
Retrieval-Augmented Generation (RAG) (opens new window) Systeme wurden entwickelt, um die Antwortqualität eines großen Sprachmodells (LLM) zu verbessern. Wenn ein Benutzer eine Abfrage stellt, extrahiert das RAG-System relevante Informationen aus einer Vektordatenbank und gibt sie als Kontext an das LLM weiter. Das LLM verwendet diesen Kontext dann, um eine Antwort für den Benutzer zu generieren. Dieser Prozess verbessert signifikant die Qualität der LLM-Antworten mit weniger „Halluzinationen“ (opens new window).
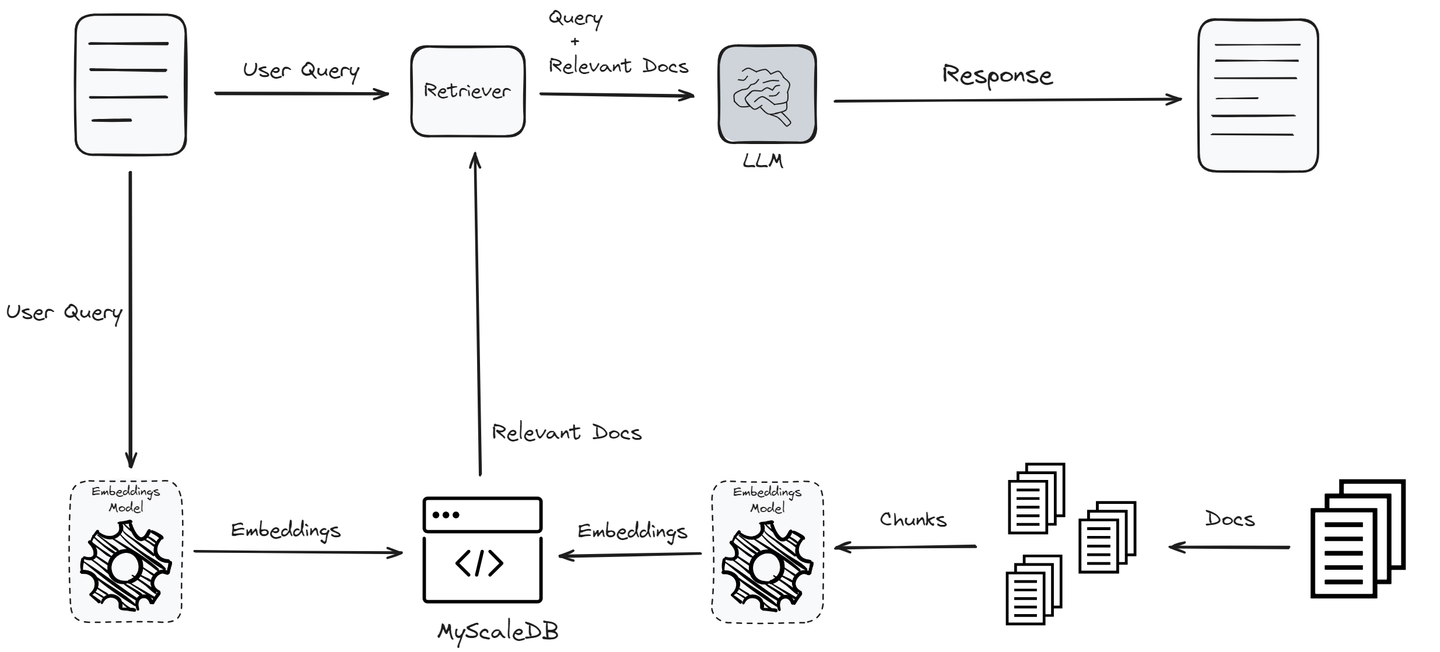
In dem oben gezeigten Workflow gibt es zwei Hauptkomponenten in einem RAG-System:
Retriever: Er identifiziert die relevantesten Informationen aus der Vektordatenbank mithilfe der Leistung der Ähnlichkeitssuche. Diese Phase ist der wichtigste Teil eines RAG-Systems, da sie die Grundlage für die Qualität der endgültigen Ausgabe bildet. Der Retriever durchsucht eine Vektordatenbank, um Dokumente zu finden, die für die Benutzerabfrage relevant sind. Dabei werden die Abfrage und die Dokumente in Vektoren codiert und Ähnlichkeitsmaße verwendet, um die besten Übereinstimmungen zu finden.
Antwortgenerator: Sobald die relevanten Dokumente abgerufen wurden, werden die Benutzerabfrage und die abgerufenen Dokumente an das LLM-Modell übergeben, um eine kohärente, relevante und informative Antwort zu generieren. Der Generator (LLM) verwendet den vom Retriever bereitgestellten Kontext und die ursprüngliche Abfrage, um eine genaue Antwort zu generieren.
Die Effektivität und Leistung eines RAG-Systems hängen wesentlich von diesen beiden Kernkomponenten ab: dem Retriever und dem Generator. Der Retriever muss effizient die relevantesten Dokumente identifizieren und abrufen, während der Generator unter Verwendung der abgerufenen Informationen Antworten erzeugen sollte, die kohärent, relevant und genau sind. Eine gründliche Bewertung dieser Komponenten ist entscheidend, um eine optimale Leistung und Zuverlässigkeit des RAG-Modells vor der Bereitstellung sicherzustellen.
# Bewertung von RAG
Zur Bewertung eines RAG-Systems verwenden wir in der Regel zwei Arten von Bewertungen:
- Rückgewinnungsbewertung
- Antwortbewertung
Im Gegensatz zu traditionellen maschinellen Lernverfahren, bei denen es gut definierte quantitative Metriken gibt (wie Gini, R-Quadrat, AIC, BIC, Verwirrungsmatrix usw.), ist die Bewertung von RAG-Systemen komplexer. Diese Komplexität ergibt sich daraus, dass die von RAG-Systemen generierten Antworten unstrukturierter Text sind und eine Kombination aus qualitativen und quantitativen Metriken erfordern, um ihre Leistung genau zu bewerten.
# TRIAD-Framework
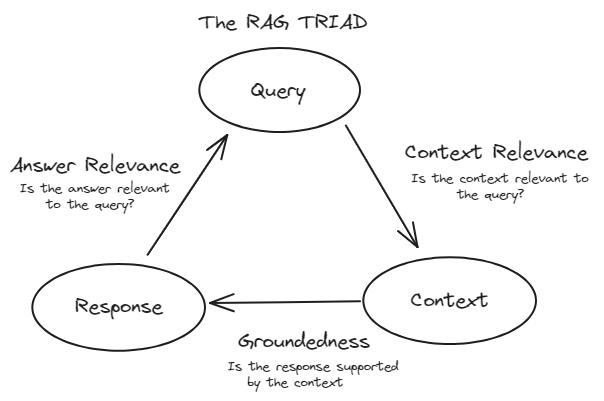
Zur effektiven Bewertung von RAG-Systemen folgen wir in der Regel dem TRIAD-Framework. Dieses Framework besteht aus drei Hauptkomponenten:
Kontextrelevanz: Diese Komponente bewertet den Rückgewinnungsteil des RAG-Systems. Sie bewertet, wie genau die Dokumente aus dem großen Datensatz abgerufen wurden. Hier werden Metriken wie Präzision, Recall, MRR und MAP verwendet.
Treue (Bodenständigkeit): Diese Komponente fällt unter die Antwortbewertung. Sie überprüft, ob die generierte Antwort faktisch korrekt und auf den abgerufenen Dokumenten basiert. Methoden wie die menschliche Bewertung, automatisierte Faktenprüfungswerkzeuge und Konsistenzprüfungen werden verwendet, um die Treue zu bewerten.
Antwortrelevanz: Dies ist ebenfalls Teil der Antwortbewertung. Es misst, wie gut die generierte Antwort die Benutzerabfrage beantwortet und nützliche Informationen liefert. Metriken wie BLEU, ROUGE, METEOR und embeddingsbasierte Bewertungen werden verwendet.
# Rückgewinnungsbewertung
Rückgewinnungsbewertungen werden auf die Retriever-Komponente eines RAG-Systems angewendet, das in der Regel eine Vektordatenbank verwendet. Diese Bewertungen messen, wie effektiv der Retriever relevante Dokumente in Reaktion auf eine Benutzerabfrage identifiziert und einstuft. Das Hauptziel der Rückgewinnungsbewertungen besteht darin, die Kontextrelevanz zu bewerten - wie gut die abgerufenen Dokumente mit der Benutzerabfrage übereinstimmen. Dies stellt sicher, dass der Generation-Komponente ein relevanter und genauer Kontext bereitgestellt wird.

Jede der Metriken bietet eine einzigartige Perspektive auf die Qualität der abgerufenen Dokumente und trägt zu einem umfassenden Verständnis der Kontextrelevanz bei.
# Präzision
Die Präzision misst die Genauigkeit der abgerufenen Dokumente. Sie ist das Verhältnis der Anzahl der relevanten abgerufenen Dokumente zur Gesamtzahl der abgerufenen Dokumente. Sie wird definiert als:
Das bedeutet, dass die Präzision bewertet, wie viele der vom System abgerufenen Dokumente tatsächlich relevant für die Benutzerabfrage sind. Zum Beispiel, wenn der Retriever 10 Dokumente abruft und 7 davon relevant sind, beträgt die Präzision 0,7 oder 70%.
Die Präzision bewertet: "Von allen Dokumenten, die das System abgerufen hat, wie viele waren tatsächlich relevant?"
Die Präzision ist besonders wichtig, wenn das Präsentieren irrelevanter Informationen negative Folgen haben kann. Zum Beispiel ist eine hohe Präzision in einem medizinischen Informationssuchsystem entscheidend, da das Bereitstellen irrelevanter medizinischer Dokumente zu Fehlinformationen und potenziell schädlichen Ergebnissen führen könnte.
# Recall
Der Recall misst die Vollständigkeit der abgerufenen Dokumente. Er ist das Verhältnis der Anzahl der relevanten abgerufenen Dokumente zur Gesamtzahl der relevanten Dokumente in der Datenbank für die gegebene Abfrage. Er wird definiert als:
Das bedeutet, dass der Recall bewertet, wie viele der relevanten Dokumente, die in der Datenbank vorhanden sind, erfolgreich vom System abgerufen wurden.
Der Recall bewertet: "Von allen relevanten Dokumenten, die in der Datenbank vorhanden sind, wie viele hat das System erfolgreich abgerufen?"
Der Recall ist entscheidend in Situationen, in denen das Verpassen relevanter Informationen kostspielig sein kann. Zum Beispiel ist ein hoher Recall in einem rechtlichen Informationssuchsystem unerlässlich, da das Versäumnis, ein relevantes rechtliches Dokument abzurufen, zu unvollständiger Fallrecherche führen und potenziell den Ausgang rechtlicher Verfahren beeinflussen könnte.
# Balance zwischen Präzision und Recall
Die Balance zwischen Präzision und Recall ist oft notwendig, da die Verbesserung einer Metrik manchmal die andere verringern kann. Das Ziel besteht darin, ein optimales Gleichgewicht zu finden, das den spezifischen Anforderungen der Anwendung entspricht. Dieses Gleichgewicht wird manchmal mit dem F1-Score quantifiziert, der das harmonische Mittel aus Präzision und Recall ist:
# Mean Reciprocal Rank (MRR)
Der Mean Reciprocal Rank (MRR) ist eine Metrik, die die Effektivität des Rückgewinnungssystems bewertet, indem sie die Rangposition des ersten relevanten Dokuments berücksichtigt. Er ist besonders nützlich, wenn nur das erste relevante Dokument von primärem Interesse ist. Der Reciprocal Rank ist das Inverse des Rangs, an dem das erste relevante Dokument gefunden wird. MRR ist der Durchschnitt dieser reziproken Ränge über mehrere Abfragen. Die Formel für MRR lautet:
Dabei ist Q die Anzahl der Abfragen und
Der MRR bewertet: "Im Durchschnitt wie schnell wird das erste relevante Dokument in Reaktion auf eine Benutzerabfrage abgerufen?"
Zum Beispiel ist der MRR in einem RAG-basierten Frage-Antwort-System entscheidend, da er widerspiegelt, wie schnell das System die richtige Antwort dem Benutzer präsentieren kann. Wenn die richtige Antwort häufiger an erster Stelle erscheint, wird der MRR-Wert höher sein, was auf ein effektiveres Rückgewinnungssystem hinweist.
# Mean Average Precision (MAP)
Die Mean Average Precision (MAP) ist eine Metrik, die die Präzision der Rückgewinnung über mehrere Abfragen bewertet. Sie berücksichtigt sowohl die Präzision der Rückgewinnung als auch die Reihenfolge der abgerufenen Dokumente. MAP wird als Durchschnitt der durchschnittlichen Präzisionsscores für eine Reihe von Abfragen definiert. Um die durchschnittliche Präzision für eine einzelne Abfrage zu berechnen, wird die Präzision an jeder Position in der Rangliste der abgerufenen Dokumente berechnet, wobei nur die top-K abgerufenen Dokumente berücksichtigt werden, wobei jede Präzision gewichtet wird, ob das Dokument relevant ist oder nicht. Die Formel für MAP über mehrere Abfragen lautet:
Dabei ist ( Q ) die Anzahl der Abfragen und
MAP bewertet: "Im Durchschnitt wie präzise sind die am besten gerankten Dokumente, die vom System über mehrere Abfragen abgerufen wurden?"
Zum Beispiel ist MAP in einer RAG-basierten Suchmaschine entscheidend, da sie die Präzision der Rückgewinnung an verschiedenen Rängen berücksichtigt und sicherstellt, dass relevante Dokumente in den Suchergebnissen weiter oben erscheinen, was die Benutzererfahrung verbessert, indem relevante Informationen zuerst präsentiert werden.
# Eine Übersicht über die Rückgewinnungsbewertungen
- Präzision: Qualität der abgerufenen Ergebnisse.
- Recall: Vollständigkeit der abgerufenen Ergebnisse.
- MRR: Wie schnell das erste relevante Dokument abgerufen wird.
- MAP: Umfassende Bewertung, die Präzision und Rang der relevanten Dokumente kombiniert.
# Antwortbewertung
Antwortbewertungen werden auf die Generierungskomponente eines Systems angewendet. Diese Bewertungen messen, wie effektiv das System Antworten auf der Grundlage des vom abgerufenen Dokumenten bereitgestellten Kontexts generiert. Wir unterteilen Antwortbewertungen in zwei Arten:
- Treue (Bodenständigkeit)
- Antwortrelevanz
# Treue (Bodenständigkeit)
Die Treue bewertet, ob die generierte Antwort korrekt und auf den abgerufenen Dokumenten basiert. Sie stellt sicher, dass die Antwort keine Halluzinationen oder falsche Informationen enthält. Diese Metrik ist entscheidend, da sie die generierte Antwort auf ihre Quelle zurückverfolgt und sicherstellt, dass die Informationen auf einer überprüfbaren Wahrheit beruhen. Die Treue hilft, Halluzinationen zu verhindern, bei denen das System plausibel klingende, aber faktisch falsche Antworten generiert.
Zur Messung der Treue werden häufig folgende Methoden verwendet:
- Menschliche Bewertung: Experten bewerten manuell, ob die generierten Antworten faktisch korrekt und korrekt auf den abgerufenen Dokumenten referenziert sind. Dieser Prozess umfasst das Überprüfen jeder Antwort anhand der Quelldokumente, um sicherzustellen, dass alle Behauptungen belegt sind.
- Automatisierte Faktenprüfungswerkzeuge: Diese Werkzeuge vergleichen die generierte Antwort mit einer Datenbank verifizierter Fakten, um Ungenauigkeiten zu identifizieren. Sie bieten eine automatisierte Möglichkeit, die Gültigkeit der Informationen ohne menschliches Eingreifen zu überprüfen.
- Konsistenzprüfungen: Diese bewerten, ob das Modell konsistent dieselben faktischen Informationen für verschiedene Abfragen liefert. Dadurch wird sichergestellt, dass das Modell zuverlässig ist und keine widersprüchlichen Informationen liefert.
# Antwortrelevanz
Die Antwortrelevanz misst, wie gut die generierte Antwort die Benutzerabfrage beantwortet und nützliche Informationen liefert.
# BLEU (Bilingual Evaluation Understudy)
BLEU misst die Überschneidung zwischen der generierten Antwort und einer Reihe von Referenzantworten und konzentriert sich auf die Präzision von n-Grammen. Es wird berechnet, indem die Überschneidung von n-Grammen (zusammenhängenden Sequenzen von n Wörtern) zwischen der generierten und den Referenzantworten gemessen wird. Die Formel für den BLEU-Score lautet:
Dabei ist ( BP ) die Kürzungspenalty, um kurze Antworten zu bestrafen, ( P_n ) die Präzision der n-Gramme und ( w_n ) sind die Gewichte für jede n-Gramm-Ebene. BLEU misst quantitativ, wie eng die generierte Antwort der Referenzantwort entspricht.
# ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE misst die Überschneidung von n-Grammen, Wortsequenzen und Wortpaaren zwischen der generierten und den Referenzantworten und berücksichtigt sowohl Recall als auch Präzision. Die häufigste Variante, ROUGE-N, misst die Überschneidung von n-Grammen zwischen der generierten und den Referenzantworten. Die Formel für ROUGE-N lautet:
ROUGE bewertet sowohl die Präzision als auch den Recall und liefert eine ausgewogene Messung dafür, wie viel relevanter Inhalt von der Referenz in der generierten Antwort vorhanden ist.
# METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR berücksichtigt Synonymie, Stemming und Wortreihenfolge, um die Ähnlichkeit zwischen der generierten Antwort und den Referenzantworten zu bewerten. Die Formel für den METEOR-Score lautet:
Dabei ist $ F_{\text{mean}}$ das harmonische Mittel aus Präzision und Recall und
# Embedding-basierte Bewertung
Diese Methode verwendet Vektorrepräsentationen von Wörtern (Embeddings), um die semantische Ähnlichkeit zwischen der generierten Antwort und den Referenzantworten zu messen. Techniken wie die Kosinusähnlichkeit werden verwendet, um die Embeddings zu vergleichen und eine Bewertung auf der Bedeutung der Wörter anstelle ihrer exakten Übereinstimmung zu basieren.

# Tipps und Tricks zur Optimierung von RAG-Systemen
Es gibt einige grundlegende Tipps und Tricks, die Sie verwenden können, um Ihre RAG-Systeme zu optimieren:
- Verwenden Sie Re-Ranking-Techniken: Re-Ranking ist die am häufigsten verwendete Technik, um die Leistung eines RAG-Systems zu optimieren. Es nimmt die anfängliche Menge der abgerufenen Dokumente und rangiert die relevantesten basierend auf ihrer Ähnlichkeit weiter. Mit Techniken wie Cross-Encodern und BERT-basierten Re-Rankern können wir die Relevanz der Dokumente genauer bewerten. Dadurch wird sichergestellt, dass die Dokumente, die dem Generator bereitgestellt werden, kontextuell reichhaltig und hochrelevant sind, was zu besseren Antworten führt.
- Stimmen Sie Hyperparameter ab: Durch regelmäßiges Abstimmen von Hyperparametern wie Chunk-Größe, Überlappung und Anzahl der abgerufenen Top-Dokumente können Sie die Leistung der Rückgewinnungskomponente optimieren. Durch Experimentieren mit verschiedenen Einstellungen und Bewertung ihrer Auswirkungen auf die Qualität der Rückgewinnung können Sie die Gesamtleistung des RAG-Systems verbessern.
- Embedding-Modelle: Die Auswahl eines geeigneten Embedding-Modells ist entscheidend für die Optimierung der Rückgewinnungskomponente eines RAG-Systems. Das richtige Modell, ob allgemein oder domänenspezifisch, kann die Fähigkeit des Systems, relevante Informationen genau darzustellen und abzurufen, erheblich verbessern. Durch die Auswahl eines Modells, das zu Ihrem spezifischen Anwendungsfall passt, können Sie die Präzision von Ähnlichkeitssuchen und die Gesamtleistung Ihres RAG-Systems verbessern. Berücksichtigen Sie Faktoren wie die Trainingsdaten des Modells, die Dimensionalität und Leistungsmetriken bei Ihrer Auswahl.
- Chunking-Strategien: Durch die Anpassung von Chunk-Größen und Überlappungen kann die Leistung von RAG-Systemen erheblich verbessert werden, indem mehr relevante Informationen für das LLM erfasst werden. Zum Beispiel teilt die semantische Chunking von Langchain Dokumente basierend auf Semantik auf, wodurch jeder Chunk kontextuell kohärent ist. Adaptive Chunking-Strategien, die je nach Dokumententypen variieren (wie PDFs, Tabellen und Bilder), können dazu beitragen, mehr kontextuell angemessene Informationen beizubehalten.
# Rolle von Vektordatenbanken in RAG-Systemen
Vektordatenbanken sind integraler Bestandteil der Leistung von RAG-Systemen. Wenn ein Benutzer eine Abfrage stellt, nutzt die Retriever-Komponente des RAG-Systems die Vektordatenbank, um die relevantesten Dokumente basierend auf der Vektorsimilarität zu finden. Dieser Prozess ist entscheidend, um dem Sprachmodell den richtigen Kontext für die Generierung genauer und relevanter Antworten zu liefern. Eine robuste Vektordatenbank gewährleistet eine schnelle und präzise Rückgewinnung und beeinflusst direkt die Gesamtwirksamkeit und Reaktionsfähigkeit des RAG-Systems.
MyScaleDB (opens new window) ist eine SQL-Vektordatenbank, die auf der leistungsstarken ClickHouse (opens new window)-Datenbank aufbaut. ClickHouse bietet fortschrittliche Funktionen zur Datenverarbeitung wie spaltenorientierten Speicher und vektorisierte Abfrageausführung. Der proprietäre Multi-Scale Tree Graph (MSTG)-Algorithmus von MyScale hat mit dem LAION 5M-Datensatz eine Leistung von 390 QPS (Abfragen pro Sekunde) erreicht, eine 95% Recall-Rate erzielt und eine durchschnittliche Abfrage-Latenz von 18 ms mit dem s1.x1-Pod beibehalten. Dieser einzigartige Algorithmus verbessert die Indizierung und Sucheffizienz, indem er hierarchisches Baumclustering mit Graphtraversierungstechniken kombiniert und dadurch schneller und genauer ist. MSTG reduziert auch den Ressourcenverbrauch und beschleunigt Suchoperationen im Vergleich zu traditionellen Methoden wie HNSW (Hierarchical Navigable Small World) und IVF (Inverted File). Darüber hinaus ermöglicht die Kompatibilität von MyScaleDB mit SQL und ihre leistungsstarken Vektorsuchfunktionen Entwicklern eine einfache Integration in bestehende Workflows, wobei vertraute SQL-Abfragen für komplexe Vektoroperationen verwendet werden.
# Fazit
Die Entwicklung eines RAG-Systems ist an sich nicht schwierig, aber die Bewertung von RAG-Systemen ist entscheidend, um die Leistung zu messen, kontinuierliche Verbesserungen zu ermöglichen, sich an Geschäftsziele anzupassen, Kosten auszugleichen, Zuverlässigkeit sicherzustellen und sich an neue Methoden anzupassen. Dieser umfassende Bewertungsprozess hilft dabei, ein robustes, effizientes und benutzerzentriertes RAG-System aufzubauen.
Indem sie diese wichtigen Aspekte berücksichtigen, dienen Vektordatenbanken als Grundlage für leistungsstarke RAG-Systeme, die genaue, relevante und zeitnahe Antworten liefern und gleichzeitig große, komplexe Daten effizient verwalten können. MyScaleDB ist mit dem proprietären MSTG-Algorithmus, SQL und Vektor-Joint-Abfragen ausgestattet, die die Leistung von RAG-Systemen erheblich verbessern können. Dadurch ist MyScaleDB eine ausgezeichnete Wahl für den Aufbau von RAG-Systemen.



