
MyScale hat kürzlich die Funktion EmbedText (opens new window) eingeführt, ein leistungsstarkes Feature, das SQL-Abfragen mit Textvektorisierungsfunktionen integriert und Text in numerische Vektoren umwandelt. Diese Vektoren bilden semantische Ähnlichkeiten, die von Menschen wahrgenommen werden, effektiv in Nähebeziehungen innerhalb eines Vektorraums ab. Mit der vertrauten Syntax von SQL vereinfacht EmbedText den Vektorisierungsprozess, verbessert die Zugänglichkeit und ermöglicht es Benutzern, Textvektorisierung in MyScale effizient mit Anbietern wie OpenAI (opens new window), Jina AI (opens new window), Amazon Bedrock (opens new window) und anderen sowohl in Echtzeit- als auch in Stapelverarbeitungsszenarien durchzuführen. Darüber hinaus wird durch die Nutzung der automatischen Stapelverarbeitung die Verarbeitungsleistung großer Datenmengen erheblich verbessert. Diese Integration beseitigt die Notwendigkeit externer Tools oder komplexer Programmierung und vereinfacht den Vektorisierungsprozess innerhalb der MyScale-Datenbankumgebung.
# Einführung
Die Funktion EmbedText, definiert als EmbedText(text, provider, base_url, api_key, others), ist hoch konfigurierbar und für Echtzeitsuche sowie Stapelverarbeitung ausgelegt.
Hinweis:
Die detaillierten Parameter dieser Funktion finden Sie in unserer Dokumentation (opens new window).
Wie in der folgenden Tabelle beschrieben, unterstützt die Funktion EmbedText acht Anbieter, von denen jeder einzigartige Vorteile bietet:
| Anbieter | Unterstützt | Anbieter | Unterstützt |
|---|---|---|---|
| OpenAI | ✔ | Amazon Bedrock | ✔ |
| HuggingFace | ✔ | Amazon SageMaker | ✔ |
| Cohere | ✔ | Jina AI | ✔ |
| Voyage AI | ✔ | Gemini | ✔ |
Zum Beispiel ist das Modell text-embedding-ada-002 von OpenAI (opens new window) für seine robuste Leistung bekannt. Es kann in MyScale mit dem folgenden SQL-Befehl verwendet werden:
SELECT EmbedText('IHR_TEXT', 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Das Modell jina-embeddings-v2-base-en von Jina AI (opens new window) unterstützt umfangreiche Sequenzlängen von bis zu 8k und bietet eine kostengünstige und kompakte Alternative für die Einbettungsdimension. So verwenden Sie dieses Modell:
SELECT EmbedText('IHR_TEXT', 'Jina', '', 'API_KEY', '{"model":"jina-embeddings-v2-base-en"}')
Hinweis:
Dieses Modell ist derzeit nur auf englischen Text beschränkt.
Amazon Bedrock Titan (opens new window) ist mit OpenAI-Modellen kompatibel und zeichnet sich durch seine Integration in AWS und seine Sicherheitsfunktionen aus. Es bietet eine umfassende Lösung für AWS-Benutzer, wie der folgende Code-Schnipsel zeigt:
SELECT EmbedText('IHR_TEXT', 'Bedrock', '', 'SECRET_ACCESS_KEY', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"ACCESS_KEY_ID"}')
# Erstellung dedizierter Funktionen
Für eine einfache Verwendung können dedizierte Funktionen für jeden Anbieter erstellt werden. Zum Beispiel können Sie die folgende Funktion mit dem Modell text-embedding-ada-002 von OpenAI definieren:
CREATE FUNCTION OpenAIEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(x, 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Anschließend kann die Funktion OpenAIEmbedText vereinfacht verwendet werden:
SELECT OpenAIEmbedText('IHR_TEXT')
Dieser Ansatz vereinfacht den Einbettungsprozess und reduziert die wiederholte Eingabe von gemeinsamen Parametern wie API-Schlüsseln.
# Vektorverarbeitung mit EmbedText
EmbedText revolutioniert die Vektorverarbeitung in MyScale, insbesondere für die Vektorsuche und die Datenverarbeitung. Diese Funktion ist entscheidend, um sowohl Suchanfragen als auch Datenbankspalten in numerische Vektoren umzuwandeln, was ein wesentlicher Schritt für die Vektorsuche und die Datenverwaltung ist.
# Verbesserung der Vektorsuche
Bei der Vektorsimilarity-Suche, wie in unserem Leitfaden zur Vektorsuche (opens new window) detailliert beschrieben - und wie im folgenden Code-Schnipsel beschrieben - müssen Benutzer im herkömmlichen Ansatz die Abfragevektoren manuell in SQL eingeben.
SELECT id, distance(vector, [0.123, 0.234, ...]) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
Wie im folgenden Code-Schnipsel dargestellt, vereinfacht EmbedText den Vektor-Suchprozess, macht ihn intuitiver, vereinfacht die Benutzererfahrung erheblich und konzentriert sich auf die Formulierung der Abfrage anstelle der Mechanik der Vektorerstellung.
SELECT id, distance(vector, OpenAIEmbedText('Die Textabfrage')) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
# Vereinfachung von Stapeltransformationen
Basierend auf diesem Diagramm sehen wir, dass der typische Workflow für Stapeltransformationen eine Vorverarbeitung und Speicherung der Textdaten in einem strukturierten Format umfasst.
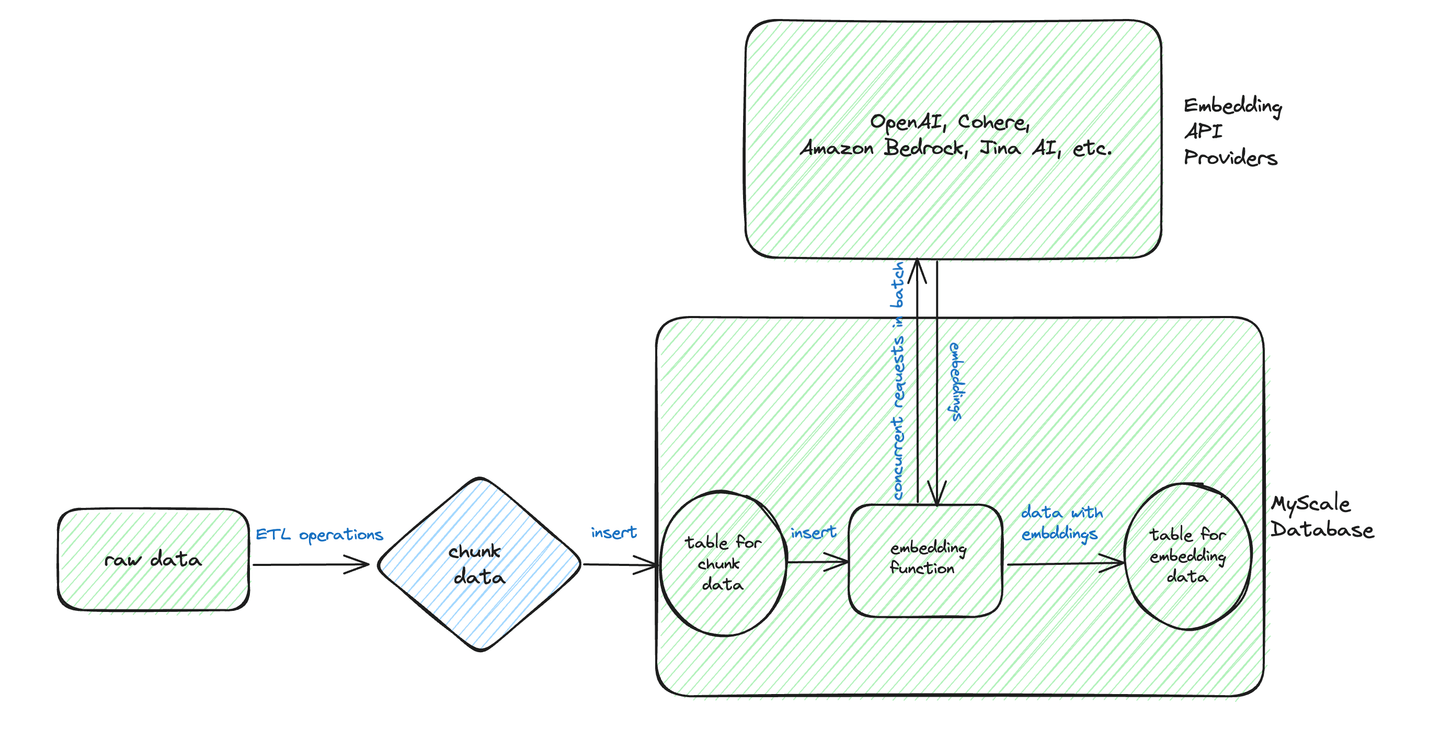
Angenommen, wir haben die folgende Tabelle chunk_data, die Rohdaten enthält.
CREATE TABLE chunk_data
(
id UInt32,
chunk String,
) ENGINE = MergeTree ORDER BY id
INSERT INTO chunk_data VALUES (1, 'Chunk1'), (2, 'Chunk2'), ...
Wir können eine zweite Tabelle - die Tabelle test_embedding - erstellen, um Vektoreinbettungen auf folgende Weise zu speichern - unter Verwendung der Funktion EmbedText.
CREATE TABLE test_embedding
(
id UInt32,
paragraph String,
vector Array(Float32) DEFAULT OpenAIEmbedText(paragraph),
CONSTRAINT check_length CHECK length(vector) = 1536,
) ENGINE = MergeTree ORDER BY id
Das Einfügen von Daten in test_embedding wird dadurch vereinfacht.
INSERT INTO test_embedding (id, paragraph) SELECT id, chunk FROM chunk_data
Alternativ kann EmbedText explizit während des Einfügens angewendet werden.
INSERT INTO test_embedding (id, paragraph, vector) SELECT id, chunk, OpenAIEmbedText(chunk) FROM chunk_data
Wie oben hervorgehoben, enthält EmbedText eine automatische Stapelverarbeitungsfunktion, die die Effizienz bei der Verarbeitung mehrerer Texte erheblich verbessert. Diese Funktion verwaltet den Stapelverarbeitungsprozess intern, bevor sie die Daten an die Einbettungs-API sendet, und gewährleistet so einen effizienten und optimierten Datenverarbeitungsworkflow. Ein Beispiel für diese Effizienz wird mit dem Modell BAAI/bge-small-en (opens new window) auf einer NVIDIA A10G GPU demonstriert, das bis zu 1200 Anfragen pro Sekunde erreicht.

# Fazit
Die Funktion EmbedText von MyScale ist ein praktisches und effizientes Werkzeug zur Vektorisierung von Texten, das komplexe Prozesse vereinfacht und die erweiterte Vektorsuche und Datenverarbeitung demokratisiert. Unsere Vision ist es, diese Innovation nahtlos in den täglichen Datenbankbetrieb zu integrieren und eine breite Palette von Benutzern in der KI-/LLM-bezogenen Datenverarbeitung zu unterstützen.



