
Große Sprachmodelle sind fortschrittliche KI-Systeme, die eine Vielzahl von Fragen beantworten können. Obwohl sie informative Antworten zu Themen liefern, die sie kennen, sind sie nicht immer genau bei unbekannten Themen. Dieses Phänomen wird als Halluzination bezeichnet.
![]()
# Was ist Halluzination?
Bevor wir uns ein Beispiel für eine LLM-Halluzination ansehen, betrachten wir zunächst eine Definition des Begriffs "Halluzination", wie sie von Wikipedia.com (opens new window) beschrieben wird:
"Eine Halluzination ist eine Wahrnehmung in Abwesenheit eines externen Reizes, die die Eigenschaften einer realen Wahrnehmung aufweist."
Darüber hinaus:
"Halluzinationen sind lebhaft, substantiell und werden als im externen, objektiven Raum befindlich wahrgenommen."
Mit anderen Worten, eine Halluzination ist ein Fehler in (oder eine falsche) Wahrnehmung von etwas Realem oder Konkretem. Zum Beispiel wurde ChatGPT (ein bekanntes großes Sprachmodell von OpenAI) gefragt, was LLM-Halluzinationen sind, und die Antwort lautete:

Die Frage lautet also, wie verbessern wir dieses Ergebnis? Die prägnante Antwort lautet, Fakten zu deiner Frage hinzuzufügen, zum Beispiel indem du die LLM-Definition vor oder nach der Fragestellung angibst.
Zum Beispiel:
Ein LLM ist ein großes Sprachmodell, ein künstliches neuronales Netzwerk, das modelliert, wie Menschen sprechen und schreiben. Bitte sag mir, was LLM-Halluzination ist?
Die öffentliche Antwort auf diese Frage, die von ChatGPT bereitgestellt wird, lautet:

Hinweis:
Der Grund für den ersten Satz "Entschuldigung für die Verwirrung in meiner vorherigen Antwort" ist, dass wir ChatGPT unsere erste Frage gestellt haben, was LLM-Halluzinationen sind, bevor wir ihm unseren zweiten Anstoß gegeben haben: "Ein LLM..."
Diese Ergänzungen haben die Qualität der Antwort verbessert. Zumindest denkt es nicht mehr, dass eine LLM-Halluzination eine "Late-Life Migraine Accompaniment!" ist 😆
# Externes Wissen reduziert Halluzinationen
An dieser Stelle ist es äußerst wichtig zu beachten, dass ein LLM nicht unfehlbar ist und nicht die ultimative Autorität für alle Kenntnisse darstellt. LLMs werden auf großen Datenmengen trainiert und lernen Sprachmuster, aber sie haben möglicherweise nicht immer Zugriff auf die aktuellsten Informationen oder ein umfassendes Verständnis komplexer Themen.
Was nun? Wie erhöhen Sie die Chance, LLM-Halluzinationen zu reduzieren?
Die Lösung für dieses Problem besteht darin, unterstützende Dokumente zur Abfrage (oder zum Anstoß) hinzuzufügen, um das LLM auf eine genauere und informiertere Antwort zu lenken. Wie Menschen muss es aus diesen Dokumenten lernen, um Ihre Frage genau und korrekt zu beantworten.
Hilfreiche Dokumente können aus vielen Quellen stammen, einschließlich einer Suchmaschine wie Google oder Bing und einer digitalen Bibliothek wie Arxiv, die eine Schnittstelle zum Suchen relevanter Passagen bietet. Die Verwendung einer Datenbank ist ebenfalls eine gute Wahl, da sie eine flexiblere und private Abfrageschnittstelle bietet.
Das aus den Quellen abgerufene Wissen muss relevant zur Frage/dem Anstoß sein. Es gibt verschiedene Möglichkeiten, relevante Dokumente abzurufen, darunter:
- Schlüsselwortbasiert: Suche nach Schlüsselwörtern im Klartext, geeignet für eine exakte Übereinstimmung von Begriffen.
- Vektorsuchbasiert: Suche nach Datensätzen, die den Einbettungen näher sind, hilfreich bei der Suche nach geeigneten Paraphrasen oder allgemeinen Dokumenten.
Heutzutage sind Vektorsuchen beliebt, da sie Paraphrasenprobleme lösen und die Bedeutung von Absätzen berechnen können. Vektorsuche ist keine Einheitslösung; sie sollte mit spezifischen Filtern kombiniert werden, um ihre Leistung aufrechtzuerhalten, insbesondere bei der Suche in großen Datensätzen. Wenn Sie beispielsweise nur Wissen über Physik (als Fachgebiet) abrufen möchten, müssen Sie alle Informationen zu anderen Themen filtern. Dadurch wird das LLM nicht durch Wissen aus anderen Disziplinen verwirrt.
# Automatisieren Sie den gesamten Prozess mit SQL... und Vektorsuche
Das LLM sollte auch lernen, Daten aus seinen Datenquellen abzufragen, bevor es die Fragen beantwortet, und den gesamten Prozess automatisieren. Tatsächlich sind LLMs bereits in der Lage, SQL-Abfragen zu schreiben und Anweisungen zu befolgen.
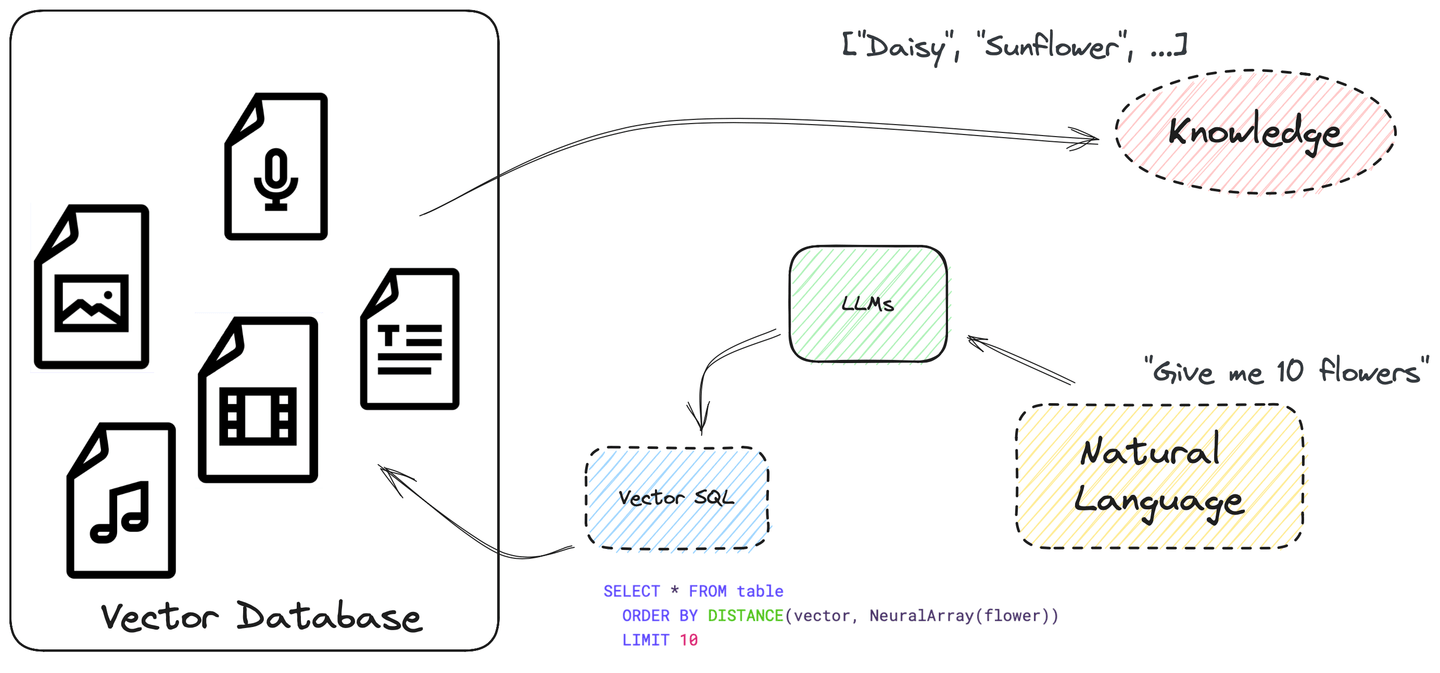
SQL ist leistungsstark und kann verwendet werden, um komplexe Suchabfragen zu erstellen. Es unterstützt viele verschiedene Datentypen und Funktionen. Und es ermöglicht uns, eine Vektorsuche in SQL mit ORDER BY und LIMIT zu schreiben, wobei die Ähnlichkeit zwischen Einbettungen als Spalte distance behandelt wird. Ziemlich unkompliziert, oder?
Weitere Informationen zur Strukturierung einer Vektorsuchabfrage finden Sie im nächsten Abschnitt Wie Vector SQL aussieht.
Die Verwendung von Vector SQL zur Erstellung komplexer Suchabfragen bietet erhebliche Vorteile, darunter:
- Erhöhte Flexibilität für Datentypen und Funktionen
- Verbesserte Effizienz, da SQL hoch optimiert ist und innerhalb der Datenbank ausgeführt wird
- Ist für Menschen lesbar und leicht zu erlernen, da es eine Erweiterung von Standard-SQL ist
- Ist LLM-freundlich
Hinweis:
Im Internet sind viele SQL-Beispiele und Tutorials verfügbar. LLMs sind mit Standard-SQL sowie einigen seiner Dialekte vertraut.
Neben MyScale fügen viele SQL-Datenbanklösungen wie ClickHouse und PostgreSQL der vorhandenen Funktionalität auch die Vektorsuche hinzu, sodass Benutzer Vector SQL und LLMs verwenden können, um Fragen zu komplexen Themen zu beantworten. Ebenso integrieren immer mehr Anwendungsentwickler die Vektorsuche mit SQL in ihre Anwendungen.
# Wie Vector SQL aussieht
Vector Structured Query Language (Vector SQL) wurde entwickelt, um LLMs beizubringen, wie sie Vektor-SQL-Datenbanken abfragen können, und enthält die folgenden zusätzlichen Funktionen:
DISTANCE(column, query_vector): Diese Funktion vergleicht die Entfernung zwischen der Spalte der Vektoren und dem Abfragevektor entweder genau oder ungefähr.NeuralArray(entity): Diese Funktion wandelt eine Entität (z. B. ein Bild oder einen Text) in eine Einbettung um.
Mit diesen beiden Funktionen können wir das Standard-SQL für die Vektorsuche erweitern. Wenn Sie beispielsweise nach 10 relevanten Datensätzen zum Wort Blume suchen möchten, können Sie die folgende SQL-Anweisung verwenden:
SELECT * FROM Tabelle
ORDER BY DISTANCE(Vektor, NeuralArray(Blume))
LIMIT 10
Die DISTANCE-Funktion besteht aus folgenden Teilen:
- Die innere Funktion
NeuralArray(Blume)wandelt das WortBlumein eine Einbettung um. - Diese Einbettung wird dann serialisiert und in die
DISTANCE-Funktion eingespeist.
Vector SQL ist eine erweiterte Version von SQL, die je nach verwendeter Vektordatenbank weiter übersetzt werden muss. Viele Implementierungen haben beispielsweise unterschiedliche Namen für die DISTANCE-Funktion. In MyScale wird sie distance genannt, in ClickHouse L2Distance oder CosineDistance. Abhängig von der Datenbank wird dieser Funktionsname unterschiedlich übersetzt.
# Wie man einem LLM beibringt, Vector SQL zu schreiben
Nun, da wir die grundlegenden Prinzipien von Vector SQL und seine einzigartigen Funktionen verstehen, lassen Sie uns ein LLM verwenden, um uns bei der Erstellung einer Vector SQL-Abfrage zu helfen.
# 1. Bringe einem LLM bei, was Standard Vector SQL ist
Zunächst müssen wir unserem LLM beibringen, was Standard Vector SQL ist. Wir möchten sicherstellen, dass das LLM spontan die folgenden drei Dinge tut, wenn es eine Vector SQL-Abfrage schreibt:
- Extrahiere die Schlüsselwörter aus unserer Frage/unserem Anstoß. Es könnte ein Objekt, ein Konzept oder ein Thema sein.
- Entscheide, welche Spalte verwendet werden soll, um die Ähnlichkeitssuche durchzuführen. Es sollte immer eine Vektorspalte für die Ähnlichkeit wählen.
- Übersetze den Rest der Einschränkungen unserer Frage in gültiges SQL.
# 2. Entwerfe den LLM-Anstoß
Nachdem wir genau festgelegt haben, welche Informationen das LLM benötigt, um eine Vector SQL-Abfrage zu erstellen, können wir den Anstoß wie folgt entwerfen:
# Hier ist ein Beispiel für einen Vector SQL-Anstoß
_prompt = f"""Du bist ein MyScale-Experte. Gegeben eine Eingabefrage, erstelle zuerst eine syntaktisch korrekte MyScale-Abfrage, um sie auszuführen, dann schau dir die Ergebnisse der Abfrage an und gib die Antwort auf die Eingabefrage zurück.
MyScale-Abfragen haben eine Vektorabstandsfunktion namens `DISTANCE(column, array)`, um die Relevanz zur Frage des Benutzers zu berechnen und das Feature-Array in der Spalte nach der Relevanz zu sortieren.
Wenn die Abfrage nach den {top_k} nächsten Zeilen fragt, musst du diese Distanzfunktion verwenden, um die Distanz zum Array der Entität in der Vektorspalte zu berechnen und nach der Distanz zu relevanten Zeilen zu suchen.
*HINWEIS*: `DISTANCE(column, array)` akzeptiert nur eine Arrayspalte als ersten Argument und eine `NeuralArray(entity)` als zweites Argument. Du benötigst auch eine benutzerdefinierte Funktion namens `NeuralArray(entity)`, um das Array der Entität abzurufen.
Sofern der Benutzer in der Frage nicht explizit eine bestimmte Anzahl von Beispielen angibt, frage höchstens {top_k} Ergebnisse mit der LIMIT-Klausel gemäß MyScale ab. Du solltest nur nach der Distanzfunktion sortieren.
Frage niemals alle Spalten einer Tabelle ab. Du musst nur die Spalten abfragen, die benötigt werden, um die Frage zu beantworten. Um jede Spaltenbezeichnung in doppelte Anführungszeichen (") zu setzen, um sie als begrenzte Bezeichner zu kennzeichnen.
Achte darauf, nur die Spaltennamen zu verwenden, die in den unten stehenden Tabellen sichtbar sind. Achte darauf, keine Spalten abzufragen, die nicht existieren. Achte auch darauf, welche Spalte in welcher Tabelle ist.
Achte darauf, die Funktion today() zu verwenden, um das aktuelle Datum zu erhalten, wenn die Frage "heute" betrifft. Die `ORDER BY`-Klausel sollte immer nach der `WHERE`-Klausel stehen. Füge KEIN Semikolon am Ende von SQL hinzu. Achte auf den Kommentar im Tabellenschema.
Verwende das folgende Format:
======== Tabelleninformationen ========
<einige Tabelleninformationen>
Frage: "Frage hier"
SQL-Abfrage: "SQL-Abfrage zum Ausführen"
Lass uns beginnen:
======== Tabelleninformationen ========
{table_info}
Frage: {input}
SQL-Abfrage:
Dieser Anstoß sollte seinen Zweck erfüllen. Aber je mehr Beispiele du hinzufügst, desto besser wird es sein, wie zum Beispiel die Verwendung des folgenden Vector-SQL-zu-Text-Paares als Anstoß:
Die SQL-Tabellenerstellungsanweisung:
------ Tabellenschema ------
CREATE TABLE "ChatPaper" (
abstract String,
id String,
vector Array(Float32),
categories Array(String),
pubdate DateTime,
title String,
authors Array(String),
primary_category String
) ENGINE = ReplicatedReplacingMergeTree()
ORDER BY id
PRIMARY KEY id
Die Frage und Antwort:
Frage: Was ist PaperRank? Was ist der Beitrag dieser Arbeiten? Verwende Papiere mit mehr als 2 Kategorien.
SQL-Abfrage: SELECT ChatPaper.title, ChatPaper.id, ChatPaper.authors FROM ChatPaper WHERE length(categories) > 2 ORDER BY DISTANCE(vector, NeuralArray(PaperRank contribution)) LIMIT {top_k}
Je mehr relevante Beispiele du deinem Anstoß hinzufügst, desto besser wird der Prozess des LLM, die richtige Vector SQL-Abfrage zu erstellen, verbessert.
Abschließend hier noch einige zusätzliche Tipps, die dir beim Entwerfen deines Anstoßes helfen können:
- Decke alle möglichen Funktionen ab, die in den gestellten Fragen auftreten könnten.
- Vermeide monotone Fragen.
- Ändere das Tabellenschema, z. B. durch Hinzufügen/Entfernen/Ändern von Namen und Datentypen.
- Achte auf das Format des Anstoßes.

# Ein Beispiel aus der Praxis: Verwendung von MyScale
Lass uns jetzt ein Beispiel aus der Praxis (opens new window) erstellen, das in den folgenden Schritten beschrieben wird:

# Bereite die Datenbank vor
Wir haben einen Spielplatz für dich vorbereitet, mit mehr als 2 Millionen Papieren, die zur Abfrage bereitstehen. Du kannst auf diese Daten zugreifen, indem du den folgenden Python-Code zu deiner App hinzufügst.
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
Wenn du möchtest, kannst du die folgenden Schritte überspringen, in denen wir die Tabelle erstellen und ihre Daten mithilfe der MyScale-Konsole einfügen, und zu dem Punkt springen, an dem wir mit Vector SQL spielen und die SQLDatabaseChain erstellen, um die Datenbank abzufragen.
Erstelle die Datenbanktabelle:
CREATE TABLE default.ChatArXiv (
`abstract` String,
`id` String,
`vector` Array(Float32),
`metadata` Object('JSON'),
`pubdate` DateTime,
`title` String,
`categories` Array(String),
`authors` Array(String),
`comment` String,
`primary_category` String,
CONSTRAINT vec_len CHECK length(vector) = 768)
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192
Füge die Daten ein:
INSERT INTO ChatArXiv
SELECT
abstract, id, vector, metadata,
parseDateTimeBestEffort(JSONExtractString(toJSONString(metadata), 'pubdate')) AS pubdate,
JSONExtractString(toJSONString(metadata), 'title') AS title,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'categories')) AS categories,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'authors')) AS authors,
JSONExtractString(toJSONString(metadata), 'comment') AS comment,
JSONExtractString(toJSONString(metadata), 'primary_category') AS primary_category
FROM
s3(
'https://myscale-demo.s3.ap-southeast-1.amazonaws.com/chat_arxiv/data.part*.zst',
'JSONEachRow',
'abstract String, id String, vector Array(Float32), metadata Object(''JSON'')',
'zstd'
);
ALTER TABLE ChatArXiv ADD VECTOR INDEX vec_idx vector TYPE MSTG('metric_type=Cosine');
# Erstelle die VectorSQLDatabaseChain
Du benötigst das experimentelle Paket LangChain für VectorSQLDatabaseChain. Du kannst es installieren, indem du das folgende Installations-Skript ausführst:
python3 -m venv .venv
source .venv/bin/activate
pip3 install langchain langchain-experimental --upgrade
Sobald du dieses Feature installiert hast, ist der nächste Schritt, es zu verwenden, um die Datenbank abzufragen, wie der folgende Python-Code zeigt:
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
# Verbindung zur Datenbank herstellen
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.callbacks import StdOutCallbackHandler
from langchain.llms import OpenAI
from langchain.utilities.sql_database import SQLDatabase
from langchain_experimental.sql.prompt import MYSCALE_PROMPT
from langchain_experimental.sql.vector_sql import VectorSQLDatabaseChain
from langchain_experimental.sql.vector_sql import VectorSQLRetrieveAllOutputParser
# Dieser Parser wandelt `NeuralArray()` in Einbettungen um
output_parser = VectorSQLRetrieveAllOutputParser(
model=HuggingFaceInstructEmbeddings(model_name='hkunlp/instructor-xl')
)
# Verwende den oben definierten Anstoß
PROMPT = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_prompt,
)
# Metadaten an SqlAlchemy-Engine binden
metadata = MetaData(bind=engine)
# Erstelle SQLDatabaseChain
query_chain = VectorSQLDatabaseChain.from_llm(
# GPT-3.5 generiert besseres gültiges SQL
llm=OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0),
# Verwende den vordefinierten Anstoß, ändere ihn zu deinem eigenen Anstoß
prompt=PROMPT,
# Gib die 10 relevantesten Dokumente zurück
top_k=10,
# Verwende das Ergebnis direkt aus der Datenbank
return_direct=True,
# Verwende unsere Datenbank für die Abfrage
db=SQLDatabase(engine, None, metadata),
# Konvertiere `NeuralArray()` in Einbettungen
sql_cmd_parser=output_parser)
# Starte die Kette!! Und verfolge alle Kettensprünge in der Standardausgabe
query_chain.run("Stelle einige Papiere vor, die Generative Adversarial Networks verwenden und um 2019 veröffentlicht wurden.",
callbacks=[StdOutCallbackHandler()])
# Frage mit RetrievalQAwithSourcesChain
Du kannst diese VectorSQLDatabaseChain auch als Retriever verwenden. Du kannst sie in einige Retrieval-QA-Ketten einbinden, genau wie andere Retriever in LangChain.
from langchain_experimental.retrievers.vector_sql_database \
import VectorSQLDatabaseChainRetriever
from langchain.chains.qa_with_sources.map_reduce_prompt import combine_prompt_template
OPENAI_API_KEY = "sk-***"
# Definiere, wie du diese strukturierten Daten aus der Datenbank serialisierst
document_with_metadata_prompt = PromptTemplate(
input_variables=["page_content", "id", "title", "authors", "pubdate", "categories"],
template="Inhalt:\n\tTitel: {title}\n\tAbstract: {page_content}\n\t" +
"Autoren: {authors}\n\tVeröffentlichungsdatum: {pubdate}\n\tKategorien: {categories}\nQUELLE: {id}"
)
# Definiere den Anstoß, den du verwendest, um das LLM zu fragen
COMBINE_PROMPT = PromptTemplate(
template=combine_prompt_template, input_variables=["summaries", "question"])
# Definiere einen Retriever mit einer SQLDatabaseChain
retriever = VectorSQLDatabaseChainRetriever(
sql_db_chain=query_chain, page_content_key="abstract")
# Schließlich die Ask-Kette, um all dies zu organisieren
ask_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model_name='gpt-3.5-turbo-16k',
openai_api_key=OPENAI_API_KEY, temperature=0.6),
retriever=retriever,
chain_type='stuff',
chain_type_kwargs={
'prompt': COMBINE_PROMPT,
'document_prompt': document_with_metadata_prompt,
}, return_source_documents=True)
# Führe die Kette aus! und erhalte das Ergebnis vom LLM
ask_chain("Stelle einige Papiere vor, die Generative Adversarial Networks verwenden und um 2019 veröffentlicht wurden.",
callbacks=[StdOutCallbackHandler()])
Wir bieten auch eine Live-Demo auf Huggingface (opens new window) an und der Code ist auf GitHub (opens new window) verfügbar! Wir haben eine angepasste Retrieval-QA-Kette (opens new window) verwendet, um die Leistung unserer Such- und Fragestellungspipeline mit LangChain zu maximieren!
# Zusammenfassung
In der Realität halluzinieren die meisten LLMs. Der praktischste Weg, um ihr Auftreten zu reduzieren, besteht darin, deiner Frage zusätzliche Fakten (externes Wissen) hinzuzufügen. Externes Wissen ist entscheidend, um die Leistung von LLM-Systemen zu verbessern und eine effiziente und genaue Abrufung von Antworten zu ermöglichen. Jedes Wort zählt, und du möchtest dein Geld nicht für ungenutzte Informationen verschwenden, die durch ungenaue Abfragen abgerufen werden.
Wie?
Gib Vector SQL ein, das es dir ermöglicht, fein abgestimmte Vektorsuchen durchzuführen, um die benötigten Informationen gezielt abzurufen.
Vector SQL ist leistungsstark und für Menschen und Maschinen leicht zu erlernen. Du kannst viele Datentypen und Funktionen verwenden, um komplexe Abfragen zu erstellen. LLMs mögen auch Vector SQL, da ihr Trainingssatz viele Referenzen enthält.
Schließlich ist es möglich, Vector SQL in viele Vektordatenbanken mit verschiedenen Einbettungsmodellen zu übersetzen. Wir glauben, dass dies die Zukunft von Vektordatenbanken ist.
Interessierst du dich für das, was wir tun? Tritt noch heute unserem Discord (opens new window) bei!



