
Vektor-Datenbanken bieten blitzschnelle Abfragen von ähnlichen Objekten, die in Milliarden von Datensätzen gespeichert sind. Möglicherweise möchten Sie jedoch auch nach verwandten Objekten suchen, die bestimmten Bedingungen entsprechen. Diese Art der Suche wird als gefilterte Vektor-Suche bezeichnet. Mit Hilfe von MyScale (opens new window) können Sie Ihre gefilterten Vektor-Suchen auf ein neues Niveau heben.
Die meisten Vektor-Indizes oder Vektor-Speicher funktionieren als dedizierte Indexdienste. Sie unterstützen eine teilweise Implementierung der gefilterten Vektor-Suche von MongoDB-Abfrage- und Projektionsoperatoren (opens new window), bei der Sie ein Wörterbuch von Bedingungen eingeben können.
Die unterstützten Datentypen und Vergleichsoperatoren unterscheiden sich je nach Implementierung, aber die meisten Schnittstellen unterstützen nur Zeichenketten, Ganzzahlen bei Gleichheit und grundlegende Wertvergleiche. Im Gegensatz zu Datenbanken sind diese Vektor-Indizes nicht darauf ausgelegt, komplexe Datentypen und Bedingungen zu verarbeiten. Daher benötigen Sie eine externe Datenbanklösung, um diese Daten zu speichern, können jedoch keine gefilterten Vektor-Suchen mit diesen Daten durchführen. Diese Lösung funktioniert, ist jedoch kompliziert und hat Einschränkungen.
Tatsächlich gibt es eine bessere Lösung. Die Vektor-Suche kann in eine Datenbank integriert werden, um sie robuster zu machen. MyScale kann gleichzeitig gefilterte Vektor-Suchen mit komplexen Bedingungen und Datentypen mithilfe der standardmäßigen WHERE-Klausel verarbeiten.
# Vor-Filterung und Nach-Filterung
Implementierungen der gefilterten Vektor-Suche können in zwei Typen unterteilt werden:
- Vor-gefilterte Vektor-Suche
- Nach-gefilterte Vektor-Suche
Stellen Sie sich zum Beispiel vor, Sie haben eine Tabelle mit dem Chat-Verlauf für die Benutzer Jack, Jan und John, und Sie möchten eine gefilterte Vektor-Suche verwenden, um den Chat-Verlauf von Jack abzurufen, der ähnlich zum angegebenen Abfrage-Vektor ist.
Hinweis:
Jeder Datensatz hat eine Benutzerkennzeichnung und einen Merkmalsvektor - zur Vereinfachung wandeln wir Vektoren in Zahlen um.
Das folgende Bild beschreibt sowohl eine NoSQL- als auch eine SQL-Abfrage zum Abrufen des Chat-Verlaufs von Jack:
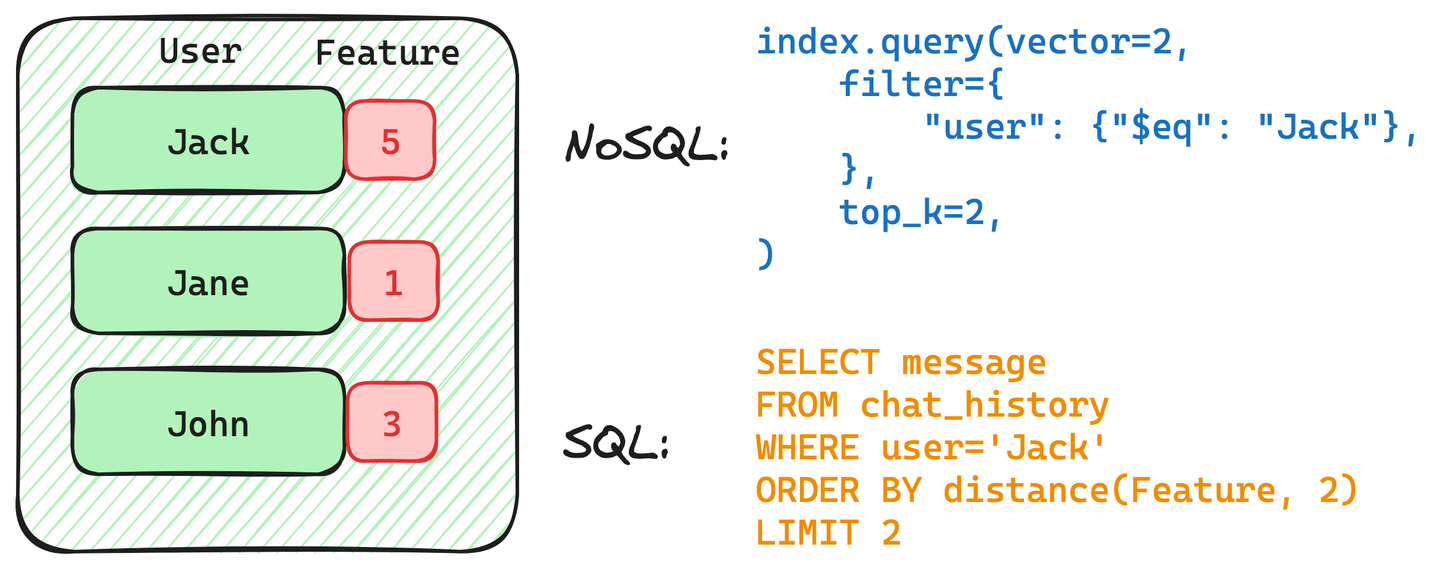
Beide Abfragen enthalten einen Filter für den Benutzer Jack. Dieser Filter kann jedoch je nach Implementierung unterschiedlich strukturiert sein.
1. Vor-gefilterte Vektor-Suche: Bei der vor-gefilterten Vektor-Suche durchsucht der Motor zuerst die Daten und behält nur die Datensätze, die der angegebenen Filterbedingung entsprechen. Sobald dieser Scan abgeschlossen ist, führt der Motor die Vektor-Suche auf den vor-gefilterten Kandidaten durch.
2. Nach-gefilterte Vektor-Suche: Bei der nach-gefilterten Vektor-Suche wird zuerst die Vektor-Suche durchgeführt und dann diese Ergebnisse basierend auf der angegebenen Filterbedingung gefiltert.
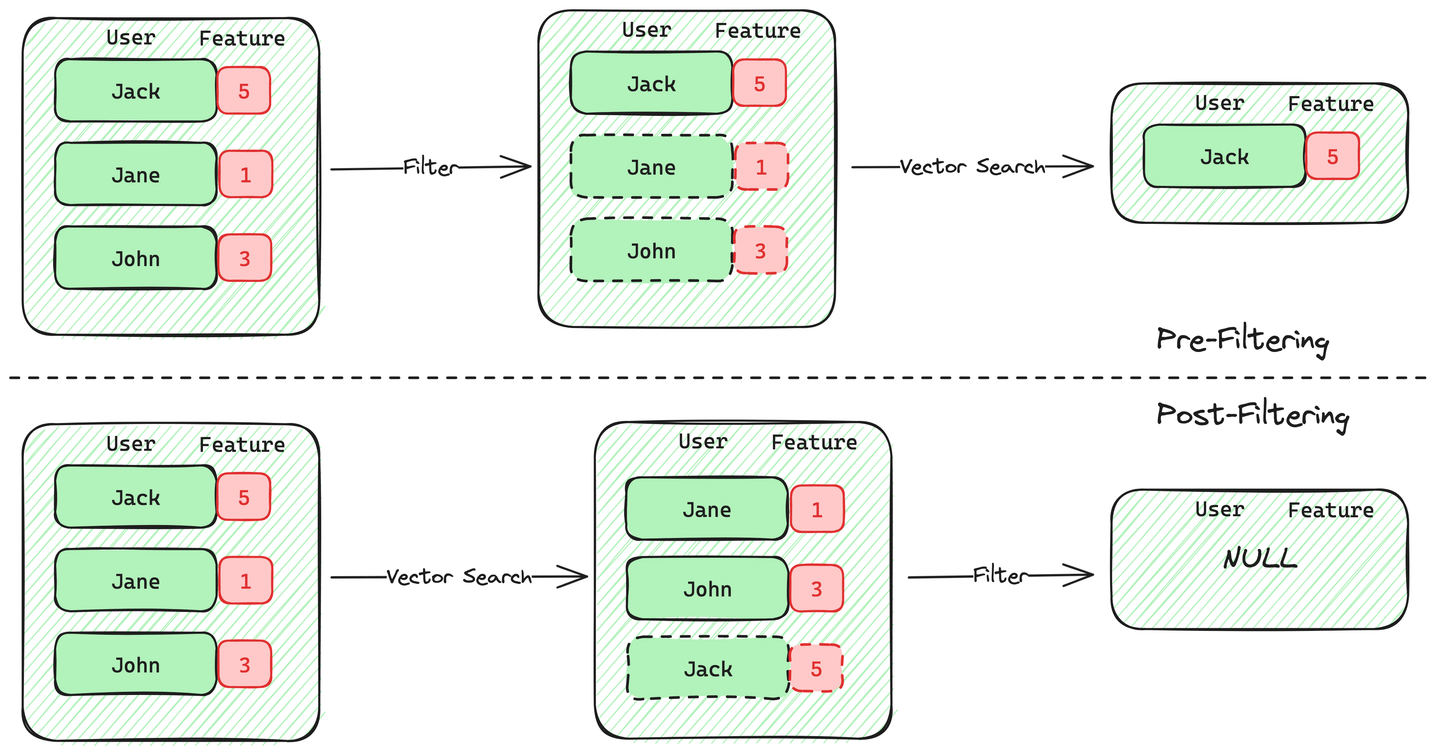
Zwischen diesen beiden Methoden ist die Vor-Filterung genauer und entspricht dem, was wir von einer gefilterten Vektor-Suche erwarten. Die meisten Vektor-Datenbanken unterstützen die Vor-Filterung mit Vektor-Suche. Diese Vor-Filterung ist jedoch nicht kostenlos und erhöht die Berechnung und beeinträchtigt die Leistung der gefilterten Vektor-Suche. Die meisten Implementierungen leiden entweder unter Leistungseinbußen oder Einschränkungen bei den Filtern, wie z.B. Speicherplatz und unterstützte Vergleichsoperatoren.
MyScale verwendet eine spaltenbasierte Speicher-Engine (opens new window), die von der ClickHouse MergeTree-Engine (opens new window) adaptiert wurde und auf herkömmlichen Filtern super schnell ist. Dadurch wird die erste Filterung erheblich verbessert und die gefilterte Vektor-Suche schneller als bei anderen Implementierungen. Darüber hinaus können Sie eine einfache SQL-WHERE-Klausel verwenden, um Filter für beliebige Spalten in Ihrer Tabelle zu definieren.
# Was Sie mit der WHERE-Klausel in MyScale tun können
Da MyScale auf ClickHouse (opens new window) entwickelt wurde, bietet es genau die gleiche Funktionalität wie ClickHouse.
Zum Beispiel:
| Methode | Andere | MyScale |
|---|---|---|
| eq / neq | ✅ | ✅ |
| ge / gt / lt / le | ✅ | ✅ |
| include / exclude | ✅ | ✅ |
mit Zeichenkettenmusterabgleich LIKE | ❌ | ✅ |
| Zeitstempel/Geo-Daten/JSON | ❌ | ✅ |
| mit Funktion | ❌ | ✅ |
| mit arrayFunction (opens new window) | ❌ | ✅ |
| mit Unterabfragen | ❌ | ✅ |
Werfen wir einen Blick auf mehrere Beispiele, die zeigen, wozu die WHERE-Klausel von MyScale in der Lage ist.
Hinweis:
Den Code für diese Beispiele finden Sie in unseren Colab- oder GitHub-Räumen.
![]()
![]()
Hinweis:
Weitere Informationen zu Datentypen und Funktionen finden Sie in der offiziellen Dokumentation von ClickHouse (opens new window).
# Vergleich von Werten: =, !=, >, <, >=, <=
Die meisten Vektor-Indexlösungen unterstützen diese Operationen für Zeichenketten oder Zahlen. In MyScale können Sie Wertvergleiche mit folgendem Code schreiben:
WHERE spalte = wert
Die Spalte kann dabei jeder Spaltenname in der Tabelle sein und die Operation kann eine der folgenden sein: =, !=, >, <, >=, <=.
Hinweis:
Der Spaltentyp und der Wert müssen übereinstimmen.
Wenn Sie mehrere Bedingungen zur WHERE-Klausel hinzufügen möchten, verwenden Sie logische Operatoren wie AND, um sie zu verbinden:
WHERE spalte_1 = wert_1 AND spalte_2 >= wert_2
# Gemeinsame Mengenoperatoren: Include, Exclude
MyScale unterstützt auch Mengenoperationen wie IN und NOT IN:
WHERE spalte IN (wert_1, wert_2, ...)
Dies ist nützlich, wenn Sie eine Menge von Zeilen auswählen möchten. Sie können auch logische Operatoren verwenden, um diese Mengenoperatoren mit anderen Bedingungen zu verbinden.
# Operatoren für Arrays
Sie können überprüfen, ob ein Element in einem Array enthalten ist, mit der Funktion has:
WHERE has(spalte, wert_1)
# Zeichenkettenmusterabgleich
Sie können in MyScale Zeichenkettenmuster mit dem Schlüsselwort LIKE abgleichen:
WHERE spalte_1 LIKE '%wert%'
Diese Bedingung passt zu Werten, die wert in der Spalte_1 enthalten. Dieser Zeichenkettenmusterabgleichsoperator ist einer von vielen Operatoren, die von MySQL angeboten werden. Andere umfassen NOT LIKE, match mit regulären Ausdrücken und ngramSearch.
Hinweis:
Weitere Informationen zum LIKE-Operator finden Sie in der offiziellen Dokumentation von ClickHouse (opens new window).
# Datum-Zeit-Vergleich
MyScale enthält auch eine Funktion für den Vergleich von Datum und Zeit:
WHERE dateDiff('hour', spalte_datetime, toDateTime('2018-01-02 23:00:00')) >= 25;
Diese WHERE-Klausel bezieht sich auf alle Zeilen, deren spalte_datetime später als das angegebene Datum und die angegebene Uhrzeit um mehr als 25 Stunden ist. Diese Funktion unterstützt auch Sekunden, Minuten, Tage und Monate.
Hinweis:
Weitere Informationen finden Sie hier (opens new window).
# Geo-Daten-Vergleich
MyScale kann den H3-Index (opens new window) und die S2-Geometrie (opens new window) verarbeiten, leistungsstarke Werkzeuge für die Routenplanung und Geometrieanalyse.
Mit dem H3-Index können Sie beispielsweise den Bereich eines Hexagons verwenden, um geografische Daten in einem bestimmten Bereich zu filtern:
WHERE h3CellAreaM2(spalte_h3) > 1000
Sie können auch die Entfernung zu einem bestimmten H3-Index hinzufügen:
WHERE h3Distance(spalte_h3, wert_h3) > 10
# Beliebige Objekte mit JSON-Spalten
MyScale ermöglicht es Ihnen, JSON als Objekt zu speichern und nach seinen Attributen zu filtern.
Sie können den JSON-Datentyp verwenden, um eine JSON-Zeichenkette in eine Tabelle zu importieren und die folgende WHERE-Klausel verwenden, um Ergebnisse zu filtern:
WHERE spalte_json.attr_1 = wert_1
Sie können auch nach verschachtelten Attributen filtern:
WHERE spalte_json.attr_1.attr_2 = wert_1
Obwohl dies ein experimentelles Feature (opens new window) ist, ist es leistungsstark. Wir haben diese Objekte in unseren Implementierungen von LangChain (opens new window) und LlamaIndex (opens new window) verwendet.
# Wertfunktionen
MyScale enthält viele Funktionen zur Verarbeitung von Spaltendaten, die Sie in WHERE-Klauseln verwenden können, wie z.B.:
WHERE abs(spalte_1) > 5
Sie können mehrere Spalten in Ihre WHERE-Klausel einbeziehen:
WHERE spalte_1 + spalte_2 + spalte_3 > 10
# Array-Funktionen
Array-Funktionen sind besonders leistungsstark, insbesondere bei unserer Vektor-Suche. In unserer Dokumentation (opens new window) haben wir Array-Funktionen in MyScale für die Berechnung der finalen Logits und Gradienten für unseren Few-Shot-Klassifikator vorgestellt.
ClickHouse hat eine großartige Dokumentation zu Array-Funktionen (opens new window).
Hinweis:
Wenn Sie immer noch Hilfe bei Array-Funktionen in MyScale benötigen, treten Sie unserem Discord (opens new window) bei und fragen Sie nach.
# Unterabfragen
Unterabfragen sind Abfragen innerhalb von Abfragen. Sie können auch eine WHERE-Klausel mit einer anderen SELECT-Abfrage schreiben, wie folgt:
WHERE spalte_1 IN (SELECT ... FROM andere_tabelle WHERE ...)

# Leistung der gefilterten Vektor-Suche
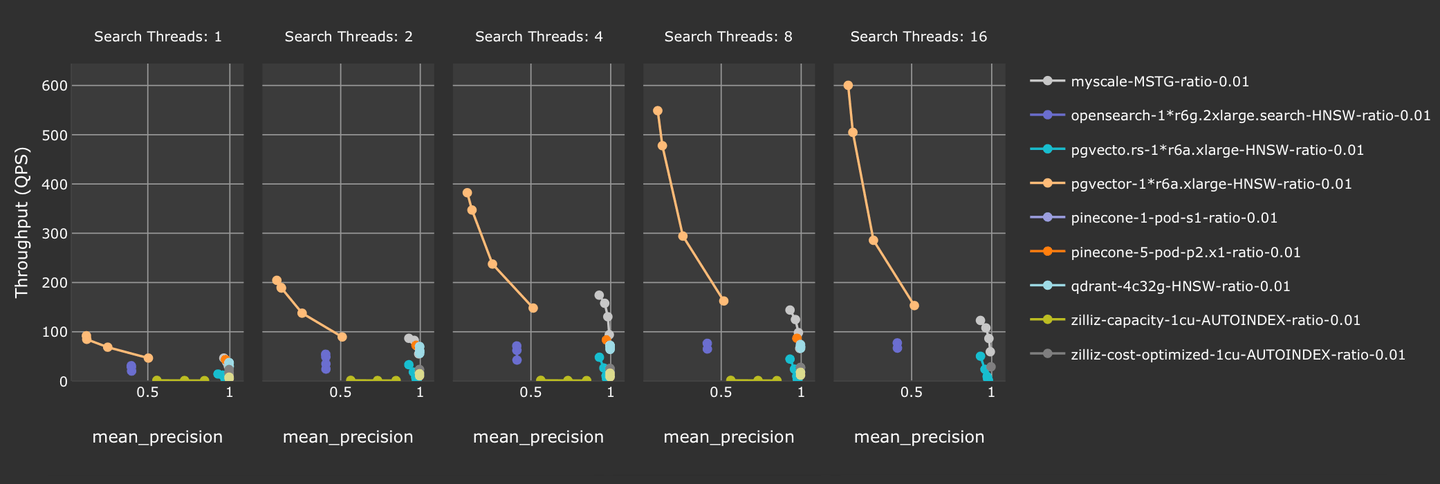
Wir haben die Leistung der gefilterten Vektor-Suche in vector-db-benchmark (opens new window) untersucht. Wir haben laion-768-5m-ip-probability verwendet, bei dem eine zufällige Gleitkommazahl als Filtermarkierung während der Abfrage hinzugefügt wird. Wir haben auch beliebte Vektor-Datenbanklösungen mit MyScale getestet. Wie das folgende Diagramm zeigt, übertrifft MyScale die meisten anderen Vektor-Datenbanklösungen, indem wir eine bessere Genauigkeit bei höherer Durchsatzrate bieten.
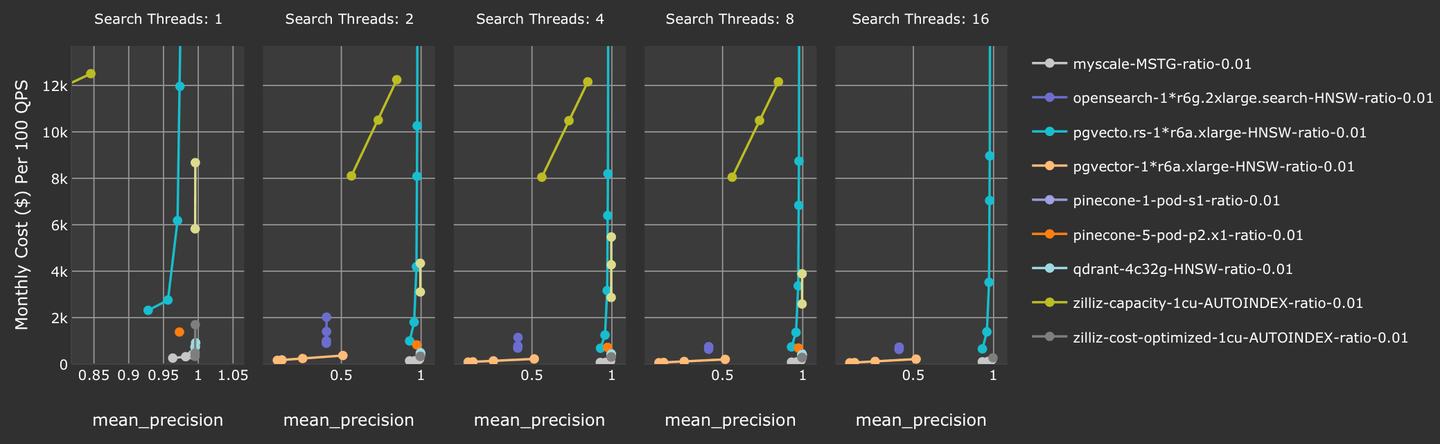
Darüber hinaus erzielt MyScale die beste Kosten-Effizienz aller getesteten Vektor-Datenbanken, wenn die Genauigkeit >= 90% ist. Im Vergleich zu anderen SQL-integrierten Vektor-Datenbanken wie pgvector und pgvector.rs ist MyScale die einzige SQL- und Vektor-integrierte Datenbank, die eine produktionsbereite Genauigkeit und Durchsatzrate für gefilterte Suchen bietet.
Hinweis:
Weitere Informationen finden Sie in unserem Blog Vergleich von pgvector und MyScale (opens new window).
Zusammenfassend bietet MyScale eine bessere Genauigkeit bei höherer Durchsatzrate zu geringeren Kosten. Wir unterstützen auch 5 Millionen Vektoren mit mehr Datentypen und Funktionen in unserem s1-Pod in der Produktlinie, der für alle registrierten Benutzer kostenlos ist.
# Fazit
Gefilterte Suche ist ein häufiger Abfragetyp in Vektor-Datenbanken, der es Ihnen ermöglicht, ähnliche Vektoren oder Datenpunkte basierend auf bestimmten Kriterien oder Filtern zu suchen, insbesondere wenn es um Daten geht, die als Vektoren dargestellt werden können, wie Text- und Bild-Einbettungen oder andere strukturierte Daten.
MyScale integriert SQL-Power in KI-Technologie; die gefilterte Suche ist ein Beispiel dafür und ermöglicht anspruchsvollere und flexiblere Abfragefähigkeiten für Vektor-Datenbanken. Durch die Kombination von KI und SQL können Sie komplexe Datenoperationen und -suchen durchführen, was die Extraktion wertvoller Erkenntnisse, die Entdeckung von Mustern und die Durchführung verschiedener analytischer Aufgaben erleichtert.
Wenn Sie daran interessiert sind, wie SQL Ihre KI-Anwendungen verbessern kann, treten Sie uns noch heute auf Discord (opens new window) oder X (opens new window) bei.



