
Retrieval-Augmented Generation (RAG) (opens new window) hat sich als revolutionäre Technik im Bereich Natural Language Processing (NLP) und Large Language Models (LLMs) erwiesen. Es kombiniert traditionelle Sprachmodelle mit einem innovativen Abrufmechanismus, der es den Sprachmodellen ermöglicht, auf eine umfangreiche Wissensbasis (opens new window) zuzugreifen, um die Qualität und Relevanz ihrer Antworten zu verbessern. RAG ist besonders vorteilhaft in Szenarien, in denen detaillierte und aktuelle Informationen benötigt werden, wie z.B. akademische Forschung, Kundenservice und Content-Erstellung.
RAG wird besser, wenn es im großen Maßstab eingesetzt wird, aber das bringt auch einige Herausforderungen mit sich. Mit dem rapiden Wachstum der Informationen muss RAG schnell durch große Mengen unstrukturierter Daten sortieren. Das Problem besteht darin, das System zu vergrößern, ohne Geschwindigkeit oder Genauigkeit zu beeinträchtigen. RAG wird oft mit spezialisierten Vektor-Datenbanken implementiert, die speziell zur Speicherung von Informationen als Vektoren entwickelt wurden. Diese Datenbanken können jedoch Probleme bei der Bearbeitung komplexer Abfragen haben, was die Effektivität des Systems bei komplexen Fragen beeinträchtigen kann.
# Herausforderungen spezialisierter Vektor-Datenbanken
Es besteht kein Zweifel daran, dass spezialisierte Vektor-Datenbanken gut darin sind, Vektordaten zu verarbeiten, aber sie haben ihre eigenen Probleme.
- Spezialisierte Vektor-Datenbanken sind nicht mit ausgereiften Datensystemen kompatibel
Ein großes Problem besteht darin, spezialisierte Vektor-Datenbanken in bestehende große Datensysteme zu integrieren. Die meisten Unternehmen verwenden SQL-Datenbanken für ihre großen Datensammlungen. Der Übergang zu spezialisierten Vektor-Datenbanken kann erhebliche Integrationsprobleme verursachen, Dateninseln verursachen und die Zusammenarbeit mit anderen Systemen erschweren.
- Spezialisierte Vektor-Datenbanken haben Schwierigkeiten bei der Bearbeitung komplexer Datenszenarien
Spezialisierte Vektor-Datenbanken sind in erster Linie für die Durchführung von nächsten Nachbarschaftssuchen (opens new window) konzipiert. Sie stoßen jedoch auf Herausforderungen bei Abfragen, die mit zeitbasierten oder Aggregatfunktionen (opens new window) zusammenhängen. Diese Einschränkung kann in Szenarien, in denen solche Abfragen wesentlich sind, Probleme verursachen und die Integration und Nutzung in verschiedenen Datenumgebungen erschweren.
- Spezialisierte Vektor-Datenbanken sind nicht benutzerfreundlich für Entwickler
Darüber hinaus können Datenwissenschaftler und Ingenieure, die an SQL (opens new window) gewöhnt sind, diese spezialisierten Datenbanken als schwer erlernbar empfinden. Dies kann die Geschwindigkeit, mit der sie übernommen werden, verlangsamen und die Nutzung dieser fortschrittlichen Datenbanken einschränken. Darüber hinaus fehlen Vektor-Datenbanken oft umfassende Funktionen zur Verwaltung strukturierter und relationaler Daten, die in vielen Anwendungen der Industrie immer noch vorherrschen.
Verwandter Artikel: Wie funktioniert RAG? (opens new window)
# Warum SQL für Datenmanagement und -speicherung wichtig ist
SQL ist seit geraumer Zeit das zuverlässige und bewährte Datenbankmanagementsystem. Es ist bekannt für seine Effizienz, Sicherheit und Vielseitigkeit im Umgang mit großen Datenmengen in verschiedenen Branchen.
# SQL kann große Datenmengen verarbeiten
SQL ist bekannt für seine Fähigkeit, große Datenmengen effizient abzufragen und zu verwalten, während Geschwindigkeit und Genauigkeit beibehalten werden. Die Stärke von SQL liegt in seinem optimierten Abfrage-Engine und effizienten Datenstrukturen. SQL-Datenbanksysteme verwenden in der Regel ausgeklügelte Indexierungstechniken und Datenpartitionierungsstrategien, um einen schnellen Zugriff und Abruf von Informationen auch bei der Verarbeitung großer strukturierter Datenmengen zu gewährleisten, was Unternehmen ein reibungsloses Wachstum ermöglicht.
# SQL ist zuverlässig
Zuverlässigkeit ist ein weiteres wichtiges Merkmal von SQL. Diese Zuverlässigkeit ergibt sich aus mehreren Faktoren, die in SQL-Datenbanken inhärent sind, wie z.B. Datenkonsistenz, robuste Mechanismen zur Datenwiederherstellung, Verarbeitung großer Datenmengen und hoher gleichzeitiger Datenverkehr. Die SQL-Datenbank verwendet Optimierungstechniken wie Indexierung, Abfrageoptimierung und Zwischenspeicherung, um eine effiziente Datenabfrage und -verarbeitung sicherzustellen und die Zuverlässigkeit auch bei zunehmender Größe und Komplexität der Datenbank zu gewährleisten.
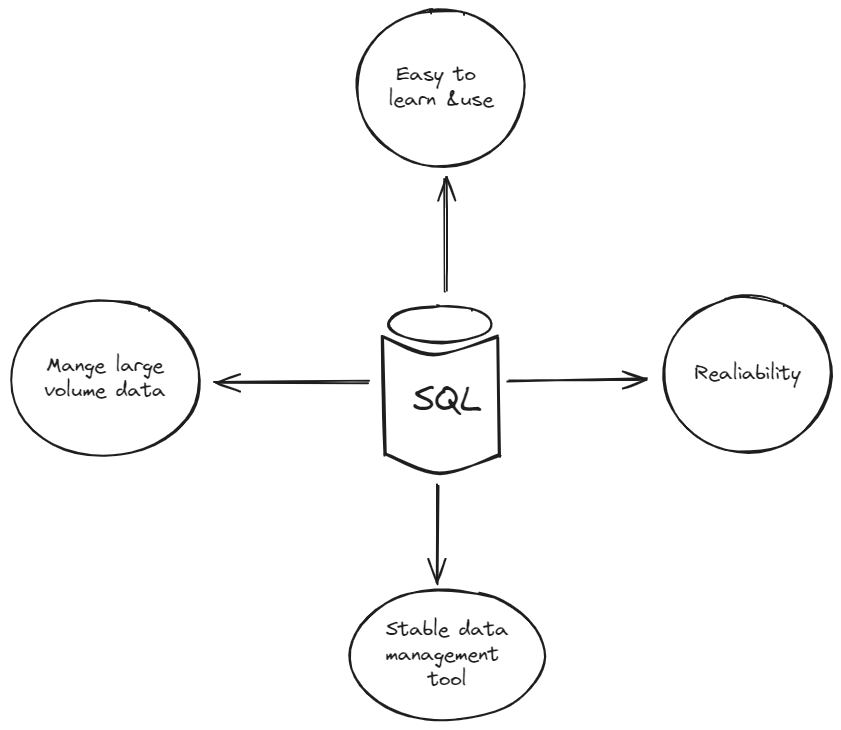
# SQL bietet fortschrittliche Datenverarbeitungswerkzeuge
SQL verfügt auch über leistungsstarke Werkzeuge und Funktionen, um das Datenmanagement zu verbessern. Es ermöglicht Entwicklern, die Abfrageleistung je nach den individuellen Anforderungen und Mustern der Anwendung zu optimieren und zu verbessern. Durch Funktionen wie Indexierung (opens new window), Partitionierung (opens new window) und Abfrageoptimierung verbessert SQL signifikant die Effizienz und Geschwindigkeit der Datenabfrage und -verarbeitung. Dadurch können Apps, die auf Daten angewiesen sind, schneller ausgeführt werden und den Benutzern eine bessere Erfahrung bieten. Darüber hinaus verfügt SQL über großartige Tools zur Suche und Behebung von Verlangsamungen, um sicherzustellen, dass Datenbanken in verschiedenen Situationen gut funktionieren.
Verwandter Artikel: Wenn SQL auf Vektorsuche trifft (opens new window)
# Warum SQL für RAG wichtig ist
Der Aufbau eines Retrieval-Augmented Generation (RAG) Systems birgt mehrere Herausforderungen, aber SQL könnte helfen, diese zu bewältigen:
- SQL kann komplexe Daten abrufen
Die Suche nach relevanten Informationen in umfangreichen und vielfältigen Datensätzen kann komplex sein, insbesondere wenn es um unstrukturierte oder halbstrukturierte Daten (opens new window) wie Textdokumente, Bilder oder Multimedia geht. Die Integration effizienter Abrufmechanismen, die mit dieser Komplexität umgehen können, ist eine große Herausforderung. Die Abfragefähigkeiten von SQL ermöglichen einen effizienten Abruf relevanter Informationen aus diesen Datenquellen. Durch die Generierung von SQL-Abfragen, die auf spezifische Kriterien zugeschnitten sind, und die Nutzung fortschrittlicher Suchfunktionen kann SQL den Datenabrufprozess optimieren und so die Komplexität des Zugriffs auf verschiedene Datensätze bewältigen.
- SQL kann zur Qualitätssicherung von Daten beitragen
Die Sicherstellung der Qualität und Relevanz der abgerufenen Daten ist entscheidend für die Generierung genauer und aussagekräftiger Antworten. Jedoch können störende oder veraltete Daten sowie irrelevante Informationen die Leistung des RAG-Systems negativ beeinflussen. Die Entwicklung von Algorithmen zur effektiven Filterung und Bewertung der abgerufenen Daten ist eine Herausforderung. SQL bietet Mechanismen zur Filterung und Bewertung der abgerufenen Daten basierend auf verschiedenen Kriterien wie Zeitstempeln, Kategorien oder Relevanzbewertungen. Darüber hinaus ermöglichen die Aggregations- und Analysefunktionen von SQL Entwicklern die Vorverarbeitung und Bereinigung von Daten, um deren Qualität vor der Verwendung zur Generierung sicherzustellen.
- SQL kann in Verbindung mit anderen Techniken die Dateninterpretation verbessern
Das Verständnis der semantischen Bedeutung und des Kontexts der abgerufenen Daten ist wichtig für die Generierung kohärenter und relevanter Antworten. Die Interpretation der Feinheiten natürlicher Sprache und des Kontexts ist jedoch eine komplexe Aufgabe, insbesondere bei der Verarbeitung mehrdeutiger oder subjektiver Informationen. Obwohl SQL selbst keine inhärenten Fähigkeiten zur semantischen Interpretation bietet, kann es in Verbindung mit anderen NLP-Techniken wie Embeddings verwendet werden, um das semantische Verständnis der Daten zu verbessern. Entwickler können beispielsweise SQL verwenden, um Daten basierend auf Schlüsselwörtern oder kontextuellen Informationen abzurufen und dann semantische Analysealgorithmen zur weiteren Interpretation der abgerufenen Daten zu verwenden.
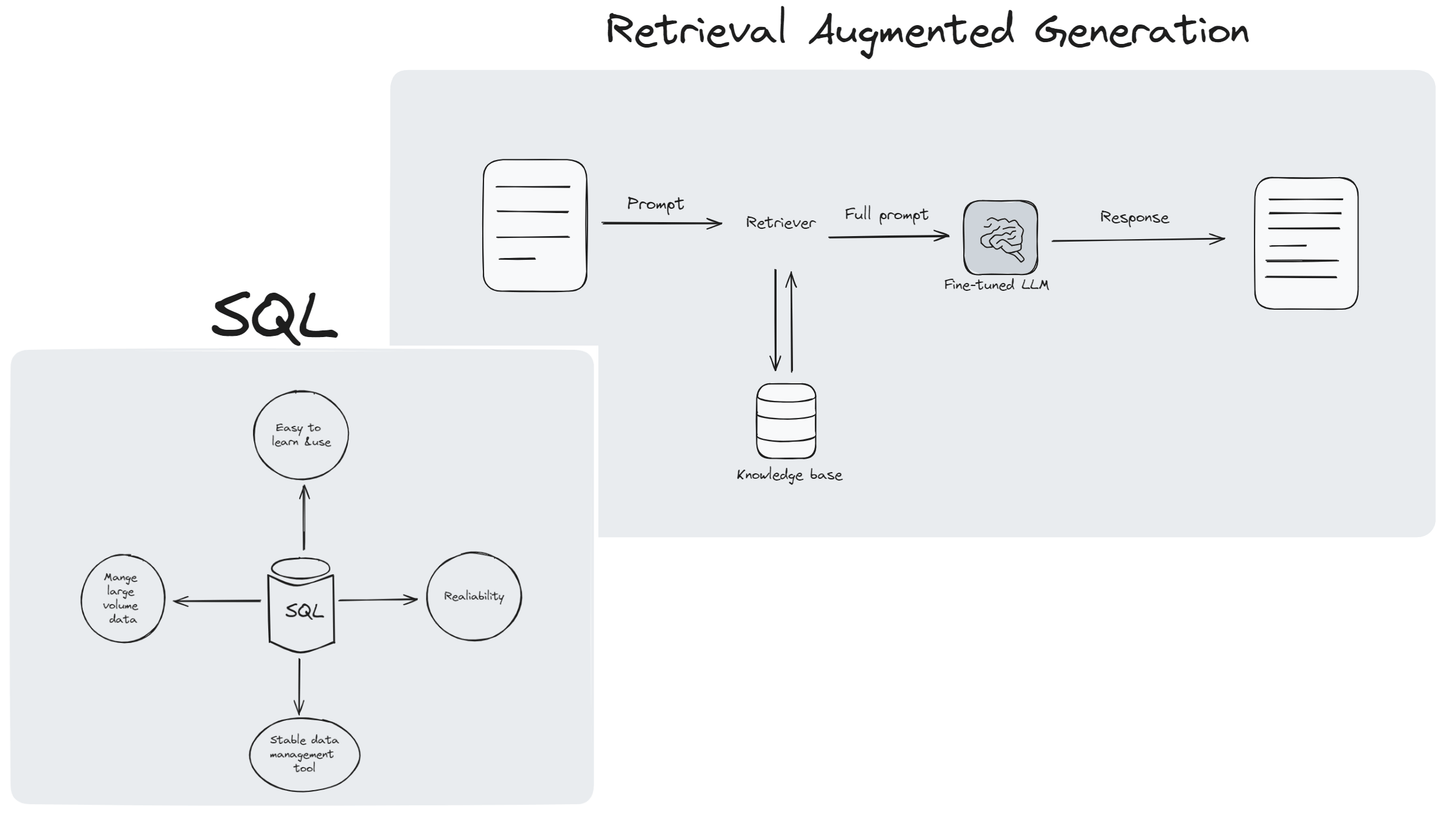
- SQL bietet Skalierbarkeit und Flexibilität
Mit dem Wachstum von Datensätzen in Größe und Komplexität wird die Skalierbarkeit zu einer großen Herausforderung für RAG-Systeme. Um sicherzustellen, dass das System steigende Datenmengen bewältigen kann, während die Leistung und Reaktionsfähigkeit erhalten bleiben, sind effiziente Architekturdesigns und Optimierungsstrategien erforderlich. SQL-Datenbanken sind darauf ausgelegt, große Mengen strukturierter Daten effizient zu verwalten. Die Integration von SQL in RAG-Systeme löst eine der zentralen Herausforderungen im Bereich Künstliche Intelligenz: die Skalierung des Abrufmechanismus, um umfangreiche Datensätze ohne Beeinträchtigung der Leistung zu verarbeiten. Darüber hinaus ermöglicht die Flexibilität von SQL bei der Formulierung von Abfragen RAG die Durchführung komplexer Informationsabfragen und die Anpassung des Umfangs und der Tiefe der während des Generierungsprozesses berücksichtigten Daten.
- SQL hilft bei der Echtzeitdatenabfrage
Die Bereitstellung von Echtzeitantworten ist für viele Anwendungen von RAG-Systemen, wie z.B. Chatbots oder virtuelle Assistenten, entscheidend. Die Erzielung von geringen Latenzzeiten bei gleichzeitiger Aufrechterhaltung der Qualität des generierten Inhalts stellt eine Herausforderung dar, insbesondere in Szenarien mit strengen Latenzanforderungen. SQLs Optimierungstechniken wie Abfragezwischenspeicherung und Indexierung können die Abfrageverarbeitungszeiten erheblich reduzieren und so RAG-Systemen ermöglichen, Echtzeitantworten bereitzustellen.
Verwandter Artikel: Ein umfassender Einblick in SQL-Vektor-Datenbanken (opens new window)

# MyScaleDB - Die beste SQL-Vektor-Datenbank für RAG
Angesichts der rapiden Zunahme von Datenvolumen und der spezifischen Einschränkungen spezialisierter Vektor-Datenbanken haben wir MyScaleDB entwickelt. MyScaleDB (opens new window) ist eine cloudbasierte SQL-Vektor-Datenbank, die speziell für die Verwaltung großer Datenmengen für KI-Anwendungen entwickelt und optimiert wurde. Sie basiert auf ClickHouse (opens new window) (einer SQL-Datenbank) und kombiniert die Fähigkeit zur Vektorähnlichkeitssuche mit vollständiger SQL-Unterstützung. Es handelt sich um eine SQL-Vektor-Datenbank, in der Vektoren zusammen mit strukturierten Daten gespeichert werden können.
Im Gegensatz zu spezialisierten Vektor-Datenbanken integriert MyScaleDB Vektor-Suchalgorithmen nahtlos mit strukturierten Datenbanken, sodass sowohl Vektoren als auch strukturierte Daten in derselben Datenbank verwaltet werden können. Diese Integration bietet Vorteile wie vereinfachte Kommunikation, flexible Metadatenfilterung, Unterstützung für SQL- und Vektorverbundabfragen sowie Kompatibilität mit etablierten Tools, die typischerweise mit vielseitigen Datenbanken für allgemeine Zwecke verwendet werden.
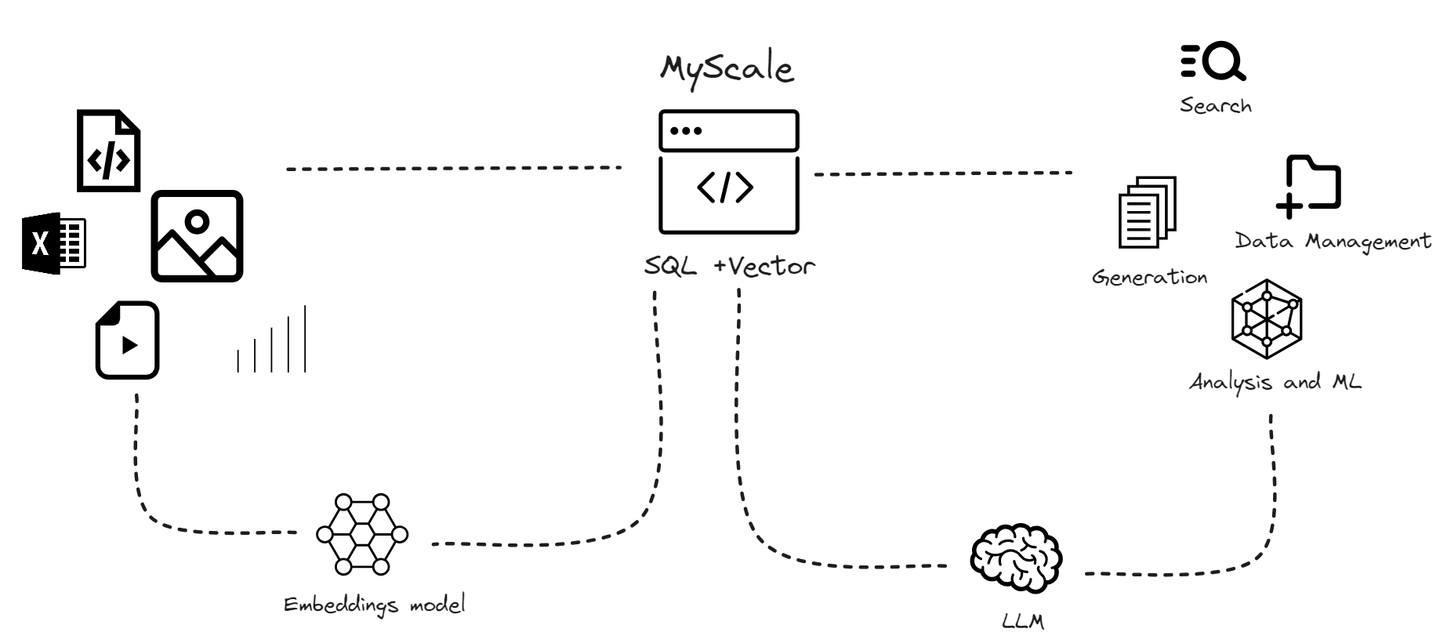
MyScaleDB zeichnet sich durch die Integration von SQL in RAG-Systeme aus. Im Gegensatz zu traditionellen Vektor-Datenbanken, die Schwierigkeiten mit komplexen Abfragen und Kompatibilität haben, ist MyScaleDB darauf ausgelegt, den spezifischen Anforderungen von RAG-Systemen reibungslos gerecht zu werden.
- Erstens ermöglicht die fortgeschrittene Unterstützung von MyScaleDB für komplexe SQL-Abfragen RAG-Systemen die Durchführung anspruchsvoller Datenabrufoperationen, die zuvor nicht möglich waren. Diese Funktion ermöglicht relevantere und kontextuell angemessenere Antworten und verbessert so die Benutzererfahrung.
- MyScaleDB ist speziell für groß angelegte KI-Anwendungen konzipiert und gewährleistet hohe Leistung und Kosteneffizienz. Es bietet auch bei sehr großen Datensätzen mit vollständiger SQL-Unterstützung eine hohe Geschwindigkeit und Genauigkeit. Ein einzelner c1x1-Pod unterstützt bis zu 10 Millionen 768D-Vektoren, während der s1x1-Pod über 150 QPS mit 5 Millionen Vektoren erreicht.
- Darüber hinaus zeichnet sich MyScaleDB durch seine Leistungsmetriken aus und verwaltet mühelos große, komplexe Datensätze und bietet schnellere Reaktionszeiten als traditionelle Vektor-Datenbanken.
Dieser Leistungsvorteil macht MyScaleDB besonders für Echtzeitanwendungen geeignet, bei denen Geschwindigkeit entscheidend ist. MyScale bietet neuen Benutzern kostenlosen Speicherplatz für bis zu 5 Millionen Vektoren. Sie können problemlos eine MVP-Version jeder mittleren oder großen Anwendung entwickeln. Besuchen Sie die Homepage von MyScaleDB (opens new window), um ein kostenloses Konto zu erstellen und in 2 Minuten einen kostenlosen Pod zu starten.
Verwandter Artikel: Erste Schritte mit MyScale (opens new window)
# Fazit
Mit der steigenden Nachfrage nach anspruchsvollen, wissensbasierten Anwendungen markiert die Integration von SQL in Retrieval-Augmented Generation-Systeme eine bedeutende Entwicklung. Diese Kombination löst nicht nur die Skalierbarkeits- und Effizienzprobleme spezialisierter Vektor-Datenbanken, sondern nutzt auch die Stärken und Vertrautheit von SQL, um fortschrittliche RAG-Systeme entwicklerfreundlicher und praxisorientierter zu machen.
MyScaleDB steht an vorderster Front dieser Integration und bietet unübertroffene Leistung, Kompatibilität und Benutzerfreundlichkeit. Durch die Wahl von MyScaleDB können Entwickler und Organisationen das volle Potenzial ihrer KI-Anwendungen ausschöpfen. Wenn Sie planen, eine groß angelegte Anwendung zu entwickeln oder Ihre Pläne die Entwicklung einer Anwendung auf einer bereits bestehenden großen Datenbank beinhalten, könnte MyScaleDB die ideale Vektor-Datenbank für Sie sein.
Wenn Sie Vorschläge haben, können Sie uns über Twitter (opens new window) und Discord (opens new window) kontaktieren.



