
Große Sprachmodelle (LLMs) haben viele Aufgaben erleichtert, wie z.B. die Erstellung von Chatbots, Sprachübersetzungen, Textzusammenfassungen und vieles mehr. Früher mussten wir Modelle für verschiedene Aufgaben schreiben, und dann gab es immer das Problem ihrer Leistung. Jetzt können wir die meisten Aufgaben mit Hilfe von LLMs einfach erledigen. Allerdings haben LLMs einige Einschränkungen, wenn sie auf realen Anwendungsfällen angewendet werden. Sie haben keine spezifischen oder aktuellen Informationen, was zu einem Phänomen führt, das als "Halluzination" (opens new window) bezeichnet wird, bei dem das Modell inkorrekte oder unvorhersehbare Ergebnisse generiert.
Vektordatenbanken (opens new window) haben sich als sehr hilfreich erwiesen, um das Halluzinationsproblem bei LLMs zu mildern, indem sie eine Datenbank mit domänenspezifischen Daten bereitstellen, auf die die Modelle verweisen können. Dadurch werden ungenaue oder unsinnige Antworten reduziert.
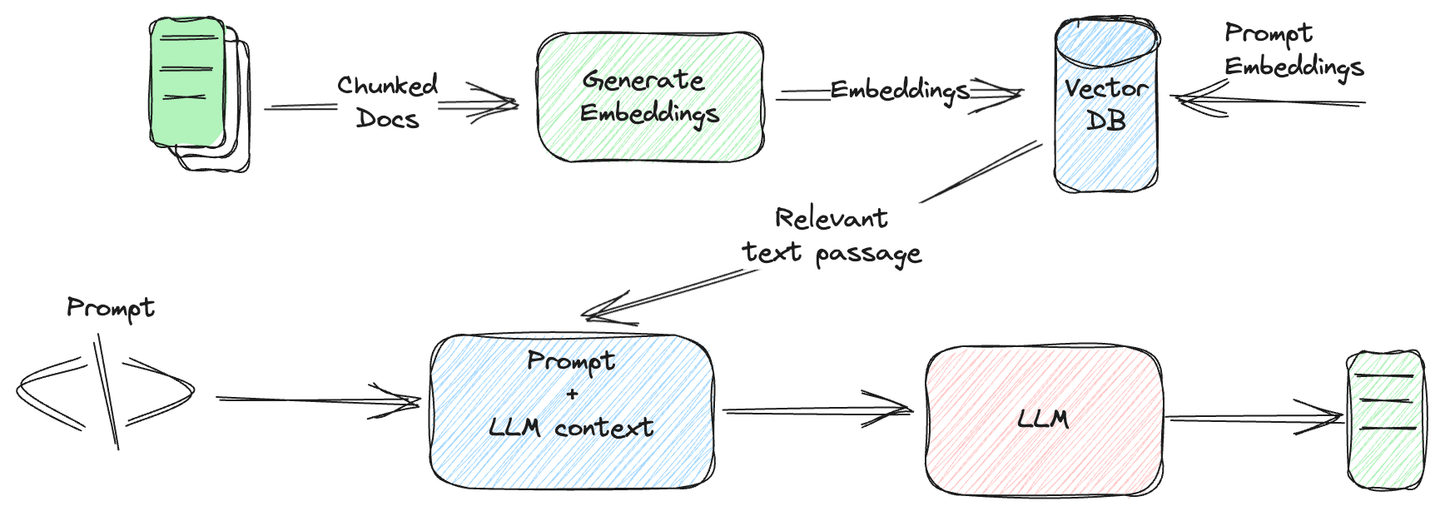
In diesem Blogbeitrag werden wir sehen, wie die Integration von Vektordatenbanken mit SQL das Leben für Unternehmen einfacher gemacht hat. Wir werden einige der Einschränkungen herkömmlicher Datenbanken diskutieren und was zur Entwicklung dieser neuen Integration, der SQL-Vektordatenbank, geführt hat. Am Ende des Blogs werden wir sehen, wie diese Datenbanken funktionieren und warum MyScale (opens new window) Ihre erste Wahl sein könnte, wenn es um die Auswahl von Vektordatenbanken geht.
# Was sind SQL-Vektordatenbanken?
Eine SQL-Vektordatenbank ist eine spezialisierte Art von Datenbank, die die Funktionen herkömmlicher SQL-Datenbanken mit den Fähigkeiten einer Vektordatenbank kombiniert. Sie ermöglicht Ihnen die effiziente Speicherung und Abfrage hochdimensionaler Vektoren mithilfe von SQL.
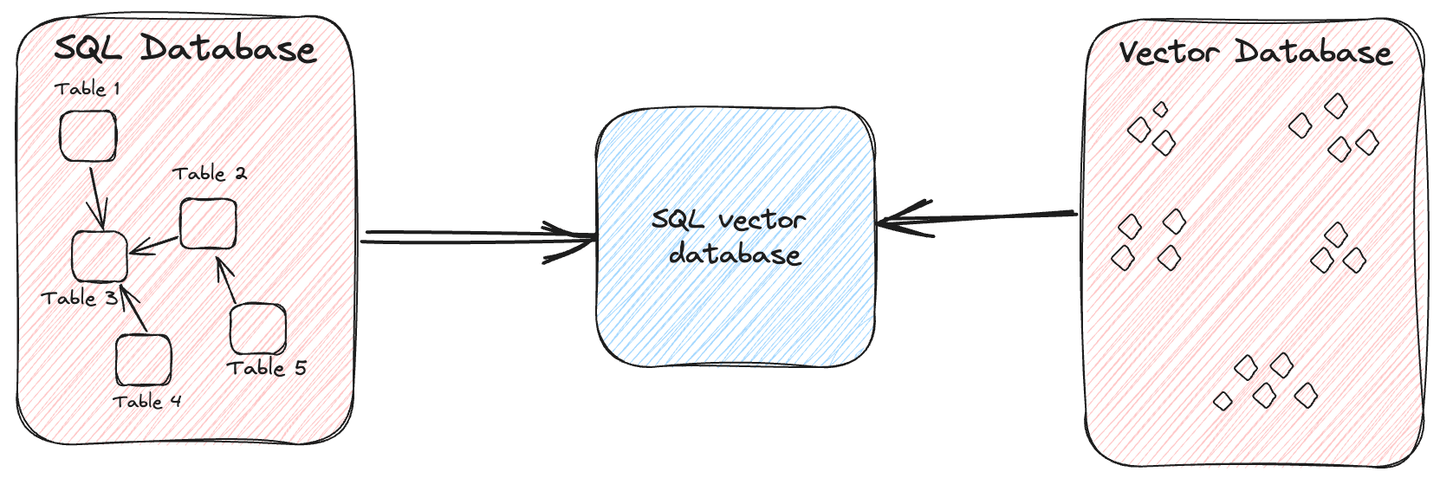
Einfach ausgedrückt handelt es sich um eine reguläre Datenbank, die Sie sowohl für strukturierte als auch für unstrukturierte Daten verwenden können, jedoch mit der zusätzlichen Möglichkeit, schnelle Abfragen über verschiedene Datentypen hinweg durchzuführen, einschließlich Bilder, Videos, Audio und Text. Die Effizienz dieses Mechanismus liegt in der Erstellung von Vektoren für die Daten, die eine schnelle Identifizierung ähnlicher Einträge ermöglichen.
Nun wollen wir versuchen, die Kernkonzepte von SQL-Vektordatenbanken zu verstehen, die dazu beitragen, den Grund dafür zu verstehen, warum wir SQL-Vektordatenbanken benötigen.
# Schlüsselkonzepte in SQL-Vektordatenbanken
SQL-Vektordatenbanken haben einige innovative Konzepte eingeführt, die die Datenabfrage und -analyse erheblich verbessern, insbesondere im Zusammenhang mit unstrukturierten und hochdimensionalen Daten. Lassen Sie uns einige davon erkunden:
- Behandlung unstrukturierter Daten: Vektorrepräsentationen von Daten ermöglichen die Durchführung einer ANN-Suche (Approximate Nearest Neighbor) auf unstrukturierten Daten. Wenn Sie die Einbettungen unstrukturierter Daten wie Text, Bilder oder Audio finden, erfassen Sie die semantische Bedeutung, die es Ihnen ermöglicht, Ähnlichkeitsvergleiche durchzuführen, indem Sie den Abstand zwischen Vektoren messen, um die nächsten Nachbarn zu finden, unabhängig vom ursprünglichen Datenformat.
- ANN-Suche: SQL-Vektordatenbanken speichern Daten als Vektoren und führen eine Art Suche durch, die als Ähnlichkeitssuche bekannt ist und nicht gegen eine einzelne Zeile, sondern gegen eine Approximate Nearest Neighbor (ANN)-Suche durchgeführt wird. Dieser Prozess umfasst die Identifizierung der Vektoren, die dem gegebenen Abfragevektor am nächsten liegen, d.h. deren Eigenschaften am besten mit den Eigenschaften des Abfragevektors übereinstimmen.
- Vektorindizierung: Vektorindizierung bezieht sich auf spezialisierte Datenstrukturen und Algorithmen, die zur effizienten Organisation und Abfrage großer Mengen von Vektordaten verwendet werden. Vektordatenbanken verwenden verschiedene Vektorindizierungsstrategien, um die Datenabfrage und -verwaltung zu optimieren. Einige Vektordatenbanken verwenden hierarchische Graphalgorithmen, um die Suchleistung zu beschleunigen. Einige Anbieter entwickeln möglicherweise ihren eigenen Indizierungsalgorithmus, zum Beispiel hat MyScale eine neuartige Technik namens Multi-Scale Tree Graph (MSTG) entwickelt, die bestehende Ansätze signifikant übertrifft (opens new window).
Hinweis:
Das Ziel der Vektorindizierung besteht darin, die Suchgeschwindigkeit und -genauigkeit bei Operationen wie der Ähnlichkeitssuche nach ungefähren nächsten Nachbarn über hochdimensionale Vektoren zu optimieren.
# Warum wir SQL-Vektordatenbanken benötigen
Nun stellt sich die Frage: Warum benötigen wir SQL-Vektordatenbanken? Herkömmliche Datenbanken wie MySQL, PostgreSQL und Oracle haben seit langem gute Dienste geleistet und verfügen über alle notwendigen Funktionen, um die Daten organisiert zu halten. Sie verfügen über schnelle Indizierungsmethoden und stellen sicher, dass Sie die genauen Daten erhalten, die Sie benötigen, ohne Probleme. Warum also eine SQL-Vektordatenbank?
Zweifellos sind herkömmliche Datenbanken großartig, aber sie haben einige Einschränkungen, wenn die Datenmenge groß und unstrukturiert wird. Schauen wir uns das genauer an:
- Mangel an Geschwindigkeit und semantischem Verständnis: Herkömmliche Datenbanken verlassen sich auf exakte Schlüsselwortübereinstimmung und Indizierung, um Daten abzurufen. Aber mit dem exponentiellen Wachstum unstrukturierter Daten aus sozialen Medien, Sensoren usw. verstehen herkömmliche Datenbanken nicht die Semantik der Daten. Es besteht die Notwendigkeit von Datenbanken, die nicht nur Daten schnell abrufen können, sondern auch den Kontext und die Semantik von Abfragen verstehen können. Beispielsweise haben herkömmliche Methoden Schwierigkeiten, schnelle und relevante Ergebnisse bei natürlichsprachlichen Abfragen oder komplexen Datenbeziehungen bereitzustellen.
- Probleme mit hochdimensionalen Daten: Relationale Datenbanken speichern Daten in Form von Zeilen und Spalten. Mit zunehmender Anzahl von Spalten oder Dimensionen nimmt die Abfrageleistung ab und es entsteht das Phänomen des "Fluchs der Dimensionalität". Daher benötigen wir eine Datenbank, die das Problem der Dimensionalität beseitigen kann, ohne die Abfrageleistung zu beeinträchtigen.
- Unstrukturierte Daten: Relationale Datenbanken erfordern, dass strukturierte Daten in Zeilen und Spalten in Tabellen transformiert und abgeflacht werden. Aber ein zunehmender Teil der wertvollen Daten von heute ist unstrukturiert - Bilder, Videos, Audio, Textdokumente usw. - was sehr schwierig ist, in relationalen Datenbanken zu speichern.
- Skalierbarkeitsprobleme: Skalierbarkeit ist eine Herausforderung für herkömmliche Datenbanken, insbesondere wenn Sie es mit massiven Datenmengen zu tun haben. Dies wird zu einem Problem für Organisationen, die große Datensätze verarbeiten und analysieren müssen, da es ihnen Schwierigkeiten bereitet, Daten effektiv zu verarbeiten und zu analysieren. Daher benötigen wir eine Datenbank, die große Datenmengen verarbeiten kann, während sie gleichzeitig Geschwindigkeit und Effizienz beibehält.
Um diese Herausforderungen anzugehen, entstanden die SQL-Vektordatenbanken als überlegene Alternative zu herkömmlichen Datenbanken.
# Wie SQL-Vektordatenbanken herkömmliche Datenbanken übertreffen
Die Kombination von SQL mit Vektoren bringt viele Vorteile mit sich, von denen einige besonders hervorstechen:
- Schnellere Leistung und semantische Suche: Die Vektorrepräsentation ermöglicht es der Datenbank, die semantische Bedeutung aus den gespeicherten Daten zu extrahieren. Außerdem wird der Prozess noch schneller, da wir hier die Vektorsimilarität finden. Dies ist hilfreich für viele Anwendungen wie Empfehlungssysteme, bei denen die semantische Beziehung zwischen den Daten wichtiger ist.
- Effiziente Datenabfrage: SQL-Vektordatenbanken verwenden die Technik der Approximate Nearest Neighbor (ANN), um die übereinstimmenden Datensätze zu finden. Durch Berechnung der Kosinusähnlichkeit zwischen Ihrer Abfrage und dem Datensatz gibt sie effizient die relevantesten Top-'K'-Ergebnisse zurück.
- Unterstützung für strukturierte und unstrukturierte Daten: Die Einführung von SQL in die Vektordatenbank ermöglicht die Darstellung unstrukturierter Daten in Vektoren und die Speicherung der semantischen Bedeutungen. Auf diese Weise können Sie beliebige strukturierte oder unstrukturierte Daten abfragen.
- Vertraute SQL-Schnittstelle: Einer der größten Vorteile von SQL-Vektordatenbanken ist, dass sie eine vertraute SQL-Schnittstelle zum Abfragen von Daten bieten. Sie können Ihre SQL-Kenntnisse nutzen und die Lernkurve bei der Einführung von Vektorfunktionen minimieren. Abfragen können mit der Standard-SQL-Syntax geschrieben werden.
# Wie SQL-Vektordatenbanken funktionieren
Die Integration von SQL und Vektordatenbanken umfasst die Speicherung und Indizierung hochdimensionaler Vektoren auf eine Weise, die effizient mit SQL abgefragt werden kann. Dieser Prozess umfasst bestimmte Schritte.
Hinweis:
In diesem Projekt verwenden wir MyScale, eine SQL-basierte Vektordatenbank, für die erste Implementierung. Es kann jedoch sein, dass verschiedene SQL-Vektordatenbanken auf unterschiedliche Weise arbeiten.
# Schritt 1: Einrichten der Datenbank
Zunächst müssen Sie eine Datenbank einrichten, die sowohl SQL- als auch Vektoroperationen unterstützt. Einige moderne Datenbanken verfügen über integrierte Unterstützung für Vektoren, während andere mit benutzerdefinierten Datentypen und Funktionen erweitert werden können.
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
description TEXT,
vector Array(Float32),
CONSTRAINT check_length CHECK length(vector) = 1536,
);
In diesem Beispiel erstellen wir eine Tabelle "products" mit einer 1536D-Spalte "vector", die die hochdimensionalen Vektoren speichert.
# Schritt 2: Einfügen von Daten
Beim Einfügen von Daten speichern Sie sowohl die strukturierten Attribute als auch die Vektorrepräsentationen der unstrukturierten Daten.
INSERT INTO products (id, name, description, vector)
VALUES (1, 'Smartphone', 'A high-end smartphone with a great camera.', ARRAY[0.13, 0.67, 0.29, ...]);
In dieser SQL-Anweisung fügen wir einen neuen Produktdatensatz zusammen mit seinem Vektor ein.
Hinweis:
Um die Vektorrepräsentation der unstrukturierten Daten zu erhalten, können Sie Modelle wie GPT-4 und BERT verwenden.
# Schritt 3: Indizierung von Vektoren
Der nächste Schritt besteht darin, Vektorindizes zu erstellen. Es handelt sich um die Technik, die bestimmt, wie schnell die Datenbank die Ähnlichkeitssuche anwendet. Viele Vektordatenbanken verwenden spezialisierte Indizierungstechniken wie KD-Bäume, R-Bäume oder invertierte Indexstrukturen, um diese Operationen zu optimieren.
ALTER TABLE products ADD VECTOR INDEX idx vector TYPE MSTG
Hier erstellen wir einen MSTG-Index, der für die Indizierung multidimensionaler Daten geeignet ist.
Hinweis:
Der MSTG-Algorithmus wurde vom MyScale-Team entwickelt und hat alle gängigen Vektorsuchindizes (in Bezug auf Leistung und Kosteneffizienz) übertroffen, die von vielen Vektordatenbanken (opens new window) verwendet werden.
# Schritt 4: Abfragen von Daten
Um die Daten abzufragen, kombinieren Sie einfach herkömmliche SQL-Abfragen mit Vektoroperationen. Wenn Sie beispielsweise Produkte finden möchten, die einem Abfragevektor ähnlich sind, können Sie die Vektorfunktion distance verwenden.
SELECT name, description, distance(vector, query_vector) as dist
FROM products
ORDER BY dist LIMIT 5;
Diese Abfrage ermittelt den Abstand zwischen den Vektorrepräsentationen der Vektorspalte und dem query_vector. Anschließend werden die Ergebnisse aufsteigend nach Abstand sortiert.

# Die ideale Lösung: MyScale - eine SQL-Vektordatenbank
Hier kommt MyScale ins Spiel als Lösung, die relationale Datenbanken und Vektordatenbanken kombiniert. Basierend auf der Open-Source-SQL-Datenbank ClickHouse ermöglicht MyScale die direkte Ausführung von erweiterten Vektorabfragen mit der Standard-SQL-Syntax. Dadurch entfällt der Aufwand, separate relationale und Vektordatenbanken zu integrieren. Im Gegensatz zu anderen Vektordatenbanken wie Pinecone, Milvus und Qdrant bietet MyScale eine einzige SQL-Schnittstelle für die Vektorsuche. Es ermöglicht die Speicherung von skalaren und Vektordaten in einer einzigen Datenbank. Jetzt können Sie blitzschnelle Vektorergebnisse direkt mit vertrautem SQL erhalten.
Es wird allgemein angenommen, dass relationale Datenbanken keine Leistung bieten können, die mit der von Vektordatenbanken vergleichbar ist. MyScale widerlegt diesen Mythos. In direkten Vergleichen übertrifft MyScale nicht nur signifikant pgvector (opens new window) in Bezug auf Suchgenauigkeit und Abfrageverarbeitungsgeschwindigkeit, sondern zeigt auch einen deutlichen Vorteil gegenüber spezialisierten Vektordatenbanken wie Pinecone (opens new window), insbesondere in Bezug auf Kosteneffizienz und Indexaufbauzeiten. Diese herausragende Leistung in Kombination mit der Einfachheit von SQL macht MyScale zur ersten Wahl für Unternehmen.
Wenn Sie weitere Fragen haben oder an unserem Angebot interessiert sind, zögern Sie nicht, uns über Discord (opens new window) zu kontaktieren oder MyScale auf Twitter (opens new window) zu folgen.



