
Retrieval-Augmented Generation (RAG) ist ein KI-Framework, das entwickelt wurde, um ein LLM (Large Language Model) durch die Integration von Informationen aus einer externen Wissensdatenbank zu erweitern. Angesichts des zunehmenden Interesses, das RAG in letzter Zeit auf sich gezogen hat, ist es vernünftig anzunehmen, dass RAG nun ein prominentes Thema im AI/NLP (Artificial Intelligence/Natural Language Processing)-Ökosystem ist. Daher wollen wir uns nun damit befassen, was man von RAG-Systemen erwarten kann, wenn sie mit selbstgehosteten LLMs kombiniert werden.
In dem Blog-Beitrag mit dem Titel „Entdecken Sie den Leistungsgewinn mit Retrieval-Augmented Generation (opens new window),” haben wir untersucht, wie die Anzahl der abgerufenen Dokumente die Qualität der Antworten des LLM verbessern kann. Wir haben auch beschrieben, wie das vektorisierte LLM basierend auf dem MMLU-Datensatz, der in einer Vektordatenbank wie MyScale (opens new window) gespeichert ist, genauere Antworten generiert, wenn es mit kontextuell relevantem Wissen integriert wird, ohne den Datensatz feinabzustimmen.
Daher lautet der zentrale Punkt:
RAG füllt die Wissenslücken, reduziert Halluzinationen, indem es die Eingabeaufforderungen mit externen Daten erweitert.
Die Verwendung von externen LLM-APIs in Ihrer Anwendung kann potenzielle Risiken für die Datensicherheit mit sich bringen, die Kontrolle verringern und die Kosten erheblich erhöhen, insbesondere bei hoher Benutzerzahl. Daher stellt sich die Frage:
Wie können Sie eine größere Datensicherheit gewährleisten und die Kontrolle über Ihr System behalten?
Die prägnante Antwort lautet: Verwenden Sie ein selbstgehostetes LLM. Dieser Ansatz bietet nicht nur eine überlegene Kontrolle über die Daten und das Modell, sondern stärkt auch die Datensicherheit und -privatsphäre und verbessert die Kosteneffizienz.
# Warum selbstgehostete LLMs?
Cloud-basierte Large Language Models-as-a-Service (wie OpenAI's ChatGPT) sind leicht zugänglich und können in einer Vielzahl von Anwendungsbereichen einen Mehrwert bieten, indem sie sofortigen und nachvollziehbaren Zugriff ermöglichen. Öffentliche LLM-Anbieter können jedoch die Datensicherheit und -privatsphäre beeinträchtigen, sowie Bedenken hinsichtlich der Kontrolle, des Wissenslecks und der Kosteneffizienz aufwerfen.
Hinweis:
Wenn Ihnen eine oder alle diese Bedenken bekannt vorkommen, lohnt es sich, ein selbstgehostetes LLM zu verwenden.
Während wir unsere Diskussion fortsetzen, wollen wir diese vier wesentlichen Bedenken im Detail besprechen:
# 🔒 Datenschutz
Datenschutz muss eine vorrangige Sorge sein, wenn Sie LLM-APIs in Ihre Anwendung integrieren.
Warum ist Datenschutz ein solches Problem?
Die Antwort auf diese Frage hat mehrere Teile, wie in den folgenden Punkten hervorgehoben:
- LLM-Serviceanbieter könnten Ihre persönlichen Informationen für Training oder Analyse verwenden und so die Privatsphäre und Sicherheit gefährden.
- Zweitens könnten LLM-Anbieter Ihre Suchanfragen in ihre Trainingsdaten aufnehmen.
Selbstgehostete LLMs lösen diese Probleme, da sie sicher sind und Ihre Daten niemals einer Drittanbieter-API ausgesetzt sind.
# 🔧 Kontrolle
LLM-Dienste wie OpenAI GPT-3.5 zensieren in der Regel Themen wie Gewalt und die Bitte um medizinischen Rat. Sie haben keine Kontrolle darüber, welcher Inhalt zensiert wird. Möglicherweise möchten Sie jedoch Ihr eigenes Zensurmodell (und Regeln) entwickeln.
Wie können Sie ein Zensurmodell annehmen, das Ihren Anforderungen entspricht?
Die theoretische Antwort in groben Zügen ist, dass das maßgeschneiderte Feinabstimmen eines LLMs durch den Aufbau benutzerdefinierter Filter gegenüber der Verwendung von Eingabeaufforderungen bevorzugt wird, da ein feinabgestimmtes Modell stabiler ist. Darüber hinaus bietet das selbstgehostete Feinabstimmen eines Modells die Freiheit, die standardmäßige Zensur, die bei öffentlichen LLMs enthalten ist, zu ändern und zu überschreiben.
# 📖 Wissenslecks
Wie oben beschrieben, sind Wissenslecks ein Problem bei der Verwendung eines LLM-Servers von Drittanbietern, insbesondere wenn Sie Abfragen ausführen, die proprietäre Geschäftsinformationen enthalten.
Hinweis:
Mögliche Wissenslecks fließen in beide Richtungen, von den Eingabeaufforderungen zum LLM und zurück zur abfragenden Anwendung.
Wie können Sie Wissenslecks verhindern?
Zusammenfassend lässt sich sagen, dass Sie ein selbstgehostetes LLM anstelle eines LLMs aus dem öffentlichen Bereich verwenden sollten, da Ihre proprietäre Geschäftsdatenbank eines der wertvollsten Assets ist.
# 💰 Kosteneffizienz
Es ist umstritten, ob selbstgehostete LLMs im Vergleich zu cloud-basierten LLMs kosteneffizient sind. Die in dem Artikel „Wie Continuous Batching die Durchsatzrate bei LLM-Inferenz um das 23-fache erhöht und die p50-Latenz reduziert (opens new window)” beschriebene Forschung zeigt, dass selbstgehostete LLMs kosteneffektiver sind, wenn Latenz und Durchsatz richtig ausbalanciert werden und eine fortgeschrittene Continuous-Batching-Strategie verwendet wird.
Hinweis:
Wir gehen in diesem Text weiter auf dieses Konzept ein.
# Das Maximum aus Ihrem RAG mit selbstgehosteten LLMs herausholen
![]()
LLMs benötigen enorme Rechenressourcen. Sie benötigen große Mengen an Ressourcen, um Antworten zu generieren und bereitzustellen. Die Hinzufügung eines RAG erhöht den Bedarf an Rechenressourcen nur noch weiter, da dadurch über 2.000 Tokens zu den für eine verbesserte Genauigkeit erforderlichen Tokens hinzugefügt werden können. Leider verursachen diese zusätzlichen Tokens zusätzliche Kosten, insbesondere wenn Sie mit Open-Source LLM-APIs wie OpenAI arbeiten.
Diese Zahlen können durch das Selbsthosting eines LLMs verbessert werden, indem Matrizen und Methoden wie KV Cache (opens new window) und Continuous Batching (opens new window) verwendet werden, um die Effizienz zu verbessern, wenn Ihre Eingabeaufforderungen zunehmen. Auf der anderen Seite berechnen die meisten cloud-basierten Core-GPU-Computing-Plattformen wie RunPod (opens new window) Ihre Laufzeiten und nicht Ihren Token-Durchsatz: eine gute Nachricht für selbstgehostete RAG-Systeme, die zu einem niedrigeren Kostensatz pro Eingabeaufforderungs-Token führt.
Die folgende Tabelle erzählt ihre eigene Geschichte: Selbstgehostete LLMs in Kombination mit RAG können Kosteneffizienz und Genauigkeit bieten. Zusammenfassend lässt sich sagen:
- Die Kosten betragen nur 10% von
gpt-3.5-turbo, wenn das Maximum erreicht wird. - Die
llama-2-13b-chatRAG-Pipeline mit zehn Kontexten kostet nur 0,04 USD für 1840 Tokens, ein Drittel der Kosten vongpt-3.5-turboohne jeden Kontext.
Hinweis:
Weitere Details zum Leistungsgewinn mit RAG finden Sie in unserem ersten RAG-Blog-Beitrag (opens new window).
Tabelle: Gesamtkostenvergleich in US-Cent
| # Kontexte | Durchschn. Tokens | LLaMA-2-13B Genauigkeitsgewinn | llama-2-13b-chat @ 1 Thread | llama-2-13b-chat @ 8 Threads | llama-2-13b-chat @ 32 Threads | gpt-3.5-turbo |
|---|---|---|---|---|---|---|
| 0 | 417 | +0,00% | 0,3090 | 0,0423 | 0,0143 | 0,1225 |
| 1 | 554 | +4,83% | 0,3151 | 0,0450 | 0,0166 | 0,1431 |
| 3 | 737 | +6,80% | 0,3366 | 0,0514 | 0,0201 | 0,1705 |
| 5 | 1159 | +9,07% | 0,3627 | 0,0575 | 0,0271 | 0,2339 |
| 10 | 1840 | +8,77% | 0,4207 | 0,0717 | 0,0400 | 0,3360 |
# Unsere Methodik
Wir haben text-generation-inference (opens new window) verwendet, um ein unquantisiertes llama-2-13b-chat-Modell für alle Bewertungen in diesem Artikel auszuführen. Wir haben auch eine Cloud-Pod mit 1x NVIDIA A100 80GB gemietet, die 1,99 USD pro Stunde kostet. Ein Pod dieser Größe kann llama-2-13b-chat bereitstellen. Beachten Sie, dass jede Zahl das erste 4. Quantil als untere Grenze und das dritte 4. Quantil als obere Grenze verwendet, um die Datenverteilung mit Boxplots darzustellen.
Hinweis:
Das Bereitstellen von Modellen mit 70B erfordert mehr verfügbaren GPU-Speicher.
# Maximierung des LLM-Durchsatzes
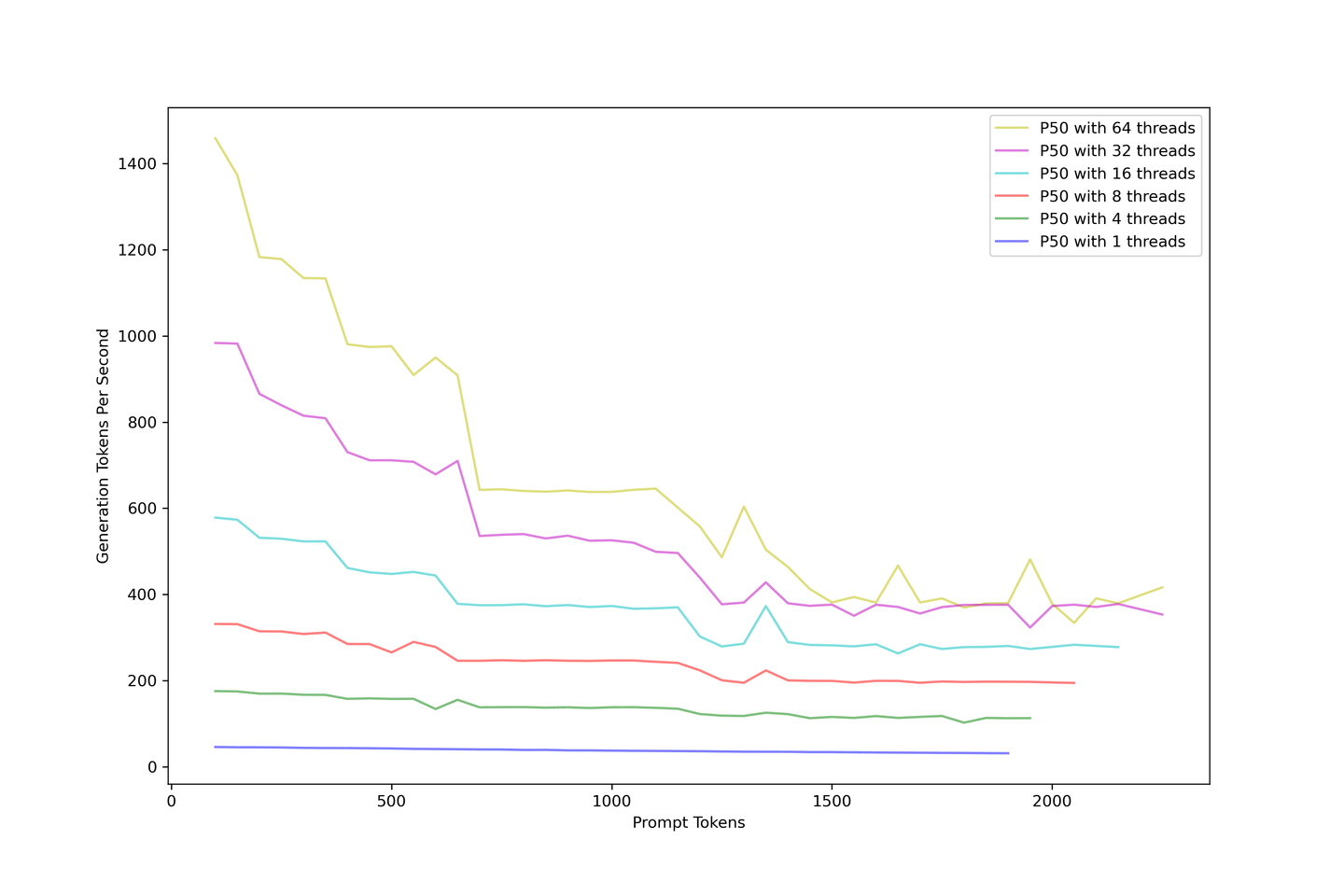
Der Gesamtdurchsatz sollte das erste sein, worüber man nachdenken sollte. Wir haben das LLM von 1 bis 64 Threads überlastet, um viele gleichzeitige eingehende Anfragen zu simulieren. Das folgende Bild beschreibt, wie der Generierungsdurchsatz mit größeren Eingabeaufforderungen abnimmt. Der Generierungsdurchsatz konvergiert bei etwa 400 Tokens pro Sekunde, unabhängig davon, wie die Parallelität erhöht wird.
Das Hinzufügen von Eingabeaufforderungen verringert den Durchsatz. Als Lösung empfehlen wir die Verwendung eines RAG mit weniger als 10 Kontexten, um Genauigkeit und Durchsatz auszugleichen.
# Messung der Boot-Zeit für längere Eingabeaufforderungen
Die Reaktionsfähigkeit des Modells ist für uns entscheidend. Wir wissen auch, dass der Generierungsprozess für informelles Sprachmodellieren iterativ ist. Um die Antwortzeit des Modells zu verbessern, haben wir die Ergebnisse der vorherigen Generierung zwischengespeichert, um die Berechnungszeit mit KV Cache zu reduzieren. Wir nennen diesen Vorgang "Booten", wenn ein LLM mit KV Cache generiert wird.
Hinweis:
Sie müssen immer Schlüssel und Werte für alle Eingabeaufforderungen am Anfang des Prozesses berechnen.

Wir haben die Boot-Zeit des Modells weiterhin erhöht, indem wir die Länge der Eingabeaufforderung erhöht haben. Das folgende Diagramm verwendet eine logarithmische Skala, um die Boot-Zeit darzustellen.
Die folgenden Punkte beziehen sich auf dieses Diagramm:
- Boot-Zeiten mit weniger als 32 Threads sind akzeptabel.
- Die Boot-Zeit der meisten Beispiele liegt unter 1000 ms.
- Die Boot-Zeit steigt drastisch an, wenn wir die Parallelität erhöhen.
- Die Beispiele mit 64 Threads beginnen bei über 1000 ms und enden bei etwa 10 Sekunden.
- Das ist viel zu lange für Benutzer, um zu warten.
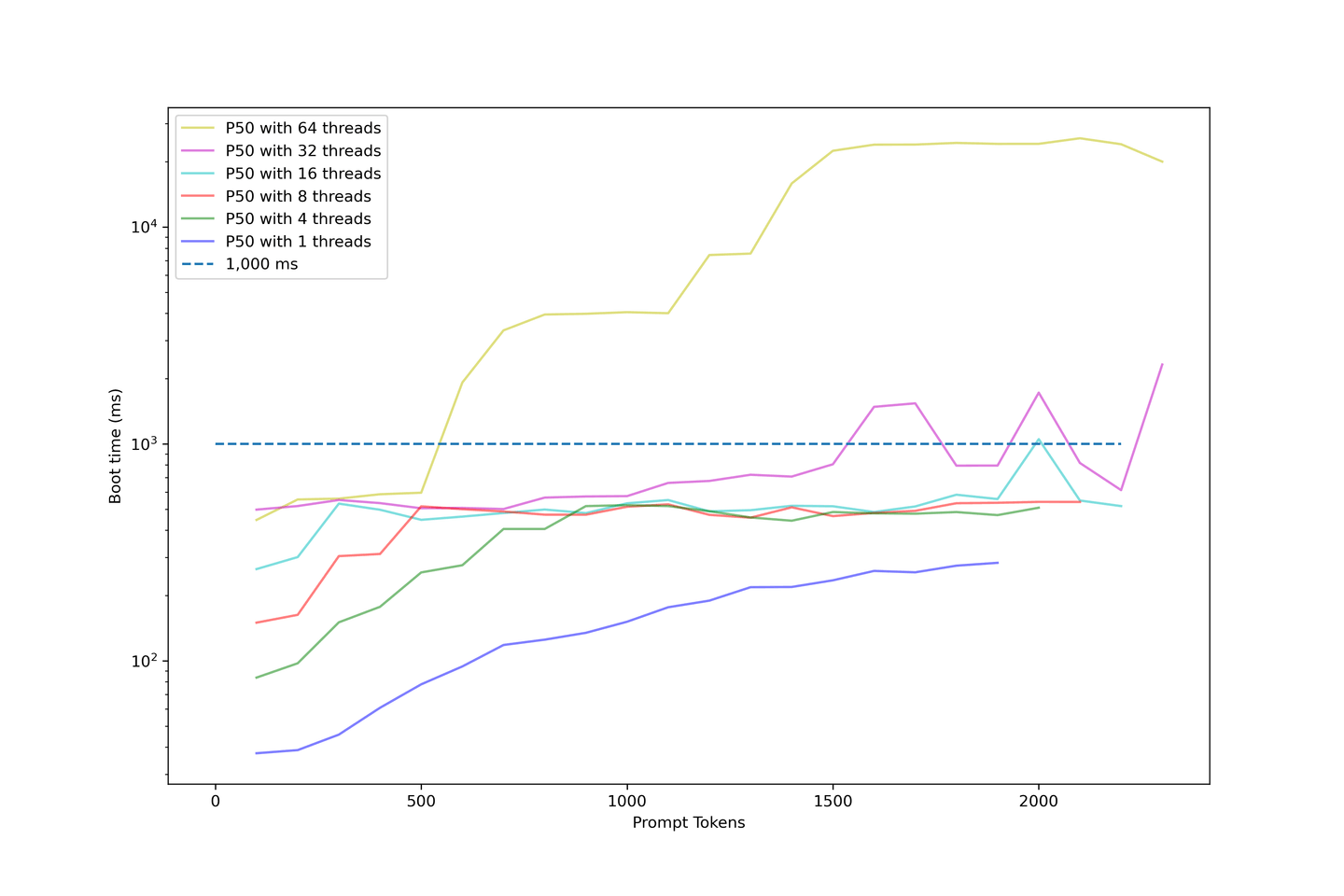
Unser Setup zeigt eine durchschnittliche Boot-Zeit von etwa 1000 ms, wenn die Parallelität unter 32 Threads liegt. Daher empfehlen wir, das LLM nicht zu stark zu überlasten, da die Boot-Zeit absurd lang wird.
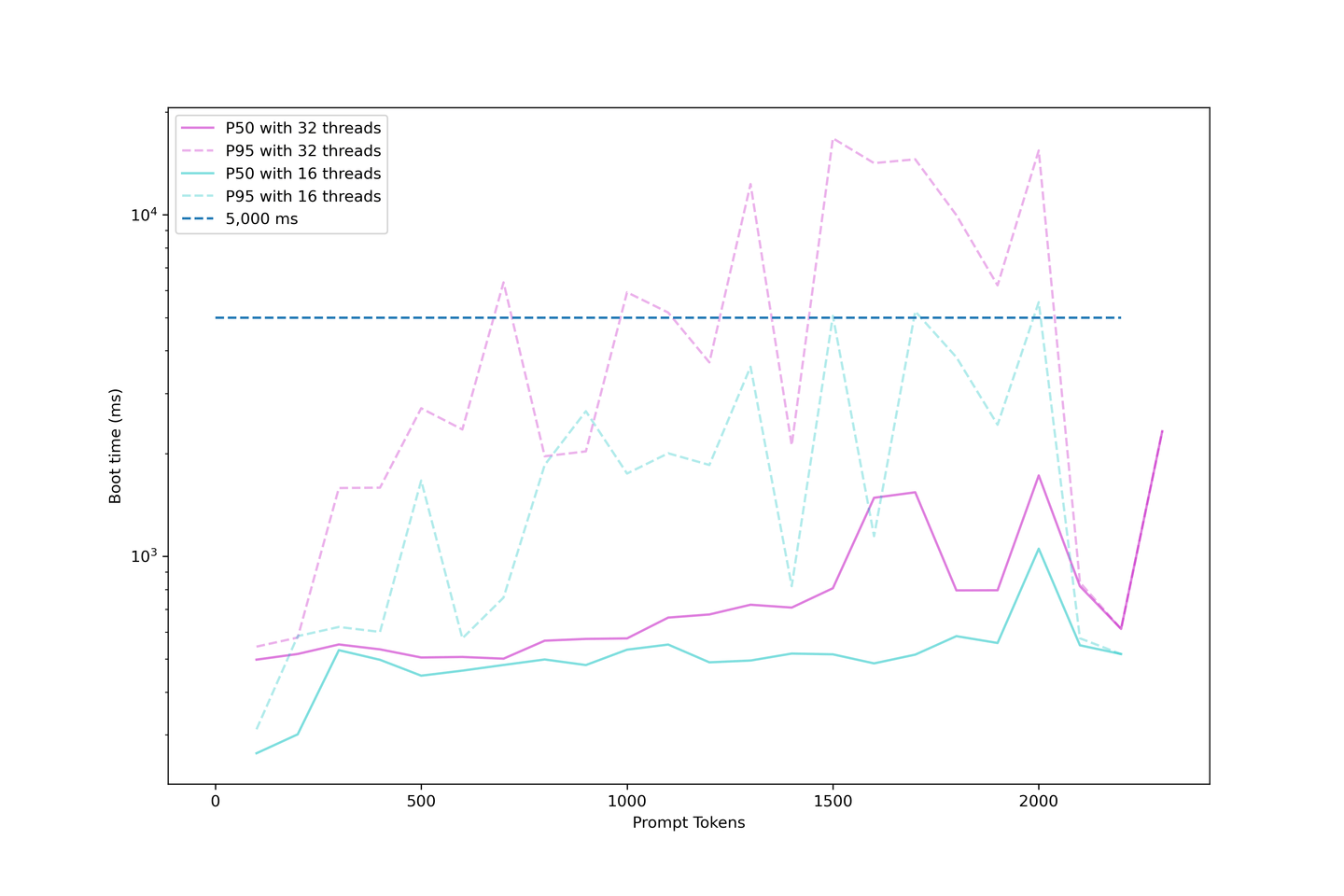
# Bewertung der Generierungslatenz
Wir wissen, dass die Generierung eines LLMs mit KV Cache in Boot-Zeit und Generierungszeit unterteilt werden kann. Wir können die tatsächliche Generierungslatenz oder die Zeit, die der Benutzer warten muss, um das nächste Token in der Anwendung zu sehen, bewerten.
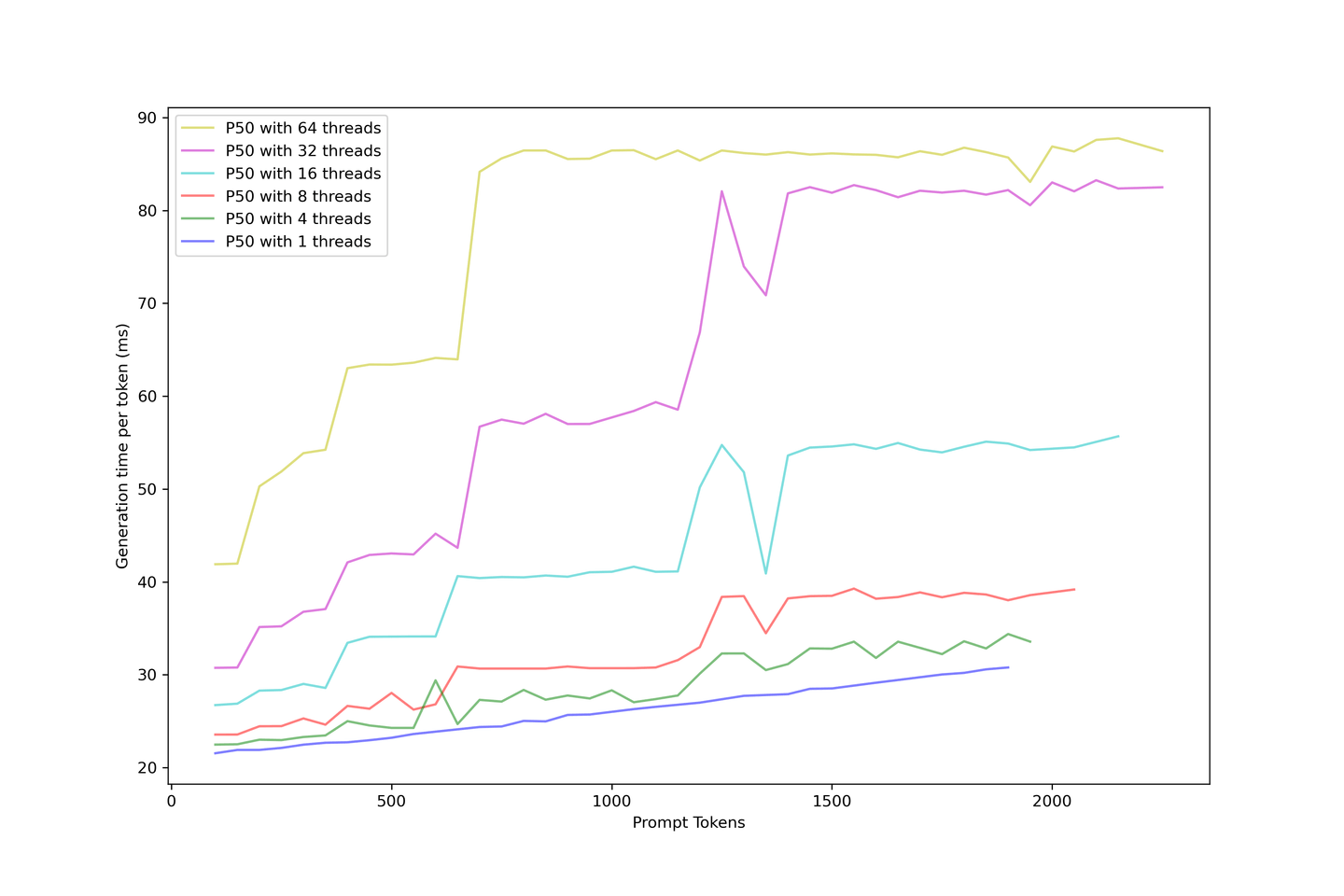
Die Generierungslatenz ist stabiler als die Boot-Zeit, da größere Eingabeaufforderungen im Boot-Prozess schwer in eine Continuous-Batching-Strategie einzufügen sind. Wenn Sie also mehr Anfragen gleichzeitig haben, müssen Sie warten, bis die vorherigen Eingabeaufforderungen zwischengespeichert sind, bevor das nächste Token angezeigt wird.
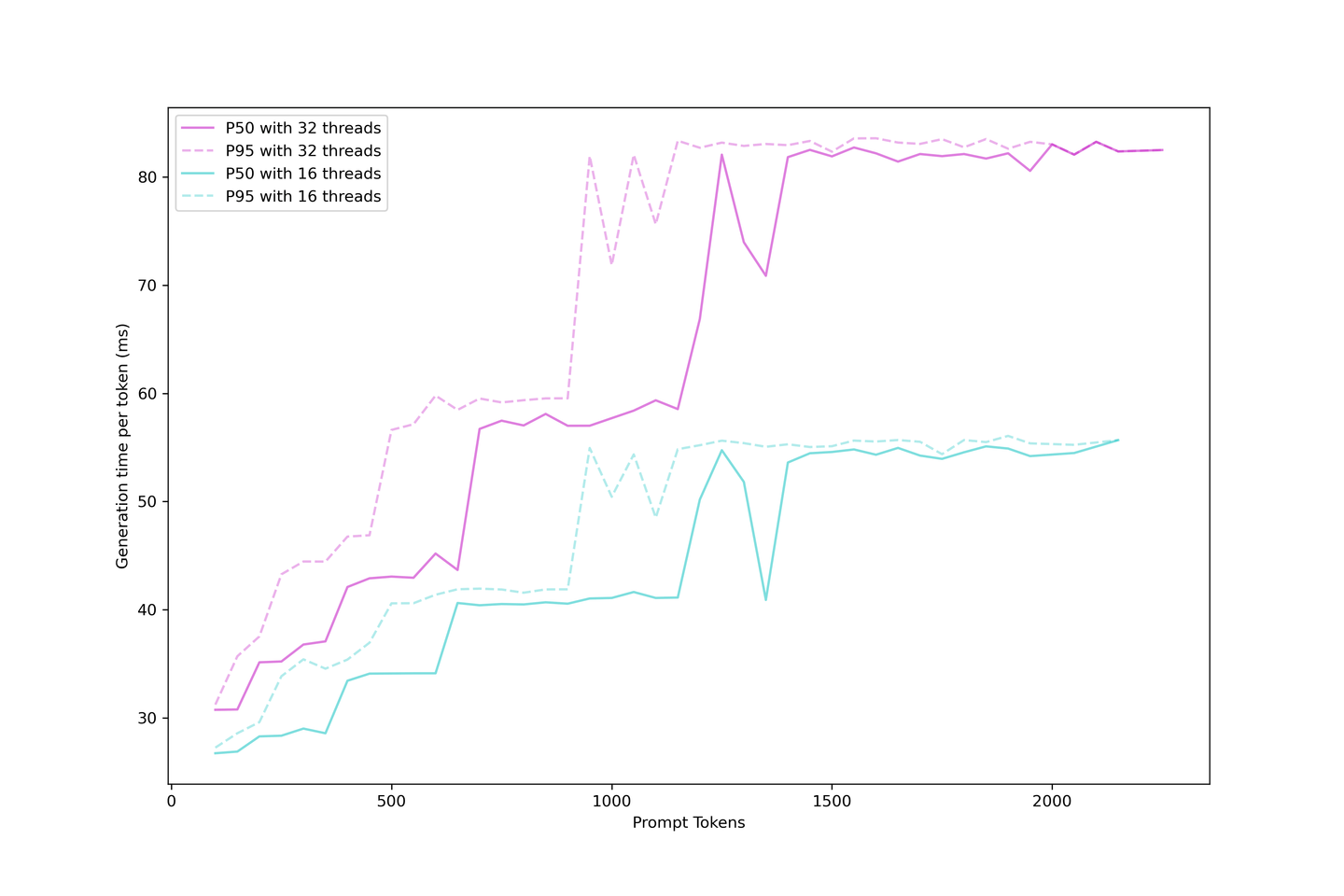
Die Generierung ist jedoch viel einfacher, sobald der Cache aufgebaut ist, da der KV-Cache die Anzahl der Iterationen reduziert und die Generierung geplant wird, sobald ein Platz in der Batch verfügbar ist. Die Latenz steigt bei verschiedenen Schritten an, wobei diese Schritte bei größeren Eingabeaufforderungen früher eintreffen und die Batch gesättigt wird. Weitere Anfragen werden das LLM bald erschöpfen und die Grenze erhöhen, während mehr Anfragen bedient werden.
Es ist vernünftig, immer eine Generierungslatenz von unter 90 ms zu erwarten und sogar etwa 60 ms, wenn Sie nicht zu stark auf Kontexte und Parallelität drängen. Daher empfehlen wir in diesem Setup fünf Kontexte mit 32 Parallelität.
# Kostenvergleich mit gpt-3.5-turbo
Wir sind sehr daran interessiert, was diese Lösung kostet. Daher haben wir die Kosten anhand der oben gesammelten Daten geschätzt und das folgende Kostenmodell für unsere Pipeline erstellt:
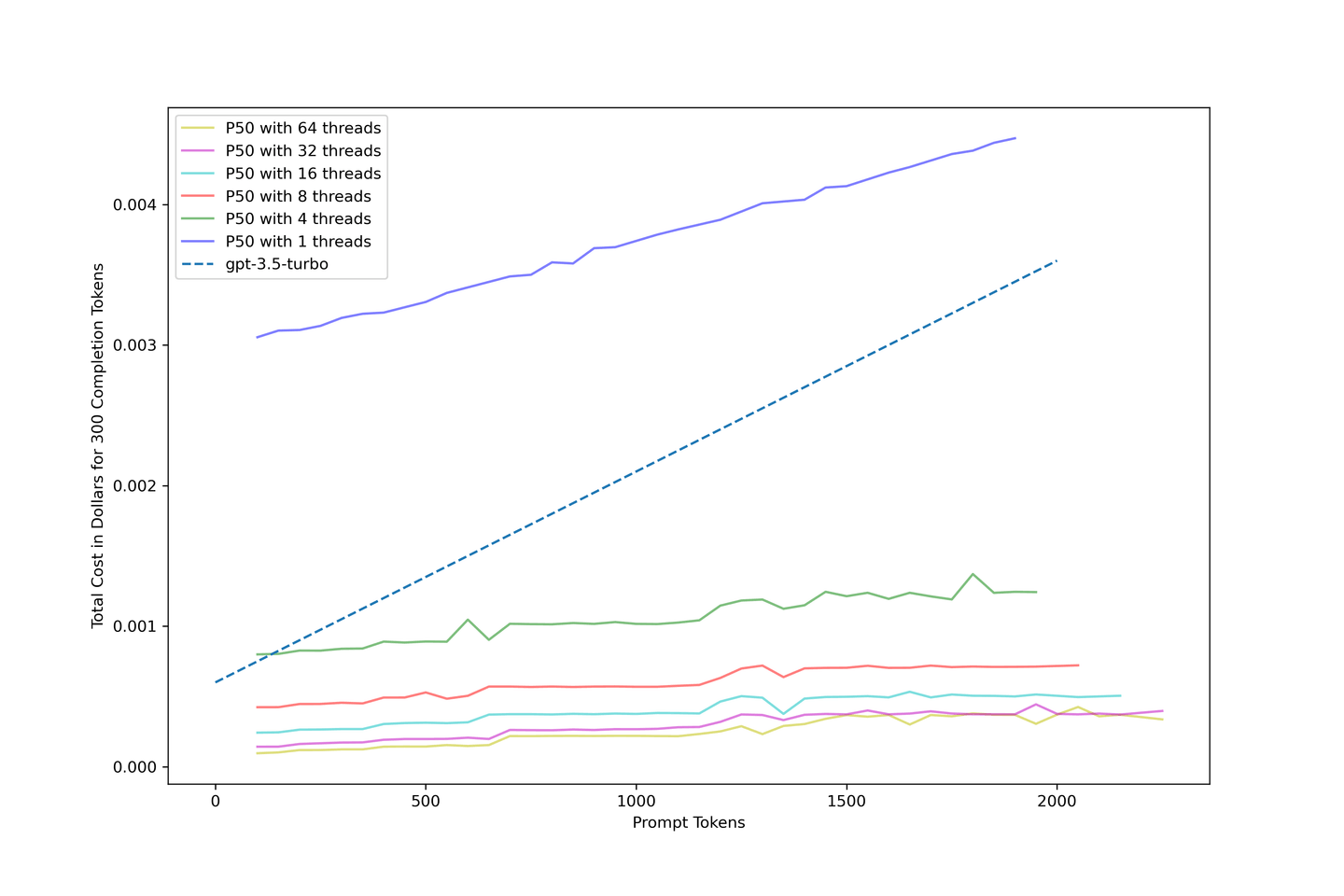
Die Verwendung von KV Cache und Continuous Batching verbessert die Kosteneffizienz des Systems und kann die Kosten im Vergleich zu gpt-3.5-turbo mit der richtigen Konfiguration auf ein Zehntel reduzieren. Eine Parallelität von 32 Threads wird für optimale Ergebnisse empfohlen.
# Was kommt als Nächstes?
Die letzte Frage, die wir stellen, lautet:
Was können wir aus diesen Diagrammen lernen und wohin sollen wir als Nächstes gehen?
# Ausgewogenheit zwischen Latenz und Durchsatz
Es gibt immer einen Kompromiss zwischen Latenz und Durchsatz. Eine Schätzung Ihres täglichen Verbrauchs und der Toleranz Ihrer Benutzer für Latenz ist ein guter Ausgangspunkt. Um Ihre Leistung pro Dollar zu maximieren, empfehlen wir, eine Parallelität von 32 auf 1x NVIDIA A100 80GB mit llama-2-13b oder ähnlichen Modellen zu erwarten. Dies gibt Ihnen den besten Durchsatz, relativ geringe Latenz und ein vernünftiges Budget. Sie können Ihre Entscheidung jederzeit ändern; denken Sie immer daran, zuerst Ihren Anwendungsfall abzuschätzen.
# Modellfeinabstimmung: Länger und stärker
Sie können Ihr Modell jetzt mit RAG-Systemen feinabstimmen. Dadurch kann das Modell sich an lange Kontexte gewöhnen. Es gibt Open-Source-Repositories, die LLMs für eine längere Eingabelänge abstimmen, wie z.B. Long-LLaMA (opens new window). Mit längeren Kontexten feinabgestimmte Modelle sind gute In-Context-Learner und performen besser als Modelle, die durch RoPE-Skalierung (opens new window) gestreckt werden.
# Kombination von MyScale mit einem RAG-System: Kostenanalyse für Inferenz vs. Datenbank
Durch die Kombination von MyScale und 10 A100-GPUs von RunPod mit MyScale (Vektordatenbank) können Sie problemlos ein RAG-System mit Llama2-13B + Wikipedia-Wissensdatenbank konfigurieren, das nahtlos bis zu 100 gleichzeitige Benutzer bedient.
Bevor wir diese Diskussion abschließen, betrachten wir eine einfache Kostenanalyse für den Betrieb eines solchen Systems:
| Empfohlenes Produkt | Vorgeschlagene Spezifikationen | Ungefähre Kosten/Monat (USD) |
|---|---|---|
| RunPod | 10 A100-GPUs | $14,000 |
| MyScale | 40 Millionen Vektoren (Datensätze) x 2 Replikate | $2,000 |
| Gesamt | $16,000 |
Hinweis:
- Diese Kosten sind eine Annäherung basierend auf den oben beschriebenen Kostenberechnungen.
- Groß angelegte RAG-Systeme verbessern die Leistung von LLMs um mehr als 15% bei zusätzlichen Kosten im Vektordatenservice.
- Die amortisierten Kosten für die Vektordatenbank werden noch niedriger sein, wenn die Anzahl der Benutzer zunimmt.

# Zusammenfassung...
Es ist naheliegend anzunehmen, dass zusätzliche Eingabeaufforderungen in RAG mehr kosten und langsamer sind. Unsere Bewertungen zeigen jedoch, dass dies eine praktikable Lösung für Anwendungen im realen Leben ist. Diese Bewertung hat auch untersucht, was man von selbstgehosteten LLMs erwarten kann, die Kosten und die Gesamtleistung dieser Lösung bewertet und Ihnen geholfen, Ihr Kostenmodell beim Bereitstellen eines LLMs mit der externen Wissensdatenbank aufzubauen.
Schließlich können wir sehen, dass die Kosteneffizienz von MyScale RAG-Systeme viel skalierbarer macht!
Wenn Sie also daran interessiert sind, die QA-Leistung von RAG-Pipelines zu bewerten, treten Sie uns auf Discord (opens new window) oder Twitter (opens new window) bei. Und Sie können auch Ihre eigenen RAG-Pipelines mit RQABenchmark (opens new window) bewerten!
Wir halten Sie über unsere neuesten Erkenntnisse zu LLMs und Vektordatenbanken auf dem Laufenden!



