
Die Iterationsgeschwindigkeit der generativen KI (GenAI) wächst exponentiell. Eine Konsequenz davon ist, dass das Kontextfenster - die Anzahl der Tokens, die ein großes Sprachmodell (LLM) gleichzeitig verwenden kann, um eine Antwort zu generieren - ebenfalls schnell wächst.
Google Gemini 1.5 Pro, das im Februar 2024 veröffentlicht wurde, stellte einen Rekord für das bisher längste Kontextfenster auf: 1 Million Tokens, was einer Stunde Video oder 700.000 Wörtern entspricht. Die herausragende Leistung von Gemini bei der Verarbeitung langer Kontexte führte dazu, dass einige Leute verkündeten, dass "retrieval-augmented generation (RAG) tot ist". LLMs sind bereits sehr leistungsstarke Retrievers, sagten sie, also warum Zeit damit verschwenden, einen schwachen Retriever zu bauen und sich mit RAG-bezogenen Problemen wie Chunking, Embedding und Indexierung auseinanderzusetzen?
Das erweiterte Kontextfenster hat eine Debatte ausgelöst: Ist RAG trotz dieser Verbesserungen immer noch notwendig? Oder könnte es bald überflüssig werden?
# Wie RAG funktioniert
LLMs stoßen ständig an die Grenzen dessen, was Maschinen verstehen und erreichen können, waren aber durch Probleme wie Schwierigkeiten bei der genauen Reaktion auf unbekannte Daten oder bei der Aktualität der neuesten Informationen begrenzt. Dies führte zu Halluzinationen, für die RAG entwickelt wurde (opens new window).
RAG kombiniert die Leistungsfähigkeit von LLMs mit externen Wissensquellen, um informiertere und genauere Antworten zu generieren. Wenn eine Benutzeranfrage eingeht, verarbeitet das RAG-System zunächst den Text, um seinen Kontext und seine Absicht zu verstehen. Dann ruft es relevante Daten zur Benutzeranfrage aus einer Wissensbasis (opens new window) ab und übergibt sie zusammen mit der Anfrage als Kontext an das LLM. Anstatt die gesamte Wissensbasis zu übergeben, gibt es nur die relevanten Daten weiter, da LLMs eine kontextuelle Begrenzung (opens new window) haben, die die Menge an Text begrenzt, die ein Modell gleichzeitig betrachten oder verstehen kann.
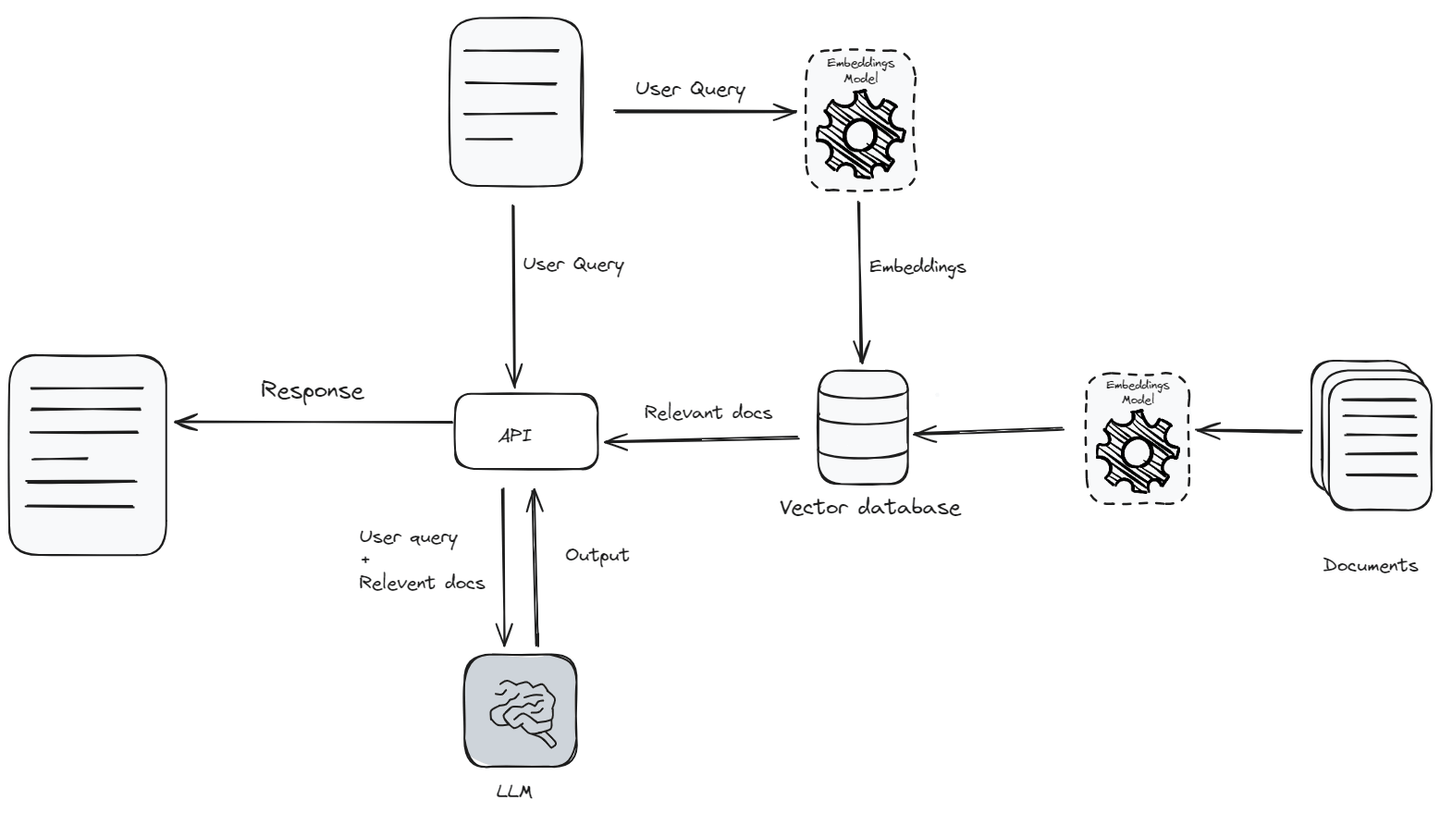
Zuerst wird die Anfrage (opens new window) mithilfe eines Einbettungsmodells (opens new window) in Vektoreinbettungen umgewandelt. Dieser Einbettungsvektor wird dann mit einer Datenbank von Dokumentenvektoren verglichen, um die relevantesten Dokumente zu identifizieren. Diese relevanten Dokumente werden abgerufen und mit der ursprünglichen Anfrage kombiniert, um dem LLM einen reichhaltigen Kontext für die Generierung einer genaueren Antwort zu bieten. Dieser hybride Ansatz ermöglicht es dem Modell, aktuelle Informationen aus externen Quellen zu nutzen, sodass LLMs informiertere und genauere Antworten generieren können.
# Warum lange Kontextfenster das Ende von RAG bedeuten könnten
Die kontinuierliche Erhöhung des Kontextfensters von LLMs wird sich direkt darauf auswirken, wie diese Modelle Informationen aufnehmen und Antworten generieren. Durch die Erhöhung der Menge an Text, die LLMs gleichzeitig verarbeiten können, verbessern diese erweiterten Kontextfenster die Fähigkeit des Modells, umfassendere Erzählungen und komplexe Ideen zu verstehen, was die Gesamtqualität und Relevanz der generierten Antworten verbessert. Dies verbessert die Fähigkeit von LLMs, längere Texte nachzuverfolgen, sodass sie einen Kontext und seine Feinheiten effektiver erfassen können. Folglich kann mit zunehmender Fähigkeit von LLMs, umfangreichen Kontext zu handhaben und zu integrieren, die Abhängigkeit von RAG zur Verbesserung der Genauigkeit und Relevanz von Antworten abnehmen.
# Genauigkeit
RAG verbessert die Fähigkeit des Modells, indem es relevante Dokumente als Kontext auf der Grundlage einer Ähnlichkeitsscore (opens new window) bereitstellt. RAG passt sich jedoch nicht in Echtzeit an den Kontext an oder lernt daraus. Stattdessen ruft es Dokumente ab, die der Benutzeranfrage ähnlich erscheinen, was nicht immer am kontextuellsten ist und zu weniger genauen Antworten führen kann.
Auf der anderen Seite kann das Aufnehmen des langen Kontextfensters eines Sprachmodells durch das Einfügen aller Daten darin der Aufmerksamkeitsmechanismus (Attention Mechanism) eines LLMs bessere Antworten generieren. Der Aufmerksamkeitsmechanismus innerhalb eines Sprachmodells konzentriert sich auf die verschiedenen Teile des bereitgestellten Kontexts, um eine präzise Antwort zu generieren. Darüber hinaus kann dieser Mechanismus feinabgestimmt (opens new window) werden. Durch die Anpassung des LLM-Modells zur Reduzierung des Verlusts wird es immer besser und liefert genauere und kontextuell relevantere Antworten.
# Informationsabruf
Beim Abrufen von Informationen aus einer Wissensbasis zur Verbesserung der LLM-Antworten ist es immer schwierig, vollständige und relevante Daten für das Kontextfenster zu finden. Es besteht ständige Unsicherheit darüber, ob die abgerufenen Daten die Benutzeranfrage vollständig beantworten. Diese Situation kann zu Ineffizienzen und Fehlern führen, wenn die ausgewählten Informationen nicht ausreichen und nicht gut mit den tatsächlichen Absichten des Benutzers oder dem Kontext des Gesprächs übereinstimmen.
# Externer Speicher
Traditionell konnten LLMs gleichzeitig keine großen Datenmengen verarbeiten, da sie in der Verarbeitung des Kontexts begrenzt waren. Aber ihre neu verbesserten Fähigkeiten ermöglichen es ihnen, umfangreiche Daten direkt zu verarbeiten, was die Notwendigkeit einer separaten Speicherung pro Abfrage beseitigt. Dadurch werden Architektur vereinfacht, der Zugriff auf externe Datenbanken beschleunigt und die Effizienz der KI verbessert.
# Warum RAG bestehen bleibt
Erweiterte Kontextfenster in LLMs können einem Modell tiefere Einblicke geben, bringen aber auch Herausforderungen wie höhere Rechenkosten und Effizienz mit sich. RAG bewältigt diese Herausforderungen, indem es selektiv nur die relevantesten Informationen abruft, was die Leistung und Genauigkeit optimiert.
# Komplexes RAG wird fortbestehen
Es besteht kein Zweifel daran, dass einfaches RAG, bei dem Daten in Dokumente fester Länge aufgeteilt und aufgrund der Ähnlichkeit abgerufen werden, an Bedeutung verliert. Komplexe RAG-Systeme hingegen bestehen nicht nur fort, sondern entwickeln sich auch signifikant weiter.
Komplexes RAG umfasst eine breitere Palette von Fähigkeiten wie Anfragenumschreibung (opens new window), Datenbereinigung (opens new window), Reflexion (opens new window), optimierte Vektorsuche (opens new window), Graphensuche (opens new window), Reranker (opens new window) und anspruchsvollere Chunking-Techniken. Diese Verbesserungen verfeinern nicht nur die Funktionalität von RAG, sondern skalieren auch ihre Fähigkeiten.
# Leistung über die Kontextlänge hinaus
Die Erweiterung des Kontextfensters in LLMs, um Millionen von Tokens einzuschließen, sieht vielversprechend aus, aber die praktische Umsetzung ist aufgrund mehrerer Faktoren wie Zeit, Effizienz und Kosten immer noch fraglich.
Zeit: Mit zunehmender Größe des Kontextfensters steigt auch die Latenzzeit der Antwort. Wenn Sie die Größe des Kontextfensters erweitern, benötigt das LLM mehr Zeit, um eine größere Anzahl von Tokens zu verarbeiten, was zu Verzögerungen und erhöhter Latenz führt. Viele LLM-Anwendungen erfordern schnelle Antworten. Die zusätzliche Verzögerung durch die Verarbeitung größerer Textblöcke kann die Leistung des LLMs in Echtzeitszenarien erheblich beeinträchtigen und zu einem Engpass bei der Implementierung größerer Kontextfenster führen.
Effizienz: Studien zeigen, dass LLMs bessere Ergebnisse erzielen, wenn ihnen weniger, relevantere Dokumente zur Verfügung gestellt werden, anstatt große Mengen ungefilterter Daten. Eine kürzlich durchgeführte Studie der Stanford University (opens new window) ergab, dass modernste LLMs oft Schwierigkeiten haben, wertvolle Informationen aus ihrem umfangreichen Kontextfenster zu extrahieren. Die Schwierigkeit tritt besonders auf, wenn wichtige Daten in der Mitte eines großen Textblocks verborgen sind, was dazu führt, dass LLMs wichtige Details übersehen und zu ineffizienter Datenverarbeitung führen.
Kosten: Die Erweiterung der Größe des Kontextfensters in LLMs führt zu höheren Rechenkosten. Die Verarbeitung einer größeren Anzahl von Eingabetokens erfordert mehr Ressourcen, was zu höheren Betriebskosten führt. Zum Beispiel wird in Systemen wie ChatGPT darauf geachtet, die Anzahl der verarbeiteten Tokens zu begrenzen, um die Kosten unter Kontrolle zu halten.
RAG optimiert direkt jeden dieser drei Faktoren. Indem nur ähnliche oder relevante Dokumente als Kontext übergeben werden (anstatt alles zu überladen), verarbeiten LLMs Informationen schneller, was nicht nur die Latenzzeit reduziert, sondern auch die Qualität der Antworten verbessert und die Kosten senkt.
# Warum kein Feinabstimmen?
Neben der Verwendung eines größeren Kontextfensters ist eine andere Alternative zu RAG das Feinabstimmen. Allerdings kann das Feinabstimmen teuer und umständlich sein. Es ist eine Herausforderung, ein LLM jedes Mal zu aktualisieren, wenn neue Informationen eingehen, um es auf dem neuesten Stand zu halten. Weitere Probleme beim Feinabstimmen sind:
- Beschränkungen der Trainingsdaten: Unabhängig von den Fortschritten bei LLMs wird es immer Kontexte geben, die zum Zeitpunkt des Trainings nicht verfügbar waren oder als irrelevant angesehen wurden.
- Rechenressourcen: Um ein LLM anhand Ihres Datensatzes feinabzustimmen und es für bestimmte Aufgaben anzupassen, benötigen Sie hohe Rechenressourcen.
- Erforderliche Expertise: Die Entwicklung und Aufrechterhaltung von hochmoderner KI ist keine leichte Aufgabe. Sie benötigen spezialisierte Fähigkeiten und Kenntnisse, die schwer zu finden sein können.
Weitere Probleme umfassen das Sammeln der Daten, die Sicherstellung der ausreichenden Qualität und die Bereitstellung des Modells.
# Vergleich von RAG vs. Feinabstimmung oder langen Kontextfenstern
Im Folgenden finden Sie einen vergleichenden Überblick über RAG und Feinabstimmung oder Techniken mit langen Kontextfenstern (da die letzten beiden ähnliche Eigenschaften aufweisen, habe ich sie in dieser Tabelle kombiniert). Es werden wichtige Aspekte wie Kosten, Aktualität der Daten und Skalierbarkeit hervorgehoben.
| Merkmal | RAG | Feinabstimmung / Lange Kontextfenster |
| Kosten | Minimal, kein Training erforderlich | Hoch, erfordert umfangreiches Training und Aktualisierung |
| Aktualität der Daten | Daten werden bei Bedarf abgerufen, um Aktualität zu gewährleisten | Daten können schnell veraltet sein |
| Transparenz | Hoch, zeigt abgerufene Dokumente an | Niedrig, unklar wie Daten Ergebnisse beeinflussen |
| Skalierbarkeit | Hoch, lässt sich problemlos mit verschiedenen Datenquellen integrieren | Begrenzt, Skalierung erfordert erhebliche Ressourcen |
| Leistung | Selektiver Datenabruf verbessert die Leistung | Leistung kann mit zunehmender Kontextgröße abnehmen |
| Anpassungsfähigkeit | Kann an spezifische Aufgaben angepasst werden, ohne erneutes Training | Erfordert erneutes Training für signifikante Anpassungen |

# Optimierung von RAG-Systemen mit Vektordatenbanken
Modernste LLMs können Millionen von Tokens gleichzeitig verarbeiten, aber die Komplexität und ständige Weiterentwicklung von Datenstrukturen machen es für LLMs herausfordernd, heterogene Unternehmensdaten effektiv zu verwalten. RAG begegnet diesen Herausforderungen, obwohl die Genauigkeit des Abrufs nach wie vor ein wesentlicher Engpass für die End-to-End-Leistung ist. Ob es sich um das große Kontextfenster von LLMs oder RAG handelt, das Ziel besteht darin, die Vorteile von Big Data optimal zu nutzen und die Effizienz der Datenverarbeitung im großen Maßstab sicherzustellen.
Die Integration von LLMs mit Big Data mithilfe fortschrittlicher SQL-Vektordatenbanken wie MyScaleDB (opens new window) verbessert die Effektivität von LLMs und erleichtert die Extraktion von Informationen aus Big Data. Darüber hinaus mindert es Modellhalluzinationen, bietet Daten-Transparenz und verbessert die Zuverlässigkeit. MyScaleDB, eine Open-Source-SQL-Vektordatenbank, die auf ClickHouse (opens new window) aufbaut, ist auf große KI-/RAG-Anwendungen zugeschnitten. Mit ClickHouse als Basis und dem proprietären MSTG-Algorithmus bietet MyScaleDB eine überlegene Leistung bei der Verwaltung von Daten im großen Maßstab im Vergleich zu anderen Vektordatenbanken (opens new window).
LLM-Technologie verändert die Welt und die Bedeutung des Langzeitgedächtnisses wird bestehen bleiben. Entwickler von KI-Anwendungen streben immer nach dem perfekten Gleichgewicht zwischen Anfragequalität und Kosten. Wenn große Unternehmen generative KI in Produktion bringen, müssen sie die Kosten kontrollieren und gleichzeitig die beste Qualität der Antwort gewährleisten. RAG und Vektordatenbanken bleiben wichtige Werkzeuge, um dieses Ziel zu erreichen.
Sie sind herzlich eingeladen, MyScaleDB auf GitHub (opens new window) zu erkunden oder in unserem Discord (opens new window) mehr über LLMs oder RAG zu diskutieren.
Dieser Artikel wurde ursprünglich auf The New Stack veröffentlicht. (opens new window)




