
Wie einer unserer früheren Blog-Beiträge (opens new window) bereits erläutert hat, ermöglicht die Vektorsuche eine deutliche Verbesserung der Informationssuche durch einen nuancierteren und kontextbewussteren Ansatz im Vergleich zur traditionellen Schlüsselwortübereinstimmung. Die Umwandlung von Text in numerische Vektoren bringt die kontextuelle Bedeutung von Suchanfragen mit den Daten in Einklang und verbessert dadurch die Relevanz der Suchergebnisse.
Allerdings treten bei der Vektorsuche auch Herausforderungen auf, insbesondere der mögliche Informationsverlust während der Umwandlung von Text in Vektoren, der die Notwendigkeit zusätzlicher Methoden zur Verbesserung der Suchgenauigkeit mit sich bringt.
Was sind diese zusätzlichen Methoden?
Die kurze Antwort auf diese Frage lautet, dass eine der wichtigsten "zusätzlichen Methoden" die Implementierung eines zweistufigen Abfragesystems ist, wenn man die Vektorsuche zur Informationsabfrage verwendet.
Lassen Sie uns diese Antwort erweitern, indem wir einen Schritt-für-Schritt-Leitfaden zur Implementierung einer zweistufigen Abfragetechnik mit MyScale betrachten, der zeigt, wie man Vektorsuche und Reranking effizient und effektiv kombiniert, um Informationssuchsysteme zu optimieren.
# Was ist Reranking?
Aber zuerst wollen wir Reranking definieren und darüber nachdenken, warum es Teil des zweistufigen Abfrageprozesses ist.
Kurz gesagt, ordnet Reranking die Suchergebnisse neu, um die kontextuelle Relevanz einer Vektorsuche zu erhöhen. Laut https://en.wiktionary.org/wiki/reranking (opens new window) handelt es sich dabei um "die erneute oder unterschiedliche Rangfolge... [Zum Beispiel] führt der Algorithmus mehrere Rerankings durch, bevor das optimale Ergebnis erreicht wird."
Reranking, das oft mit einem Cross-Encoder-Modell (opens new window) implementiert wird, verbessert die Suchergebnisse, indem es eine verfeinerte Ergebnismenge liefert. Im Gegensatz zur anfänglichen Vektorsuche, bei der Dokumente zuerst in Vektoren zusammengefasst und dann diese Dokumente abgefragt werden, verarbeitet Reranking die Abfrage und die Dokumente gemeinsam und ordnet die Suchergebnisse basierend auf der Relevanz präziser neu.
Allerdings gibt es auch Herausforderungen bei der Verwendung von Reranking, insbesondere den hohen Rechenaufwand und die daraus resultierende Unpraktikabilität bei der Verarbeitung großer Datensätze, was seine eigenständige Anwendung erheblich einschränkt.
# Das zweistufige Abfragesystem
Um diese Herausforderungen zu bewältigen, wurde ein zweistufiges Abfragesystem entwickelt, das die Stärken der Vektorsuche und des Rerankings kombiniert. Es beginnt mit einer Vektorsuche für eine anfängliche breit angelegte Ergebnismenge und wendet dann selektiv Reranking an, um eine größere Genauigkeit zu erzielen.
# MyScale's zweistufiges Abfragesystem
Das zweistufige Abfragesystem von MyScale beginnt mit einer Vektorsuche, die die Datenbank durchsucht und eine breite Palette von Dokumenten auswählt, die der Semantik der Suchanfrage sehr nahe kommen, und reduziert so effizient den umfangreichen Datensatz auf eine relevante Teilmenge.
Als Nächstes: Diese Teilmenge wird mithilfe einer Reranking-Funktion verfeinert, die sie basierend auf Ähnlichkeitswerten sorgfältig sortiert, um Präzision zu priorisieren und das endgültige Ergebnis so nah wie möglich an die Absicht des Benutzers anzupassen.
Um dieses zweistufige Abfragesystem zu optimieren, haben wir diese Reranking-Funktionen (opens new window) in MyScale integriert - unsere Vektordatenbank - und sie über eine einfache SQL-Abfrage zugänglich gemacht.
Hinweis:
Diese Funktionen nutzen anspruchsvolle Reranking-APIs und bieten Benutzern eine benutzerfreundliche Schnittstelle für komplexe Sortieroperationen von Daten sowie eine kompakte und effiziente Benutzererfahrung für eine robuste Suchfunktionalität.
Wie im folgenden Diagramm dargestellt, können Benutzer diesen zweistufigen Abfrage-Mechanismus mit einem einfachen Befehl starten, der eine Vektorsuche-Unterabfrage enthält, um die Top-N-Dokumente zurückzugeben, und eine Reranking-Abfrage, um diesen Ergebnissatz weiter zu verfeinern und die relevantesten K-Dokumente zu extrahieren.
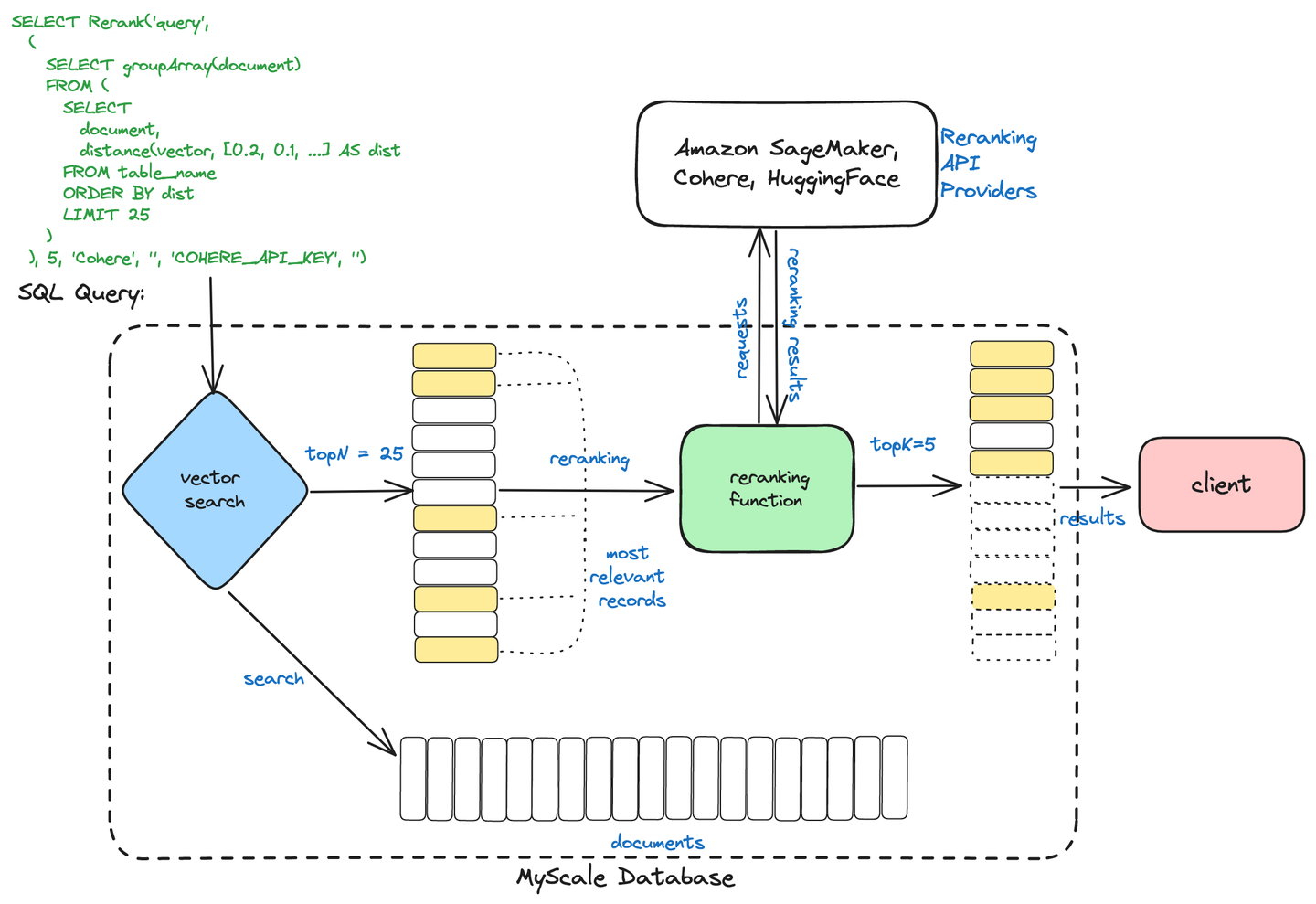
Die Effektivität dieses Systems zeigt sich in seinen Leistungsmetriken. Unter Verwendung von OpenAI Embeddings (opens new window) für die Analyse haben wir eine signifikante Verbesserung der Abfragegenauigkeit festgestellt. Die Trefferquote stieg von 0,854545 auf 0,895455 bei Verwendung des Modells bge-reranker-base. Der Mean Reciprocal Rank - MRR - stieg ebenfalls von 0,640303 auf 0,707652, was die Effizienz der Methode bei der Suche nach relevanten Suchergebnissen zeigt. Diese Verbesserungen unterstreichen den Wert der Integration von Reranking in den Informationsabfrageprozess.
Hinweis:
Unsere Evaluierungsmethodik und Ergebnisse haben wir in diesem Notebook (opens new window) detailliert beschrieben, basierend auf den in diesem Blog (opens new window) von LlamaIndex diskutierten Methoden.
# Implementierung des zweistufigen Abfragesystems von MyScale
Lassen Sie uns nun anhand eines praktischen Beispiels das zweistufige Abfragesystem besser verstehen, indem wir uns auf die Verbesserung der Abstractive QA (opens new window) Beispielanwendung konzentrieren, wie sie in der MyScale-Dokumentation beschrieben ist.
Hinweis:
Die einzige erforderliche Änderung betrifft die Abfragephase (opens new window) des ursprünglichen Beispiels - wir verwenden immer noch dieselbe Tabelle und dieselben Daten.
Die ursprüngliche Abstractive QA-App wandelt Fragen mithilfe eines separaten Retrievers in Embeddings um. Anschließend führt sie eine Suchabfrage aus, um die Top_k-Kandidaten zu finden. Nun, wie der folgende SQL-Befehl zeigt, werden diese Schritte mit der Embedding-Funktion von MyScale in einem einzigen SQL-Befehl zusammengeführt.
SELECT summary,
distance(
summary_feature,
CohereEmbedText('what is the difference between bitcoin and traditional money?')
) AS dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist LIMIT 10
Dieser SQL-Befehl verwendet eine benutzerdefinierte Embedding-Funktion - CohereEmbedText - die mit dem Cohere embed-english-light-v3.0 Modell (opens new window) erstellt wurde und im folgenden Code-Snippet definiert ist.
CREATE FUNCTION CohereEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(
x,
'Cohere',
'',
'YOUR_COHERE_API_KEY',
'{"model":"embed-english-light-v3.0", "input_type":"search_query"}')
Um den Prozess weiter zu optimieren, führen wir eine benutzerdefinierte Reranking-Funktion ein, wie in der Funktionsdokumentation (opens new window) beschrieben:
CREATE FUNCTION CohereRerank ON CLUSTER '{cluster}'
AS (x,y,z) -> Rerank(
x, y, z, 'Cohere', '', 'YOUR_COHERE_API_KEY', '');
Mit diesen Funktionen können wir nun das zweistufige Abfragesystem mit dem folgenden SQL-Befehl implementieren:
SELECT
tupleElement(arrayElement, 2) AS summary,
tupleElement(arrayElement, 3) AS score
FROM (
SELECT arrayJoin(CohereRerank('what is the difference between bitcoin and traditional money?',
(SELECT groupArray(summary)
FROM (
SELECT summary, distance(summary_feature, CohereEmbedText('what is the difference between bitcoin and traditional money?')) as dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist
LIMIT 50
)
), 10
)) AS arrayElement
)
Dieser SQL-Befehl umfasst die folgenden Schritte zur Implementierung unseres zweistufigen Abfragesystems:
- Erweitern Sie die Suchergebnisse von 10 auf 50, um relevante Informationen nicht zu übersehen;
- Gruppieren Sie die Top 50 Kandidaten in einem Array - für das Reranking - mit Hilfe von groupArray (opens new window);
- Ordnen Sie diese Kandidaten basierend auf der Relevanz mit der Funktion
CohereRerankneu und extrahieren Sie die 10 relevantesten Zusammenfassungen; und schließlich - Verwenden Sie arrayJoin (opens new window) (um den Ergebnissatz in mehrere Zeilen zu entfalten) und tupleElement (opens new window) (um eine bestimmte Spalte aus den Ergebniszeilen zu extrahieren), um die Ergebnisse zu strukturieren und die Benutzerpräsentation zu verbessern.

# Fazit
Zusammenfassend zeigt das zweistufige Abfragesystem von MyScale die Kraft von Einfachheit und Effizienz in der modernen Suchtechnologie. Es zeigt, dass selbst komplexe Prozesse wie die Vektorsuche in Kombination mit fortschrittlichen Reranking-Funktionen nahtlos mit einer einzigen, einfachen SQL-Abfrage ausgeführt werden können. Dieser Ansatz macht komplexe Abfrageprozesse nicht nur für eine breitere Benutzergruppe zugänglich, sondern unterstreicht auch MyScale's Engagement für leistungsstarke, aber benutzerfreundliche Daten-Such- und Analysetools.



