
In letzter Zeit gibt es viel Aufregung um Large Language Models (LLMs) (opens new window) und ihre vielfältigen Anwendungsmöglichkeiten, von Chatbots (opens new window) bis zur Inhaltsgenerierung. Trotz ihrer zahlreichen Anwendungen stehen LLMs vor erheblichen Herausforderungen bei der Bereitstellung in der realen Welt, insbesondere wenn es darum geht, effizient auf verschiedenen Hardwaregeräten zu laufen. Diese Modelle sind rechenintensiv und erfordern erheblichen Speicherplatz, was es schwierig macht, sie auf Geräten mit begrenzten Verarbeitungsmöglichkeiten wie Smartphones und Tablets auszuführen. Diese Einschränkung kann die weitreichende Nutzung von LLMs behindern.
Um diese Herausforderungen zu bewältigen, haben Forscher die Quantisierung als eine praktikable Lösung eingeführt. Die Quantisierung reduziert den Speicherbedarf und die Größe eines Modells, sodass es auf verschiedenen Geräten ohne Leistungseinbußen ausgeführt werden kann, indem hochpräzise Parameter in niedrigere Präzisionsformate umgewandelt werden.
In diesem Artikel werden wir uns mit den Grundlagen von LLMs, ihrer transformierenden Wirkung auf NLP-Aufgaben und dem dringenden Bedarf an Optimierung dieser Modelle für verschiedene Hardwareplattformen befassen. Wir werden auch die Herausforderungen der Optimierung ansprechen und die Quantisierung als eine leistungsstarke Methode zur Bereitstellung von LLMs auf verschiedenen Geräten hervorheben.
# Funktionsweise von LLMs und die Notwendigkeit der Quantisierung
LLMs funktionieren, indem sie auf umfangreichen Datensätzen trainiert werden, die Bücher, Artikel und Webinhalte umfassen. Sie lernen, menschliche Sprache zu verstehen und zu generieren, indem sie Millionen oder sogar Milliarden von Parametern anpassen, die im Wesentlichen Gewichte sind, die das Modell während des Trainings feinabstimmt, um Vorhersagefehler zu minimieren. Diese Gewichte belegen erheblichen Speicherplatz, was für Geräte mit begrenzten Rechenressourcen eine große Herausforderung darstellen kann.
Ein Modell mit 5 Milliarden Parametern benötigt beispielsweise etwa 10 GB Speicher, wenn es eine 16-Bit-Präzision verwendet. Dies macht es für Geräte mit begrenzten Rechenmöglichkeiten praktisch unbrauchbar. Hier kommt die Quantisierung ins Spiel. Durch die Reduzierung der Präzision der Modellparameter verringert die Quantisierung den Speicherbedarf und die Rechenlast, ohne die Leistung signifikant zu beeinträchtigen. Dieser Prozess beinhaltet die Umwandlung von hochpräzisen Gewichten und Aktivierungen (z. B. 16-Bit-Gleitkommazahlen oder 32-Bit-Gleitkommazahlen) in niedrigere Präzision (z. B. 8-Bit-Ganzzahlen).
# Überblick über die Quantisierung:
Quantisierung ist entscheidend für die effiziente Bereitstellung von LLMs auf verschiedenen Hardwareplattformen. Sie reduziert die Modellgröße und die Rechenanforderungen, indem hochpräzise Gewichte und Aktivierungen (z. B. 32-Bit-Gleitkommazahlen) in niedrigere Präzision (z. B. 8-Bit-Ganzzahlen) umgewandelt werden. Diese Reduzierung der Präzision führt zu kleineren Modellgrößen, schnelleren Berechnungen und geringerem Speicherbedarf, sodass Modelle auf Edge-Geräten wie Smartphones und IoT-Geräten ohne signifikanten Genauigkeitsverlust ausgeführt werden können.
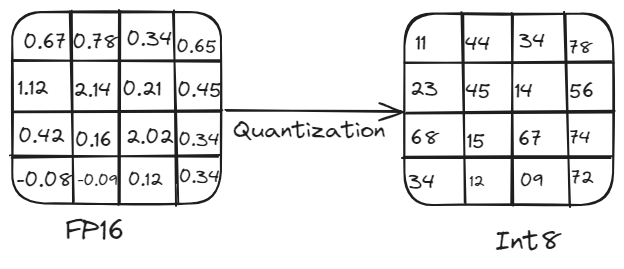
Quantisierungsprozess
# Wie wird die Quantisierung durchgeführt?
Die Quantisierung kann mit zwei Hauptmethoden durchgeführt werden: symmetrische und asymmetrische Quantisierung.
# Symmetrische Quantisierung
Dieser Ansatz skaliert sowohl positive als auch negative Werte symmetrisch um Null. Der gleiche Skalierungsfaktor wird für alle Werte verwendet, was Berechnungen vereinfacht, aber manchmal zu einer weniger effizienten Darstellung für Werte mit einer schiefen Verteilung führt.
Stellen Sie sich vor, wir haben einen Bereich von Gleitkommazahlen von -6 bis 5. Um diese Werte zu quantisieren, finden wir den maximalen absoluten Wert, der 6 ist. Wir verwenden diesen Wert, um den gesamten Bereich zu skalieren. In einer 8-Bit-Darstellung reicht der Bereich von -128 bis 127. Daher ordnen wir -6 -128 zu, 0 0 und 5 etwa 106. Auf diese Weise ist die Skalierung um Null symmetrisch.
Q=round(SX)
Hier ist S der Skalierungsfaktor (z. B. 6/128).
# Asymmetrische Quantisierung
Diese Methode verwendet unterschiedliche Skalierungsfaktoren für verschiedene Wertebereiche. Sie bietet mehr Flexibilität und führt oft zu einer besseren Modellleistung, kann jedoch komplexer in der Implementierung sein.
Angenommen, wir haben einen Bereich von Gleitkommazahlen von 0 bis 10. In einer 8-Bit-Darstellung kann dieser Bereich direkt auf 0 bis 255 abgebildet werden, wobei der gesamte Bereich der quantisierten Werte genutzt wird. Hier wird der Nullpunkt verwendet, um die Bereiche ordnungsgemäß auszurichten und sicherzustellen, dass der gesamte Bereich effizient genutzt wird.
X=Q×S+Z
Hier ist S der Skalierungsfaktor und Z die Nullpunktanpassung.
# Quantisierungsmodi
Es gibt zwei Hauptmodi der Quantisierung: Quantisierung nach dem Training und Quantisierung während des Trainings.
# Quantisierung nach dem Training (PTQ)
Diese Methode beinhaltet die Umwandlung eines Modells, das bereits mit voller Präzision trainiert wurde (normalerweise in 32-Bit-Gleitkommazahlen), in ein niedrigeres Präzisionsformat (wie 8-Bit-Ganzzahlen), nachdem das Training abgeschlossen ist. Der Prozess ist einfach und schnell, da keine erneute Schulung des Modells erforderlich ist. Da das Modell jedoch ursprünglich nicht darauf trainiert wurde, mit dieser niedrigeren Präzision zu arbeiten, besteht die Möglichkeit, dass seine Genauigkeit geringfügig abnimmt. Dies liegt daran, dass die Gewichte und Aktivierungen des Modells approximiert werden, um in die kleinere Bit-Repräsentation zu passen, was zu einigen Quantisierungsfehlern führen kann.
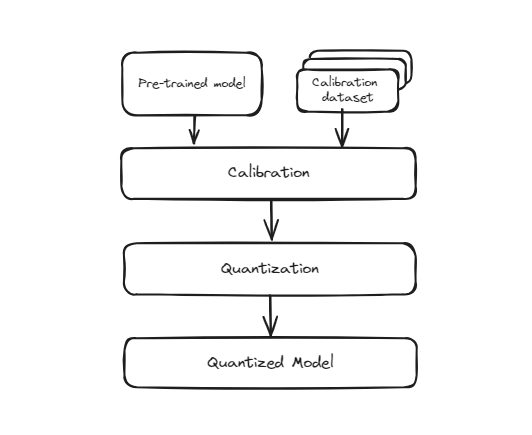
Quantisierung vor dem Training
Während dieser Konvertierung wird jedoch die Präzision der Gewichte reduziert, was zu einem leichten Rückgang der Leistung des Modells bei der genauen Erkennung von Ziffern führen kann. Dies ist insbesondere in Szenarien nützlich, in denen die Modellgröße und die Inferenzgeschwindigkeit entscheidend sind, wie z. B. bei mobilen Anwendungen, eingebetteten Systemen und Edge Computing. Trotz des potenziell geringfügigen Genauigkeitsverlusts sind die Kompromisse oft für die Vorteile von Effizienz und Skalierbarkeit lohnenswert.
# Quantisierung während des Trainings (QAT)
Diese Technik integriert die Quantisierung direkt in den Trainingsprozess des neuronalen Netzwerks. Anstatt das Modell zuerst zu trainieren und dann in eine niedrigere Präzision umzuwandeln, trainiert QAT das Modell unter Berücksichtigung der niedrigeren Präzision von Anfang an. Dies bedeutet, dass während des Trainings die Gewichte und Aktivierungen des Modells "falsch quantisiert" werden, um die Auswirkungen der niedrigeren Präzision zu simulieren. Dadurch lernt das Modell, wie es effektiv innerhalb der Einschränkungen quantisierter Werte arbeiten kann, was zu einer besseren Leistung führt, wenn es tatsächlich in eine niedrigere Präzision umgewandelt wird. QAT erfordert mehr Rechenressourcen und Zeit, da das Modell während des Trainings zusätzliche Schritte durchläuft, führt jedoch in der Regel zu einer höheren Genauigkeit im Vergleich zur Quantisierung nach dem Training (PTQ).
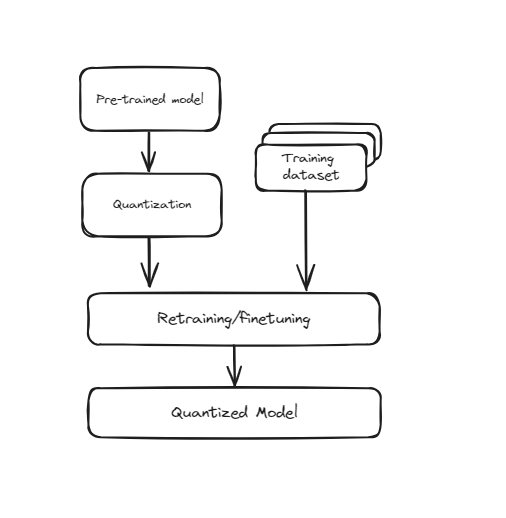
Training Aware Quantisierung
Es ist besonders nützlich für Anwendungen, bei denen eine hohe Genauigkeit entscheidend ist, wie z. B. bei der Bilderkennung, der natürlichen Sprachverarbeitung und anderen KI-Aufgaben. Trotz der längeren Trainingszeit und des höheren Ressourcenbedarfs macht die verbesserte Leistung und Genauigkeit bei niedrigerer Präzision QAT zu einer wertvollen Technik für die Bereitstellung leistungsstarker Modelle in ressourcenbeschränkten Umgebungen.
# Vor- und Nachteile der Quantisierung
Vorteile:
- Modelle belegen weniger Speicherplatz, was ihre Verteilung und Bereitstellung erleichtert.
- Berechnungen mit geringerer Präzision sind schneller und verbessern die Echtzeitleistung.
- Ideal für batteriebetriebene Geräte.
Nachteile:
- Quantisierung kann Fehler einführen und die Modellgenauigkeit verringern.
- Insbesondere bei asymmetrischer Quantisierung und QAT.
- Nicht alle Hardware unterstützt alle Arten von Quantisierung effizient.

# Praktisches Beispiel für Quantisierung
In diesem Beispiel zeigen wir, wie man eine dynamische Quantisierung auf ein vortrainiertes DistilBERT-Modell mithilfe der Bibliotheken transformers und torch durchführt. Dadurch wird die Modellgröße reduziert und es wird für die Bereitstellung auf Geräten mit begrenzten Rechenressourcen geeignet.
Erstellen wir ein Python-Skript, um ein vortrainiertes DistilBERT-Modell zu laden, eine dynamische Quantisierung durchzuführen und die Größen des ursprünglichen und quantisierten Modells zu vergleichen. Hier ist die schrittweise Erläuterung des Codes:
- Erforderliche Bibliotheken importieren
Zunächst müssen wir die Bibliotheken transformers und torch installieren, um die Quantisierung durchzuführen. Dies kann durch Ausführen des folgenden Befehls in Ihrem Terminal erfolgen:
pip install transformers torch
Die Bibliothek torch wird verwendet, um PyTorch-Modelle und Quantisierungsaufgaben zu verarbeiten, während die Bibliothek transformers zum Laden des vortrainierten DistilBERT-Modells und des Tokenizers verwendet wird. Zusätzlich wird das Modul os zum Interagieren mit dem Betriebssystem verwendet, z. B. zum Lesen und Schreiben von Dateien.
import torch
from transformers import DistilBertModel, DistilBertTokenizer
import os
- Vortrainiertes Modell und Tokenizer laden
Anschließend laden wir das vortrainierte DistilBERT-Modell und den Tokenizer mithilfe der Klassen DistilBertModel und DistilBertTokenizer aus der Bibliothek transformers. Der Modellname distilbert-base-uncased wird verwendet, um die bestimmte Variante von DistilBERT anzugeben.
model_name = 'distilbert-base-uncased'
model = DistilBertModel.from_pretrained(model_name)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
- Quantisierungsfunktion definieren
Als Nächstes definieren wir eine Funktion quantize_model, die eine dynamische Quantisierung auf das Modell anwendet. Die Funktion torch.quantization.quantize_dynamic wird verwendet, um das Modell in eine quantisierte Version umzuwandeln, wobei speziell die torch.nn.Linear-Schichten als Ziel festgelegt werden und eine 8-Bit-Ganzzahl (qint8) als Präzision verwendet wird.
def quantize_model(model):
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
return quantized_model
- DistilBERT-Modell quantisieren
Wir wenden dann die Funktion quantize_model auf das DistilBERT-Modell an, was zu einer quantisierten Version des Modells führt.
quantized_model = quantize_model(model)
- Größe des ursprünglichen und quantisierten Modells überprüfen
Schließlich definieren wir eine Funktion print_model_size, um die Größen des ursprünglichen und quantisierten Modells zu überprüfen und auszugeben. Die Funktion torch.save wird verwendet, um den Zustand des Modells als Dictionaries in eine Datei zu speichern, und die Funktion os.path.getsize wird verwendet, um die Dateigröße in Megabyte (MB) zu erhalten.
def print_model_size(model, model_name):
torch.save(model.state_dict(), f'{model_name}.pt')
print(f'Größe von {model_name}: {os.path.getsize(f"{model_name}.pt") / 1e6} MB')
Wir verwenden dann diese Funktion, um die Größen des ursprünglichen und quantisierten DistilBERT-Modells auszugeben.
print_model_size(model, 'original_distilbert')
print_model_size(quantized_model, 'quantized_distilbert')
Die endgültige Ausgabe des Codes sieht wie folgt aus:
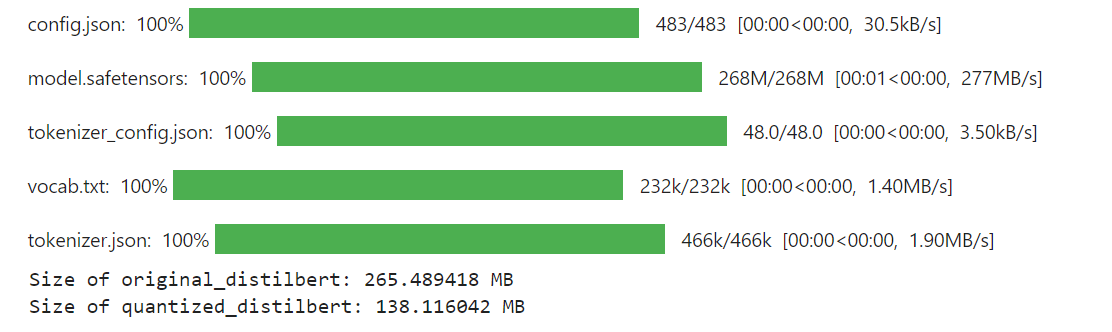
Ergebnisse
Wie Sie sehen können, wurde die Größe des DistilBERT-Modells nach der Quantisierung signifikant auf 138 MB reduziert, verglichen mit 265 MB vor der Quantisierung.
# Wie Quantisierung dabei hilft, bessere RAG-Systeme zu entwickeln
Quantisierung ermöglicht es uns, größere Modelle effektiver zu nutzen, indem ihre Größe reduziert wird, ohne dass dies zu einem signifikanten Leistungsverlust führt. LLMs erzielen naturgemäß bessere Leistungen und verfügen über fortschrittlichere Fähigkeiten, je größer sie sind, erfordern jedoch auch erhebliche Rechenressourcen. Mit Quantisierung können wir diese großen Modelle verkleinern und sie in ressourcenbeschränkten Umgebungen bereitstellen, während wir dennoch von ihren verbesserten Fähigkeiten profitieren.
Vektordatenbanken können mit Quantisierungstechniken integriert werden, um RAG-Systeme erheblich zu verbessern, indem Effizienz und Skalierbarkeit verbessert werden. Durch Speicherung und Suche von quantisierten Einbettungen ermöglichen Vektordatenbanken eine schnellere Abfrage, reduzierten Speicherbedarf und geringere Rechenkosten. Dadurch können RAG-Systeme größere Datensätze verarbeiten und schneller reagieren, während eine akzeptable Genauigkeit beibehalten wird. Die Kompatibilität mit quantisierten LLMs gewährleistet eine Konsistenz im gesamten Prozess und verbessert möglicherweise die Gesamtleistung. MyScaleDB (opens new window), eine SQL-Vektordatenbank, verbessert die Leistung von RAG zusätzlich, indem sie effiziente und genaue Datenabfrage bietet. Sie ist eine gute Wahl für Entwickler, da sie eine vertraute SQL-Schnittstelle bietet und zudem erschwinglich, schnell und für RAG-Anwendungen auf Produktionsniveau optimiert ist.
Wenn Sie Vorschläge haben, kontaktieren Sie uns bitte über Twitter (opens new window) oder Discord (opens new window).



