
In unserer vorherigen Erkundung des Kontrastiven Lernens (opens new window), haben wir herausgefunden, wie Modelle lernen können, zwischen ähnlichen und unähnlichen Daten zu unterscheiden, indem sie ähnliche Elemente näher zusammenbringen und unähnliche Elemente voneinander entfernen, in einem Einbettungsraum. Wir haben Methoden wie SimCLR (opens new window), MoCo (opens new window) und CLIP (opens new window) diskutiert, die das selbstüberwachte Lernen (opens new window) erheblich vorangetrieben haben.
Setzen wir diese Reise in das metrische Lernen fort und sprechen über den Triplet Loss. Er baut auf den Prinzipien des kontrastiven Lernens auf und spielt eine entscheidende Rolle bei Aufgaben, die feinere Unterscheidungen erfordern, wie Gesichtserkennung, Bildsuche und Signaturverifikation.
# Metrisches Lernen
Bevor wir uns mit dem Triplet Loss beschäftigen, ist es wichtig, das metrische Lernen zu verstehen. Metrisches Lernen ist eine Art des maschinellen Lernens, das sich darauf konzentriert, eine Abstandsfunktion (oder Metrik) zu erlernen, die die Ähnlichkeit zwischen Datenpunkten misst. Die Kernidee ist einfach:
- Ähnliche Datenpunkte sollten nah beieinander liegen im Einbettungsraum.
- Unähnliche Datenpunkte sollten weit voneinander entfernt sein.
Wir verwenden ein maschinelles Lernmodell, um Einbettungen zu generieren, und trainieren das Modell, den Abstand zwischen ähnlichen Datenpunkten zu minimieren und den Abstand zwischen Datenpunkten, die zu verschiedenen Kategorien oder Labels gehören, zu maximieren.
# Gemeinsame Abstandsmetriken
Da wir über den Abstand sprechen, liegt die Wahl des Abstands beim Benutzer. Es kann der euklidische, der Manhattan- oder einige fortgeschrittene Abstandsmessungen sein. Einige häufig verwendete Abstände sind:
- Minkowski-Abstand - Minkowski ist eine Verallgemeinerung von normbasierten Abständen durch Berechnung der p-Norm, wobei
- Kosinus-Ähnlichkeit - Die Kosinus-Ähnlichkeit basiert auf dem Skalarprodukt von Vektoren. Sie berücksichtigt, dass parallele Vektoren eine Ähnlichkeit von 1 (cos 0º), senkrechte eine Ähnlichkeit von 0 (cos 90º) und gegenüberliegende eine Ähnlichkeit von -1 (cos 180º) zwischen ihnen haben.
- Manhattan-Abstand: Auch bekannt als City-Block- oder L1-Abstand, berechnet der Manhattan-Abstand die Summe der absoluten Differenzen zwischen den Koordinaten zweier Punkte. Er ist besonders nützlich, wenn es um gitterartige Pfade oder Situationen geht, in denen eine diagonale Bewegung nicht möglich ist.
- Jaccard-Abstand - Der Jaccard-Abstand misst die Ähnlichkeit (oder Unähnlichkeit) zwischen zwei Gruppen (Mengen), indem er das Verhältnis ihrer übereinstimmenden Elemente zu ihren Gesamtelementen nimmt.
- Mahalanobis-Abstand - Der Mahalanobis-Abstand ist ein einzigartiges Maß, das die Verteilung in den Daten berücksichtigt. Er ist definiert als:
Hier ist
# Was ist der Triplet Loss?
Kommen wir nun zum Hauptthema zurück. Der Triplet Loss basiert auf einem einfachen Prinzip. Wir wählen einen Punkt im Einbettungsraum (normalerweise als Anker bezeichnet) mit einem positiven und einem negativen Punkt. Unweigerlich möchten wir den Abstand zu den negativen Punkten maximieren und für die positiven Punkte minimieren.
Hier bezeichnet
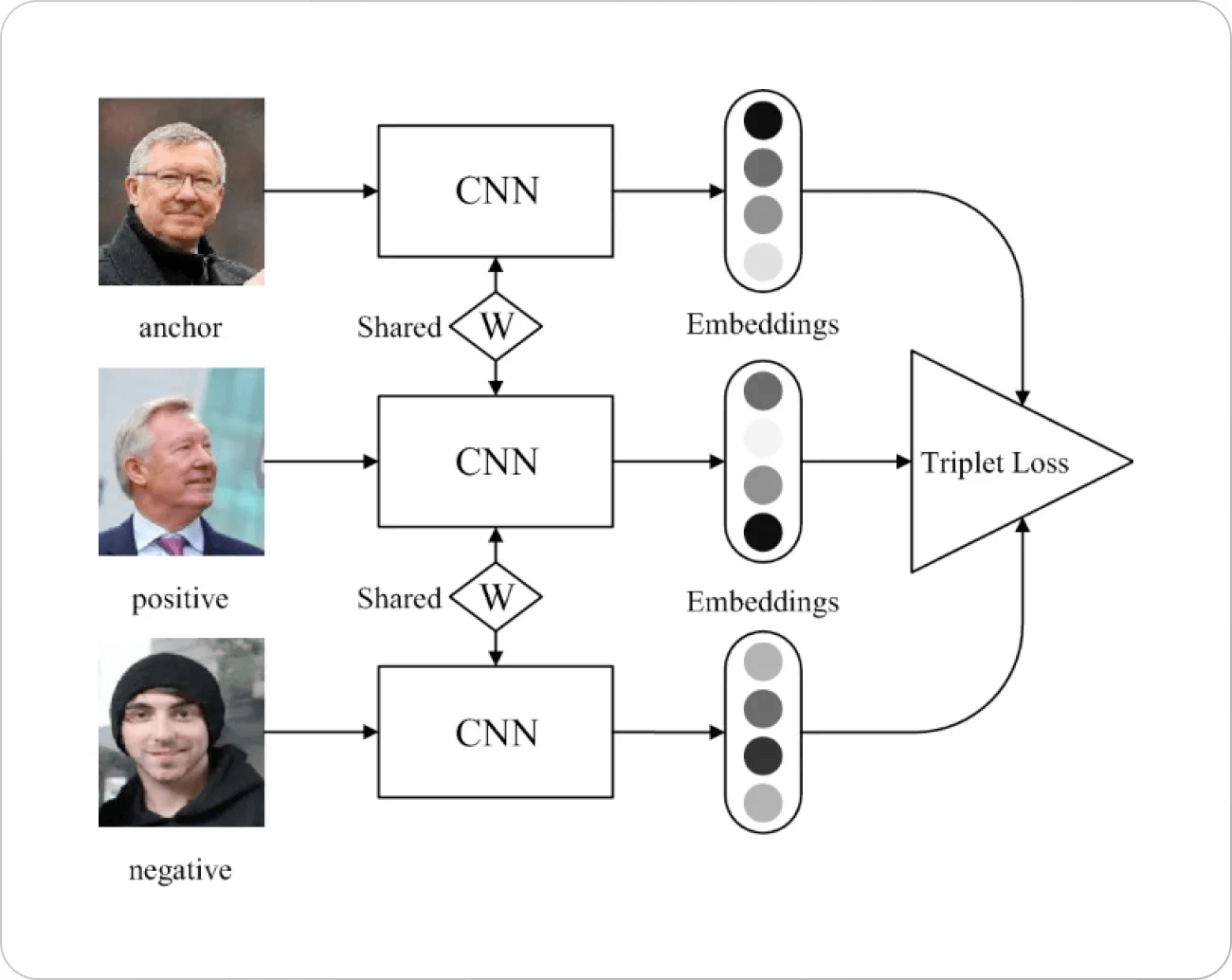
Bildquelle: Springer Paper
Hinter dem Triplet Loss gibt es einige Hintergrundinformationen. Eine der früheren Verlustfunktionen für die Gesichtserkennung (hauptsächlich basierend auf dem
# Wie funktioniert der Triplet Loss?
Stellen Sie sich vor, Sie plotten Datenpunkte in einem Einbettungsraum. Mit dem Triplet Loss:
- Werden Anker und positive Beispiele (dieselbe Klasse) näher zusammengezogen.
- Werden Anker und negative Beispiele (unterschiedliche Klassen) voneinander entfernt.
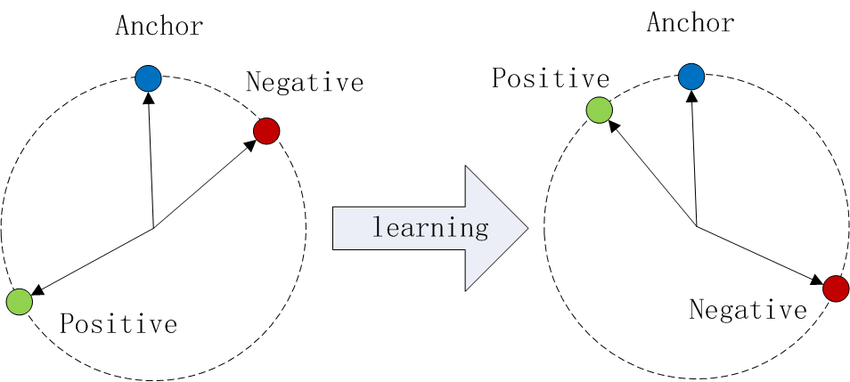
Bildquelle: Wikipedia
Dieser Prozess erzeugt für jede Klasse separate Cluster und verbessert die Fähigkeit des Modells, zwischen ihnen zu unterscheiden.
# Die Rolle des Abstands α
Der Abstand α ist ein Hyperparameter, der den minimal gewünschten Abstand zwischen positiven und negativen Paaren relativ zum Anker festlegt. Er verhindert, dass das Modell alle Einbettungen auf denselben Punkt zusammenfallen lässt, und fördert eine sinnvolle Trennung zwischen den Klassen.
- Zu kleines
α - Zu großes
α
Die Auswahl eines geeigneten Abstands ist entscheidend für ein effektives Training.
# Warum den Triplet Loss verwenden?
Der Triplet Loss ist besonders nützlich, wenn:
- Feinere Unterscheidungen wichtig sind: Bei Aufgaben wie der Gesichtserkennung, bei denen subtile Unterschiede erfasst werden müssen.
- Klassendistributionen unausgeglichen sind: Er konzentriert sich auf relative Abstände anstelle absoluter Positionen im Einbettungsraum.
- Diskriminative Merkmale lernen: Er zwingt das Modell, auf Merkmale zu achten, die zwischen den Klassen unterscheiden.
# Triplet Mining
Der Triplet Loss hat definitiv seinen Preis, da wir jeden Punkt mit allen positiven und negativen Punkten vergleichen müssen, was bedeutet, dass das Training bei wachsenden Trainingsdaten nicht durchführbar ist und zu einer worst-case Komplexität von
Um dies zu lösen, wird eine kluge Verwendung von schwierigen positiven und schwierigen negativen Beispielen gemacht. Bei der Gesichtserkennung kann zum Beispiel ein schwieriger positiver Fall Bilder derselben Person in sehr unterschiedlichen Umgebungen sein (wie Beleuchtung, Kleidung, Pose usw.), und ähnlich können schwierige negative Fälle verschiedene Personen in ähnlichen Umgebungen sein. Der Prozess des Findens dieser schwierigen positiven und negativen Beispiele wird als Mining bezeichnet. Ähnlich wie bei anderen Algorithmen, die viel Daten verwenden, wird dies auch in Minibatches durchgeführt.
# Herausforderungen
Das Finden dieser schwierigen positiven und negativen Beispiele ist definitiv ein Problem, aber noch größere Herausforderungen ergeben sich später im Training.
- Auswahl der richtigen Batch-Größe: Zu wenige Beispiele führen zu einer schlechten Darstellung der Daten und damit zu ineffizienten schwierigen Beispielen. Andererseits führen zu große Batch-Größen zu Begrenzungen der Rechenressourcen (hauptsächlich des GPU-Speichers).
- Grad der Schwierigkeit: Das Präsentieren der schwierigen Beispiele, insbesondere der schwierigen negativen Beispiele, führt zu einem schlechten Training [1] und das ist durchaus verständlich. Als Ergebnis werden einige negative Beispiele gesucht, so dass
Mit anderen Worten, wir wählen die negativen Beispiele
Hinweis:
Das Konzept des Curriculum Learning ist in Bezug auf die Auswahl des richtigen Schwierigkeitsgrads sehr relevant. Diese Technik, wie der Name schon sagt, ist von Lernen in der Schule inspiriert. Mit dieser Technik präsentieren wir dem Modell zuerst die einfachsten Beispiele (wie schwarz-weiße kontrastierende Beispiele) und steigern allmählich den Schwierigkeitsgrad. Das Gegenteil von Curriculum Learning geht umgekehrt vor, indem zuerst die schwierigsten Beispiele präsentiert werden und sich allmählich lockern. Im Jahr 2021 haben Forscher [3] eine umfangreiche Studie durchgeführt, um herauszufinden, dass Curriculum Learning in einigen Fällen hilfreich sein kann, insbesondere bei verrauschten Daten und begrenzter Trainingszeit.
- Online oder nicht online (generieren): Eine weitere Wahl besteht darin, ob alle Triplets im Voraus (offline) generiert oder dynamisch generiert werden sollen. Beide Optionen haben ihre Vor- und Nachteile. Die Offline-Generierung ermöglicht es uns, Batches normal zu generieren, während die Online-Generierung adaptiv ist. Es kann jedoch einen Overhead für die Generierung schwieriger Beispiele geben.
# Triplet Loss und Kontrastives Lernen
Sowohl der Triplet Loss als auch das kontrastive Lernen zielen darauf ab, durch das Halten von Einbettungen näher an der gewünschten Klasse (d.h. kleinere Abstände) und weiter von den Ausreißern zu lernen, sodass sie oft als dasselbe getarnt sind. Obwohl ihr Zweck derselbe ist, gibt es einen klaren Unterschied, da der kontrastive Verlust jedes Beispiel mit einer Gruppe von positiven und negativen Beispielen kontrastiert, während der Triplet Loss dies (theoretisch) für alle möglichen Triplets tut.
Da das kontrastive Lernen nicht alle Triplets (oder Paare) erstellen muss, ist es in der Implementierung rechnerisch viel schneller als die Implementierungen des Triplet Loss. Der Triplet Loss hat jedoch in den meisten Fällen eine bessere Genauigkeit.
# Unterschied zwischen kontrastivem Lernen und Triplet Loss
Gruppierung der Daten:
- Kontrastives Lernen: Arbeitet mit Paaren von Beispielen (positive oder negative Paare).
- Triplet Loss: Arbeitet mit Triplets von Beispielen (Anker, positiv, negativ).
Verlustmechanismus:
- Kontrastives Lernen: Verwendet eine binäre Entscheidung, ob Paare ähnlich oder unähnlich sind.
- Triplet Loss: Konzentriert sich auf relative Abstände zwischen Anker-positiv und Anker-negativ Paaren und stellt sicher, dass positive Beispiele dem Anker näher sind als negative Beispiele.
Flexibilität:
- Kontrastives Lernen: Einfacher in Bezug auf die Berechnung, da es nur Paare umfasst, kann aber in komplexen Fällen, in denen mehrere negative Beispiele dem Anker nahe sind, weniger effektiv sein.
- Triplet Loss: Komplexer, bietet jedoch eine bessere Kontrolle über den Einbettungsraum, da es die relativen Abstände direkt optimiert.
Trainingkomplexität:
- Kontrastives Lernen: Im Allgemeinen weniger komplex zu implementieren, da nur Paare benötigt werden.
- Triplet Loss: Komplexer, da sorgfältig ausgewählte Triplets benötigt werden (schwierige Negative werden häufig verwendet, um die Leistung zu verbessern).
# Implementierung
Wir können den Triplet Loss implementieren, indem wir den Anker (Referenzpunkt) mit positiven und negativen Beispielen nehmen. Hier verwenden wir den Minkowski-Abstand - d.h. die Wahl der Reihenfolge der Norm liegt beim Benutzer.
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative, norm_order):
pos_dist = torch.norm(anchor - positive, p=norm_order, dim=1)
neg_dist = torch.norm(anchor - negative, p=norm_order, dim=1)
loss = torch.mean(torch.clamp(pos_dist - neg_dist + self.margin, min=0.0))
return loss
# Best Practices
Einige bewährte Verfahren für die Verwendung des Triplet Loss sind:
- Der normale euklidische Abstand liefert bessere Ergebnisse als der quadrierte euklidische Abstand.
- Normalisierung (wie Batch- oder Layer-Normalisierung) hilft in der Regel nicht beim Training.
- Eine optimale Batch-Größe ([1] verwendete in den meisten Experimenten etwa 1800).

# Fazit
Der Triplet Loss ist ein wertvolles Werkzeug im metrischen Lernen, das Modellen hilft, zwischen ähnlichen und unähnlichen Datenpunkten zu unterscheiden, indem es sich auf ihre relativen Abstände konzentriert. Aufbauend auf den Ideen des kontrastiven Lernens ist er besonders nützlich für Aufgaben, die subtile Unterscheidungen zwischen Klassen erfordern.
Durch die Integration des Triplet Loss in unsere Modelle gewinnen wir die Fähigkeit, ihnen beizubringen, Muster auf eine raffiniertere Weise zu erkennen und eröffnen aufregende Möglichkeiten für Anwendungen in Bereichen wie Computer Vision, Sprachverarbeitung und vielem mehr.
# Referenzen
- Schroff, et al (CVPR 2015) FaceNet: A Unified Embedding for Face Recognition and Clustering
- Hermans, et al (2017), In Defense of the Triplet Loss for Person Re-Identification
- Wu, et al. (ICLR 2021), When Do Curricula Work?



