie können das Benchmark (opens new window) hier einsehen. Am wichtigsten ist, dass Sie keine externen Tools oder Sprachen lernen müssen, um auf MyScale zuzugreifen. Sie können es über einfache SQL-Syntax zugreifen, was es zu einer perfekten Wahl für Entwickler macht.
# Vorteile:
- Dynamische Informationen: Durch die Nutzung externer Datenquellen kann RAG aktuelle und hoch relevante Informationen liefern.
- Ausgewogenheit: Bietet einen Mittelweg zwischen der Benutzerfreundlichkeit von Prompting und der Anpassungsfähigkeit von Fine-Tuning.
- Kontextuelle Relevanz: Verbessert die Antworten des Modells durch zusätzlichen Kontext und führt zu informierteren und nuancierteren Ausgaben.
# Nachteile:
- Komplexität: Die Implementierung von RAG kann komplex sein und erfordert eine Integration zwischen dem Sprachmodell und dem Abrufsystem.
- Ressourcenintensiv: Obwohl weniger ressourcenintensiv als das vollständige Fine-Tuning, erfordert RAG dennoch erhebliche Rechenleistung.
- Abhängigkeit von Daten: Die Qualität der Ausgabe hängt stark von der Relevanz und Genauigkeit der abgerufenen Informationen ab.
# Prompting vs. Fine-Tuning vs. RAG
Lassen Sie uns nun einen Seit-an-Seit-Vergleich von Prompting, Fine-Tuning und Retrieval Augmented Generation (RAG) durchführen. Diese Tabelle soll Ihnen helfen, die Unterschiede zu erkennen und zu entscheiden, welche Methode für Ihre Bedürfnisse am besten geeignet sein könnte.
| Eigenschaft | Prompting | Fine-Tuning | Retrieval Augmented Generation (RAG) |
|---|---|---|---|
| Benötigtes Fähigkeitsniveau | Niedrig: Erfordert ein grundlegendes Verständnis dafür, wie man Prompts erstellt. | Moderat bis Hoch: Erfordert Kenntnisse über maschinelles Lernen und Modellarchitekturen. | Moderat: Erfordert Verständnis sowohl von maschinellem Lernen als auch von Information Retrieval-Systemen. |
| Preis und Ressourcen | Niedrig: Verwendet vorhandene Modelle, minimale Rechenkosten. | Hoch: Für das Training sind erhebliche Rechenressourcen erforderlich. | Mittel: Erfordert Ressourcen für Abrufsysteme und Modellinteraktion, aber weniger als Fine-Tuning. |
| Anpassungsmöglichkeiten | Niedrig: Begrenzt durch das vortrainierte Wissen des Modells und die Fähigkeit des Benutzers, effektive Prompts zu erstellen. | Hoch: Ermöglicht umfangreiche Anpassungsmöglichkeiten an spezifische Domänen oder Stile. | Mittel: Anpassbar durch externe Datenquellen, abhängig von deren Qualität und Relevanz. |
| Datenanforderungen | Keine: Verwendet vortrainierte Modelle ohne zusätzliche Daten. | Hoch: Erfordert einen großen, relevanten Datensatz für effektives Fine-Tuning. | Mittel: Erfordert Zugriff auf relevante externe Datenbanken oder Informationsquellen. |
| Aktualisierungshäufigkeit | Niedrig: Abhängig vom erneuten Training des zugrunde liegenden Modells. | Variabel: Abhängig davon, wann das Modell mit neuen Daten erneut trainiert wird. | Hoch: Kann die aktuellsten Informationen einbeziehen. |
| Qualität | Variabel: Hängt stark von der Fähigkeit zur Formulierung von Prompts ab. | Hoch: Auf spezifische Datensätze zugeschnitten, was zu relevanteren und genaueren Antworten führt. | Hoch: Verbessert Antworten mit kontextuell relevanten externen Informationen. |
| Anwendungsfälle | Allgemeine Anfragen, breite Themen, Bildungszwecke. | Spezialisierte Anwendungen, branchenspezifische Anforderungen, individuelle Aufgaben. | Situationen, die aktuelle Informationen und komplexe Abfragen mit Kontext erfordern. |
| Implementierungsaufwand | Hoch: Einfach mit vorhandenen Tools und Schnittstellen zu implementieren. | Niedrig: Erfordert eine gründliche Einrichtung und Schulungsprozesse. | Mittel: Umfasst die Integration von Sprachmodellen mit Abrufsystemen. |
Die Tabelle gibt einen Überblick über die wichtigsten Punkte von Prompting, Fine-Tuning und RAG. Sie sollte Ihnen helfen, zu verstehen, welche Methode in verschiedenen Situationen am besten funktionieren könnte. Wir hoffen, dass dieser Vergleich Ihnen bei der Auswahl des richtigen Werkzeugs für Ihre nächste Aufgabe hilft.
Verwandte Artikel: Wie funktioniert RAG (opens new window)

# RAG - die beste Wahl zur Verbesserung Ihrer KI-Anwendung
RAG ist ein einzigartiger Ansatz, der die Leistungsfähigkeit traditioneller Sprachmodelle mit der Präzision externer Wissensbasen kombiniert. Diese Methode zeichnet sich aus mehreren Gründen aus und ist in bestimmten Kontexten besonders vorteilhaft gegenüber reinem Prompting oder Fine-Tuning.
Erstens stellt RAG sicher, dass die bereitgestellten Informationen sowohl aktuell als auch relevant sind, indem es externe Daten in Echtzeit abruft. Dies ist entscheidend für Anwendungen, bei denen aktuelle Informationen wichtig sind, wie z.B. bei Nachrichtenabfragen oder sich schnell entwickelnden Bereichen.
Zweitens bietet RAG einen ausgewogenen Ansatz in Bezug auf Anpassungsmöglichkeiten und Ressourcenanforderungen. Im Gegensatz zum vollständigen Fine-Tuning, das umfangreiche Rechenleistung erfordert, ermöglicht RAG flexiblere und ressourceneffizientere Operationen, was es einem breiteren Spektrum von Benutzern und Entwicklern zugänglich macht.
Schließlich überbrückt die hybride Natur von RAG die Kluft zwischen den breiten generativen Fähigkeiten von LLMs und den spezifischen, detaillierten Informationen, die in Wissensbasen verfügbar sind. Dies führt zu Ausgaben, die nicht nur relevant und detailliert, sondern auch kontextuell angereichert sind.
Eine optimierte, skalierbare und kostengünstige Vektordatenbanklösung kann die Leistung und Funktionalität Ihrer RAG-Anwendungen erheblich verbessern. Deshalb benötigen Sie MyScale (opens new window), eine SQL-basierte Vektordatenbank, die nahtlose Integrationen mit wichtigen KI-Frameworks und Sprachmodellplattformen wie OpenAI, Langchain, Langchain JS/TS und LlamaIndex bietet. Mit MyScale wird RAG schneller und genauer (opens new window), was für Benutzer, die die besten Ergebnisse suchen, großartig ist.
# Fazit
Zusammenfassend lässt sich sagen, dass die Wahl zwischen Prompting Engineering, Fine-Tuning und Retrieval Augmented Generation (RAG) von den spezifischen Anforderungen Ihres Projekts, den verfügbaren Ressourcen und den gewünschten Ergebnissen abhängt. Jede Methode hat ihre einzigartigen Stärken und Einschränkungen. Prompting ist zugänglich und kostengünstig, bietet jedoch weniger Anpassungsmöglichkeiten. Fine-Tuning ermöglicht detaillierte Anpassungen zu höheren Kosten und Komplexität. RAG bietet einen Kompromiss und liefert aktuelle und domänenspezifische Informationen bei moderater Komplexität.
Wenn Sie mehr mit uns diskutieren möchten, sind Sie herzlich eingeladen, unserem MyScale Discord (opens new window) beizutreten, um Ihre Gedanken und Feedbacks zu teilen.



