
Traditionell kann maschinelles Lernen (ML) (opens new window) grob in zwei Arten unterteilt werden: überwachtes und unüberwachtes Lernen (opens new window). Beim überwachten Lernen haben wir einige Daten mit Labels, und diese Labels werden verwendet, um das Modell zu trainieren. Zum Beispiel werden mit Hilfe von (beschrifteten) Bildern verschiedener Objekte ein Bildklassifizierer trainiert.
Beim unüberwachten Lernen hingegen sind keine Labels erforderlich, und hier erkunden wir die Muster ohne jegliche vorherige Informationen. Es ist zweifellos schwierig, aber auch faszinierend. Mit Tonnen von verfügbaren Daten (und neuen Daten, die jeden Tag produziert werden), ist es immer einfach, an die Daten zu gelangen, obwohl das Labeln viel Zeit und Geld erfordert.
Um die riesigen Datenmengen um uns herum zu nutzen, gibt es eine fortgeschrittene Lernstrategie, die als selbstüberwachtes Lernen bekannt ist. Beim selbstüberwachten Lernen nehmen wir die unbeschrifteten Daten und ahmen das überwachte Lernen nach.
# Selbstüberwachtes Lernen (SSL)
Beim selbstüberwachten Lernen teilen wir die Daten in positive und negative Beispiele auf - ähnlich wie bei der binären (überwachten) Klassifizierung - indem wir das betrachtete Objekt als positives Beispiel und alle anderen Beispiele als negativ behandeln.
Methoden des selbstüberwachten Lernens lernen gemeinsame Einbettungen und können grob in zwei Arten unterteilt werden:
- Kontrastive Methoden
- Nicht-kontrastive Methoden
Bei kontrastiven Methoden nehmen wir verschiedene Beispiele der gleichen Daten, wie verschiedene Ansichten des gleichen Bildes, und versuchen, ihre Ähnlichkeitswerte zu maximieren, während wir sie für die anderen Beispiele/Bilder minimieren. Nicht-kontrastive Methoden berücksichtigen hingegen keine negativen Beispiele. Einige der bekannten SSL-Methoden wie BYOL oder DINO sind gute Beispiele für nicht-kontrastive Methoden, während SimCLR und MoCo auch negative Beispiele verwenden und gute Beispiele für kontrastive Methoden sind.
# Kontrastives Lernen (CL)
Das kontrastive Lernen dreht sich um das einfache Konzept, eine Repräsentation zu wählen, die die Ähnlichkeiten zwischen positiven Datenpaaren maximiert, während sie für negative Paare minimiert wird. Zum Beispiel gebe ich ein Bild einer Mango ein, und nun sollte das Ziel sein, die Ähnlichkeit zwischen Mangobildern zu maximieren, während sie für andere Bilder minimiert wird.
Die einfachste Einstellung besteht darin, jeden Datenpunkt (bei seiner Betrachtung) als positiven Datenpunkt zu betrachten, während alle anderen als negativen Punkt betrachtet werden. Nehmen wir an, der Punkt ist
# Training
Für jedes Paar von Datenpunkten
Um das Training praktischer zu gestalten, führen wir es in Batches durch. Angenommen, wir haben einen Batch mit 32 Bildern, dann muss 1 Bild (es selbst) einen maximierten Ähnlichkeitswert haben, während die anderen 31 so weit wie möglich einen minimierten Ähnlichkeitswert haben müssen.
Da es jedoch schwierig ist, anhand eines einzelnen positiven Beispiels gegen eine Reihe von negativen Beispielen diskriminative Merkmale zu lernen, verwenden wir einige clevere Techniken wie Datenaugmentation, um mehrere Kopien desselben Datenpunkts zu erstellen.
# Beispiele für CL
Das kontrastive Lernen gibt es schon seit einiger Zeit. In den letzten 10 Jahren hat es sich von der normalen CNN-basierten (opens new window) Bildunterscheidung (die sich nur darüber freute, SIFT zu übertreffen) bis hin zu CLIP weiterentwickelt. Einige der modernen CL-Algorithmen sind:
- Kontrastive Vorhersagekodierung, CPC
- Ein einfacher Rahmen für das kontrastive Lernen von (visuellen) Repräsentationen, SimCLR
- Momentum-Kontrast, MoCo
- Kontrastives Sprach-Bild-Vortraining, CLIP
Lassen Sie uns sie kurz durchgehen, um eine bessere Vorstellung davon zu bekommen, wie kontrastives Lernen praktisch angewendet wird.
# Kontrastive Vorhersagekodierung
Inspiriert von der klassischen Datenkompressionstechnik der Vorhersagekodierung und ihrer Anpassung in der Neurowissenschaft versucht CPC (Kontrastive Vorhersagekodierung) (opens new window), sich auf die hochrangigen Informationen in den Daten zu konzentrieren und das Niederpegelrauschen zu ignorieren.
CPC funktioniert im Wesentlichen wie folgt:
- Hochdimensionale Daten werden in einen geeigneten latenten Einbettungsraum komprimiert. Diese Kompression erleichtert die Modellierung der Daten und die entsprechenden Vorhersagen.
- Vorhersagen werden im gewählten Einbettungsraum gemacht.
- Das Modell wird mit der Noise-Contrastive Estimation (NCE)-Verlustfunktion trainiert.
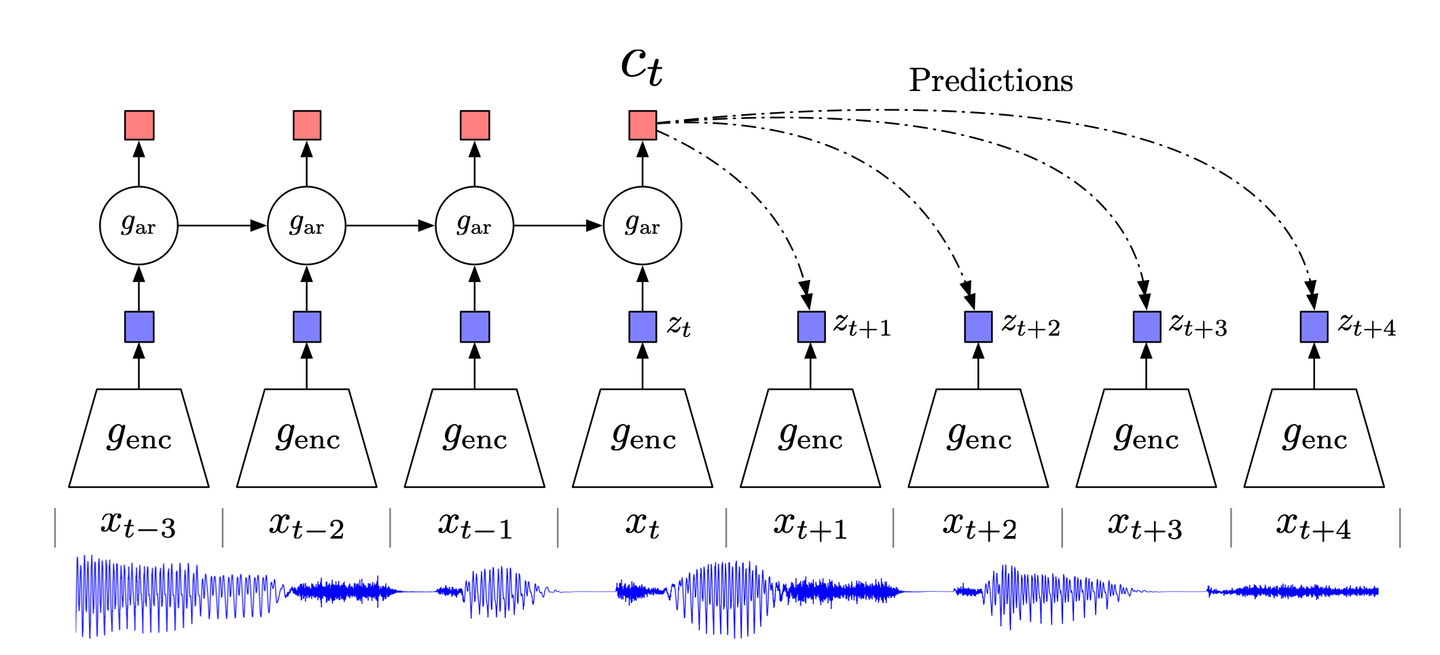
# SimCLR
Ein einfacher Rahmen für das kontrastive Lernen visueller Repräsentationen, SimCLR ist eine fortschrittliche kontrastive Lernmethode für Computer Vision. Ohne dass eine Vor-Augmentation oder spezialisierte Architektur erforderlich ist, funktioniert SimCLR wie folgt:
- Ein Bild wird zufällig ausgewählt, und seine Ansichten (zwei in der Originalimplementierung) werden mit verschiedenen Augmentationstechniken wie zufälligem Zuschneiden, zufälliger Farbverzerrung oder Gaußscher Unschärfe erzeugt.
- Die Bildrepräsentation/Einbettung wird mithilfe eines auf ResNet basierenden CNN berechnet.
- Diese Repräsentation wird weiter in eine (nichtlineare) Projektion mithilfe eines MLP transformiert.
- Sowohl das CNN als auch das MLP werden trainiert, um die kontrastive Verlustfunktion zu minimieren.
Bisher haben wir über die Notwendigkeit des unüberwachten Lernens gesprochen, aber wir haben auch einige beschriftete Daten zur Verfügung. Wenn wir das CNN am Ende auf einigen beschrifteten Bildern feinabstimmen, hilft dies, die Leistung und Verallgemeinerung auf verschiedene andere (nachgelagerte) Aufgaben zu verbessern.
Einige Erkenntnisse darüber, wie kontrastives Lernen funktioniert
SimCLR hat nicht nur ein neues Modell mit sehr guter Leistung eingeführt (Sie können das Papier für eine detaillierte Ergebnisanalyse überprüfen), sondern die Autoren haben auch einige neue Erkenntnisse gegeben, die für nahezu jede kontrastive Lernmethode nützlich sein können. Daher halte ich es für sinnvoll, sie hier zu teilen:
Eine Kombination von Augmentationstechniken ist entscheidend: Zufälliges Zuschneiden und Farbverzerrung ergaben keine herausragenden Ergebnisse, wenn sie einzeln verwendet wurden, aber wenn sie in Kombination verwendet wurden, erzielten sie die besten Ergebnisse.
Nichtlineare Projektion ist wichtig: Die komplexe Natur von neuronalen Netzwerken und der kontrastiven Verlustfunktion bedeutet, dass es schwer zu verstehen ist, was hinter den Kulissen passiert, aber empirisch ist klar, dass die nichtlineare Projektion (durch MLP) nützlich ist, da sie die Leistung um bis zu 10% erhöht. Diese Tatsache wird auch in der Veröffentlichung von MoCov2 unabhängig davon beobachtet, wie wir gleich sehen werden.
Skalierung verbessert die Leistung: Während einige der Beobachtungen spezifisch für SimCLR sind, sind sie hauptsächlich allgemein für kontrastives Lernen. Eine Erhöhung der Kapazität des Modells (entweder Breite oder Tiefe), eine Erhöhung der Batch-Größe oder sogar die Anzahl der Epochen führen alle zu einer Leistungssteigerung.
# Momentum-Kontrast (MoCo)
Momentum-Kontrast (MoCo) betrachtet das kontrastive Lernen als ein Wörterbuch-Lookup aus einer alternativen Perspektive. Dieser interessante Standpunkt, der einige Ähnlichkeiten mit den Transformer-Modellen aufweist, funktioniert wie folgt:
- Datenaugmentation wird angewendet, um zwei Kopien,
- Der Query-Encoder (links im Bild) nimmt
- Der Momentum-Encoder nimmt die andere augmentierte Kopie,
Um es relevant zu machen, wird es als Warteschlange implementiert, die
- Der codierte Query,
- Beide Encoder werden gemeinsam trainiert, um diesen kontrastiven Verlust zu minimieren.
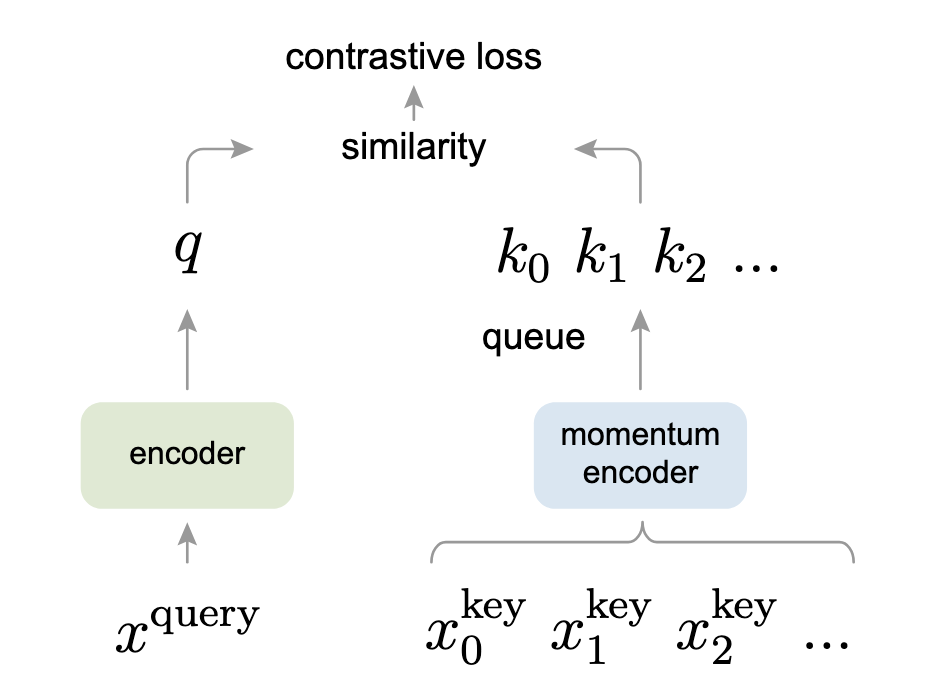
Wenn Sie mit den Transformern vertraut sind, können Sie sehen, dass der InfoNCE-Verlust dem Vorgehen ähnelt, wie wir die Aufmerksamkeit in den Transformern berechnen.
# CLIP
CLIP, das 2021 eingeführt wurde, erhöht den Einsatz, indem es sowohl Bilder als auch ihre Bildunterschriften kombiniert. Obwohl es nicht auf einer momentumbasierten Durchschnittsberechnung basiert, arbeitet es auch mit zwei Encodern, einem für Text und einem für Bilder. Hier ist sein kurzer Workflow:
- Das Bild wird in den Bildencoder eingegeben und seine Bildunterschrift wird in den Textencoder eingegeben.
- Der Bildencoder, basierend auf einem ViT (Vision Transformer), erhält die Bild-Einbettung, während der Textencoder die Bildunterschrift tokenisiert, um die Textmerkmale zu erhalten. Diese Merkmale werden als Paar im Einbettungsraum zusammengeführt.
- Sowohl der Text- als auch der Bildencoder werden so trainiert, dass der Abstand eines gegebenen Paares
- Beim Testen stellen wir ein Wörterbuch von Bildunterschriften bereit (nicht zu verwechseln mit dem dynamischen Wörterbuch in MoCo) und das gewünschte Bild. Basierend auf dem Bild gibt es die Bildunterschrift mit der höchsten Wahrscheinlichkeit zurück.
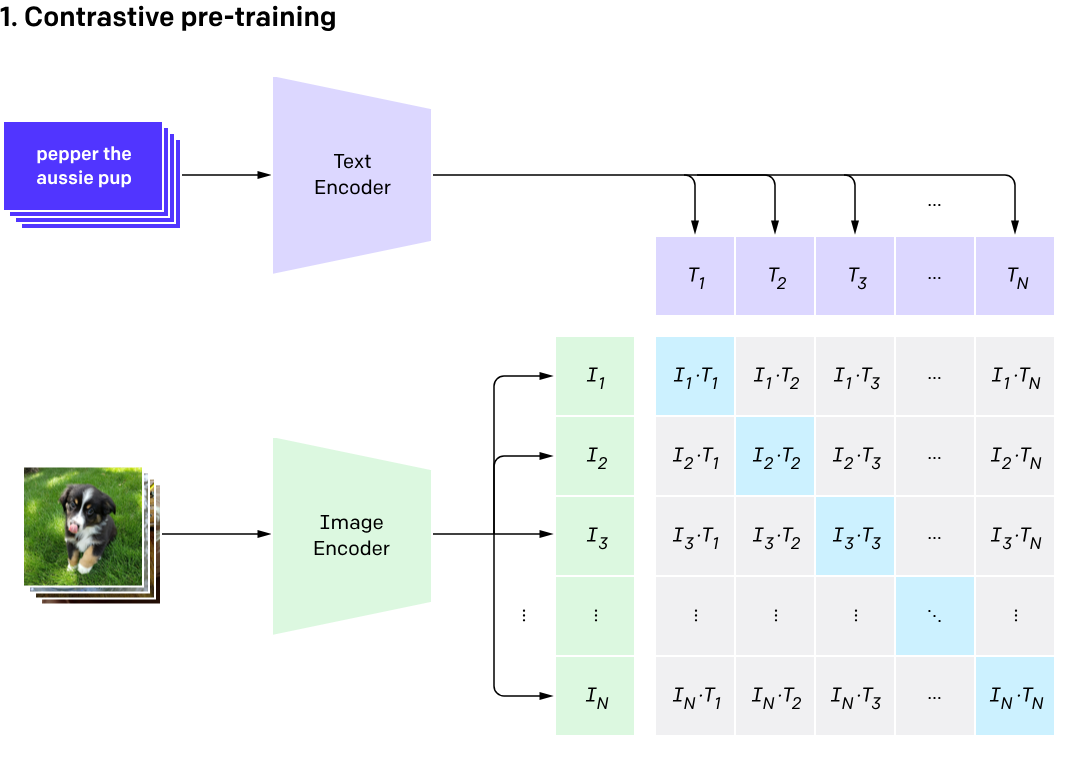
Hinweis: Für weitere Details zu CLIP lesen Sie bitte diesen Artikel (opens new window).
# Codebeispiel
Lassen Sie uns die Dinge mit einem Codebeispiel abschließen, um das Bild zu vervollständigen. Hier verwende ich die offizielle Implementierung von MoCo (opens new window) von Meta Research. Dieser Code konzentriert sich hauptsächlich auf die Klasse MoCo.
# Konstruktor
Der Konstruktor der Klasse MoCo initialisiert die Attribute wie K, m und T. Wie wir sehen können, verwendet er die Standardwerte für die Merkmalsdimension (dim) als 128, die Warteschlangengröße (K) als 16-Bit (65.536), während der Momentum-Koeffizient μ 0,999 (ziemlich langsame gleitende Durchschnitt) ist. Die Softmax-Temperatur τ, wie bereits im Papier angegeben, beträgt 0,07.
Außerdem können wir die Implementierung des MLP sehen, das wir zuerst in SimCLR und später in MoCov2 gesehen haben (diese Implementierung umfasst beide Versionen).
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
# Momentum-Encoder
Der Kernbereich ist einfach, aber sehr effektiv. Im Momentum-Encoder implementieren wir einfach diese Gleichung für den momentumbasierten Durchschnitt:
@torch.no_grad()
def _momentum_update_key_encoder(self):
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
# Warteschlangenverwaltung
Schließlich wird die Warteschlange aktualisiert, um die älteren Batch-Daten zu entfernen. Es funktioniert wie folgt:
- Wir sammeln zuerst die Schlüssel.
- Der Zeiger der Warteschlange zeigt auf die Transposition der
keys. Warum dies genau für die Spalten und nicht für die Zeilen erfolgt, ist etwas, das mich interessiert. - Am Ende bewegt sich der Zeiger zum nächsten Batch (hier ist das Modulo für die zirkuläre Warteschlange), und dies spiegelt sich auch im Attribut (
self.queue_ptr) wider.
def _dequeue_and_enqueue(self, keys):
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0
self.queue[:, ptr : ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K
self.queue_ptr[0] = ptr
# Training
Im Trainingsschritt kombinieren wir dies alles wie folgt:
- Berechnung der Query-Merkmale
- Berechnung der Key-Merkmale (unter Verwendung des Momentum-Updates)
- Berechnung der Logits (sowohl positiv als auch negativ)
- Dequeue und Enqueue unter Verwendung der oben diskutierten Funktion
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
Übrigens sind all diese Kommentare von den Autoren selbst geschrieben und zeigen, dass sie nicht nur ein klares Papier geschrieben haben, sondern auch einen guten, leicht verständlichen Code.

# Kontrastives Lernen und Vektordatenbanken
Da sich das kontrastive Lernen um die Einbettungen der Eingabedaten und deren Abstand dreht, sind sie für Vektordatenbanken von großer Bedeutung. Mit einem trainierten CL-Modell können wir einfach eine Metrik wie den euklidischen Abstand, die Kosinusähnlichkeit oder den
Daher gibt es unzählige Anwendungen des kontrastiven Lernens in Verbindung mit Vektordatenbanken, zum Beispiel:
- Zero-Shot-Erkennung (kann selbst eine Vielzahl von Anwendungen haben) mit CLIP
- Empfehlungssystem für einen Online-Benutzer - basierend auf der Historie des Benutzers schlägt es Produkte vor, die der Historie am nächsten kommen.
- Dokumentenabfrage - Abrufen des Dokuments aus der Datenbank, das der Abfrageeinbettung des Benutzers am nächsten kommt.
- Anomalieerkennung - Ob eine neue Transaktion mit dieser Kreditkarte normal oder betrügerisch ist, kann mithilfe der Einbettungen früherer Transaktionen und der Ermittlung der Ähnlichkeit (oder Nicht-Ähnlichkeit) zwischen dieser Transaktion und dem "Bereich" der Transaktionshistorie im Einbettungsraum überprüft werden.
# Referenzen
- Dosovitskiy, et al., Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks, IEEE PAMI, 2016.
- Hjelm, et al., Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR, 2019.
- Oord, et al., Representation Learning with Contrastive Predictive Coding, arXiv 2018.
- Chen, et al., A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020.
- Radford, et al., Learning Transferable Visual Models From Natural Language Supervision, arXiv 2020
- He, et al., Momentum Contrast for Unsupervised Visual Representation Learning, arXiv 2020
- He, et al., Improved Baselines with Momentum Contrastive Learning, arXiv 2020



