
Mit dem Aufkommen von KI haben Vektordatenbanken aufgrund ihrer Fähigkeit, große Mengen hochdimensionaler Daten effizient zu speichern, zu verwalten und abzurufen, erhebliche Aufmerksamkeit erlangt. Diese Fähigkeit ist entscheidend für KI- und generative KI (GenAI)-Anwendungen, die sich mit unstrukturierten Daten wie Texten, Bildern und Videos befassen.
Die Hauptlogik hinter einer Vektordatenbank besteht darin, Ähnlichkeitssuchfunktionen anstelle von Schlüsselwortsuchen bereitzustellen, wie es herkömmliche Datenbanken tun. Dieses Konzept wurde weitgehend übernommen, um die Leistung großer Sprachmodelle (LLMs) zu steigern, insbesondere nach der Veröffentlichung von ChatGPT.
Das größte Problem bei LLMs ist, dass sie erhebliche Ressourcen, Zeit und Daten für die Feinabstimmung erfordern, was es sehr schwierig macht, sie auf dem neuesten Stand zu halten. Deshalb geben LLMs bei Abfragen zu aktuellen Ereignissen oft Antworten, die faktisch falsch, unsinnig oder nicht mit der Eingabeaufforderung verbunden sind und zu "Halluzinationen" führen.
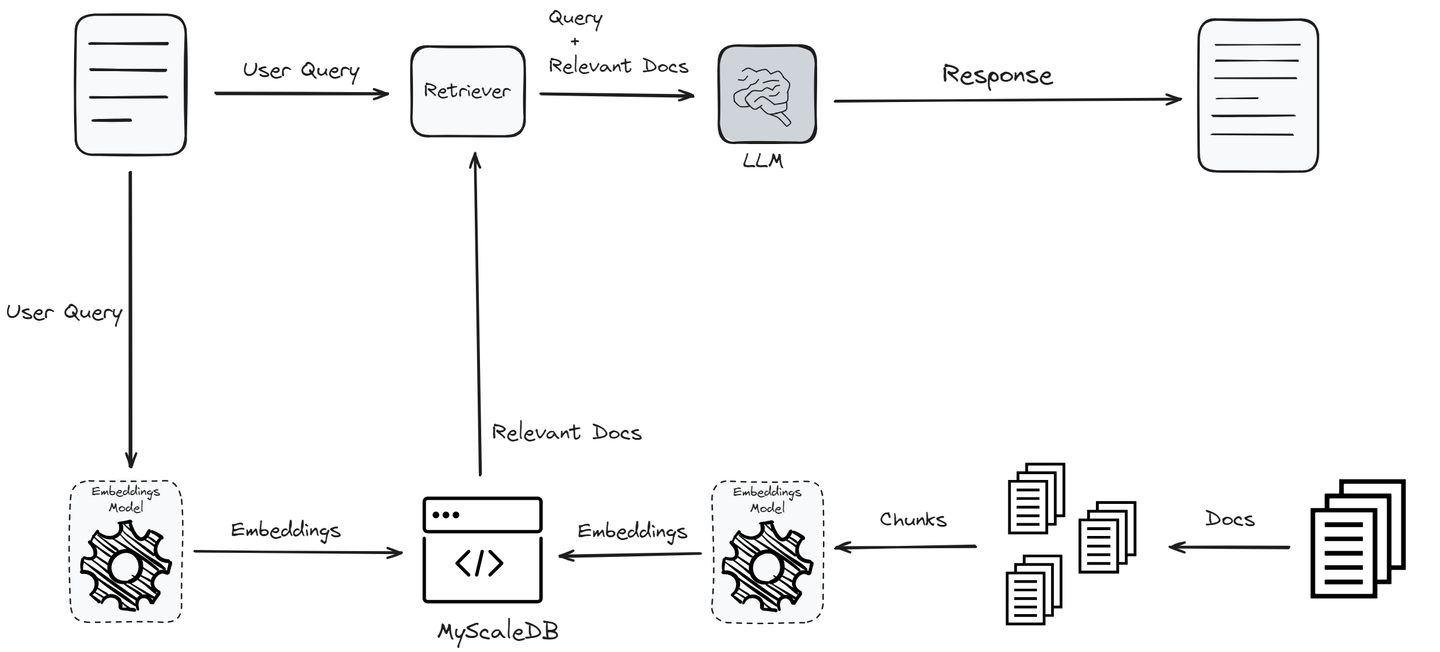
Eine Lösung dafür ist retrieval-augmented generation (RAG) (opens new window), bei der ein LLM durch die Integration aktueller Informationen aus einer externen Wissensbasis erweitert wird. Spezialisierte Vektordatenbanken sind darauf ausgelegt, vektorisierte Daten effizient zu verarbeiten und robuste semantische Suchfunktionen bereitzustellen. Diese Datenbanken sind optimiert für die Speicherung und Abfrage hochdimensionaler Vektoren, die für Ähnlichkeitssuchen sehr wichtig sind. Die Geschwindigkeit und Effizienz von Vektordatenbanken haben sie zu einem integralen Bestandteil von RAG-Systemen gemacht.
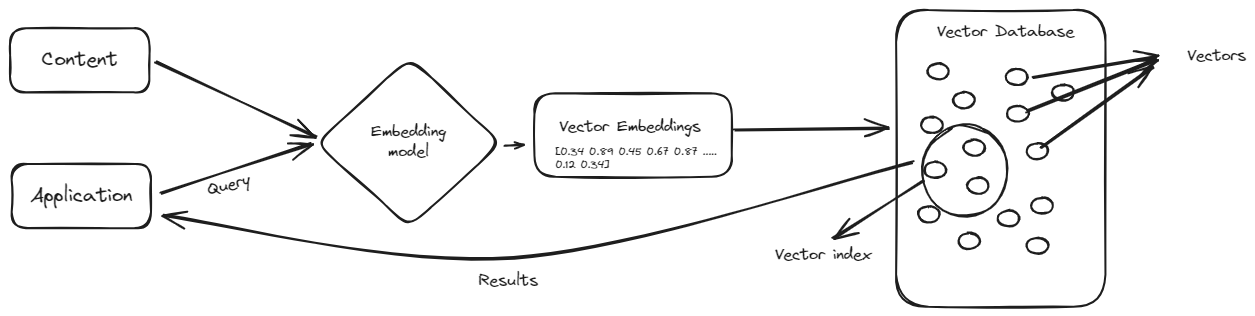
Die Begeisterung für Vektordatenbanken hat viele Menschen dazu veranlasst, vorzuschlagen, dass herkömmliche Datenbanken möglicherweise durch Vektordatenbanken ersetzt werden könnten. Anstatt Daten in herkömmlichen (SQL- oder NoSQL-)Datenbanken zu speichern, könnten Sie den gesamten Datensatz einer Organisation in einer Vektordatenbank speichern und ihn mithilfe natürlicher Sprache anstelle von manuellen Abfragen abrufen?
Aber Vektordatenbanken funktionieren nicht wie herkömmliche Datenbanken. Wie Andrey Vasnetsov, CTO von Qdrant, schrieb, "sind die meisten Vektordatenbanken in diesem Sinne keine Datenbanken. Es ist genauer, sie als Suchmaschinen zu bezeichnen." Denn ihr Hauptzweck besteht darin, optimierte Suchfunktionen bereitzustellen, und sie sind nicht darauf ausgelegt, grundlegende Funktionen wie Schlüsselwortsuche oder SQL-Abfragen zu unterstützen.
# Einschränkungen von spezialisierten Vektordatenbanken
Mit dem Wachstum der Anwendungsfälle und dem Fokus der Menschen auf die Skalierbarkeit ihrer Anwendungen wurden die Einschränkungen von Vektordatenbanken deutlicher. Entwickler erkannten bald, dass sie immer noch die Funktionen einer Volltextsuchmaschine zusammen mit der Vektorsuche benötigen. Zum Beispiel ist es mit Vektordatenbanken sehr schwierig, Suchergebnisse basierend auf bestimmten Kriterien zu filtern. Diese Datenbanken bieten auch keine direkten Übereinstimmungen für exakte Phrasen, die für viele Aufgaben entscheidend sind.
# Begrenzte Unterstützung für komplexe Abfragen
Komplexe Abfragen beinhalten oft mehrere Bedingungen, Verknüpfungen und Aggregationen, was sie für spezialisierte Vektordatenbanken herausfordernd macht. Diese Datenbanken bieten begrenzte Unterstützung für komplexe Abfragen durch Metadatenfilterung. Die Metadatenspeicherung ist jedoch in Vektordatenbanken sehr begrenzt, was die Fähigkeit der Benutzer einschränkt, eine Vielzahl von komplexen Abfragen durchzuführen.
Im Gegensatz dazu sind SQL-Datenbanken darauf ausgelegt, umfangreiche Speicherung und Verarbeitung zu bewältigen, was eine effiziente Ausführung komplexer Abfragen mit mehreren Bedingungen, Verknüpfungen und Aggregationen ermöglicht. Dies macht SQL-Datenbanken weitaus vielseitiger und leistungsfähiger, wenn es darum geht, komplexe Datenabruf- und Manipulationsaufgaben zu bewältigen.
# Einschränkungen bei Datentypen
Spezialisierte Vektordatenbanken stoßen auch auf Einschränkungen bei den Datentypen. Sie sind darauf ausgelegt, Vektoren und minimale Metadaten zu speichern, was ihre Flexibilität einschränkt. Diese Fokussierung auf Vektoren bedeutet, dass sie nicht mit der Vielzahl von Datentypen umgehen können, die SQL-Datenbanken verarbeiten können, wie Ganzzahlen, Zeichenketten und Datumsangaben, was komplexere und vielfältigere Datenoperationen ermöglicht.
Insgesamt haben spezialisierte Vektordatenbanken einen sehr engen Fokus. Ihre Architektur ist in erster Linie auf die semantische Suche optimiert und nicht auf die breiteren Anforderungen der Datenverwaltung. Dies begrenzt ihre Funktionalität, um eine Vielzahl von Aufgaben auszuführen, die von vielseitigeren Systemen wie SQL-Datenbanken problemlos bewältigt werden können. Darüber hinaus sind sie aufgrund ihrer Unfähigkeit, verschiedene Datentypen über Vektoren hinaus zu speichern und zu verwalten, weniger geeignet für allgemeine Datenbankaufgaben. Vektordatenbanken eignen sich gut für RAG-Anwendungen, sind aber nicht vielseitig genug für breitere Anwendungsfälle.
# Integrationsherausforderungen
Die Integration spezialisierter Vektordatenbanken in bestehende IT-Infrastrukturen ist mit Herausforderungen verbunden. Kompatibilitätsprobleme treten häufig aufgrund der inhärenten Unterschiede zwischen spezialisierten Vektordatenbanken und vorhandenen Systemen auf, was eine erhebliche Datenumwandlung und potenziellen Datenverlust oder Datenkorruption erforderlich macht. Die Sicherstellung der Interoperabilität mit Legacy-Systemen und die Aufrechterhaltung von Datenkonsistenz und -integrität sind ebenfalls komplexe Aufgaben. Darüber hinaus erfordert der Integrationsprozess spezialisierte Fähigkeiten, die möglicherweise nicht leicht verfügbar sind, was zu hohen Schulungskosten und einer steilen Lernkurve führt.
Darüber hinaus sind die finanziellen Auswirkungen der Integration erheblich. Die Kosten umfassen Softwarelizenzen, Hardware-Upgrades, Schulungen des Personals und laufende Wartung. Darüber hinaus müssen vorhandene Anwendungen möglicherweise geändert oder neu geschrieben werden, um mit der Vektordatenbank zu interagieren, was ein kostspieliger und riskanter Prozess ist, der das Potenzial für das Einführen neuer Fehler oder Leistungsprobleme birgt. Der Bedarf an kontinuierlicher Unterstützung und Aktualisierungen für die spezialisierte Vektordatenbank kann auch langfristige finanzielle Verpflichtungen nach sich ziehen.
# Datenverarbeitung erfordert einen hybriden Ansatz
Die Grundlagen einer spezialisierten Vektordatenbank sind die Speicherung von Vektoren und die Vektorsuche, hauptsächlich für RAG-Anwendungen. Traditionelle Datenbanken sollten jedoch auch in der Lage sein, Vektoren zu verarbeiten,** **und die Vektorsuche ist ein Abfrageverarbeitungsansatz, kein Fundament für eine neue Art der Datenverarbeitung.
RAG ist eine beliebte KI-Technik, die von Vektordatenbanken profitiert. Während Vektordatenbanken sich hervorragend für semantische Suchen und die Verarbeitung hochdimensionaler Daten eignen, übersehen ihre fokussierten Fähigkeiten oft die betrieblichen und funktionalen Bedürfnisse einer Organisation. Dies kann ihre Verwendung in breiteren Anwendungen mit vielfältigen betrieblichen und funktionalen Anforderungen einschränken.
Auch herkömmliche Datenbanken haben versucht, Vektorspeicherung und Vektorsuchfunktionen zu integrieren, um eine effiziente Lösung für die groß angelegte Verarbeitung komplexer Datentypen anzubieten. Zum Beispiel haben PostgreSQL und Elasticsearch Vektorsuchfunktionen eingeführt. Ihre Vektorsuchleistung ist jedoch nicht so gut und hinkt spezialisierten Vektordatenbanken wie Pinecone und Qdrant hinterher. Zum Beispiel erreicht Qdrant eine durchschnittliche Latenzzeit von nur 45,23 ms bei einer Präzisionsrate von 0,9822. Im Vergleich dazu weist OpenSearch zwar eine robuste Leistung auf, hat jedoch eine höhere Latenzzeit von 53,89 ms und eine etwas niedrigere Präzision von 0,9823.
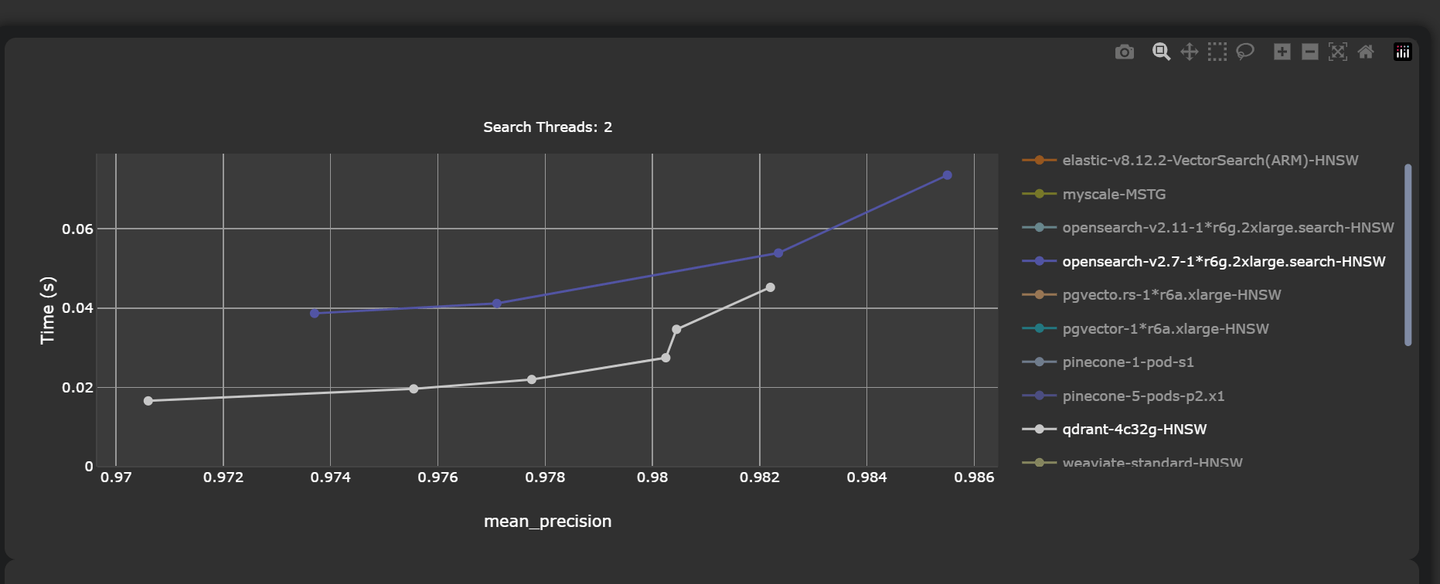
Hinweis:
Vollständige Benchmarks finden Sie hier (opens new window).
Die Architektur spezialisierter Vektordatenbanken ist speziell darauf ausgelegt, hochdimensionale Vektordaten effizient zu verarbeiten, während herkömmliche Datenbanken hauptsächlich für relationale Daten entwickelt wurden und die spezifischen Anforderungen der Vektorsuche nicht natürlicherweise unterstützen.
Eine andere Option besteht darin, Vektorextensionen zu Ihrer aktuellen Datenbank oder Suchmaschine hinzuzufügen. Dieser Ansatz unterstützt die Geschäftsanforderungen direkt, indem er die Stärken und Flexibilität herkömmlicher Datenbanken mit den erweiterten Funktionen moderner Vektorsuchen kombiniert.
Ein hybrides Modell kann den unterschiedlichen Anforderungen der Datenverarbeitung eines Unternehmens näher kommen und seine Dateninfrastruktur optimieren. Dies kann die Betriebskosten und Komplexität reduzieren und letztendlich zu einer skalierbareren und effizienteren Lösung führen, die den umfassenden Datenverarbeitungsanforderungen der Organisation gerecht wird.
# SQL-Vektordatenbanken schließen die Lücke - Vorstellung von MyScaleDB
SQL ist seit einem halben Jahrhundert das Rückgrat skalierbarer Anwendungen, und seine Integration mit Vektorsuchfunktionen steht kurz davor, die Lücke zwischen traditionellen und modernen Datenverarbeitungsanforderungen zu schließen. Die Integration von SQL mit Vektoren verbessert die Flexibilität der Datenmodellierung und vereinfacht die Entwicklung. Dadurch kann das System komplexe Abfragen mit strukturierten Daten, Vektordaten, Schlüsselwortsuchen und verbundenen Abfragen über mehrere Tabellen hinweg bewältigen.
Während spezialisierte Vektordatenbanken sich hervorragend für die Verarbeitung hochdimensionaler Daten mit Präzision und Geschwindigkeit eignen, bietet die Integration der Vektorsuche in SQL-Datenbanken eine überzeugende Alternative. Sie bietet ein Gleichgewicht zwischen der für die Verarbeitung komplexer Datentypen in großem Maßstab erforderlichen Effizienz und dem Komfort, innerhalb eines vertrauten und weit verbreiteten Frameworks zu arbeiten. Diese Integration löst viele Herausforderungen, denen spezialisierte Vektordatenbanken gegenüberstehen, wie langsame Iteration, ineffiziente Abfragen und hohe Kosten für die Verwaltung einer separaten Datenbank. Durch die Nutzung von SQL-Vektordatenbanken können Unternehmen die Leistungsfähigkeit der bewährten Skalierbarkeit und Zuverlässigkeit von SQL nutzen und gleichzeitig fortschrittliche Funktionen nutzen, die erforderlich sind, um die vielfältigen Herausforderungen der modernen Datenverarbeitung zu bewältigen.
MyScaleDB (opens new window) ist eine solche Open-Source-SQL-Vektordatenbank, die auf ClickHouse aufbaut. Sie kombiniert die Stärken herkömmlicher SQL-Datenbanken mit den Fähigkeiten von Vektordatenbanken und verwaltet hochdimensionale Vektoren effizient mithilfe von SQL für GenAI-Anwendungen. Sie bietet umfassende Datenabfrage durch erweiterte Filterung und komplexe SQL-Vektorabfragen, unterstützt durch Text-to-SQL für eine einfache Bedienung.
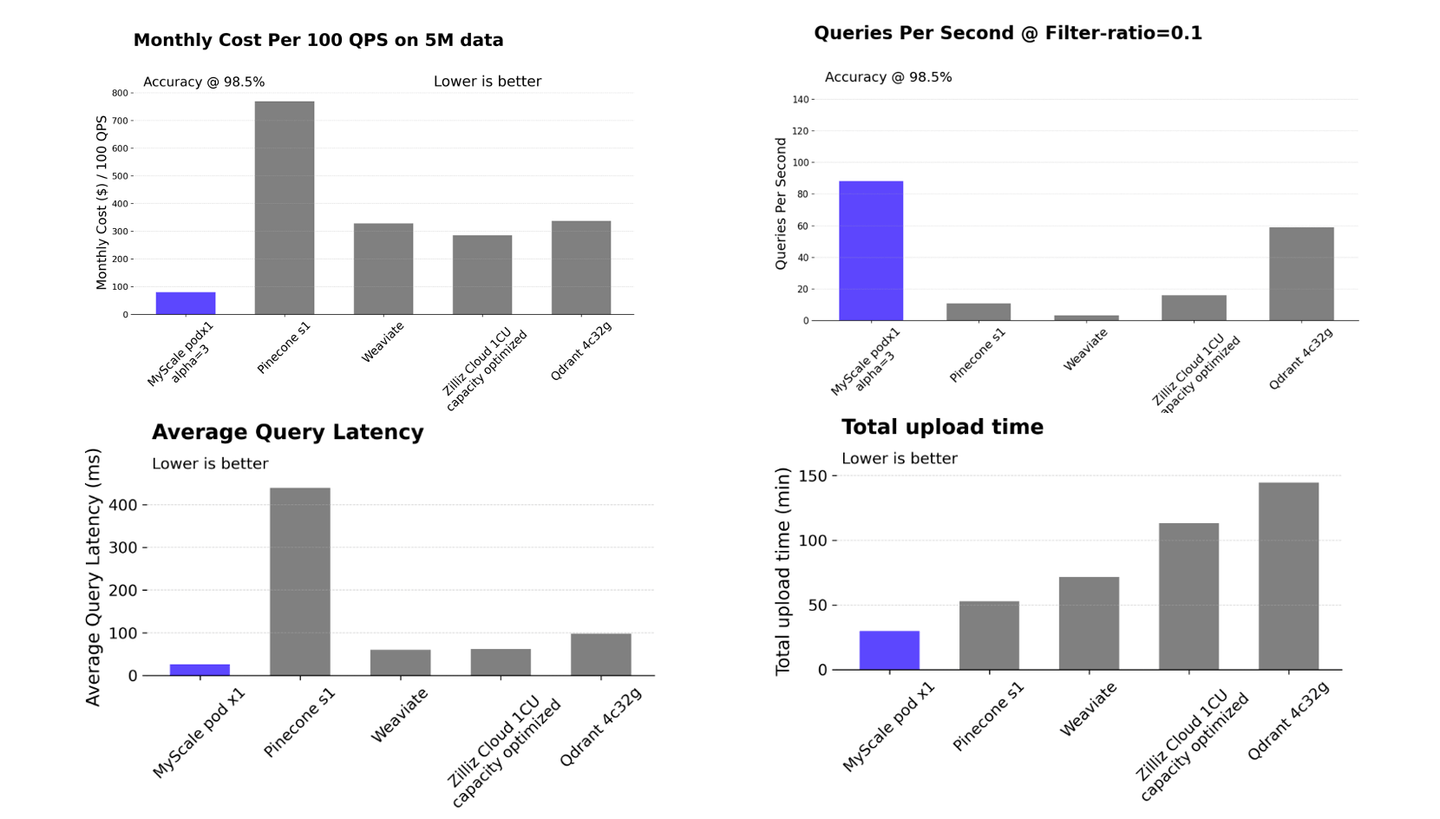
MyScaleDB ist schneller und kostengünstiger (opens new window) als spezialisierte Vektordatenbanken, wobei der proprietäre MSTG-Indexierungsalgorithmus die Abrufung von Vektordaten optimiert, um die Effizienz des Systems zu verbessern. Darüber hinaus zeichnet sich MyScaleDB im Vergleich zu vektorbasierten SQL/NoSQL-Datenbanken (opens new window) durch seine überlegene Leistung und Skalierbarkeit aus, insbesondere bei der Handhabung verschiedener Filterverhältnisse.

# Fazit
Sich ausschließlich auf eine spezialisierte Vektordatenbank zu verlassen, die nur Vektoren verarbeitet, begrenzt die Flexibilität deiner Datenverwaltungsstrategie. Eine multifunktionale oder integrierte Vektordatenbank bietet eine vielversprechendere Lösung. MyScaleDB verwaltet nicht nur Vektoren effizient, sondern fungiert auch als allgemeine Datenbank und bietet somit eine vielseitige und leistungsstarke Lösung für moderne KI-Anwendungen.
Eine Datenbank zu haben, die sowohl strukturierte als auch Vektordaten verwalten kann, ist in der heutigen KI-Technologiewelt entscheidend. Dieser Ansatz gewährleistet Skalierbarkeit, Flexibilität und Kosteneffizienz und beseitigt die Notwendigkeit, mehrere Systeme zu verwalten. Durch die Wahl einer vielseitigen Datenbank können Sie Ihre Dateninfrastruktur auf die Zukunft vorbereiten und den steigenden Anforderungen moderner Anwendungen gerecht werden.



