
![]()
LlamaIndex (opens new window) ist ein Datenframework, das für die Implementierung von Anwendungen mit Large Language Models (LLMs) entwickelt wurde. Es vereinfacht das Parsen, Speichern und Abrufen verschiedener Arten von Dokumentendaten und fügt den Fähigkeiten von LLM-Anwendungen einen immensen Mehrwert hinzu. Dieser Mechanismus wird allgemein als Retrieval-Augmented Generation (RAG) bezeichnet.
Um Ihnen zu zeigen, wie Sie LlamaIndex verwenden können, um diesen Mechanismus umzusetzen, wird in diesem Artikel eine einfache Dokumentenabfrage-Engine entwickelt, um den Prozess zu veranschaulichen.
# MyScale
Obwohl LlamaIndex verschiedene Arten von Quelldaten verarbeiten kann, speichert oder indiziert es diese Daten nicht. Wir benötigen immer noch ein Speichersystem. MyScale (opens new window) ist eine Vektordatenbank, die SQL unterstützt und einfach zu bedienen ist. Die kostenlose Version unterstützt bis zu 5 Millionen Vektordatenpunkte. Am wichtigsten ist, dass LlamaIndex MyScale-Vektordatenbanken unterstützt (opens new window). Sie können eine Verbindung zu einer MyScale-Datenbank herstellen, um Daten zu speichern und abzufragen, indem Sie MyScaleVectorStore und MyScaleReader verwenden und die folgenden Datenoperationen über LlamaIndex durchführen:
| Vektorspeicher | Typ | Metadatenfilterung | Hybride Suche | Löschen | Dokumente speichern |
|---|---|---|---|---|---|
| MyScale | Cloud | ✓ | ✓ | ✓ | ✓ |
Dieser Satz von Operationen bietet umfassende Funktionalitäten. Nun wollen wir unsere LLM-Anwendung mit diesen Operationen aufbauen.
# Vorbereitung
Hinweis:
Der im Artikel erwähnte Code ist auf GitHub im Repository myscale/llama_index_myscale (opens new window) zu finden.
# Daten
Wir haben die offizielle MyScale-Dokumentation (MyScale Docs (opens new window)) im Markdown-Format als Rohdaten verwendet. Diese Dateien können auch auf GitHub (opens new window) eingesehen und heruntergeladen werden.
# Abhängigkeiten
- Python 3.8.18
- LlamaIndex 0.9.5
- MyScale
# Ablauf
Der Aufbau einer Retrieval-Augmented Generation (RAG)-Anwendung umfasst mehrere Verarbeitungsschritte, wie das folgende Diagramm verdeutlicht. Zunächst müssen wir die Rohdaten offline verarbeiten, einschließlich der Aufteilung der Textdaten - die in flachen Dateien gespeichert sind - in Datenknoten basierend auf bestimmten Kriterien oder Regeln. Sobald dies abgeschlossen ist, müssen wir die Vektorrepräsentation jedes Datenknotens berechnen. Schließlich müssen wir die Daten in der Datenbank speichern.
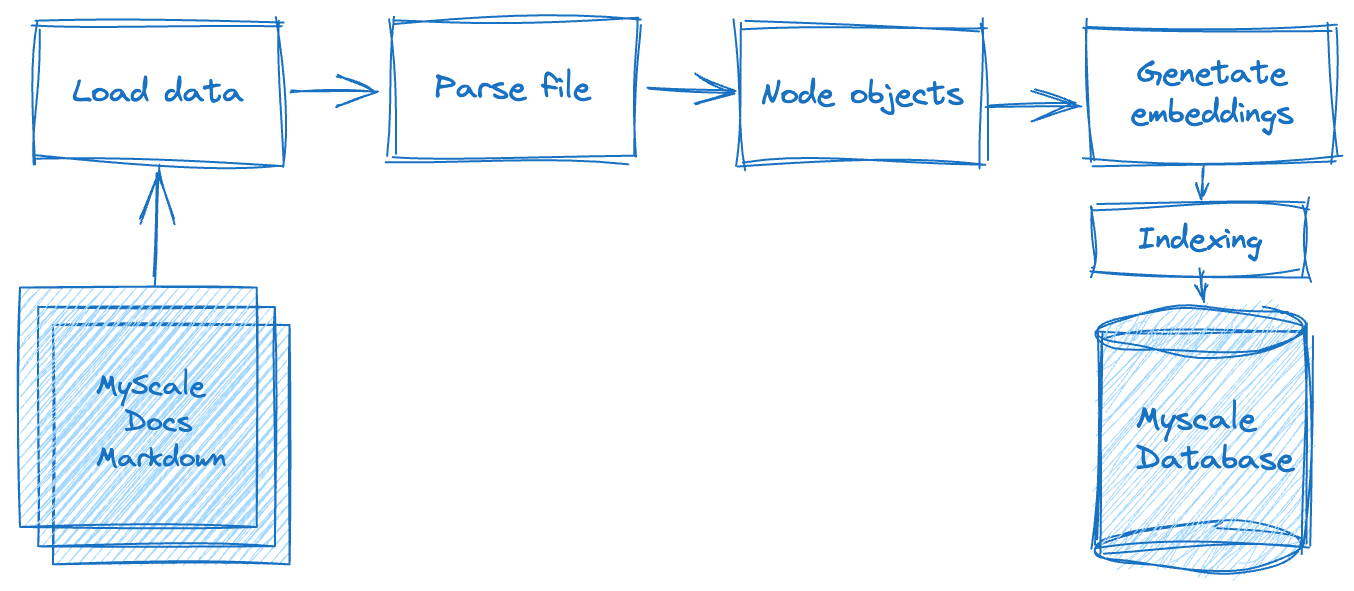
In der zweiten Phase, der Datenabrufphase, fragen wir die relevanten Dokumentendaten basierend auf dieser Abfrage ab und führen eine Zusammenführung durch. Diese Daten werden dann vom LLM-System angefordert und zurückgegeben, um die erwarteten Ergebnisse zu liefern.
Lassen Sie uns nun erkunden, wie wir LlamaIndex mit MyScale integrieren können, um diese Schritte zu erledigen.
# Laden der Daten
In dieser Phase müssen wir die heruntergeladenen Dokumentendateien lesen, in MyScale-Dokumentobjekte umwandeln und die umfangreichen Dokumentenverarbeitungsfunktionen von LlamaIndex nutzen, einschließlich der Verarbeitung von Markdown, PDFs, Word-Dokumenten, PowerPoint-Präsentationen, Bildern, Audio und Video. Für .md-Dokumente wird der MarkdownReader verwendet, wie im folgenden Beispiel gezeigt:
# utils.py
from llama_index import download_loader
from llama_index import Document
from typing import Dict, List, Union
from pathlib import Path
UnstructuredReader = download_loader("MarkdownReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> List[Dict[str, Document]]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-md files like png, jpg, etc., html.
if file.suffix.lower() == ".md":
loaded_doc = loader.load_data(file=file)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]
# Parsen der Dokumente
Nachdem wir die Textsegmente aus diesen Dokumenten gelesen haben, müssen wir sie in Datenknoten für die nächste Vektorisierungsoperation verpacken. Um eine einheitliche Formatierung sicherzustellen, verwenden wir weiterhin den MarkdownNodeParser. Der Verarbeitungsablauf für diesen Teil sieht wie folgt aus:
# utils.py
from llama_index.node_parser import MarkdownNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> List[Dict[str, Node]]:
parser = MarkdownNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]
# Vektorisierung
Die Vektorisierung ist ein entscheidender und zeitaufwändiger Schritt. Dabei geht es darum, den Textinhalt der in dem vorherigen Schritt zurückgegebenen Datenknoten zu vektorisieren und die Vektoren im Feld "embedding" der Datenknoten zu speichern. Wir verwenden das Modell sentence-transformers/all-mpnet-base-v2 (opens new window), das von Hugging Face bezogen werden kann. LlamaIndex unterstützt uns automatisch beim Herunterladen und Anwenden dieser Einbettungen in unserer Anwendung.
# utils.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Verwenden Sie das all-mpnet-base-v2 Sentence_transformer-Modell.
# Dies ist das Standard-Einbettungsmodell für LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={},
# Verwenden Sie die GPU für die Einbettung und geben Sie eine ausreichend große Batch-Größe an, um die GPU-Auslastung zu maximieren.
# Entfernen Sie "device": "cuda", um stattdessen die CPU zu verwenden.
encode_kwargs={"batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}
# Lokale Ausführung und Speichern in MyScale
Wir haben die Hauptoperationen des Parsens und Vektorisierens von Markdown-Dokumenten in den oben genannten Prozessen vorgestellt. Als Nächstes müssen wir die Daten ausgeben und einen Index erstellen. In LlamaIndex können wir MyScaleVectorStore verwenden, um diese nicht komplexen Operationen durchzuführen, wie im folgenden Python-Skript gezeigt:
Hinweis:
Dieses Skript enthält den gesamten Datenverarbeitungsablauf.
# create_vector_index.py
import clickhouse_connect
import utils
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
blog_nodes = {"embedded_nodes": []}
for docs in all_docs:
loaded_docs = utils.load_and_parse_files(docs)
for doc in loaded_docs:
nodes = utils.convert_documents_into_nodes(doc)
newNodes = {"node": []}
for node in nodes:
newNodes["node"].append(node["node"])
embedNodes = utils.EmbedNodes()
tmpNodes = embedNodes(newNodes)
blog_nodes["embedded_nodes"].extend(tmpNodes["embedded_nodes"])
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blog_nodes["embedded_nodes"], storage_context=storage_context)
Für die Wiederverwendbarkeit werden die Funktionen load_and_parse_files, convert_documents_into_nodes und EmbedNodes in utils.py platziert.
# Aufbau des Abfrage-Dienstes
Sobald die Daten in MyScale gespeichert sind, können wir MyScaleVectorStore und die API des LLM verwenden, um Benutzerabfragen zu verarbeiten, wie im folgenden Skript query_myscale.py beschrieben. Der Inhalt von query_myscale.py umfasst die folgenden Hauptschritte:
Dieses Skript umfasst diese Hauptschritte:
- Die Benutzereingabeabfrage aus dem Terminal lesen und die Abfrage vektorisieren.
- Mit
llama_index.vector_stores.MyScaleVectorStoredie mit der Abfrage zusammenhängenden Daten unter Verwendung des Hybrid-Suchmodus abfragen. Dieser Modus gewährleistet eine gewisse Relevanz sowohl in Text- als auch in Vektorentfernung. - Die Antwort synthetisieren, indem die in dem vorherigen Schritt erhaltenen Dokumente an das LLM gesendet werden, um das endgültige Ergebnis zu generieren.
# query_myscale.py
import clickhouse_connect
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.schema import NodeWithScore
from llama_index.vector_stores import MyScaleVectorStore, VectorStoreQuery
from llama_index.vector_stores.types import VectorStoreQueryMode
# Fügen Sie hier Ihren OpenAI API-Schlüssel ein, bevor Sie das Skript ausführen.
model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
# Eingabeabfrage
query = input("Abfrage: ")
while len(query) == 0:
query = input("\nAbfrage: ")
# Abfrage vektorisieren
embedded_query = model.embed_query(query)
# Abfrage an MyScale senden, indem llama_index.vector_stores.MyScaleVectorStore verwendet wird
vector_store = MyScaleVectorStore(myscale_client=client)
vector_store_query = VectorStoreQuery(
query_embedding=embedded_query,
similarity_top_k=20,
mode=VectorStoreQueryMode.HYBRID
)
result = vector_store.query(vector_store_query)
scoreNodes = [NodeWithScore(node=result.nodes[i], score=result.similarities[i]) for i in range(len(result.nodes))]
# Antwort synthetisieren
from llama_index.response_synthesizers import (
get_response_synthesizer,
)
synthesizer = get_response_synthesizer()
response_obj = synthesizer.synthesize(query, scoreNodes)
print(f"Antwort: {str(response_obj.response)}")
Hinweis:
Ersetzen Sie Platzhalter wie {MYSCALE_CLUSTER_URL}, {YOUR_USERNAME} und {YOUR_PASSWORD} durch Ihre tatsächlichen MyScale-Clusterinformationen.

# Ausführung des Skripts
Führen Sie das Skript aus und geben Sie nach der Aufforderung eine Abfrage ein, um die folgende Antwort zu erhalten:
$ python query_myscale.py
Abfrage: Wie erstelle ich einen MyScale-Cluster?
Antwort: Um einen MyScale-Cluster zu erstellen, können Sie folgende Schritte befolgen:
1. Gehen Sie zur Clusters-Seite.
2. Klicken Sie auf die Schaltfläche "+ Neuer Cluster".
3. Geben Sie Ihrem Cluster einen Namen.
4. Klicken Sie auf "Starten", um den Cluster auszuführen.
Sobald der Cluster erstellt ist, wird er automatisch gestartet. Bitte beachten Sie, dass der Cluster beendet wird, wenn für 7 Tage keine Aktivität stattfindet, und alle Daten im Cluster gelöscht werden.
Sie können verschiedene Fragen im Zusammenhang mit MyScale stellen. Diese Anwendung ist darauf ausgelegt, wertvolle Antworten zu liefern.
# Weitere Schritte
Wir haben erfolgreich eine voll funktionsfähige LLM-Anwendung mit MyScale und LlamaIndex erstellt und ihre effektive Leistung demonstriert. Wie können wir den Einbettungsprozess beschleunigen, um mit hunderttausenden oder sogar Millionen von Dokumentendaten umzugehen?
Glücklicherweise können wir Ray, ein Framework für maschinelles Lernen, in Kombination mit LlamaIndex und MyScale für verteiltes Computing verwenden, um die Effizienz der Datenverarbeitung zu verbessern. Sie können sich in der Ray-Offiziellen Dokumentation, Installing Ray (opens new window), oder Ray on Kubernetes (opens new window) über den Aufbau eines lokalen oder Kubernetes-basierten Clusters informieren.
Angenommen, Sie haben bereits einen RayCluster Head auf Local Host oder haben Post Forward für RayCluster Head im Kubernetes-Cluster aktiviert, können Sie den folgenden Code verwenden, um die Verarbeitung von Einbettungen mit parallelem Computing zu verbessern und so die Datenverarbeitungsgeschwindigkeit und -effizienz erheblich zu steigern:
# create_vector_index_by_ray.py
import clickhouse_connect
import utils
import ray
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
from ray.data import ActorPoolStrategy
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
ds = ray.data.from_items(all_docs)
loaded_docs = ds.flat_map(utils.load_and_parse_files)
nodes = loaded_docs.flat_map(utils.convert_documents_into_nodes)
embedded_nodes = nodes.map_batches(
utils.EmbedNodes,
batch_size=100,
compute=ActorPoolStrategy(size=4),
num_gpus=0)
blogs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
blogs_nodes.append(node)
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blogs_nodes, storage_context=storage_context)
Diese Prozesse, unter Verwendung der gleichen Eingabe und Ausgabe, wie sie im Abschnitt Lokale Ausführung und Speichern in MyScale beschrieben sind, können auch die relevanten Vektordaten abfragen, die in der MyScale-Datenbank gespeichert sind. Anschließend können Sie Abfragen mit query_myscale.py ausführen.
# Abschließend
MyScale und LlamaIndex sind zwei ausgezeichnete Werkzeuge für die LLM-Verarbeitung. Sie können Ihnen dabei helfen, Ihre LLM-Anwendung schnell aufzubauen. Wenn Sie vor Herausforderungen im Zusammenhang mit der Datenmenge stehen, können Sie Ray für die verteilte Verarbeitung verwenden und es mit LlamaIndex und MyScale kombinieren, um die Entwicklung zu erleichtern.
Besuchen Sie schließlich myscale.com (opens new window), um Ihren Cluster für große RAG-Anwendungen ohne Verzögerung einzurichten!



